Gebruik de uitgebreide functies van de Apache Spark History Server om fouten in Spark-toepassingen op te sporen en te diagnosticeren
In dit artikel leest u hoe u de uitgebreide functies van de Apache Spark History Server kunt gebruiken om fouten op te sporen in voltooide of actieve Spark-toepassingen. De extensie bevat een tabblad Gegevens, een grafiektabblad en een tabblad Diagnose. Op het tabblad Gegevens kunt u de invoer- en uitvoergegevens van de Spark-taak controleren. Op het tabblad Grafiek kunt u de gegevensstroom controleren en de taakgrafiek opnieuw afspelen. Op het tabblad Diagnose kunt u verwijzen naar de functies Gegevensverschil, Tijdsverschil en Uitvoerdersgebruiksanalyse .
Toegang krijgen tot de Spark History Server
De Spark History Server is de webgebruikersinterface voor voltooide en actieve Spark-toepassingen. U kunt deze openen vanuit Azure Portal of via een URL.
Open de webgebruikersinterface van Spark History Server vanuit Azure Portal
Open het Spark-cluster vanuit Azure Portal. Zie Lijst en clusters weergeven voor meer informatie.
Selecteer de Spark-geschiedenisserver in clusterdashboards. Wanneer u hierom wordt gevraagd, voert u de beheerdersreferenties voor het Spark-cluster in.
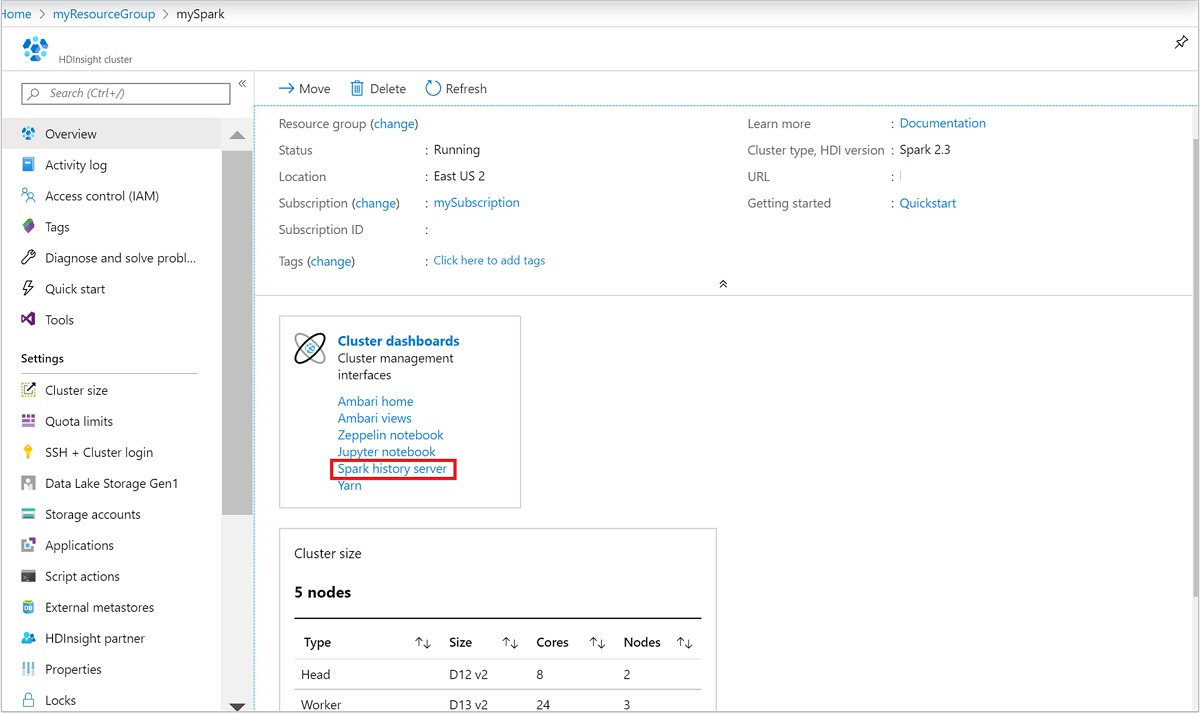 azure Portal.border="true":::
azure Portal.border="true":::
Open de webgebruikersinterface van Spark History Server op URL
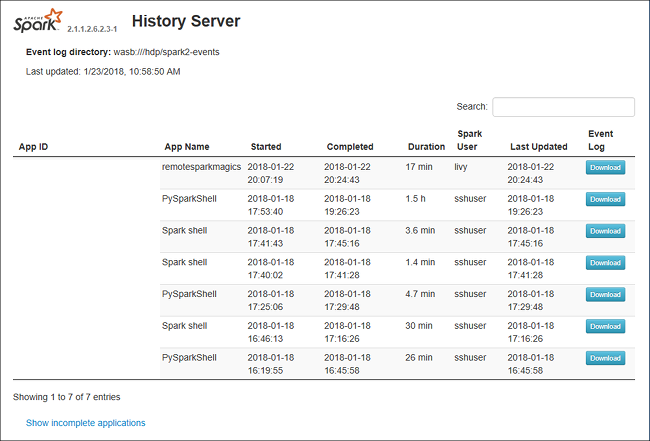
Open de Spark History Server door te bladeren naar https://CLUSTERNAME.azurehdinsight.net/sparkhistory, waar CLUSTERNAME de naam van uw Spark-cluster is.
De webgebruikersinterface van Spark History Server kan er ongeveer als volgt uitzien:
Het tabblad Gegevens gebruiken in de Spark History Server
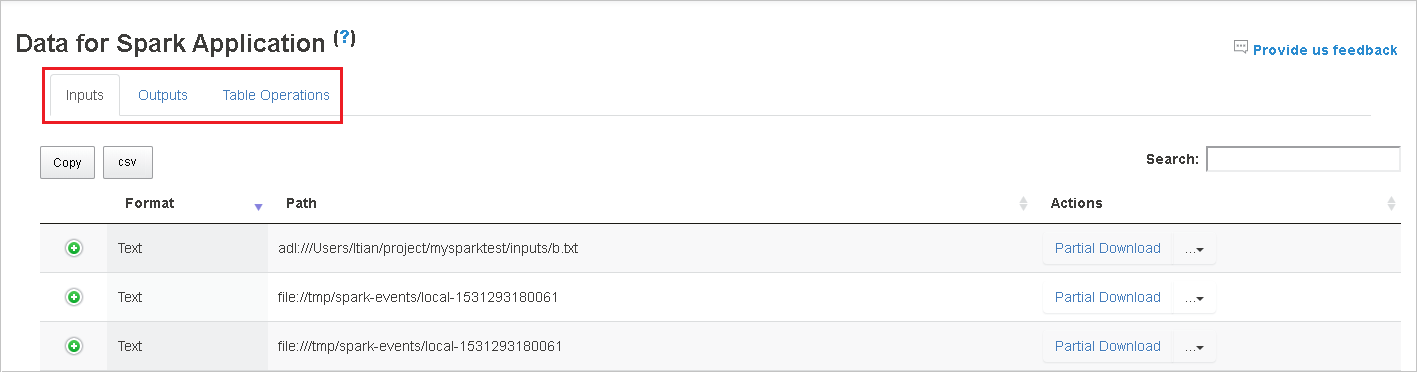
Selecteer de taak-id en selecteer vervolgens Gegevens in het taakmenu om de gegevensweergave weer te geven.
Controleer de invoer-, uitvoer- en tabelbewerkingen door de afzonderlijke tabbladen te selecteren.
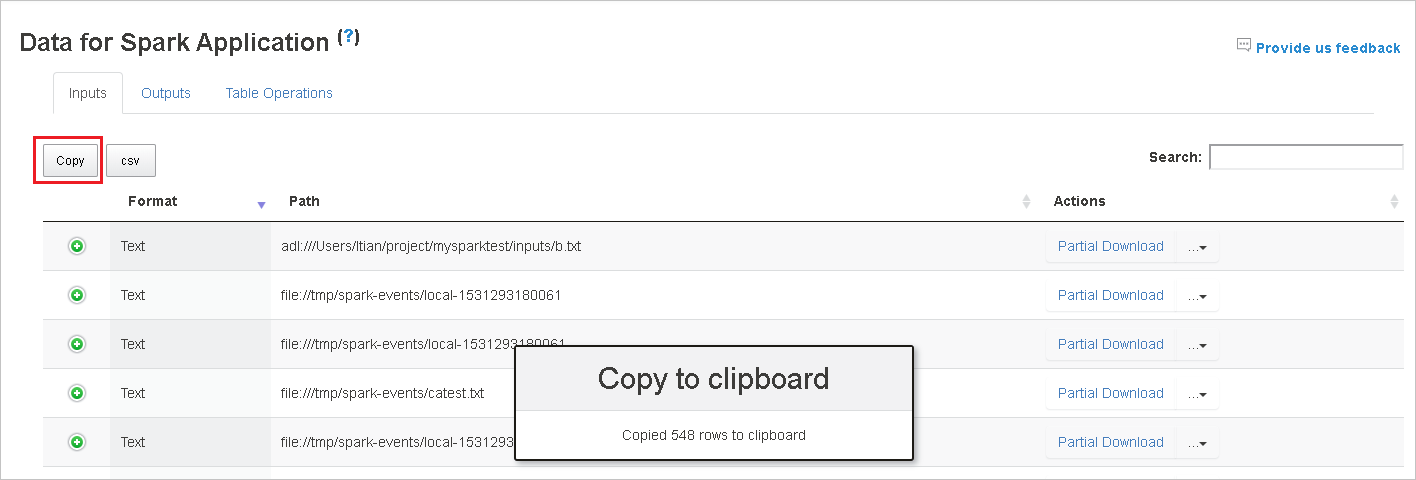
Kopieer alle rijen door de knop Kopiëren te selecteren.
Sla alle gegevens op als een . CSV-bestand door de csv-knop te selecteren.
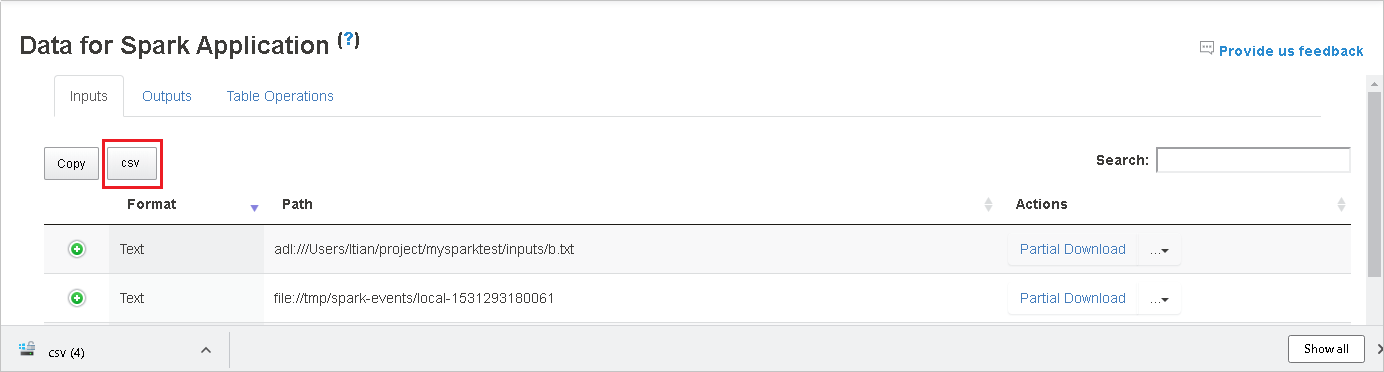
Zoek de gegevens door trefwoorden in te voeren in het zoekveld. De zoekresultaten worden onmiddellijk weergegeven.
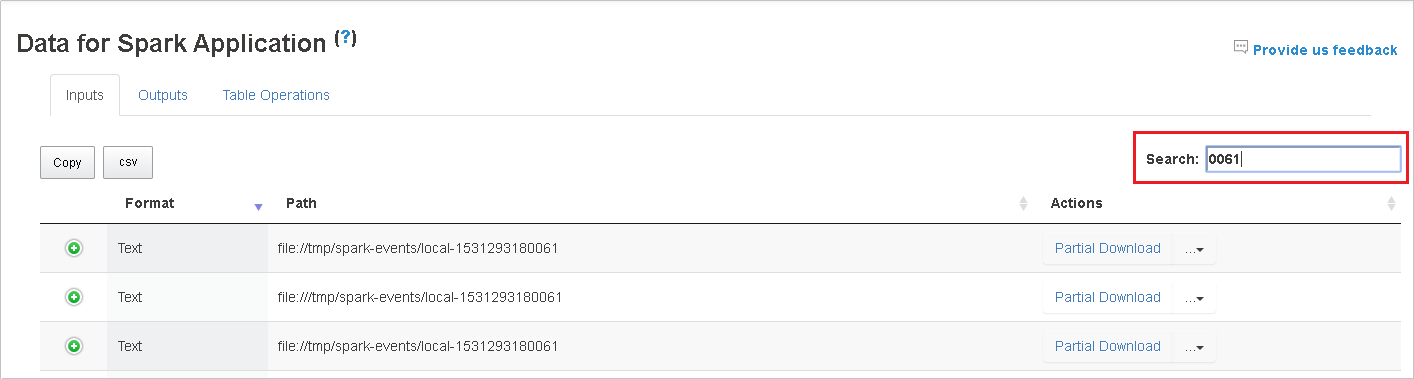
Selecteer de kolomkop om de tabel te sorteren. Selecteer het plusteken om een rij uit te vouwen om meer details weer te geven. Selecteer het minteken om een rij samen te vouwen.
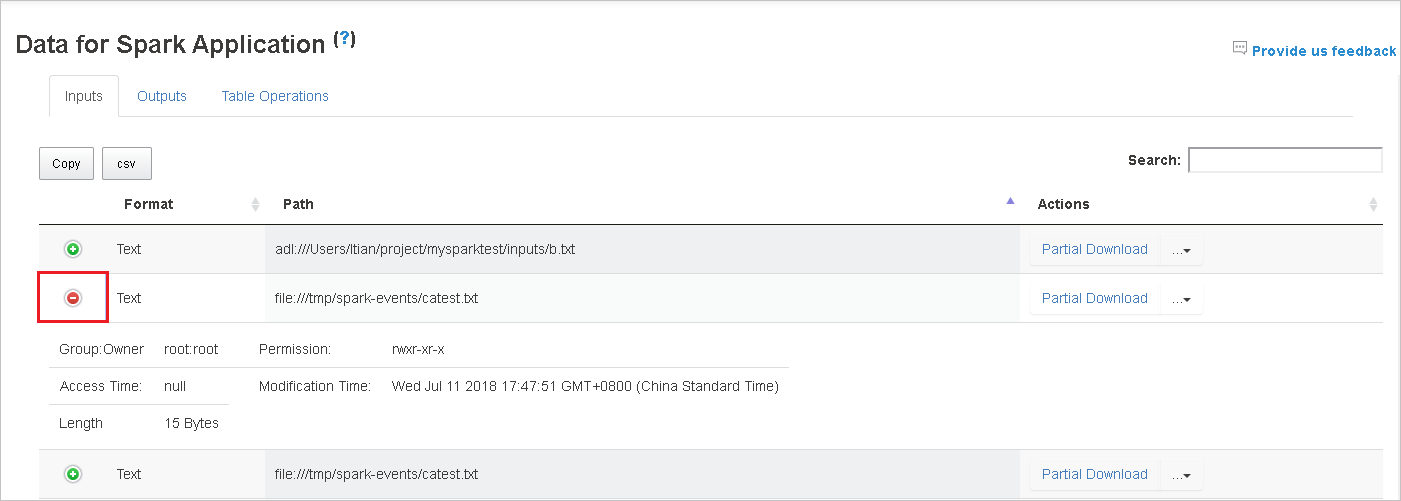
Download één bestand door de knop Gedeeltelijk downloaden aan de rechterkant te selecteren. Het geselecteerde bestand wordt lokaal gedownload. Als het bestand niet meer bestaat, wordt er een nieuw tabblad geopend om de foutberichten weer te geven.
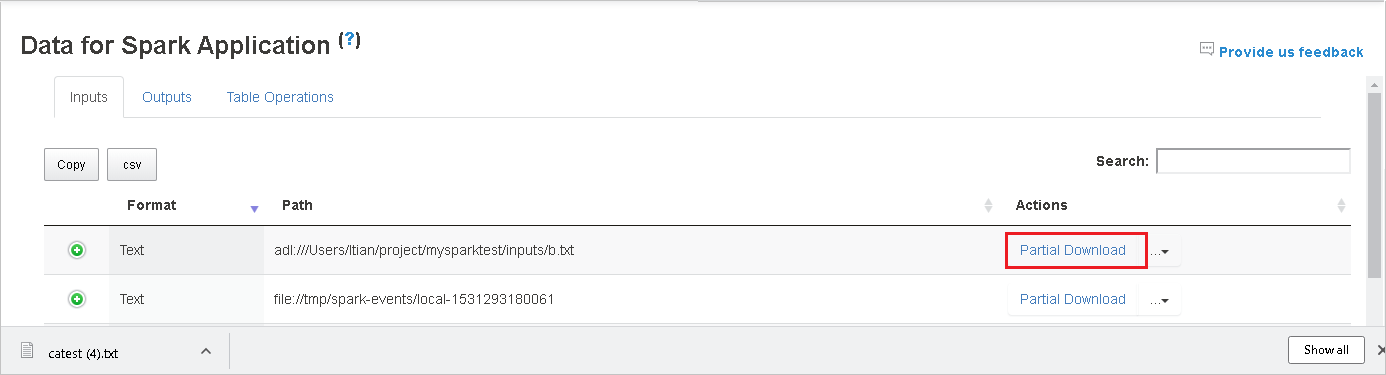
Kopieer een volledig pad of een relatief pad door de optie Volledig kopiëren of Relatief pad kopiëren te selecteren, die uitvouwen in het downloadmenu. Voor Azure Data Lake Storage-bestanden selecteert u Openen in Azure Storage Explorer om Azure Storage Explorer te starten en de map te vinden nadat u zich hebt aangemeld.
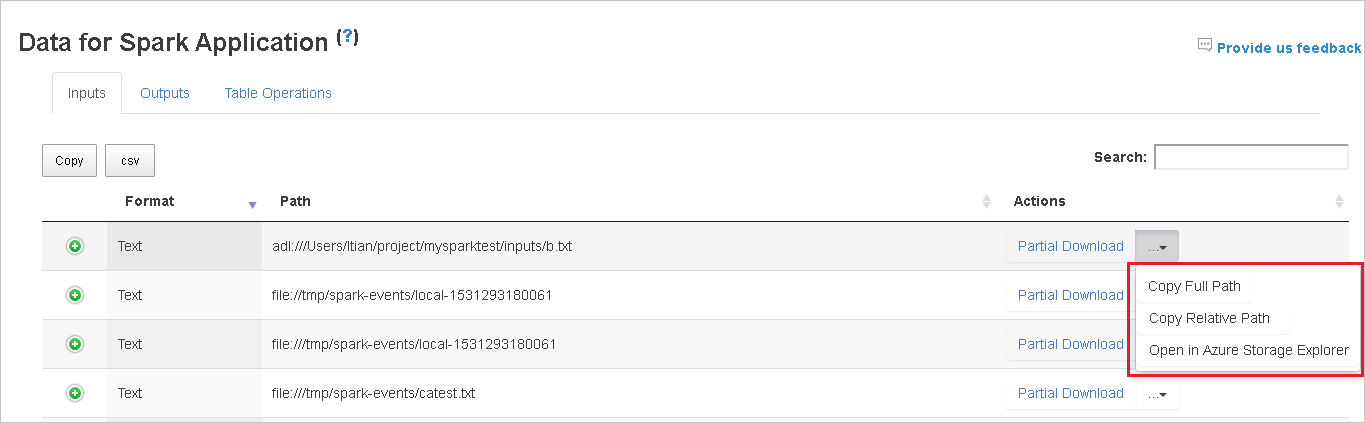
Als er te veel rijen zijn om op één pagina weer te geven, selecteert u de paginanummers onder aan de tabel om te navigeren.

Plaats de muisaanwijzer op het vraagteken naast Gegevens voor Spark-toepassing om de knopinfo weer te geven voor meer informatie.
Als u feedback wilt verzenden over problemen, selecteert u Feedback geven.
Het tabblad Graph in de Spark History Server gebruiken
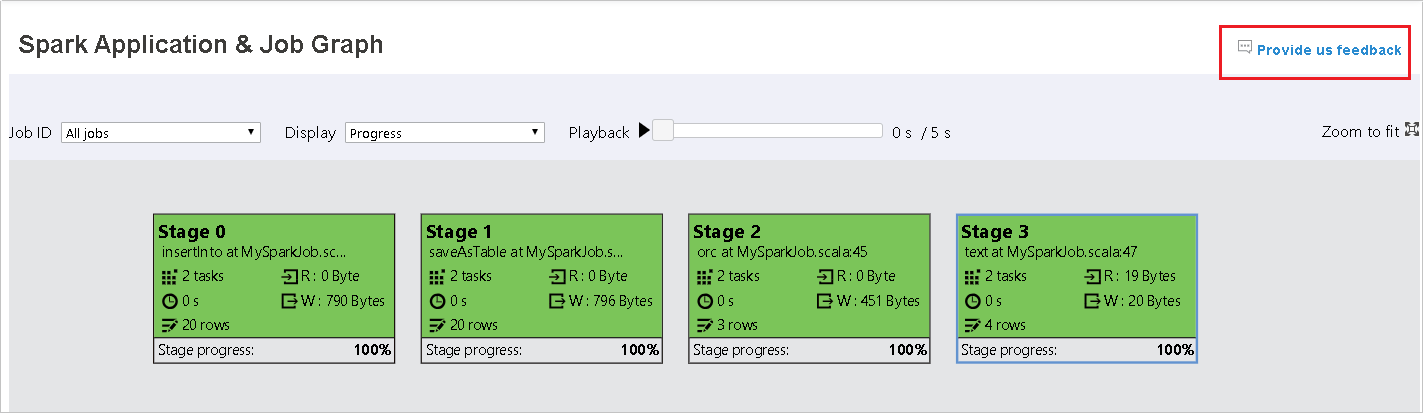
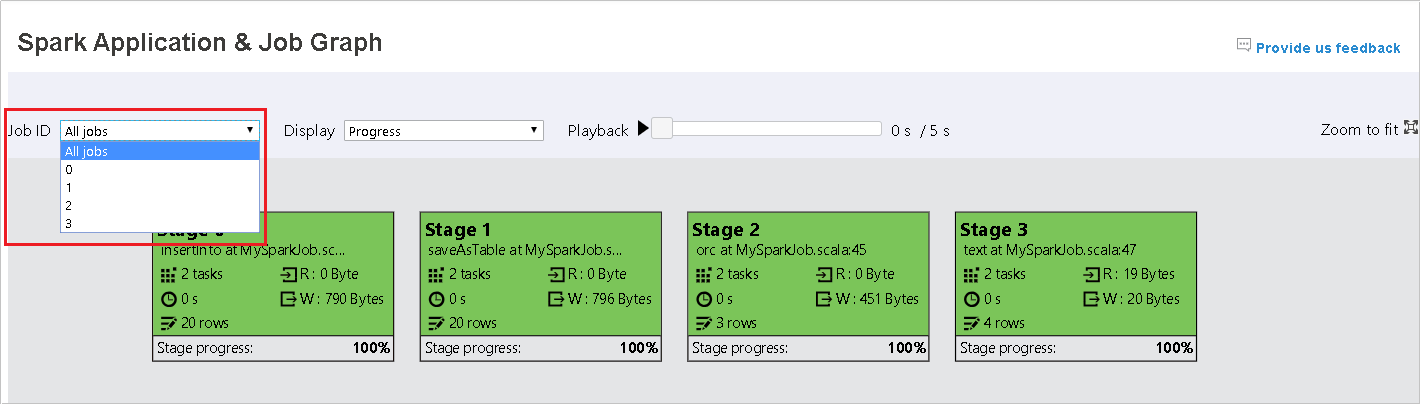
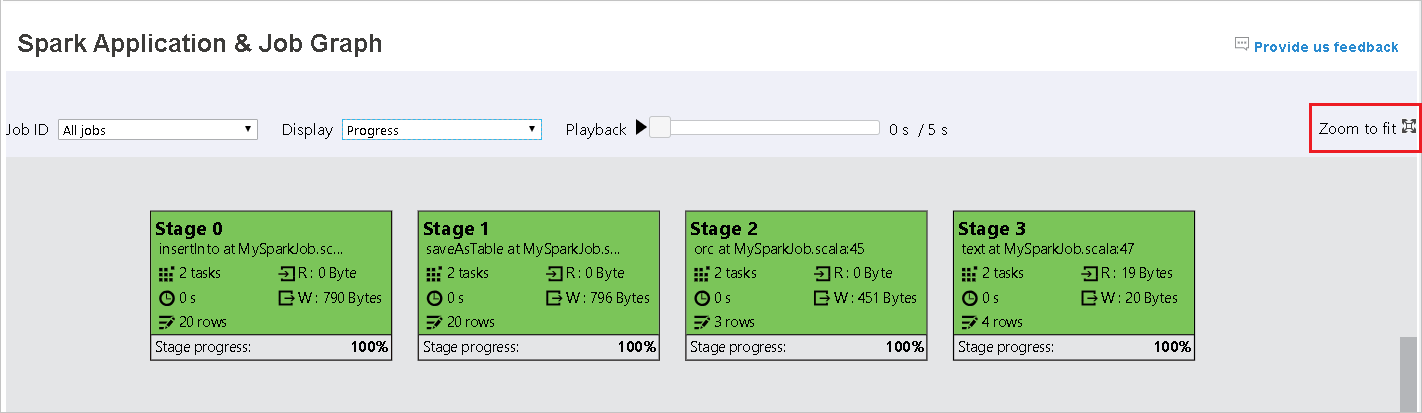
Selecteer de taak-id en selecteer vervolgens Graph in het taakmenu om de taakgrafiek weer te geven. In de grafiek worden standaard alle taken weergegeven. Filter de resultaten met behulp van de vervolgkeuzelijst Taak-id .
Voortgang is standaard geselecteerd. Controleer de gegevensstroom door Lezen of Geschreven te selecteren in de vervolgkeuzelijst Weergave.
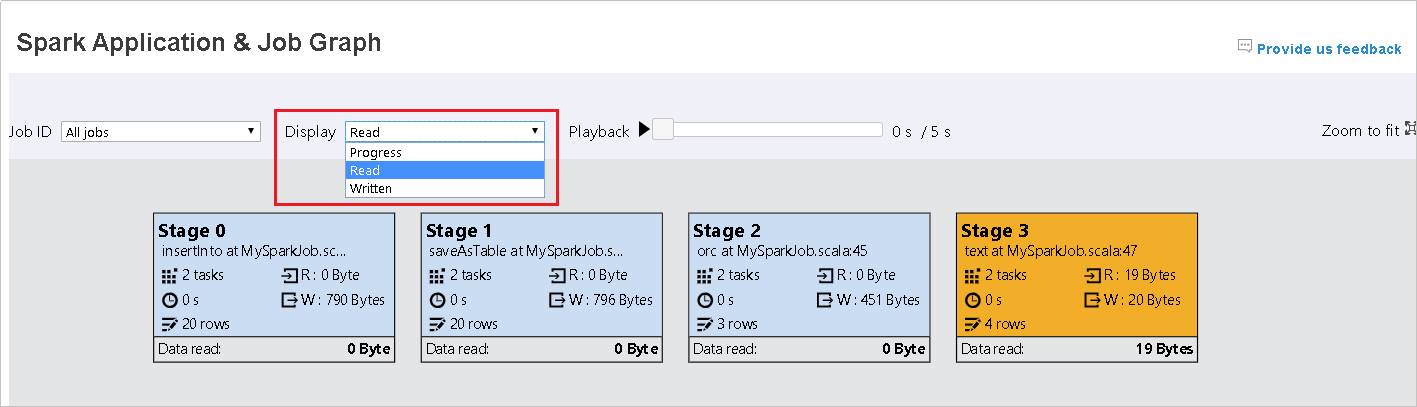
De achtergrondkleur van elke taak komt overeen met een heatmap.

Color Beschrijving Groen De taak is voltooid. Orange De taak is mislukt, maar dit heeft geen invloed op het uiteindelijke resultaat van de taak. Deze taken hebben dubbele exemplaren of nieuwe pogingen die later kunnen slagen. Blauw De taak wordt uitgevoerd. Wit De taak wacht op uitvoering of de fase is overgeslagen. Rood De taak is mislukt. 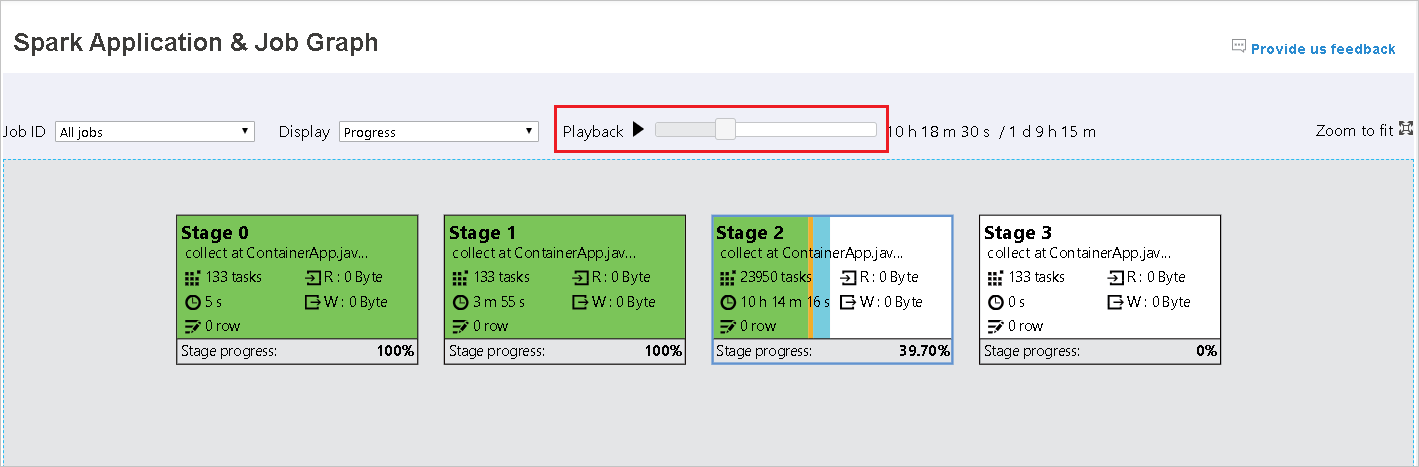
De overgeslagen fasen worden wit weergegeven.
Notitie
Afspelen is beschikbaar voor voltooide taken. Selecteer de knop Afspelen om de taak terug te spelen. Stop de taak op elk gewenst moment door de stopknop te selecteren. Wanneer een taak wordt afgespeeld, wordt de status van elke taak op kleur weergegeven. Afspelen wordt niet ondersteund voor onvolledige taken.
Schuif om in of uit te zoomen op de taakgrafiek of selecteer In- of uitzoomen om deze passend te maken voor het scherm.
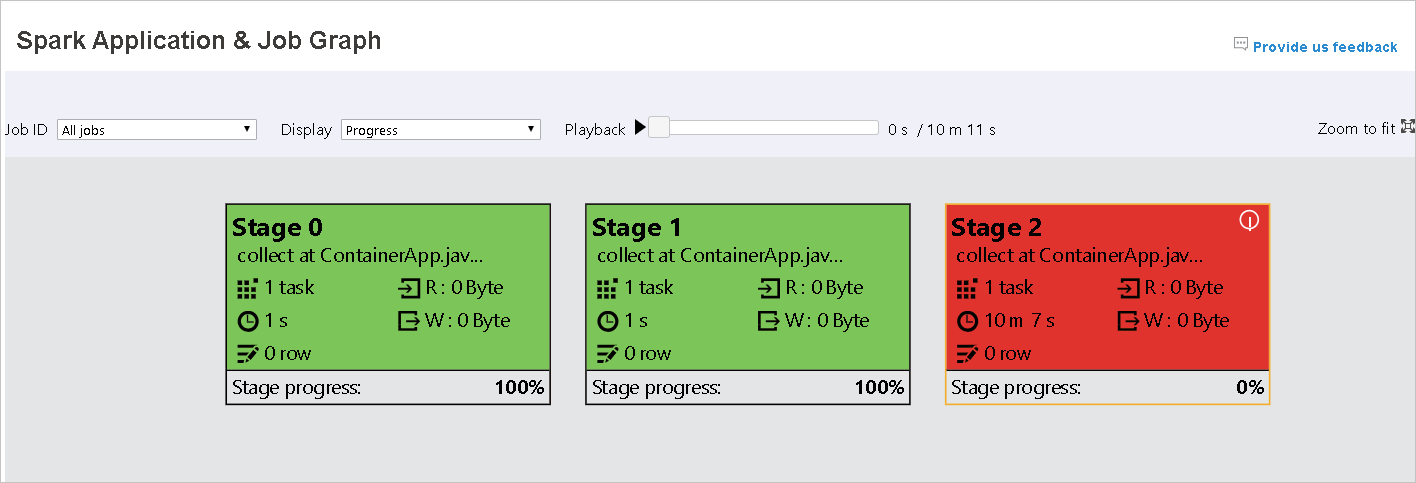
Wanneer taken mislukken, beweegt u de muisaanwijzer over het grafiekknooppunt om de knopinfo weer te geven en selecteert u vervolgens de fase om deze te openen op een nieuwe pagina.
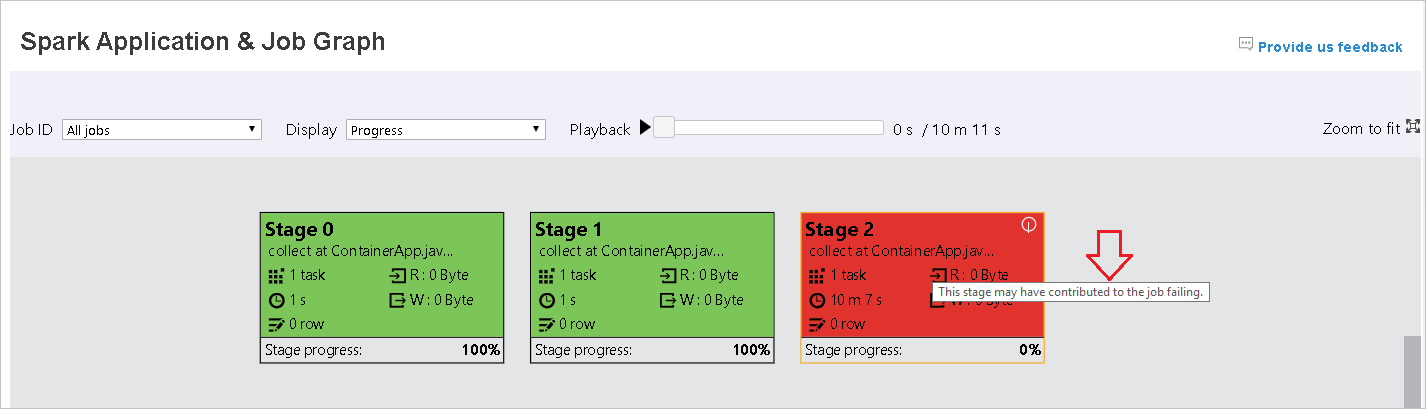
Op de pagina Spark Application & Job Graph worden knopinfo en kleine pictogrammen weergegeven als de taken aan deze voorwaarden voldoen:
Scheeftrekken van gegevens: de gemiddelde leesgrootte > van gegevens van alle taken in deze fase * 2 en de leesgrootte > van gegevens 10 MB.
Tijdverschil: de gemiddelde uitvoeringstijd > van alle taken in deze fase * 2 en uitvoeringstijd > 2 minuten.
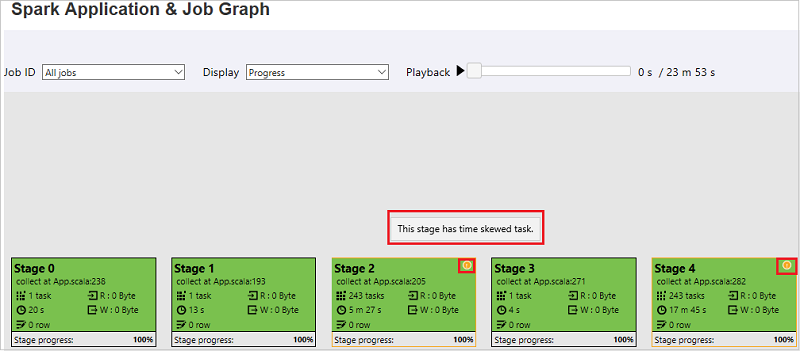
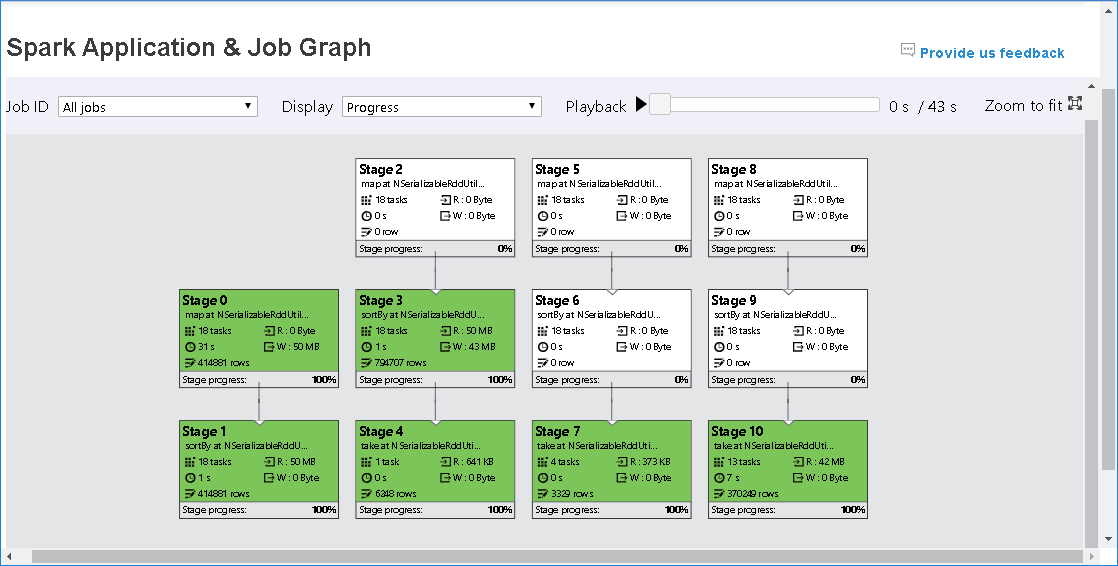
In het taakgrafiekknooppunt ziet u de volgende informatie over elke fase:
Id
Naam of omschrijving
Totaal aantal taken
Gegevens gelezen: de som van de invoergrootte en de willekeurige leesgrootte
Gegevens schrijven: de som van de uitvoergrootte en de schrijfgrootte in willekeurige volgorde
Uitvoeringstijd: de tijd tussen de begintijd van de eerste poging en de voltooiingstijd van de laatste poging
Aantal rijen: de som van invoerrecords, uitvoerrecords, willekeurige leesrecords en willekeurige schrijfrecords
Voortgang
Notitie
Standaard geeft het taakgrafiekknooppunt informatie weer van de laatste poging van elke fase (met uitzondering van uitvoeringstijd van de fase). Tijdens het afspelen toont het taakgrafiekknooppunt echter informatie over elke poging.
Notitie
Voor lees- en schrijfgrootten van gegevens gebruiken we 1 MB = 1000 KB = 1000 * 1000 bytes.
Stuur feedback over problemen door Feedback geven te selecteren.
Het tabblad Diagnose gebruiken in de Spark-geschiedenisserver
Selecteer de taak-id en selecteer vervolgens Diagnose in het taakmenu om de functiediagnoseweergave weer te geven. Het tabblad Diagnose bevat gegevensverschil, Tijdsverschil en Analyse van uitvoerdersgebruik.
Controleer gegevensverschil, tijdsverschil en gebruiksanalyse van uitvoerders door respectievelijk de tabbladen te selecteren.
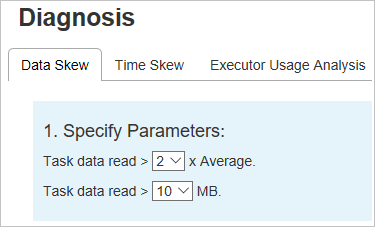
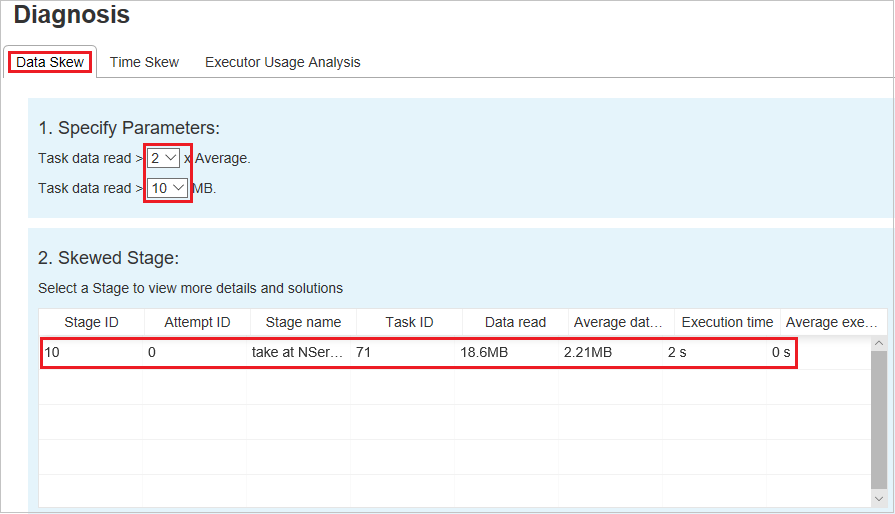
Gegevensscheefheid
Selecteer het tabblad Gegevensverschil . De bijbehorende scheve taken worden weergegeven op basis van de opgegeven parameters.
Parameters opgeven
In de sectie Parameters opgeven worden de parameters weergegeven die worden gebruikt om scheeftrekken van gegevens te detecteren. De standaardregel is: de gelezen taakgegevens zijn groter dan drie keer van de gemiddelde gelezen taakgegevens en de gelezen taakgegevens zijn meer dan 10 MB. Als u uw eigen regel wilt definiëren voor scheve taken, kunt u uw parameters kiezen. De secties Scheeftrekken en Scheeftrekken worden dienovereenkomstig bijgewerkt.
Scheeftrekkende fase
In de sectie Scheeftrekkende fase worden fasen weergegeven die scheefgetrokken taken hebben die voldoen aan de opgegeven criteria. Als er meer dan één scheve taak in een fase is, geeft de sectie Scheeftrekkende fase alleen de meest scheeftrekkende taak weer (dat wil gezegd de grootste gegevens voor scheeftrekken van gegevens).
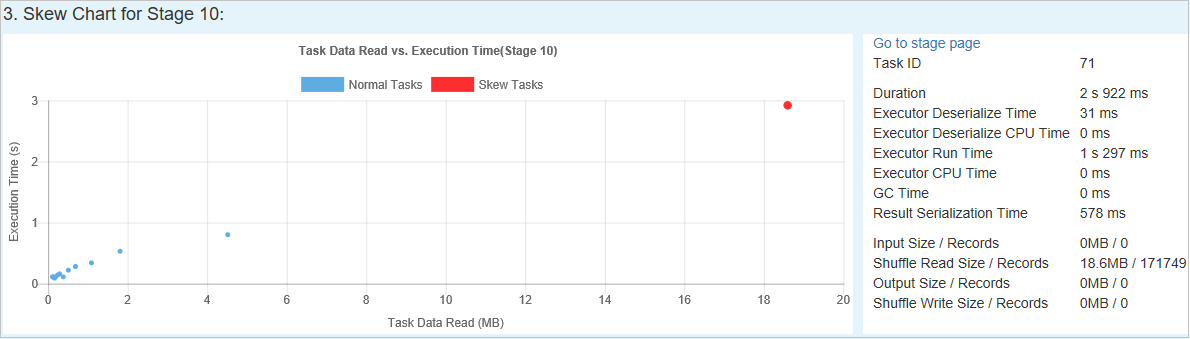
Scheeftrekken van diagram
Wanneer u een rij in de tabel Scheeftrekkende fase selecteert, worden in het diagram meer taakdistributiedetails weergegeven op basis van de lees- en uitvoeringstijd van gegevens. De scheve taken worden rood gemarkeerd en de normale taken worden blauw gemarkeerd. Voor prestatieoverwegingen geeft de grafiek maximaal 100 voorbeeldtaken weer. De taakdetails worden weergegeven in het deelvenster rechtsonder.
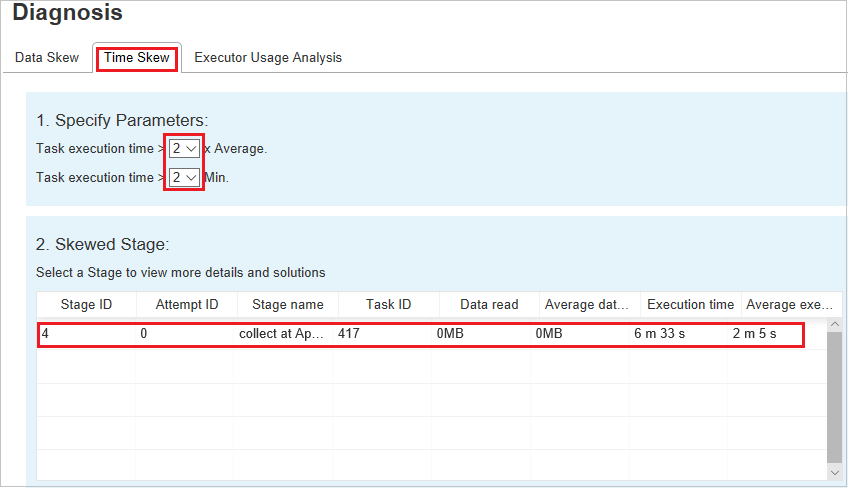
Tijdsverschil
Op het tabblad Tijdverschil worden scheve taken weergegeven op basis van de uitvoeringstijd van de taak.
Parameters opgeven
In de sectie Parameters opgeven worden de parameters weergegeven die worden gebruikt om tijdverschil te detecteren. De standaardregel is: de uitvoeringstijd van de taak is groter dan drie keer van de gemiddelde uitvoeringstijd en de uitvoeringstijd van de taak is groter dan 30 seconden. U kunt de parameters wijzigen op basis van uw behoeften. In het scheeftrekkende stadium en de scheefheidsgrafiek worden de bijbehorende fasen en taakgegevens weergegeven, net zoals op het tabblad Gegevensverschil .
Wanneer u Tijdsverschil selecteert, wordt het gefilterde resultaat weergegeven in de sectie Scheeftrekkende fase, volgens de parameters die zijn ingesteld in de sectie Parameters opgeven. Wanneer u één item selecteert in de sectie Scheeftrekken, wordt de bijbehorende grafiek opgesteld in de derde sectie en worden de taakdetails weergegeven in het deelvenster rechtsonder.
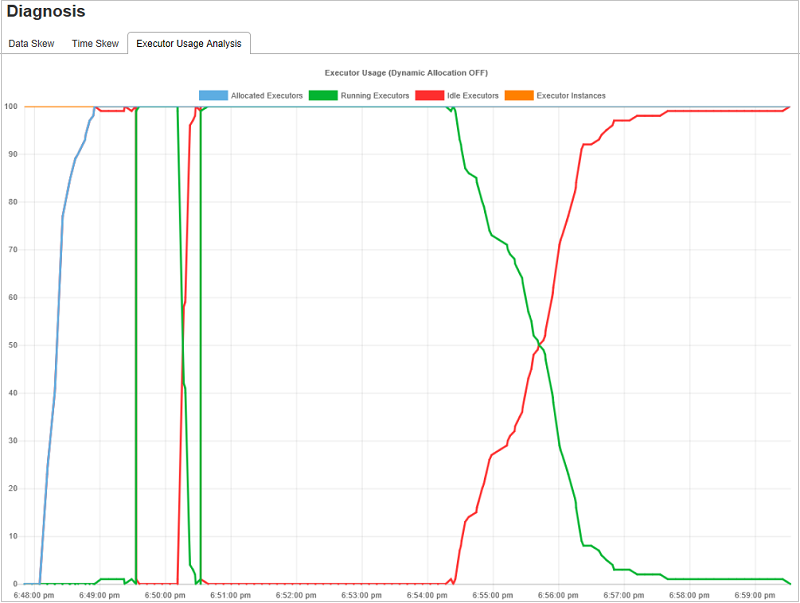
Grafieken voor gebruiksanalyse van uitvoerders
De uitvoerdersgebruiksgrafiek geeft de werkelijke toewijzing van de taak en de uitvoeringsstatus van de taak weer.
Wanneer u Gebruiksanalyse van uitvoerders selecteert, worden er vier verschillende curven over het gebruik van uitvoerders opgesteld: Toegewezen uitvoerders, actieve uitvoerders, niet-actieve uitvoerders en Max Executor-exemplaren. Elke uitvoerder die is toegevoegd of de uitvoerder heeft verwijderd , verhoogt of verlaagt de toegewezen uitvoerders. U kunt de tijdlijn van gebeurtenissen controleren op het tabblad Taken voor meer vergelijkingen.
Selecteer het kleurpictogram om de bijbehorende inhoud in alle concepten te selecteren of de selectie op te heffen.
Veelgestelde vragen
Hoe kan ik terug naar de communityversie?
Voer de volgende stappen uit om terug te keren naar de communityversie.
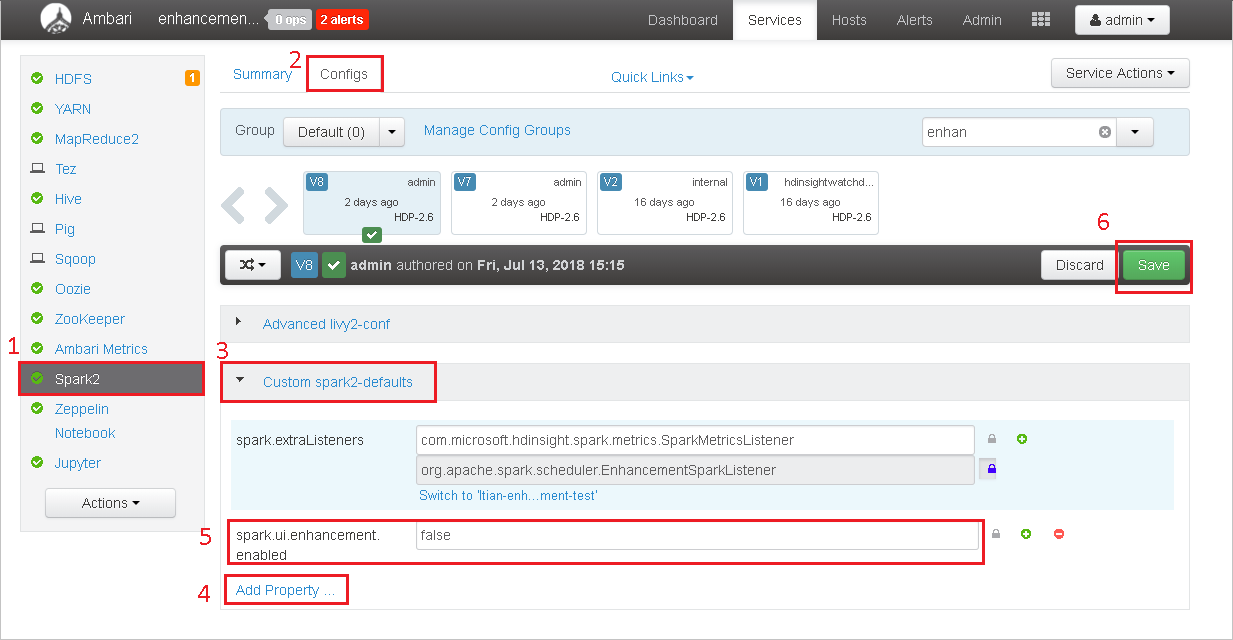
Open het cluster in Ambari.
Navigeer naar Spark2-configuraties>.
Selecteer Aangepaste spark2-standaardwaarden.
Selecteer Eigenschap toevoegen....
Voeg spark.ui.enhancement.enabled=false toe en sla deze op.
De eigenschap wordt nu ingesteld op false .
Selecteer Opslaan om de configuratie op te slaan.
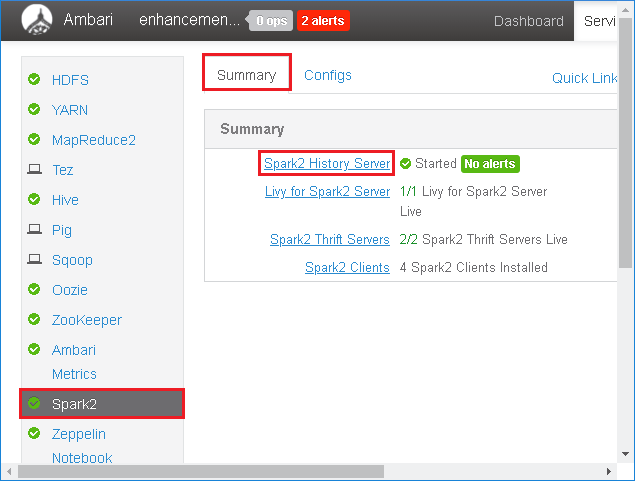
Selecteer Spark2 in het linkerdeelvenster. Selecteer vervolgens op het tabblad Samenvatting de optie Spark2 History Server.
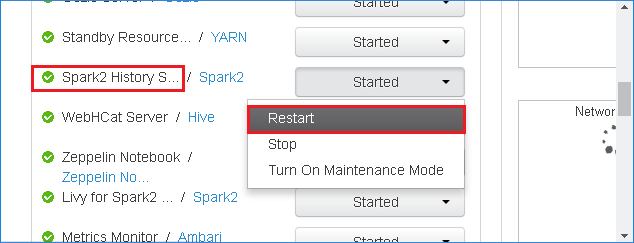
Als u de Spark History Server opnieuw wilt starten, selecteert u de knop Gestart rechts van Spark2 History Server en selecteert u Opnieuw opstarten in de vervolgkeuzelijst.
Vernieuw de webgebruikersinterface van Spark History Server. Deze wordt teruggezet naar de communityversie.
Hoe kan ik een Spark History Server-gebeurtenis uploaden om deze als een probleem te rapporteren?
Als er een fout optreedt in Spark History Server, voert u de volgende stappen uit om de gebeurtenis te rapporteren.
Download de gebeurtenis door Downloaden te selecteren in de webgebruikersinterface van Spark History Server.
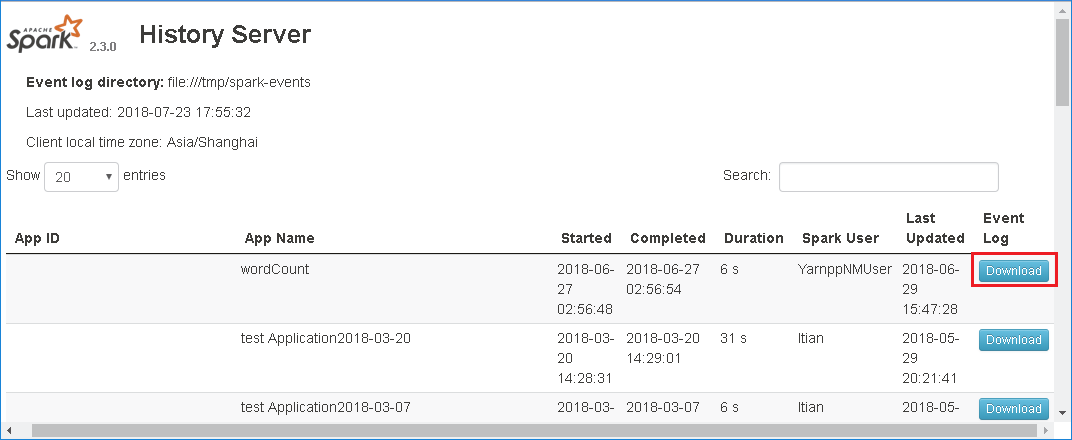
Selecteer Feedback geven op de pagina Spark-toepassing en taakgrafiek .
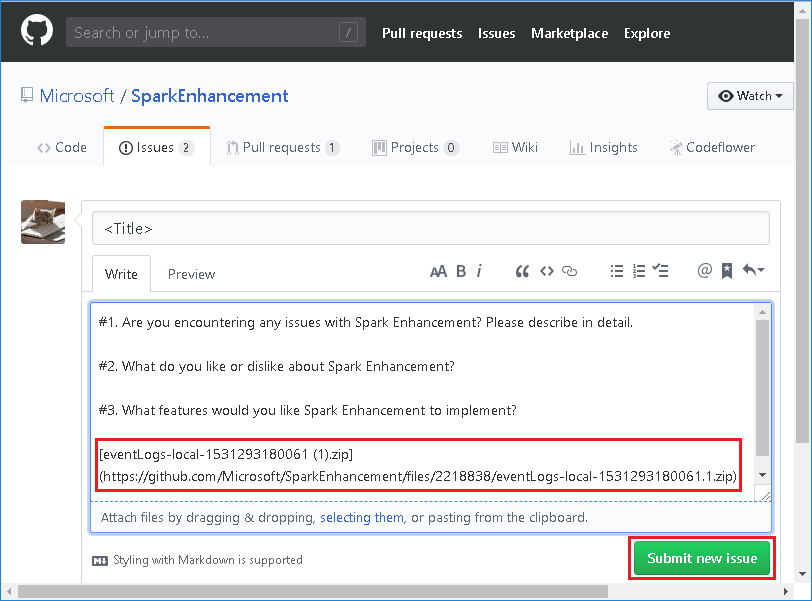
Geef de titel en een beschrijving van de fout op. Sleep vervolgens het .zip-bestand naar het bewerkingsveld en selecteer Nieuw probleem verzenden.
Hoe kan ik een .jar-bestand bijwerken in een hotfix-scenario?
Als u een upgrade wilt uitvoeren met een hotfix, gebruikt u het volgende script, dat wordt bijgewerkt spark-enhancement.jar*.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Gebruik
upgrade_spark_enhancement.sh https://${jar_path}
Opmerking
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Het bash-bestand gebruiken vanuit Azure Portal
Start De Azure-portal en selecteer vervolgens uw cluster.
Voer een scriptactie uit met de volgende parameters.
Eigenschappen Weergegeven als Scripttype - Aangepast Naam UpgradeJar Bash-script-URI https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shKnooppunttype(n) Hoofd, werkrol Parameters https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar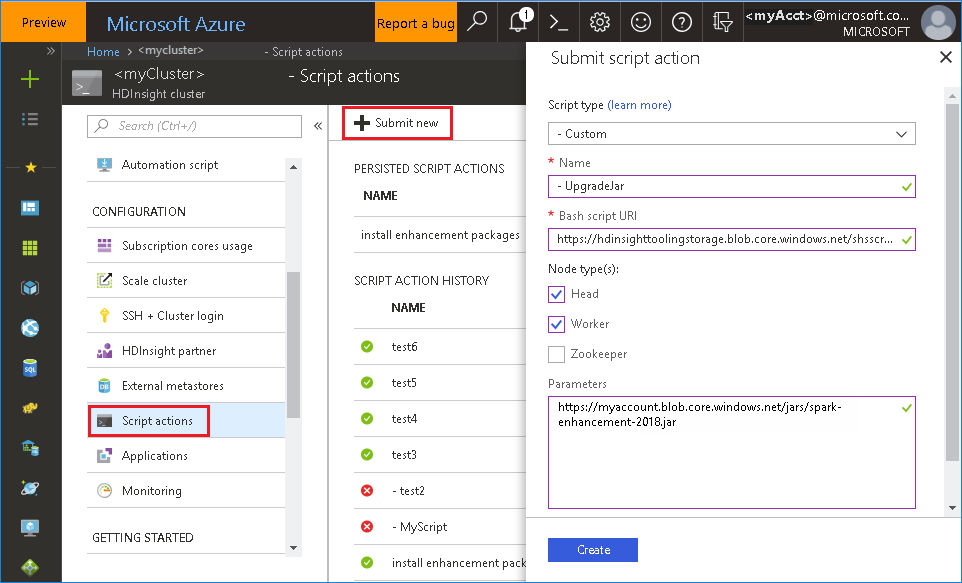
Bekende problemen
Momenteel werkt de Spark History Server alleen voor Spark 2.3 en 2.4.
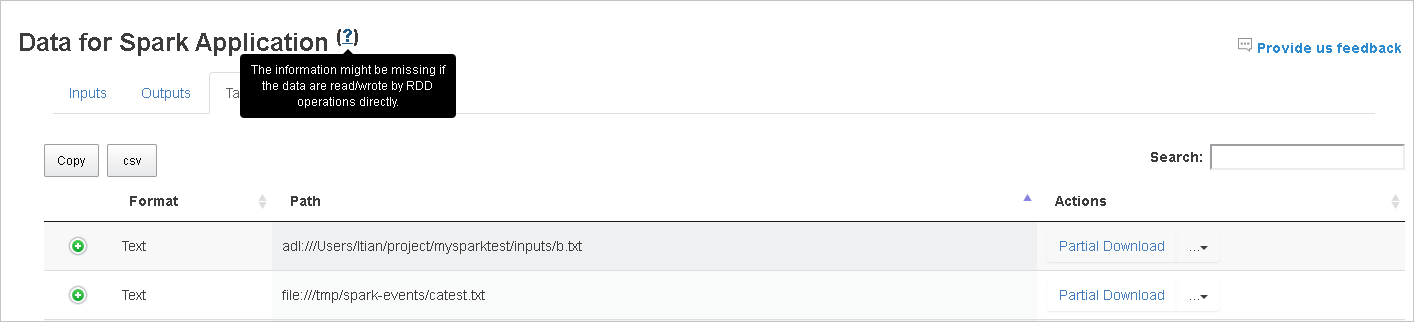
Invoer- en uitvoergegevens die gebruikmaken van RDD, worden niet weergegeven op het tabblad Gegevens .
Volgende stappen
Suggesties
Als u feedback hebt of problemen ondervindt bij het gebruik van dit hulpprogramma, stuurt u een e-mail naar (hdivstool@microsoft.com).