Apache Spark-instellingen configureren
Een HDInsight Spark-cluster bevat een installatie van de Apache Spark-bibliotheek. Elk HDInsight-cluster bevat standaardconfiguratieparameters voor alle geïnstalleerde services, waaronder Spark. Een belangrijk aspect van het beheren van een HDInsight Apache Hadoop-cluster is het bewaken van de workload, waaronder Spark-taken. Als u Spark-taken het beste wilt uitvoeren, moet u rekening houden met de configuratie van het fysieke cluster bij het bepalen van de logische configuratie van het cluster.
Het standaard HDInsight Apache Spark-cluster bevat de volgende knooppunten: drie Apache ZooKeeper-knooppunten, twee hoofdknooppunten en een of meer werkknooppunten:
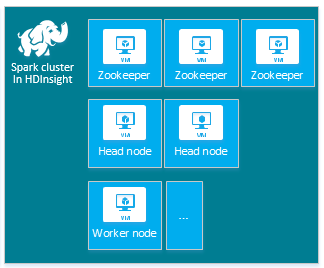
Het aantal VM's en VM-grootten voor de knooppunten in uw HDInsight-cluster kan van invloed zijn op uw Spark-configuratie. Niet-standaard HDInsight-configuratiewaarden vereisen vaak niet-standaard Spark-configuratiewaarden. Wanneer u een HDInsight Spark-cluster maakt, ziet u voorgestelde VM-grootten voor elk van de onderdelen. Momenteel zijn de voor geheugen geoptimaliseerde Linux-VM-grootten voor Azure D12 v2 of hoger.
Apache Spark-versies
Gebruik de beste Spark-versie voor uw cluster. De HDInsight-service bevat verschillende versies van zowel Spark als HDInsight zelf. Elke versie van Spark bevat een set standaardclusterinstellingen.
Wanneer u een nieuw cluster maakt, kunt u kiezen uit meerdere Spark-versies. Als u de volledige lijst wilt zien, zijn HDInsight Components and Versions.
Notitie
De standaardversie van Apache Spark in de HDInsight-service kan zonder voorafgaande kennisgeving worden gewijzigd. Als u een versieafhankelijkheid hebt, raadt Microsoft u aan die specifieke versie op te geven wanneer u clusters maakt met behulp van .NET SDK, Azure PowerShell en klassieke Azure CLI.
Apache Spark heeft drie systeemconfiguratielocaties:
- Spark-eigenschappen bepalen de meeste toepassingsparameters en kunnen worden ingesteld met behulp van een
SparkConfobject of via Java-systeemeigenschappen. - Omgevingsvariabelen kunnen worden gebruikt om instellingen per machine, zoals het IP-adres, in te stellen via het
conf/spark-env.shscript op elk knooppunt. - Logboekregistratie kan worden geconfigureerd via
log4j.properties.
Wanneer u een bepaalde versie van Spark selecteert, bevat uw cluster de standaardconfiguratie-instellingen. U kunt de standaardconfiguratiewaarden voor Spark wijzigen met behulp van een aangepast Spark-configuratiebestand. Hieronder kunt u een voorbeeld bekijken.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
In het bovenstaande voorbeeld worden verschillende standaardwaarden voor vijf Spark-configuratieparameters overschreven. Deze waarden zijn de compressiecodec, Apache Hadoop MapReduce split minimumgrootte en parquet-blokgrootten. Daarnaast worden de standaardwaarden voor de Spark SQL-partitie en het openen van de bestandsgrootten geopend. Deze configuratiewijzigingen worden gekozen omdat de bijbehorende gegevens en taken (in dit voorbeeld genomische gegevens) specifieke kenmerken hebben. Deze kenmerken werken beter met behulp van deze aangepaste configuratie-instellingen.
Clusterconfiguratie-instellingen weergeven
Controleer de huidige configuratie-instellingen van het HDInsight-cluster voordat u prestatieoptimalisatie op het cluster uitvoert. Start het HDInsight-dashboard vanuit Azure Portal door te klikken op de koppeling Dashboard in het deelvenster Spark-cluster. Meld u aan met de gebruikersnaam en het wachtwoord van de clusterbeheerder.
De Apache Ambari-webgebruikersinterface wordt weergegeven, met een dashboard met metrische gegevens over het resourcegebruik van belangrijke clusters. In het Ambari-dashboard ziet u de Apache Spark-configuratie en andere geïnstalleerde services. Het dashboard bevat een tabblad Configuratiegeschiedenis , waar u informatie weergeeft voor geïnstalleerde services, waaronder Spark.
Als u configuratiewaarden voor Apache Spark wilt zien, selecteert u Configuratiegeschiedenis en selecteert u Vervolgens Spark2. Selecteer het tabblad Configuraties en selecteer vervolgens de Spark koppeling (of Spark2, afhankelijk van uw versie) in de servicelijst. U ziet een lijst met configuratiewaarden voor uw cluster:
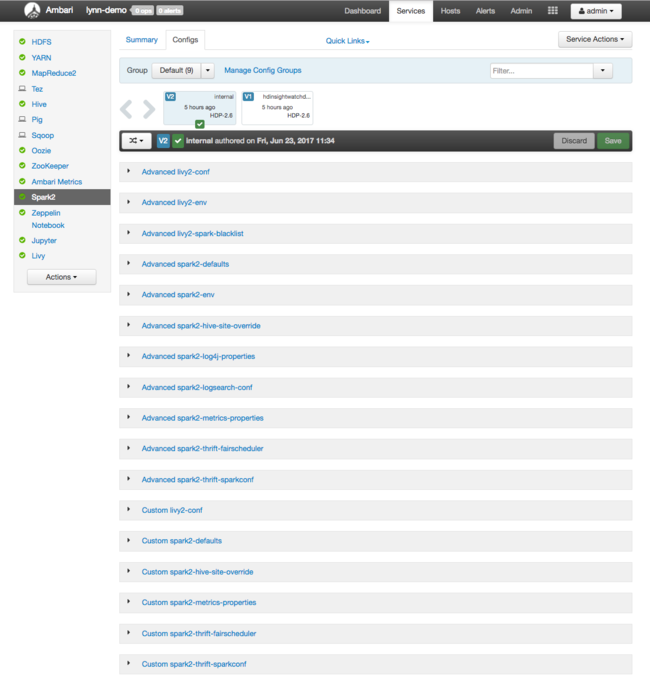
Als u afzonderlijke Spark-configuratiewaarden wilt bekijken en wijzigen, selecteert u een koppeling met Spark in de titel. Configuraties voor Spark bevatten zowel aangepaste als geavanceerde configuratiewaarden in deze categorieën:
- Aangepaste Spark2-standaardinstellingen
- Aangepaste spark2-metrics-properties
- Geavanceerde Spark2-standaardinstellingen
- Geavanceerde Spark2-env
- Geavanceerde spark2-hive-site-override
Als u een niet-standaardset met configuratiewaarden maakt, is uw updategeschiedenis zichtbaar. Deze configuratiegeschiedenis kan handig zijn om te zien welke niet-standaardconfiguratie optimale prestaties heeft.
Notitie
Als u algemene configuratie-instellingen voor Spark-clusters wilt zien, maar niet wilt wijzigen, selecteert u het tabblad Omgeving in de interface van de Spark-taak op het hoogste niveau.
Spark-uitvoerders configureren
In het volgende diagram ziet u belangrijke Spark-objecten: het stuurprogrammaprogramma en de bijbehorende Spark-context, en de clusterbeheerder en de n-werkknooppunten . Elk werkknooppunt bevat een uitvoerder, een cache en n taakexemplaren.
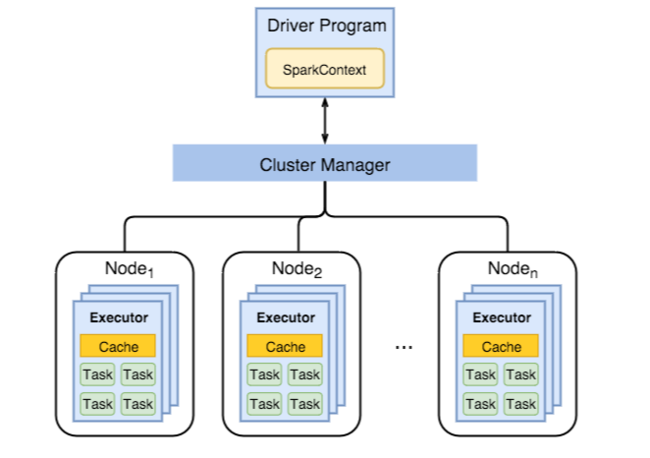
Spark-taken maken gebruik van werkrolbronnen, met name geheugen, dus het is gebruikelijk om Spark-configuratiewaarden voor werkknooppuntuitvoerders aan te passen.
Drie belangrijke parameters die vaak worden aangepast om Spark-configuraties af te stemmen om de toepassingsvereisten te verbeteren, zijn spark.executor.instances, spark.executor.coresen spark.executor.memory. Een executor is een proces dat wordt gestart voor een Spark-toepassing. Een uitvoerder wordt uitgevoerd op het werkknooppunt en is verantwoordelijk voor de taken voor de toepassing. Het aantal werkknooppunten en de grootte van het werkknooppunt bepaalt het aantal uitvoerders en uitvoerders. Deze waarden worden opgeslagen op spark-defaults.conf de hoofdknooppunten van het cluster. U kunt deze waarden bewerken in een actief cluster door aangepaste spark-standaardinstellingen te selecteren in de Ambari-webgebruikersinterface. Nadat u wijzigingen hebt aangebracht, wordt u door de gebruikersinterface gevraagd om alle betrokken services opnieuw te starten .
Notitie
Deze drie configuratieparameters kunnen worden geconfigureerd op clusterniveau (voor alle toepassingen die op het cluster worden uitgevoerd) en ook opgegeven voor elke afzonderlijke toepassing.
Een andere bron van informatie over resources die door Spark Executors worden gebruikt, is de gebruikersinterface van de Spark-toepassing. In de gebruikersinterface worden samenvattings- en detailweergaven van de configuratie- en verbruikte resources weergegeven. Bepaal of u uitvoerderswaarden voor het hele cluster of een bepaalde set taakuitvoeringen wilt wijzigen.
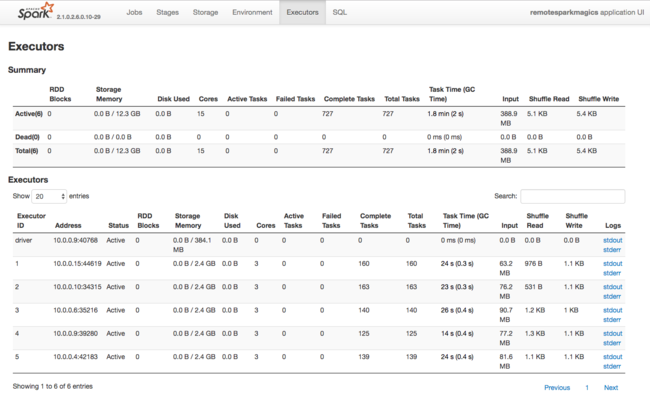
U kunt ook de Ambari REST API gebruiken om de configuratie-instellingen voor HDInsight- en Spark-cluster programmatisch te verifiëren. Meer informatie vindt u in de Naslaginformatie over de Apache Ambari-API op GitHub.
Afhankelijk van de Spark-workload kunt u bepalen dat een Spark-configuratie die niet-standaard is, meer geoptimaliseerde uitvoeringen van Spark-taken biedt. Voer benchmarktests uit met voorbeeldworkloads om niet-standaardclusterconfiguraties te valideren. Suggesties voor algemene parameters die u kunt aanpassen:
| Parameter | Description |
|---|---|
| --num-executors | Hiermee stelt u het aantal uitvoerders in. |
| --executor-cores | Hiermee stelt u het aantal kernen voor elke uitvoerder in. We raden u aan middelgrote uitvoerders te gebruiken, omdat andere processen ook een deel van het beschikbare geheugen verbruiken. |
| --executor-memory | Hiermee bepaalt u de geheugengrootte (heapgrootte) van elke uitvoerder op Apache Hadoop YARN en moet u wat geheugen overlaten voor de overhead van de uitvoering. |
Hier volgt een voorbeeld van twee werkknooppunten met verschillende configuratiewaarden:

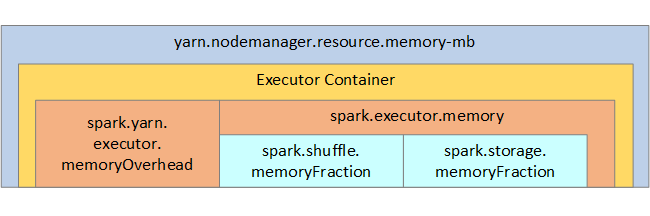
In de volgende lijst ziet u de belangrijkste spark-uitvoerdersgeheugenparameters.
| Parameter | Description |
|---|---|
| spark.executor.memory | Hiermee definieert u de totale hoeveelheid geheugen die beschikbaar is voor een uitvoerder. |
| spark.storage.memoryFraction | (standaard ~60%) definieert de hoeveelheid geheugen die beschikbaar is voor het opslaan van persistente RDD's. |
| spark.shuffle.memoryFraction | (standaard ~20%) definieert de hoeveelheid geheugen die is gereserveerd voor willekeurige volgorde. |
| spark.storage.unrollFraction en spark.storage.safetyFraction | (totaal van ~30% van het totale geheugen) - deze waarden worden intern gebruikt door Spark en mogen niet worden gewijzigd. |
YARN bepaalt de maximale som van het geheugen dat door de containers op elk Spark-knooppunt wordt gebruikt. In het volgende diagram ziet u de relaties per knooppunt tussen YARN-configuratieobjecten en Spark-objecten.
Parameters wijzigen voor een toepassing die wordt uitgevoerd in Jupyter Notebook
Spark-clusters in HDInsight bevatten standaard een aantal onderdelen. Elk van deze onderdelen bevat standaardconfiguratiewaarden, die indien nodig kunnen worden overschreven.
| Onderdeel | Beschrijving |
|---|---|
| Spark Core | Spark Core, Spark SQL, Spark streaming-API's, GraphX en Apache Spark MLlib. |
| Anaconda | Een Python-pakketbeheerder. |
| Apache Livy | De Apache Spark REST API, die wordt gebruikt voor het verzenden van externe taken naar een HDInsight Spark-cluster. |
| Jupyter Notebooks en Apache Zeppelin Notebooks | Interactieve browsergebruikersinterface voor interactie met uw Spark-cluster. |
| ODBC-stuurprogramma | Verbindt Spark-clusters in HDInsight met bi-hulpprogramma's (business intelligence), zoals Microsoft Power BI en Tableau. |
Voor toepassingen die worden uitgevoerd in Jupyter Notebook, gebruikt u de %%configure opdracht om configuratiewijzigingen aan te brengen vanuit het notebook zelf. Deze configuratiewijzigingen worden toegepast op de Spark-taken die worden uitgevoerd vanuit uw notebook-exemplaar. Breng dergelijke wijzigingen aan aan het begin van de toepassing voordat u uw eerste codecel uitvoert. De gewijzigde configuratie wordt toegepast op de Livy-sessie wanneer deze wordt gemaakt.
Notitie
Als u de configuratie in een later stadium in de toepassing wilt wijzigen, gebruikt u de -f parameter (force). Alle voortgang in de toepassing gaat echter verloren.
De onderstaande code laat zien hoe u de configuratie voor een toepassing die wordt uitgevoerd in een Jupyter Notebook wijzigt.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Conclusie
Bewaak de kernconfiguratie-instellingen om ervoor te zorgen dat uw Spark-taken op een voorspelbare en performante manier worden uitgevoerd. Deze instellingen helpen bij het bepalen van de beste Spark-clusterconfiguratie voor uw specifieke workloads. U moet ook de uitvoering van langlopende en, of resource-verbruikende Spark-taakuitvoeringen bewaken. De meest voorkomende uitdagingen zijn gericht op geheugendruk van onjuiste configuraties, zoals uitvoerders met een onjuiste grootte. Ook langlopende bewerkingen en taken, wat resulteert in Cartesische bewerkingen.