Quickstart: Een Apache Spark-cluster maken in Azure HDInsight met behulp van een ARM-sjabloon
In deze quickstart gebruikt u een Azure Resource Manager-sjabloon (ARM-sjabloon) om een Apache Spark-cluster te maken in Azure HDInsight. Vervolgens maakt u een Jupyter Notebook-bestand en gebruikt u dit om Spark SQL-query's uit te voeren voor Apache Hive-tabellen. Azure HDInsight is een beheerde, zeer uitgebreide open-source analyseservice voor bedrijven. Het Apache Spark-raamwerk voor HDInsight maakt het mogelijk om snelle gegevensanalyses en clusterberekeningen uit te voeren met behulp van verwerking in het geheugen. Via Jupyter Notebook kunt u met uw gegevens werken, code combineren met markdown-tekst en eenvoudige visualisaties uitvoeren.
Als u meerdere clusters tegelijk gebruikt, wilt u een virtueel netwerk maken. Als u een Spark-cluster gebruikt, wilt u ook de Hive Warehouse Connector gebruiken. Zie Plan a virtual network voor Azure HDInsight en Integrate Apache Spark and Apache Hive with the Hive Warehouse Connector voor meer informatie.
Een Azure Resource Manager-sjabloon is een JSON-bestand (JavaScript Object Notation) dat de infrastructuur en configuratie voor uw project definieert. Voor de sjabloon is declaratieve syntaxis vereist. U beschrijft de beoogde implementatie zonder de reeks programmeeropdrachten te schrijven om de implementatie te maken.
Als uw omgeving voldoet aan de vereisten en u benkend bent met het gebruik van ARM-sjablonen, selecteert u de knop Implementeren naar Azure. De sjabloon wordt in Azure Portal geopend.

Vereisten
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
De sjabloon controleren
De sjabloon die in deze quickstart wordt gebruikt, komt uit Azure-snelstartsjablonen.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
Er worden twee Azure-resources gedefinieerd in de sjabloon:
- Microsoft.Storage/storageAccounts: een Azure Storage-account maken.
- Microsoft.HDInsight/cluster: een HDInsight-cluster maken.
De sjabloon implementeren
Selecteer de knop Implementeren in Azure onderaan om u aan te melden bij Azure en de ARM-sjabloon te openen.
Typ of selecteer de volgende waarden:
Eigenschap Beschrijving Abonnement Selecteer in de vervolgkeuzelijst het Azure-abonnement dat wordt gebruikt voor het cluster. Resourcegroep Selecteer in de vervolgkeuzelijst de bestaande resourcegroep of selecteer Nieuwe maken. Locatie De waarde wordt automatisch ingevuld met de locatie die wordt gebruikt voor de resourcegroep. Clusternaam Voer een wereldwijd unieke naam in. Gebruik voor deze sjabloon alleen kleine letters en cijfers. Gebruikersnaam voor clusteraanmelding Geef de gebruikersnaam op, de standaardwaarde is admin.Wachtwoord voor clusteraanmelding Geef een wachtwoord op. Het wachtwoord moet minstens 10 tekens lang zijn en moet ten minste één cijfer, één hoofdletter en één kleine letter, één niet-alfanumerieke teken (behalve tekens ' ` ") bevatten.Ssh-gebruikersnaam Geef de gebruikersnaam op, de standaardwaarde is sshuser.Ssh-wachtwoord Geef het wachtwoord op. 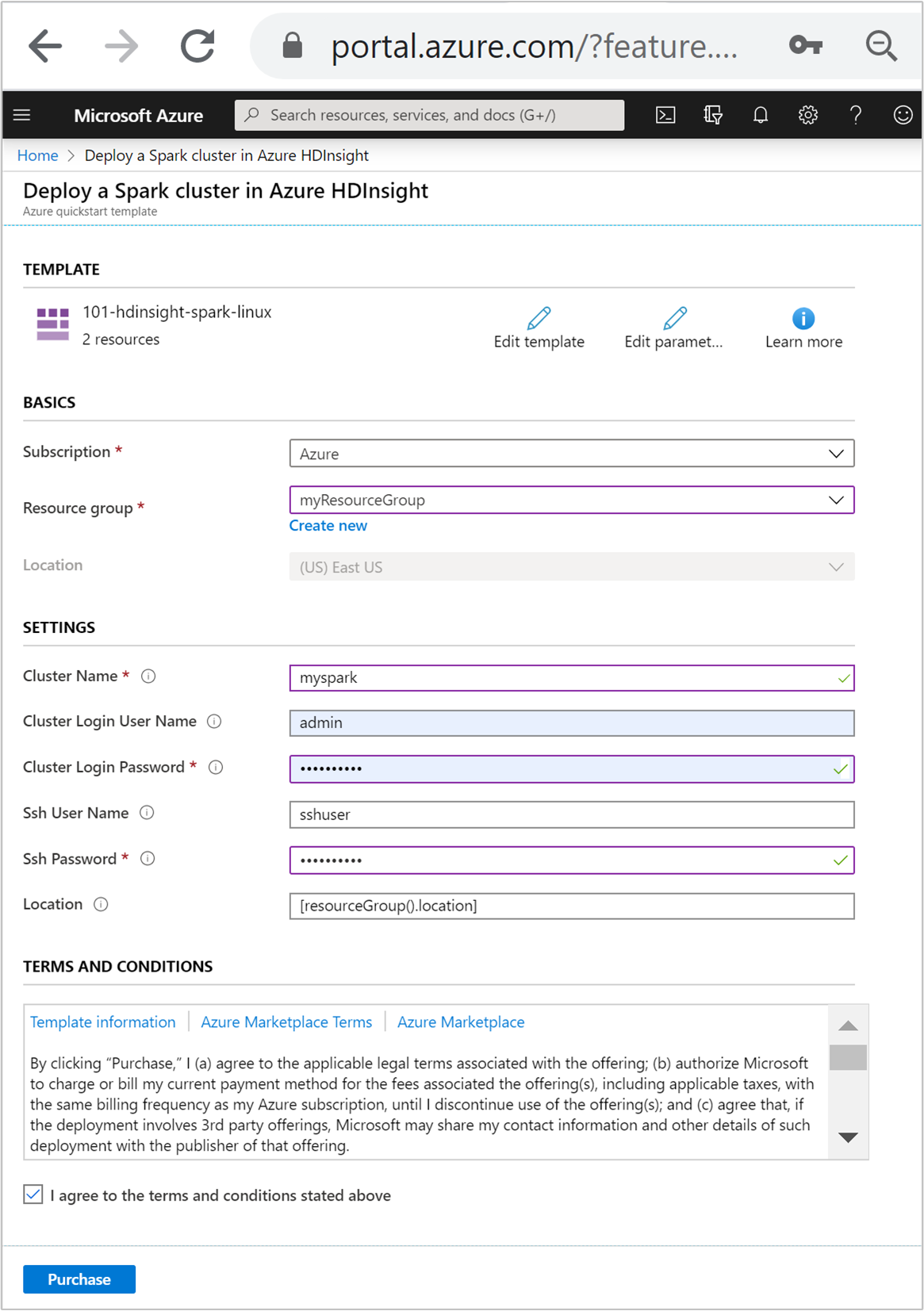
Bekijk de VOORWAARDEN. Selecteer vervolgens Ik ga akkoord met de bovenstaande voorwaarden en daarna Kopen. U ontvangt een melding dat uw implementatie wordt uitgevoerd. Het duurt ongeveer 20 minuten om een cluster te maken.
Als u een probleem ondervindt met het maken van HDInsight-clusters, beschikt u mogelijk niet over de juiste machtigingen om dit te doen. Zie Vereisten voor toegangsbeheer voor meer informatie.
Geïmplementeerde resources bekijken
Zodra het cluster is gemaakt, ontvangt u de melding Implementatie voltooid met de koppeling Naar de resource. Op de pagina Resourcegroep worden uw nieuwe HDInsight-cluster en de standaardopslag bij het cluster weergegeven. Elk cluster heeft een Azure Storage of een Azure Data Lake Storage Gen2 afhankelijkheid. Dit wordt het standaardopslagaccount genoemd. Het HDInsight-cluster en het standaardopslagaccount moeten samen in dezelfde Azure-regio worden geplaatst. De afhankelijkheid van het opslagaccount wordt niet verwijderd wanneer er clusters worden verwijderd. Dit wordt het standaardopslagaccount genoemd. Het HDInsight-cluster en het standaardopslagaccount moeten samen in dezelfde Azure-regio worden geplaatst. Het opslagaccount wordt niet verwijderd wanneer er clusters worden verwijderd.
Een Jupyter Notebook-bestand maken
Jupyter Notebook is een interactieve notitieblokomgeving die ondersteuning biedt voor verschillende programmeertalen. U kunt een Jupyter Notebook-bestand gebruiken om met uw gegevens te werken, code te combineren met markdown-tekst en eenvoudige visualisaties uit te voeren.
Open de Azure Portal.
Selecteer HDInsight-clusters en selecteer vervolgens het cluster dat u hebt gemaakt.

Ga in de portal naar de sectie Clusterdashboards en selecteer Jupyter Notebook. Voer de aanmeldingsreferenties voor het cluster in als u daarom wordt gevraagd.
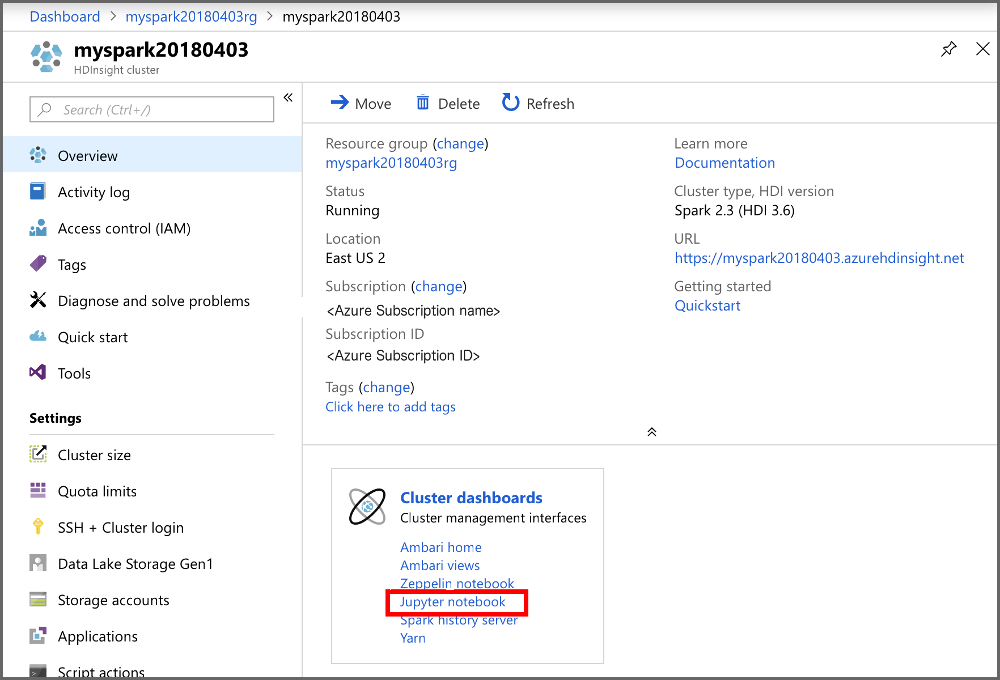
Selecteer Nieuw>PySpark om een notebook te maken.
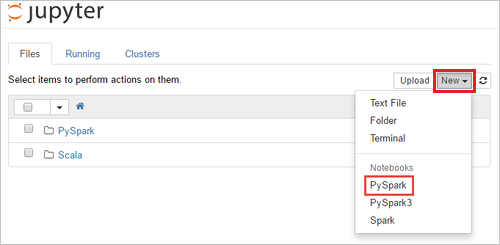
Er wordt een nieuwe notebook gemaakt en geopend met de naam Untitled (Untitled.pynb).
Apache Spark SQL-instructies uitvoeren
SQL (Structured Query Language) is de meest voorkomende en gebruikte taal voor het uitvoeren van query's en het transformeren van gegevens. Spark SQL fungeert als een uitbreiding van Apache Spark voor het verwerken van gestructureerde gegevens, met behulp van de bekende SQL-syntaxis.
Controleer of de kernel gereed is. Wanneer u een lege cirkel naast de naam van de kernel in de notebook ziet, is de kernel gereed. Gevulde cirkel geeft aan dat de kernel bezet is.
 alt-text="Kernelstatus."border="true":::
alt-text="Kernelstatus."border="true":::Wanneer u de notebook voor het eerst start, voert de kernel enkele taken in de achtergrond uit. Wacht tot de kernel gereed is.
Plak de volgende code in een lege cel en druk op Shift+Enter om de code uit te voeren. Met de opdracht worden de Hive-tabellen in het cluster weergegeven:
%%sql SHOW TABLESWanneer u een Jupyter Notebook-bestand gebruikt met uw HDInsight-cluster, krijgt u een vooraf ingestelde
spark-sessie waarmee u Hive-query's kunt uitvoeren met behulp van Apache Spark SQL.%%sqlinstrueert Jupyter Notebook om de vooraf ingesteldespark-sessie te gebruiken voor het uitvoeren van de Hive-query. De query haalt de bovenste tien rijen op uit een Hive-tabel (hivesampletable) die standaard worden meegeleverd met alle HDInsight-clusters. De eerste keer dat u de query verzendt, maakt Jupyter een Spark-toepassing voor de notebook. Dit duurt ongeveer 30 seconden. Zodra de Spark-toepassing gereed is, wordt de query uitgevoerd in ongeveer een seconde en worden de resultaten geproduceerd. De uitvoer ziet er als volgt uit: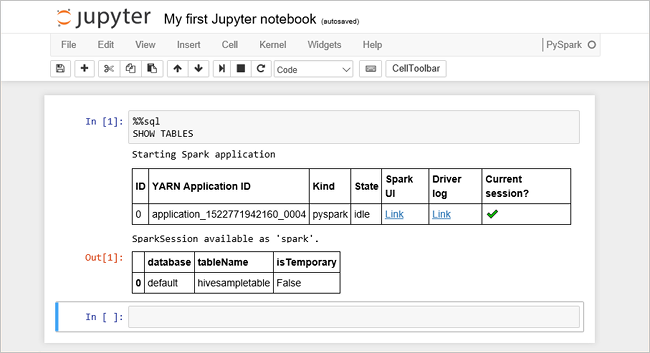 y in HDInsight" border="true":::
y in HDInsight" border="true":::Telkens wanneer u in Jupyter een query uitvoert, toont de venstertitel van uw webbrowser de status (Bezet) en de notebooktitel. Ook ziet u een gevulde cirkel naast de PySpark-tekst in de rechterbovenhoek.
Voer een andere query uit om de gegevens in
hivesampletablete zien.%%sql SELECT * FROM hivesampletable LIMIT 10Het scherm wordt vernieuwd om de query-uitvoer weer te geven.
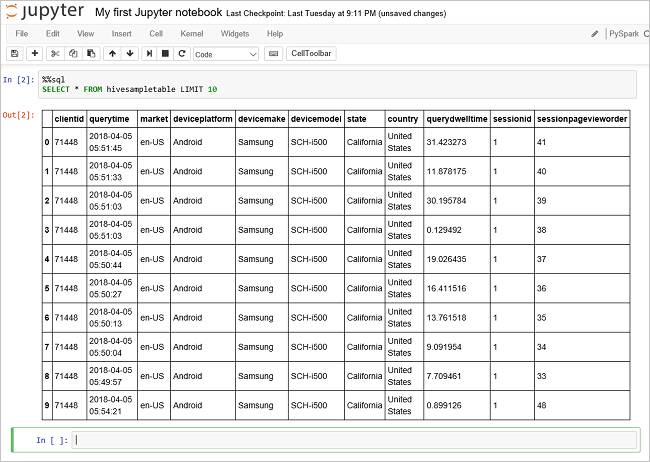 Inzicht" border="true":::
Inzicht" border="true":::Klik in het menu File van het notebook op Close and Halt. Als de notebook wordt afgesloten, komen de clusterbronnen, waaronder de Apache Spark-toepassing, vrij.
Resources opschonen
Nadat u de quickstart hebt voltooid, kunt u het cluster verwijderen. Met HDInsight worden uw gegevens opgeslagen in Azure Storage zodat u een cluster veilig kunt verwijderen wanneer deze niet wordt gebruikt. Voor een HDInsight-cluster worden ook kosten in rekening gebracht, zelfs wanneer het niet wordt gebruikt. Aangezien de kosten voor het cluster vaak zoveel hoger zijn dan de kosten voor opslag, is het financieel gezien logischer clusters te verwijderen wanneer ze niet worden gebruikt.
Ga in de Azure-portal naar het cluster en selecteer Verwijderen.
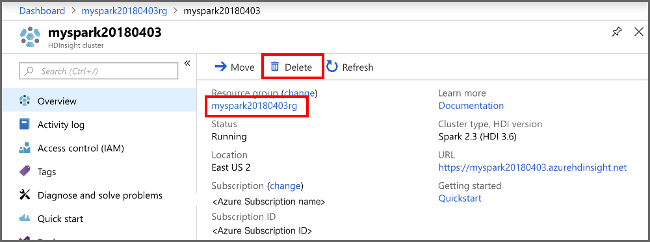 sight cluster" border="true":::
sight cluster" border="true":::
U kunt ook de naam van de resourcegroep selecteren om de pagina van de resourcegroep te openen en vervolgens Resourcegroep verwijderen selecteren. Als u de resourcegroep verwijdert, verwijdert u zowel het HDInsight-cluster als het standaardopslagaccount.
Volgende stappen
In deze snelstart hebt u geleerd hoe u een Apache Spark-cluster in HDInsight maakt en een eenvoudige Spark SQL-query uitvoert. Ga naar de volgende zelfstudie voor informatie over het gebruik van een HDInsight-cluster om interactieve query's uit te voeren op voorbeeldgegevens.