Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie leert u hoe u een gegevensframe maakt van een CSV-bestand en hoe u interactieve Spark SQL-query's uitvoert op een Apache Spark-cluster in Azure HDInsight. In Spark is een gegevensframe een gedistribueerde verzameling gegevens die zijn geordend in benoemde kolommen. Een dataframe is conceptueel equivalent aan een tabel in een relationele database of een dataframe in R/Python.
In deze zelfstudie leert u het volgende:
- Een gegevensframe maken van een CSV-bestand
- Query's uitvoeren op het gegevensframe
Vereisten
Een Apache Spark-cluster in HDInsight. Zie Een Apache Spark-cluster maken.
Een Jupyter Notebook maken
Jupyter Notebook is een interactieve notitieblokomgeving die ondersteuning biedt voor verschillende programmeertalen. Via het notitieblok kunt u interactie hebben met uw gegevens, code combineren met markdown-tekst en eenvoudige visualisaties uitvoeren.
Bewerk URL
https://SPARKCLUSTER.azurehdinsight.net/jupyterdoorSPARKCLUSTERte vervangen door de naam van uw Spark-cluster. Voer vervolgens de bewerkte URL in een webbrowser in. Voer de aanmeldingsreferenties voor het cluster in als u daarom wordt gevraagd.Selecteer op de Jupyter-webpagina de optie Nieuw>PySpark voor de Spark 2.4-clusters om een notebook te maken. Voor de release van Spark 3.1 selecteert u in plaats daarvan New>PySpark3 om een notebook te maken omdat de PySpark-kernel niet meer beschikbaar is in Spark 3.1.
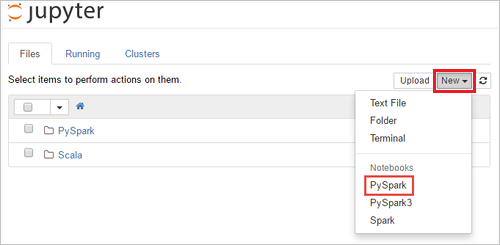
Er wordt een nieuwe notebook gemaakt met de naam Untitled(
Untitled.ipynb) en vervolgens geopend.Notitie
Door de PySpark- of pySpark3-kernel te gebruiken om een notebook te maken, wordt de
sparksessie automatisch voor u gemaakt wanneer u de eerste codecel uitvoert. U hoeft de sessie dus niet expliciet te maken.
Een gegevensframe maken van een CSV-bestand
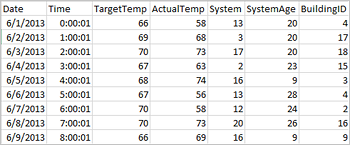
Toepassingen kunnen rechtstreeks vanuit bestanden of mappen op de externe opslag gegevensframes maken, zoals Azure Storage of Azure Data Lake Storage; uit een Hive-tabel; of uit andere gegevensbronnen die worden ondersteund door Spark, zoals Azure Cosmos DB, Azure SQL DB, DW, enzovoort. In de volgende schermafbeelding ziet u een momentopname van het bestand HVAC.csv dat wordt gebruikt in deze zelfstudie. Het CSV-bestand wordt geleverd met alle HDInsight Spark-clusters. De gegevens hebben betrekking op de schommelingen in temperatuur van sommige gebouwen.
Plak de volgende code in een lege cel van het Jupyter-notebook en druk op Shift + Enter om de code uit te voeren. Met de code importeert u de typen die voor dit scenario zijn vereist:
from pyspark.sql import * from pyspark.sql.types import *Wanneer u een interactieve query uitvoert in Jupyter, wordt in het webbrowservenster of tabbladbijschrift een status (Bezet) weergegeven, samen met de titel van het notitieblok. Ook ziet u een gevulde cirkel naast de PySpark-tekst in de rechterbovenhoek. Wanneer de taak is voltooid, verandert deze in een lege cirkel.
Status van interactieve Spark SQL-query.
Noteer de sessie-id die wordt geretourneerd. In de bovenstaande afbeelding is de sessie-id 0. Desgewenst kunt u de details van de sessie ophalen door naar
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementste gaan, waarbij CLUSTERNAME de naam van uw Spark-cluster is en id uw sessie-id-nummer.Voer de volgende code uit om een gegevensframe en een tijdelijke tabel (hvac) te maken.
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Query's uitvoeren op de datanami
Zodra de tabel is gemaakt, kunt u een interactieve query uitvoeren op de gegevens.
Voer de volgende code uit in een lege cel van de notebook:
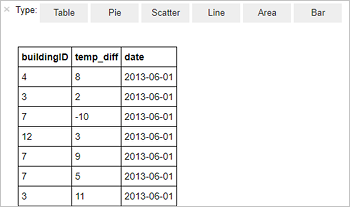
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"De uitvoer wordt weergegeven in een tabel.
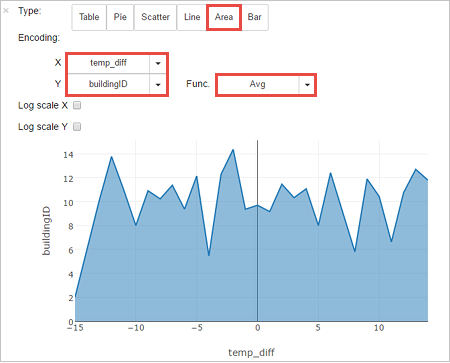
U kunt de resultaten ook in andere visualisaties bekijken. Als u een vlakdiagram wilt zien voor dezelfde uitvoer, selecteert u Area en stelt u de andere waarden in zoals deze worden weergegeven.
Ga vanaf de menubalk van de notebook naar File>Save and Checkpoint.
Als u nu begint met de volgende zelfstudie, laat het notebook openstaan. Anders sluit u het notebook om de clusterresources vrij te geven. Ga hiervoor in de menubalk naar File>Close and Halt.
Resources opruimen
Met HDInsight worden uw gegevens en Jupyter-notebooks opgeslagen in Azure Storage of Azure Data Lake Storage, zodat u een cluster veilig kunt verwijderen wanneer dit niet wordt gebruikt. Voor een HDInsight-cluster worden ook kosten in rekening gebracht, zelfs wanneer het niet wordt gebruikt. Aangezien de kosten voor het cluster vaak zoveel hoger zijn dan de kosten voor opslag, is het financieel gezien logischer clusters te verwijderen wanneer ze niet worden gebruikt. Als u van plan bent om direct verder te gaan met de volgende zelfstudie, wilt u misschien het cluster behouden.
Open het cluster in Azure Portal en selecteer Verwijderen.
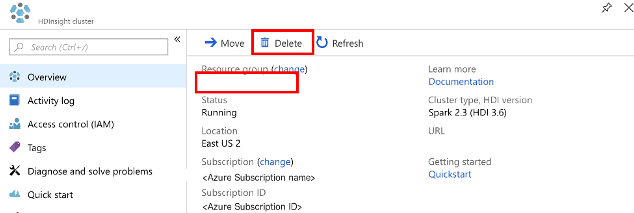
U kunt ook de naam van de resourcegroep selecteren om de pagina van de resourcegroep te openen en vervolgens Resourcegroep verwijderen selecteren. Als u de resourcegroep verwijdert, verwijdert u zowel het HDInsight Spark-cluster als het standaardopslagaccount.
Volgende stappen
In deze zelfstudie hebt u geleerd een gegevensframe te maken van een CSV-bestand en interactieve Spark SQL-query's uit te voeren op een Apache Spark-cluster in Azure HDInsight. Ga naar het volgende artikel om te zien hoe de gegevens die u hebt geregistreerd in Apache Spark kunnen worden overgebracht naar een BI-hulpprogramma voor analyse zoals Power BI.