Zelfstudie: Gegevens van Apache Spark analyseren met Power BI in HDInsight
In deze zelfstudie leert u hoe u Microsoft Power BI kunt gebruiken om gegevens te visualiseren in een Apache Spark-cluster in Azure HDInsight.
In deze zelfstudie leert u het volgende:
- Spark-gegevens visualiseren met behulp van Power BI
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Voltooi het artikel Zelfstudie: Gegevens laden en query's uitvoeren op een Apache Spark-cluster in Azure HDInsight.
Optioneel: Power BI-proefabonnement.
Het Jupyter Notebook dat u hebt gemaakt in de vorige zelfstudie bevat code voor het maken van een hvac-tabel. Deze tabel is gebaseerd op het CSV-bestand dat voor alle HDInsight Spark-clusters beschikbaar is op \HdiSamples\HdiSamples\SensorSampleData\hvac\hvac.csv. Gebruik de volgende procedure om de gegevens te controleren.
Plak de volgende code uit het Jupyter-notebook en druk vervolgens op Shift + Enter. Deze code controleert of de tabellen bestaan.
%%sql SHOW TABLESDe uitvoer ziet er als volgt uit:
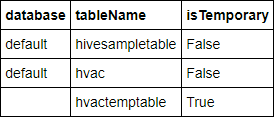
Als u het notebook voorafgaand aan deze zelfstudie hebt gesloten, is
hvactemptableopgeschoond en wordt deze niet opgenomen in de uitvoer. Alleen Hive-tabellen die zijn opgeslagen in de metastore (aangegeven met False in de kolom isTemporary) zijn toegankelijk vanuit de BI-hulpprogramma's. In deze zelfstudie maakt u verbinding met de hvac-tabel die u hebt gemaakt.Plak de volgende code in een lege cel en druk op Shift+Enter. De code controleert de gegevens in de tabel.
%%sql SELECT * FROM hvac LIMIT 10De uitvoer ziet er als volgt uit:
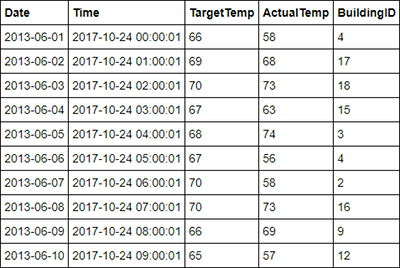
Klik in het menu File van het notebook op Close and Halt. Sluit het notebook om de resources vrij te geven.
In dit gedeelte gebruikt u Power BI om visualisaties, rapporten en dashboards te maken van de gegevens in het Spark-cluster.
De eerste stappen om te werken met Spark zijn verbinding maken met het cluster in Power BI Desktop, gegevens uit het cluster laden en eenvoudige visualisatie maken op basis van die gegevens.
Open Power BI Desktop. Sluit het welkomstscherm als dit wordt geopend.
Ga op het tabblad Start naar Gegevens ophalen>Meer...
Typ
Sparkin het zoekvak, selecteer Azure HDInsight Spark en selecteer vervolgens Verbinding maken.
Voer de cluster-URL (in de vorm
mysparkcluster.azurehdinsight.net) in het tekstvak Server in.Onder Gegevensverbindingsmodus selecteert u DirectQuery. Selecteer vervolgens OK.
U kunt beide gegevensverbindingsmodi gebruiken met Spark. Als u DirectQuery gebruikt, worden wijzigingen doorgevoerd in rapporten zonder dat de hele gegevensset wordt vernieuwd. Als u gegevens importeert, moet u de gegevensset vernieuwen om de wijzigingen te zien. Zie DirectQuery gebruiken in Power BI voor meer informatie over hoe en wanneer u DirectQuery kunt gebruiken.
Voer de gegevens voor het aanmeldingsaccount van HDInsight in en selecteer vervolgens Verbinding maken. De standaardaccountnaam is admin.
Selecteer de tabel
hvac, wacht tot u een voorbeeld van de gegevens ziet en selecteer dan Laden.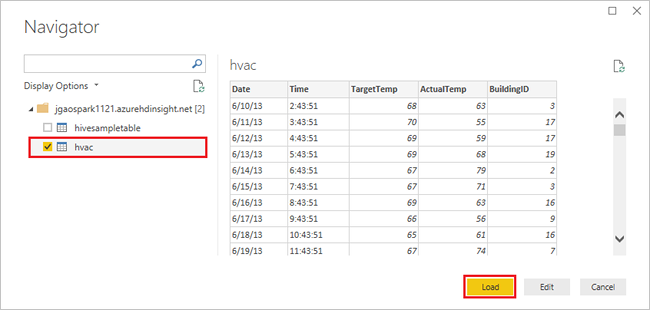
Power BI Desktop beschikt over de gegevens die nodig zijn om verbinding te maken met het Spark-cluster en om gegevens te laden uit de tabel
hvac. De tabel en de kolommen worden weergegeven in het deelvenster Velden.Visualiseer het verschil tussen de gewenste temperatuur en de werkelijke temperatuur voor elk gebouw:
Selecteer Vlakdiagram in het deelvenster Visualisaties.
Sleep het veld BuildingID naar As, en sleep de velden ActualTemp en TargetTemp naar Waarde.
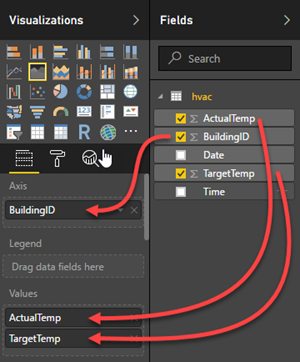
Het diagram ziet er zo uit:
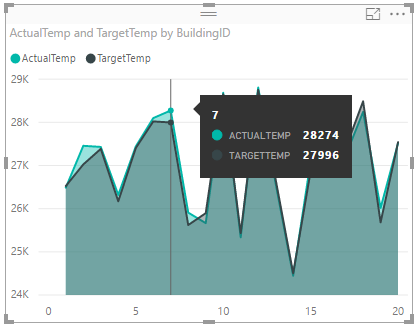
De visualisatie bevat standaard de som van ActualTemp en TargetTemp. Selecteer de pijl-omlaag naast ActualTemp en TargetTemp in het deelvenster Visualisaties. U ziet dat Som is geselecteerd.
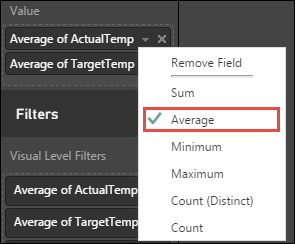
Selecteer de pijl-omlaag naast ActualTemp en TargetTemp in het deelvenster Visualisaties, selecteer Gemiddelde om een gemiddelde van de werkelijke en doeltemperatuur voor elk gebouw op te halen.
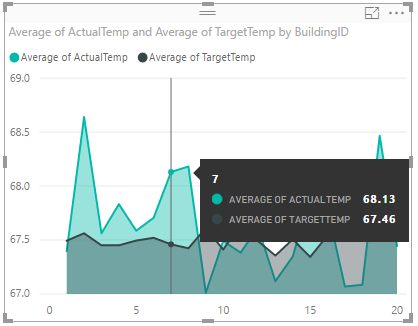
De gegevensvisualisatie moet er ongeveer uitzien zoals in de schermafbeelding. Beweeg de cursor over de visualisatie om knopinfo met relevante gegevens weer te geven.
Ga naar Bestand>Opslaan, voer de naam
BuildingTemperaturevoor het bestand in en selecteer Opslaan.
Met behulp van de Power BI-service kunt u rapporten en dashboards delen binnen uw organisatie. In dit gedeelte gaat u eerst de gegevensset en het rapport publiceren. Vervolgens maakt u het rapport vast aan een dashboard. Dashboards worden voornamelijk gebruikt om te focussen op een subset gegevens in een rapport. U hebt slechts één visualisatie in het rapport, maar het is wel handig om de stappen door te lopen.
Open Power BI Desktop.
Selecteer de optie Publiceren op het tabblad Start.

Selecteer de werkruimte waarnaar u de gegevensset wilt publiceren en rapporteren, en selecteer vervolgens Selecteren. In de volgende afbeelding is de standaardwerkruimte Mijn werkruimte geselecteerd.
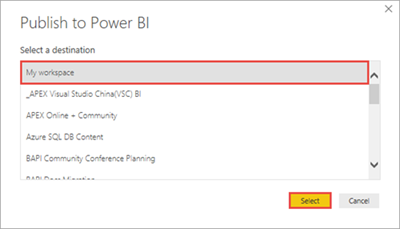
Nadat het publiceren is voltooid, selecteert u 'BuildingTemperature.pbix' openen in Power BI.
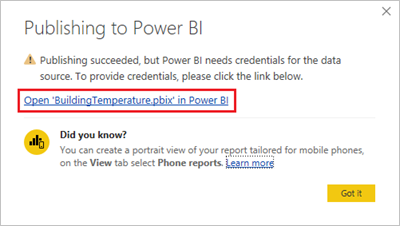
Selecteer in de Power BI-service Referenties invoeren.

Selecteer Referenties bewerken.
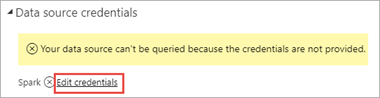
Voer de gegevens voor het aanmeldingsaccount van HDInsight in en selecteer vervolgens Aanmelden. De standaardaccountnaam is admin.
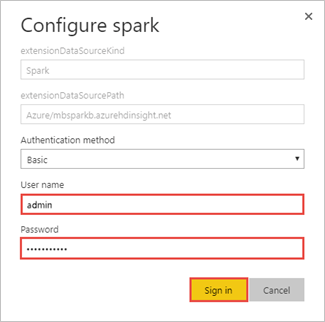
Ga in het linkerdeelvenster naar Werkruimten>Mijn werkruimte>RAPPORTEN en selecteer BuildingTemperature.
Ook moet BuildingTemperature worden vermeld GEGEVENSSETS in het linkerdeelvenster.
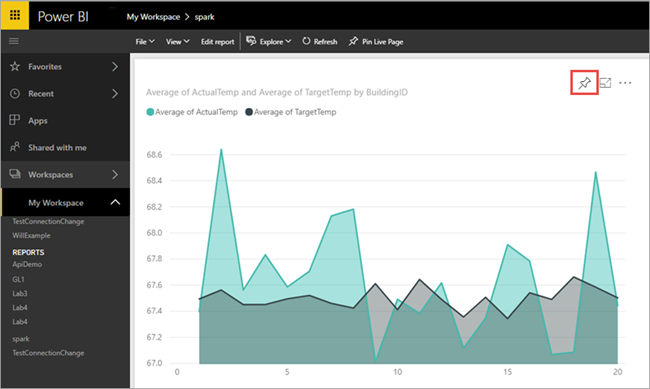
De visualisatie die u hebt gemaakt in Power BI Desktop is nu beschikbaar in de Power BI-service.
Beweeg de cursor over de visualisatie en selecteer vervolgens de speld in de rechterbovenhoek.
Selecteer 'Nieuw dashboard', voer de naam
Building temperaturein en selecteer vervolgens Vastmaken.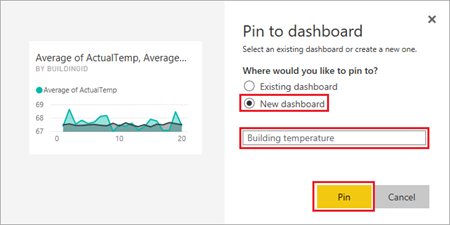
Selecteer in het rapport Naar dashboard.
De visualisatie wordt vastgemaakt aan het dashboard. U kunt andere visualisaties toevoegen aan het rapport en deze aan hetzelfde dashboard vastmaken. Zie Rapporten in Power BI en Dashboards in Power BI voor meer informatie over rapporten en dashboards.
Nadat u de zelfstudie hebt voltooid, kunt u het cluster verwijderen. Met HDInsight worden uw gegevens opgeslagen in Azure Storage zodat u een cluster veilig kunt verwijderen wanneer deze niet wordt gebruikt. Voor een HDInsight-cluster worden ook kosten in rekening gebracht, zelfs wanneer het niet wordt gebruikt. Aangezien de kosten voor het cluster vaak zoveel hoger zijn dan de kosten voor opslag, is het financieel gezien logischer clusters te verwijderen wanneer ze niet worden gebruikt.
Als u een cluster wilt verwijderen, raadpleegt u HDInsight-cluster verwijderen met behulp van uw browser, PowerShell of de Azure CLI.
In deze zelfstudie hebt u geleerd hoe u Microsoft Power BI kunt gebruiken om gegevens te visualiseren in een Apache Spark-cluster in Azure HDInsight. Ga naar het volgende artikel om te zien dat u een machine learning-toepassing kunt maken.