Aan de slag met DICOM-gegevens in analyseworkloads
In dit artikel wordt beschreven hoe u aan de slag gaat met DICOM-gegevens® in analyseworkloads met Azure Data Factory en Microsoft Fabric.
Vereisten
Voer deze stappen uit voordat u aan de slag gaat:
- Maak een opslagaccount met azure Data Lake Storage Gen2-mogelijkheden door een hiërarchische naamruimte in te schakelen:
- Maak een container voor het opslaan van DICOM-metagegevens, bijvoorbeeld met de naam
dicom.
- Maak een container voor het opslaan van DICOM-metagegevens, bijvoorbeeld met de naam
- Implementeer een exemplaar van de DICOM-service.
- (Optioneel) Implementeer de DICOM-service met Data Lake Storage om directe toegang tot DICOM-bestanden mogelijk te maken.
- Een Data Factory-exemplaar maken:
- Schakel een door het systeem toegewezen beheerde identiteit in.
- Maak een lakehouse in Fabric.
- Voeg roltoewijzingen toe aan de door het Data Factory-systeem toegewezen beheerde identiteit voor de DICOM-service en het Data Lake Storage Gen2-opslagaccount:
- Voeg de rol DICOM-gegevenslezer toe om machtigingen te verlenen aan de DICOM-service.
- Voeg de rol Inzender voor opslagblobgegevens toe om toestemming te verlenen aan het Data Lake Storage Gen2-account.
Een Data Factory-pijplijn configureren voor de DICOM-service
In dit voorbeeld wordt een Data Factory-pijplijn gebruikt voor het schrijven van DICOM-kenmerken voor exemplaren, reeksen en onderzoeken naar een opslagaccount in een Delta-tabelindeling.
Open in Azure Portal het Data Factory-exemplaar en selecteer Start studio om te beginnen.

Gekoppelde services maken
Data Factory-pijplijnen lezen uit gegevensbronnen en schrijven naar gegevenssinks. Dit zijn doorgaans andere Azure-services. Deze verbindingen met andere services worden beheerd als gekoppelde services.
De pijplijn in dit voorbeeld leest gegevens uit een DICOM-service en schrijft de uitvoer naar een opslagaccount, dus er moet een gekoppelde service worden gemaakt voor beide.
Een gekoppelde service maken voor de DICOM-service
Selecteer beheren in Azure Data Factory Studio in het menu aan de linkerkant. Selecteer Onder Verbindingen gekoppelde services en selecteer vervolgens Nieuw.
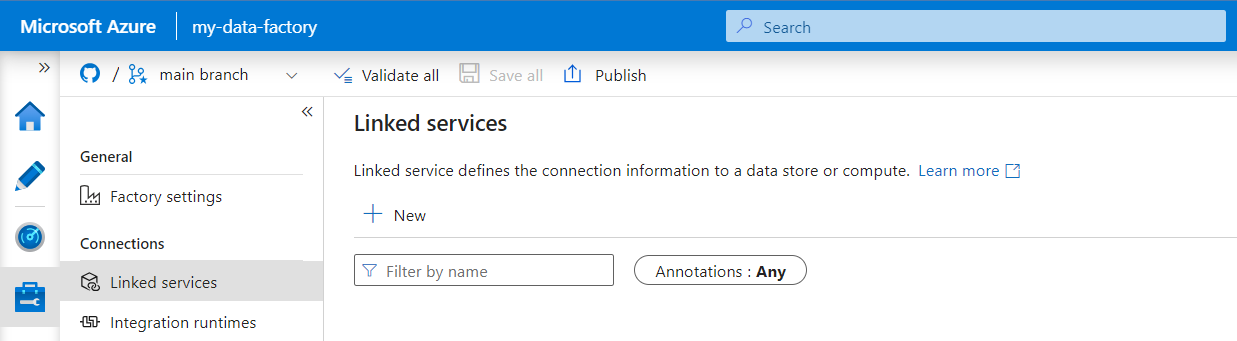
Zoek in het deelvenster Nieuwe gekoppelde service naar REST. Selecteer de REST-tegel en selecteer vervolgens Doorgaan.
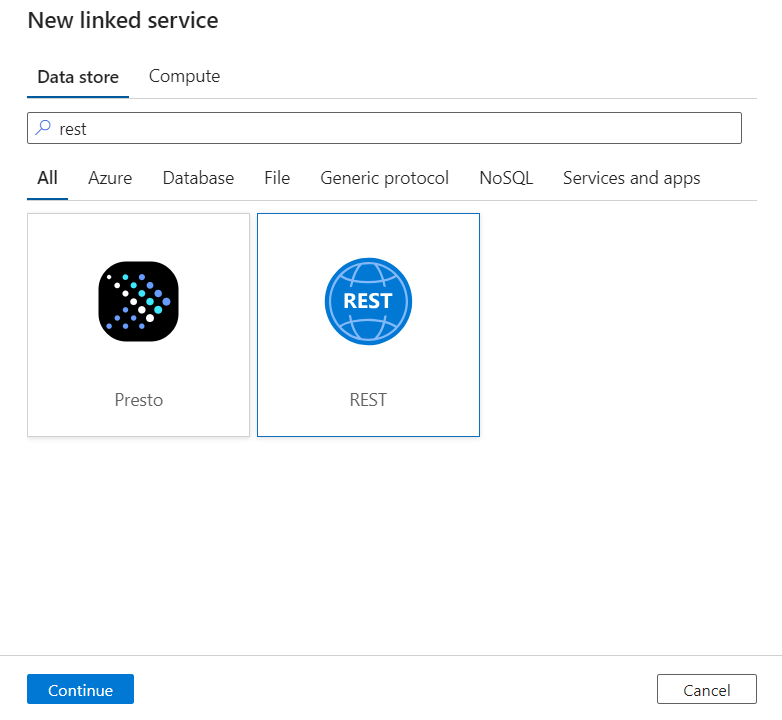
Voer een naam en beschrijving in voor de gekoppelde service.
Voer in het veld Basis-URL de service-URL voor uw DICOM-service in. Een DICOM-service met de naam
contosoclinicin decontosohealthwerkruimte heeft bijvoorbeeld de service-URLhttps://contosohealth-contosoclinic.dicom.azurehealthcareapis.com.Voor verificatietype selecteert u Door het systeem toegewezen beheerde identiteit.
Voer voor AAD-resource de naam in
https://dicom.healthcareapis.azure.com. Deze URL is hetzelfde voor alle DICOM-service-exemplaren.Nadat u de vereiste velden hebt ingevuld, selecteert u Verbinding testen om ervoor te zorgen dat de rollen van de identiteit correct zijn geconfigureerd.
Wanneer de verbindingstest is geslaagd, selecteert u Maken.



Een gekoppelde service maken voor Azure Data Lake Storage Gen2
Selecteer beheren in Data Factory Studio in het menu aan de linkerkant. Selecteer Onder Verbindingen gekoppelde services en selecteer vervolgens Nieuw.
Zoek in het deelvenster Nieuwe gekoppelde service naar Azure Data Lake Storage Gen2. Selecteer de tegel Azure Data Lake Storage Gen2 en selecteer vervolgens Doorgaan.
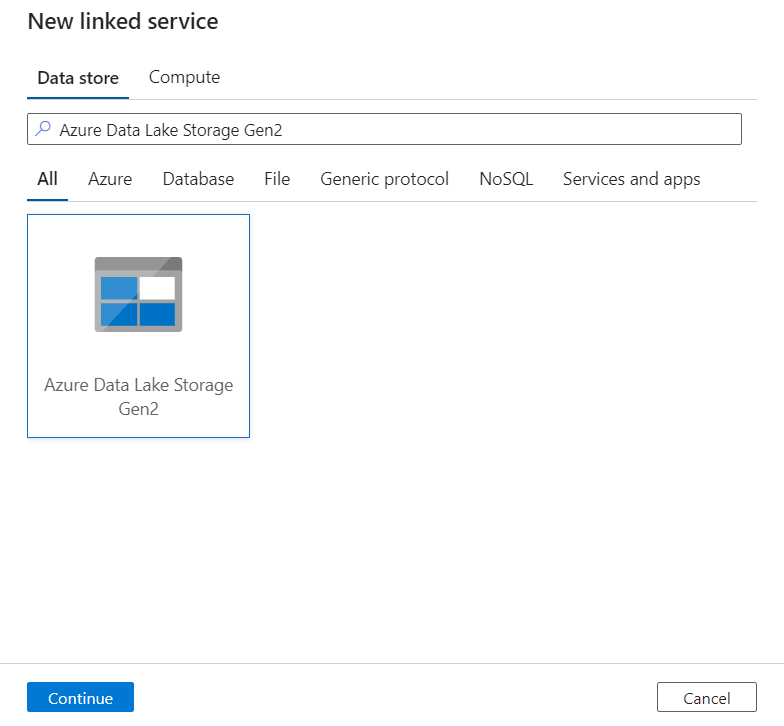
Voer een naam en beschrijving in voor de gekoppelde service.
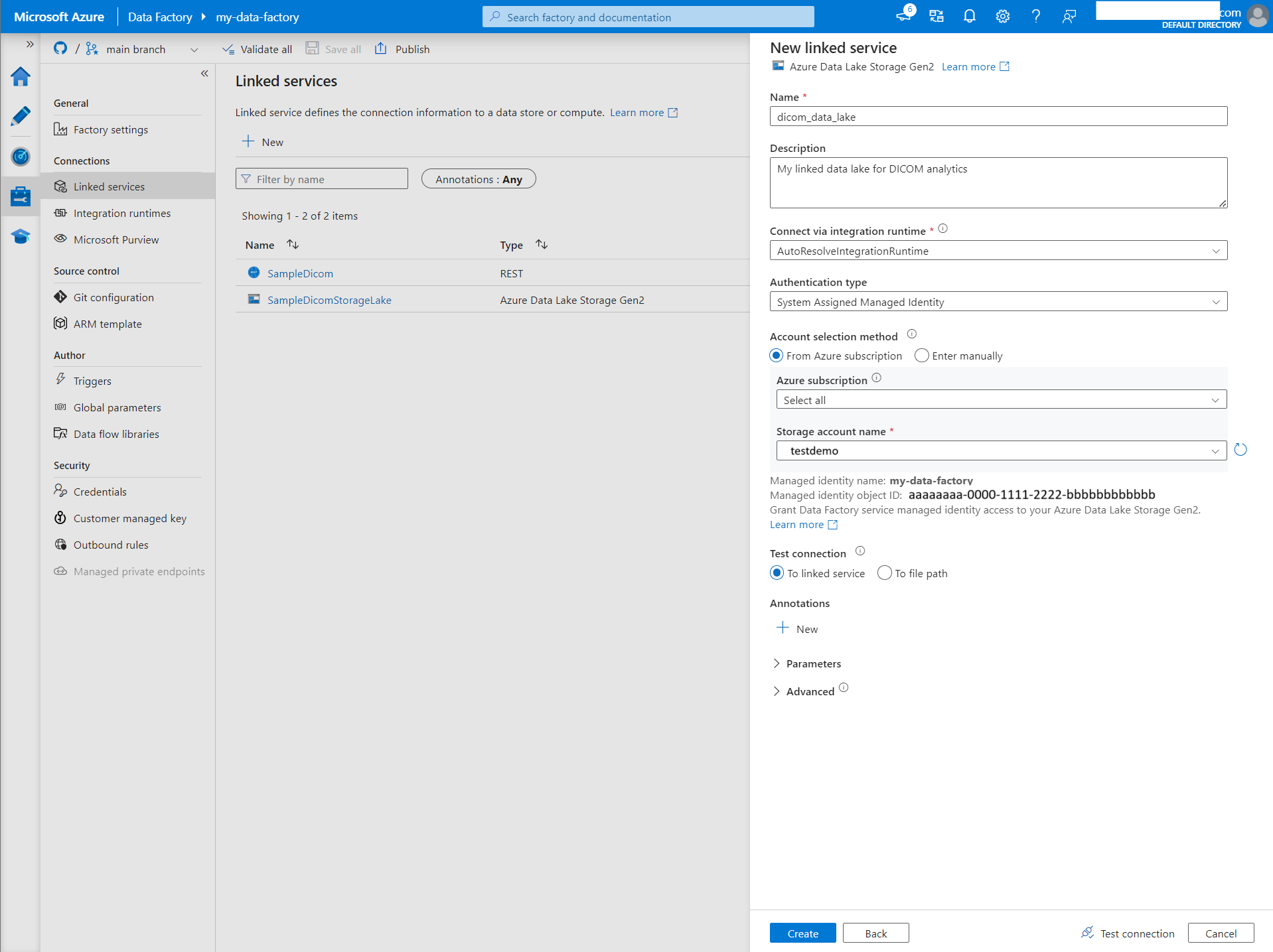
Voor verificatietype selecteert u Door het systeem toegewezen beheerde identiteit.
Voer de gegevens van het opslagaccount in door de URL handmatig in te voeren voor het opslagaccount. U kunt ook het Azure-abonnement en het opslagaccount selecteren in de vervolgkeuzelijsten.
Nadat u de vereiste velden hebt ingevuld, selecteert u Verbinding testen om ervoor te zorgen dat de rollen van de identiteit correct zijn geconfigureerd.
Wanneer de verbindingstest is geslaagd, selecteert u Maken.


Een pijplijn maken voor DICOM-gegevens
Data Factory-pijplijnen zijn een verzameling activiteiten die een taak uitvoeren, zoals het kopiëren van DICOM-metagegevens naar Delta-tabellen. In deze sectie wordt beschreven hoe u een pijplijn maakt waarmee DICOM-gegevens regelmatig worden gesynchroniseerd met Delta-tabellen wanneer gegevens worden toegevoegd aan, bijgewerkt en verwijderd uit een DICOM-service.
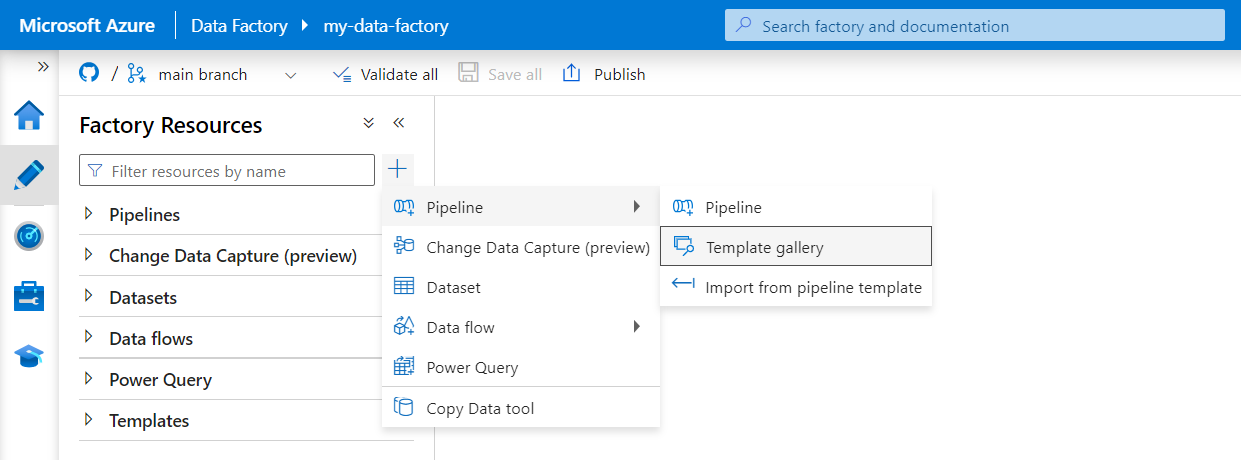
Selecteer Auteur in het menu aan de linkerkant. Selecteer in het deelvenster Factory-resources het plusteken (+) om een nieuwe resource toe te voegen. Selecteer Pijplijn en selecteer vervolgens Sjabloongalerie in het menu.
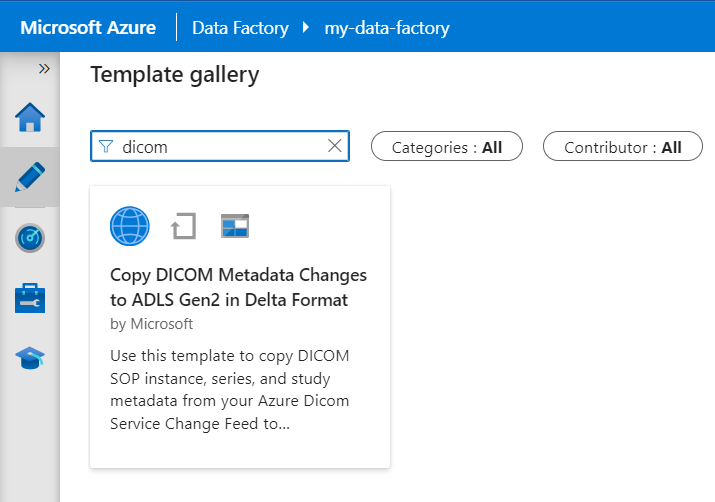
Zoek in de galerie Met sjablonen naar DICOM. Selecteer de tegel DICOM-metagegevenswijzigingen kopiëren naar ADLS Gen2 in Delta-indeling en selecteer vervolgens Doorgaan.
Selecteer in de sectie Invoer de gekoppelde services die eerder zijn gemaakt voor de DICOM-service en het Data Lake Storage Gen2-account.
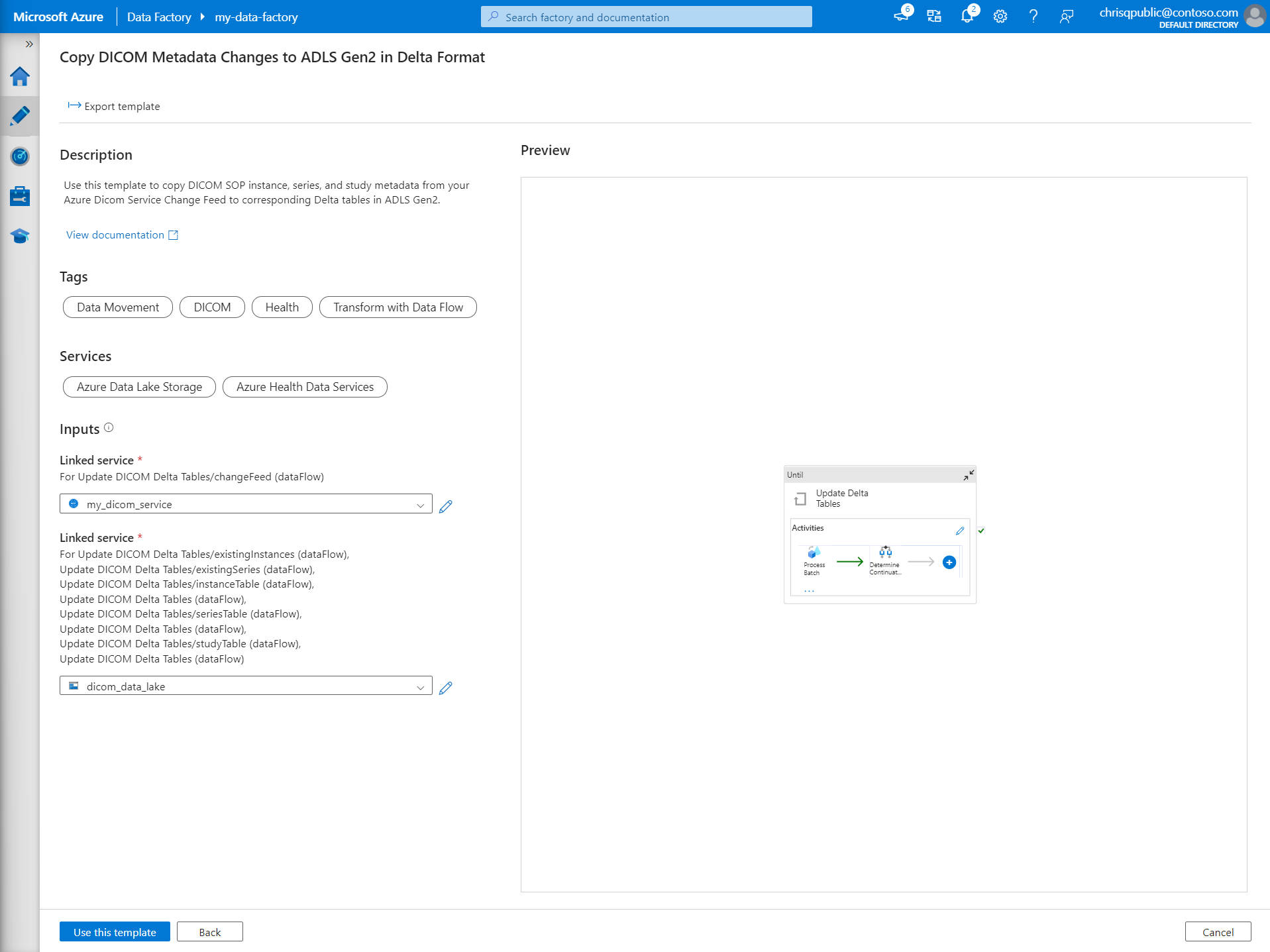
Selecteer Deze sjabloon gebruiken om de nieuwe pijplijn te maken.



Een pijplijn maken voor DICOM-gegevens
Als u de DICOM-service met Azure Data Lake Storage hebt gemaakt in plaats van de sjabloon uit de galerie met sjablonen te gebruiken, moet u een aangepaste sjabloon gebruiken om een nieuwe fileName parameter op te nemen in de metagegevenspijplijn. Volg deze stappen om de pijplijn te configureren.
Download de sjabloon vanuit GitHub. Het sjabloonbestand is een gecomprimeerde (gezipte) map. U hoeft de bestanden niet te extraheren omdat ze al zijn geüpload in gecomprimeerde vorm.
In Azure Data Factory selecteert u Auteur in het menu links. Selecteer in het deelvenster Factory-resources het plusteken (+) om een nieuwe resource toe te voegen. Selecteer Pijplijn en selecteer Vervolgens Importeren uit pijplijnsjabloon.
Selecteer in het venster Openen de sjabloon die u hebt gedownload. Selecteer Openen.
Selecteer in de sectie Invoer de gekoppelde services die zijn gemaakt voor de DICOM-service en het Azure Data Lake Storage Gen2-account.
Selecteer Deze sjabloon gebruiken om de nieuwe pijplijn te maken.
Een pijplijn plannen
Pijplijnen worden gepland door triggers. Er zijn verschillende soorten triggers. Met schematriggers kunnen pijplijnen worden geactiveerd op specifieke tijdstippen van de dag, zoals elk uur of elke dag om middernacht. Handmatige triggers activeren pijplijnen op aanvraag, wat betekent dat ze worden uitgevoerd wanneer u ze wilt.
In dit voorbeeld wordt een tumblingvenstertrigger gebruikt om de pijplijn periodiek uit te voeren op basis van een beginpunt en een regelmatig tijdsinterval. Zie Pijplijnuitvoering en triggers in Azure Data Factory of Azure Synapse Analytics voor meer informatie over triggers.
Een nieuwe tumblingvenstertrigger maken
Selecteer Auteur in het menu aan de linkerkant. Selecteer de pijplijn voor de DICOM-service en selecteer Trigger toevoegen en Nieuw/Bewerken in de menubalk.
Selecteer in het deelvenster Triggers toevoegen de vervolgkeuzelijst Trigger kiezen en selecteer Vervolgens Nieuw.
Voer een naam en beschrijving in voor de trigger.
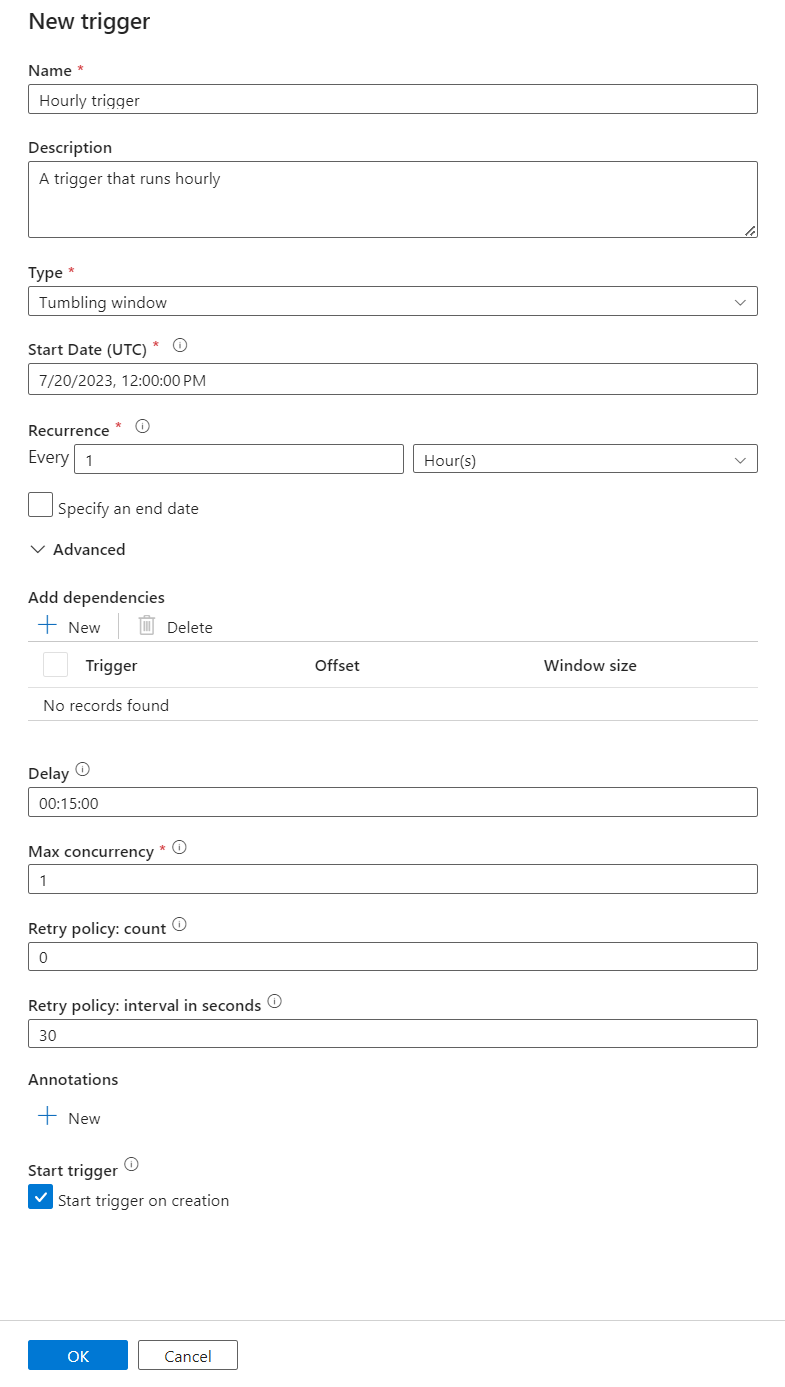
Selecteer Tumblingvenster als het type.
Als u een pijplijn wilt configureren die elk uur wordt uitgevoerd, stelt u het terugkeerpatroon in op 1 uur.
Vouw de sectie Geavanceerd uit en voer een vertraging van 15 minuten in. Met deze instelling kunnen alle bewerkingen die in behandeling zijn aan het einde van een uur worden voltooid voordat de verwerking wordt voltooid.
Stel Maximale gelijktijdigheid in op 1 om consistentie tussen tabellen te garanderen.
Selecteer OK om door te gaan met het configureren van de parameters voor de triggeruitvoering.


Parameters voor triggeruitvoering configureren
Triggers definiëren wanneer een pijplijn wordt uitgevoerd. Ze bevatten ook parameters die worden doorgegeven aan de pijplijnuitvoering. Met de dicom-metagegevenswijzigingen kopiëren naar de Delta-sjabloon worden parameters gedefinieerd die in de volgende tabel worden beschreven. Als er tijdens de configuratie geen waarde wordt opgegeven, wordt de vermelde standaardwaarde gebruikt voor elke parameter.
| Parameternaam | Beschrijving | Default value |
|---|---|---|
| BatchSize | Het maximum aantal wijzigingen dat moet worden opgehaald uit de wijzigingenfeed (maximaal 200) | 200 |
| ApiVersion | De API-versie voor de Azure DICOM-service (minimaal 2) | 2 |
| StartTime | De inclusieve begintijd voor DICOM-wijzigingen | 0001-01-01T00:00:00Z |
| EndTime | De exclusieve eindtijd voor DICOM-wijzigingen | 9999-12-31T23:59:59Z |
| ContainerName | De containernaam voor de resulterende Delta-tabellen | dicom |
| InstanceTablePath | Het pad dat de Delta-tabel voor DICOM SOP-exemplaren in de container bevat | instance |
| SeriesTablePath | Het pad dat de Delta-tabel voor DICOM-serie in de container bevat | series |
| StudyTablePath | Het pad dat de Delta-tabel bevat voor DICOM-studies binnen de container | study |
| RetentionHours | De maximale retentie in uren voor gegevens in de Delta-tabellen | 720 |
Voer in het deelvenster Parameters voor triggeruitvoering de ContainerName-waarde in die overeenkomt met de naam van de opslagcontainer die is gemaakt in de vereisten.
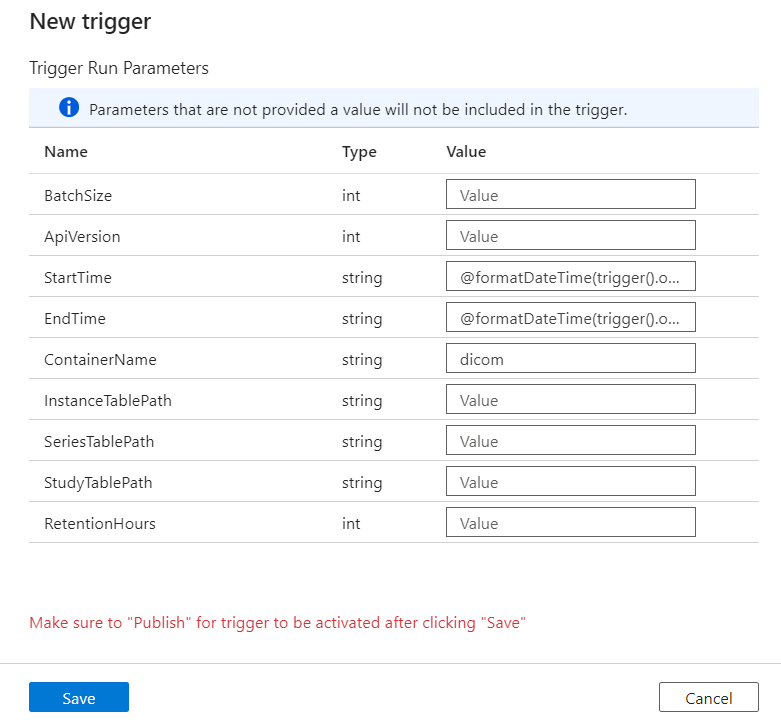
Gebruik voor StartTime de systeemvariabele
@formatDateTime(trigger().outputs.windowStartTime).Gebruik voor EndTime de systeemvariabele
@formatDateTime(trigger().outputs.windowEndTime).Notitie
Alleen tumblingvenstertriggers ondersteunen de systeemvariabelen:
@trigger().outputs.windowStartTimeen@trigger().outputs.windowEndTime.
Schematriggers gebruiken verschillende systeemvariabelen:
@trigger().scheduledTimeen@trigger().startTime.
Meer informatie over triggertypen.
Selecteer Opslaan om de nieuwe trigger te maken. Selecteer Publiceren om de trigger te starten die wordt uitgevoerd volgens de gedefinieerde planning.


Nadat de trigger is gepubliceerd, kan deze handmatig worden geactiveerd met behulp van de optie Nu activeren. Als de begintijd is ingesteld voor een waarde in het verleden, wordt de pijplijn onmiddellijk gestart.
Pijplijnuitvoeringen controleren
U kunt geactiveerde uitvoeringen en de bijbehorende pijplijnuitvoeringen bewaken op het tabblad Monitor . Hier kunt u bladeren wanneer elke pijplijn werd uitgevoerd en hoe lang het duurde om deze uit te voeren. U kunt ook mogelijke problemen opsporen die zijn ontstaan.

Microsoft Fabric
Fabric is een alles-in-één analyseoplossing die zich boven op Microsoft OneLake bevindt. Met behulp van een Fabric Lakehouse kunt u gegevens in OneLake op één locatie beheren, structuren en analyseren. Alle gegevens buiten OneLake, geschreven naar Data Lake Storage Gen2, kunnen met behulp van snelkoppelingen worden verbonden met OneLake om te profiteren van de suite met hulpprogramma's van Fabric.
Snelkoppelingen maken naar metagegevenstabellen
Ga naar het lakehouse dat is gemaakt in de vereisten. Selecteer in de Verkenner-weergave het beletseltekenmenu (...) naast de map Tabellen .
Selecteer Nieuwe snelkoppeling om een nieuwe snelkoppeling te maken naar het opslagaccount dat de DICOM-analysegegevens bevat.
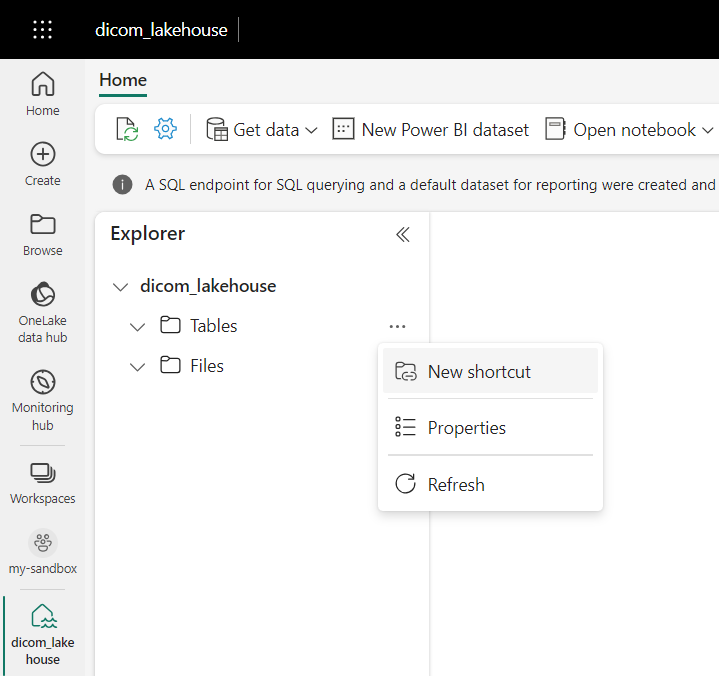
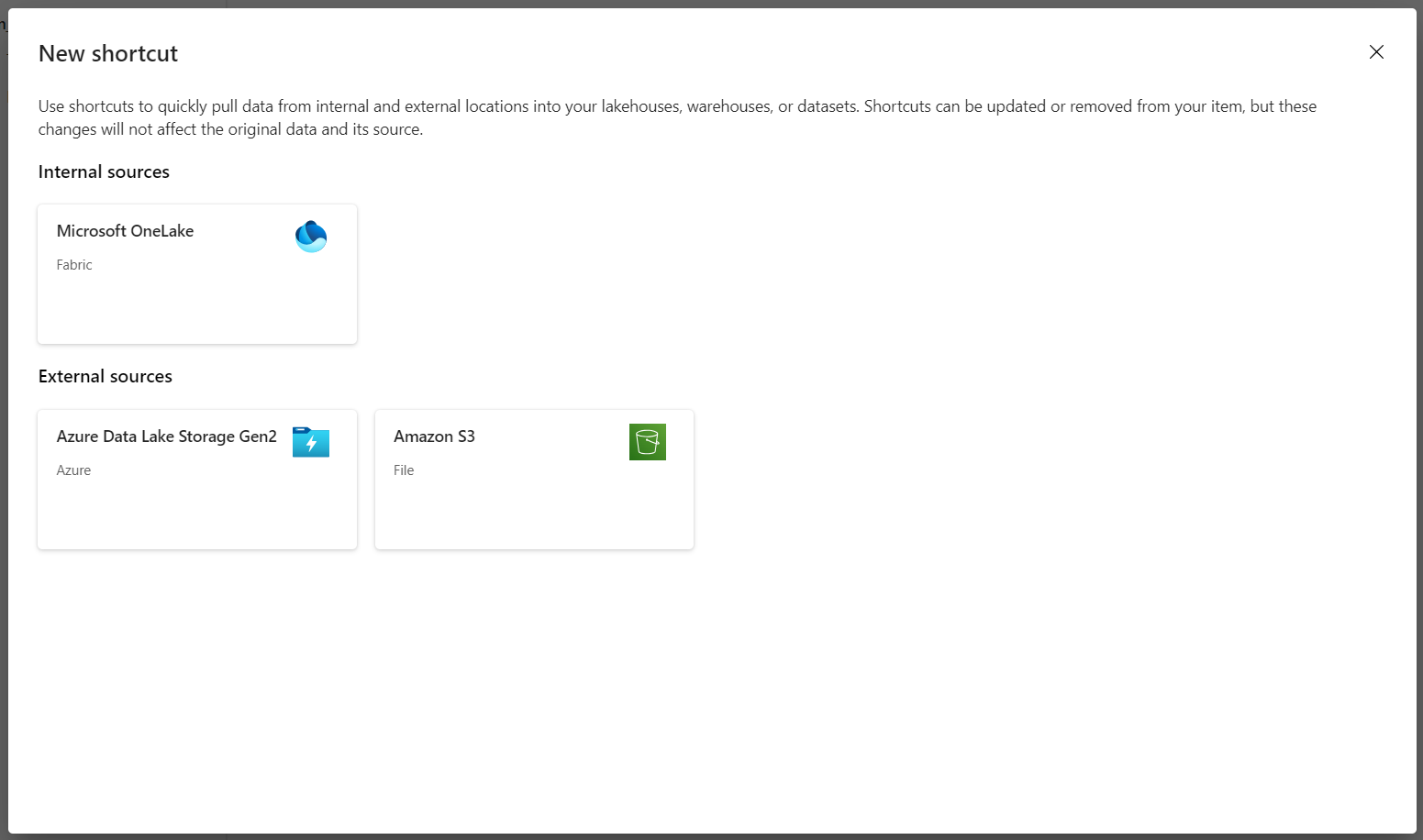
Selecteer Azure Data Lake Storage Gen2 als bron voor de snelkoppeling.
Voer onder Verbindingsinstellingen de URL in die u hebt gebruikt in de sectie Gekoppelde services .
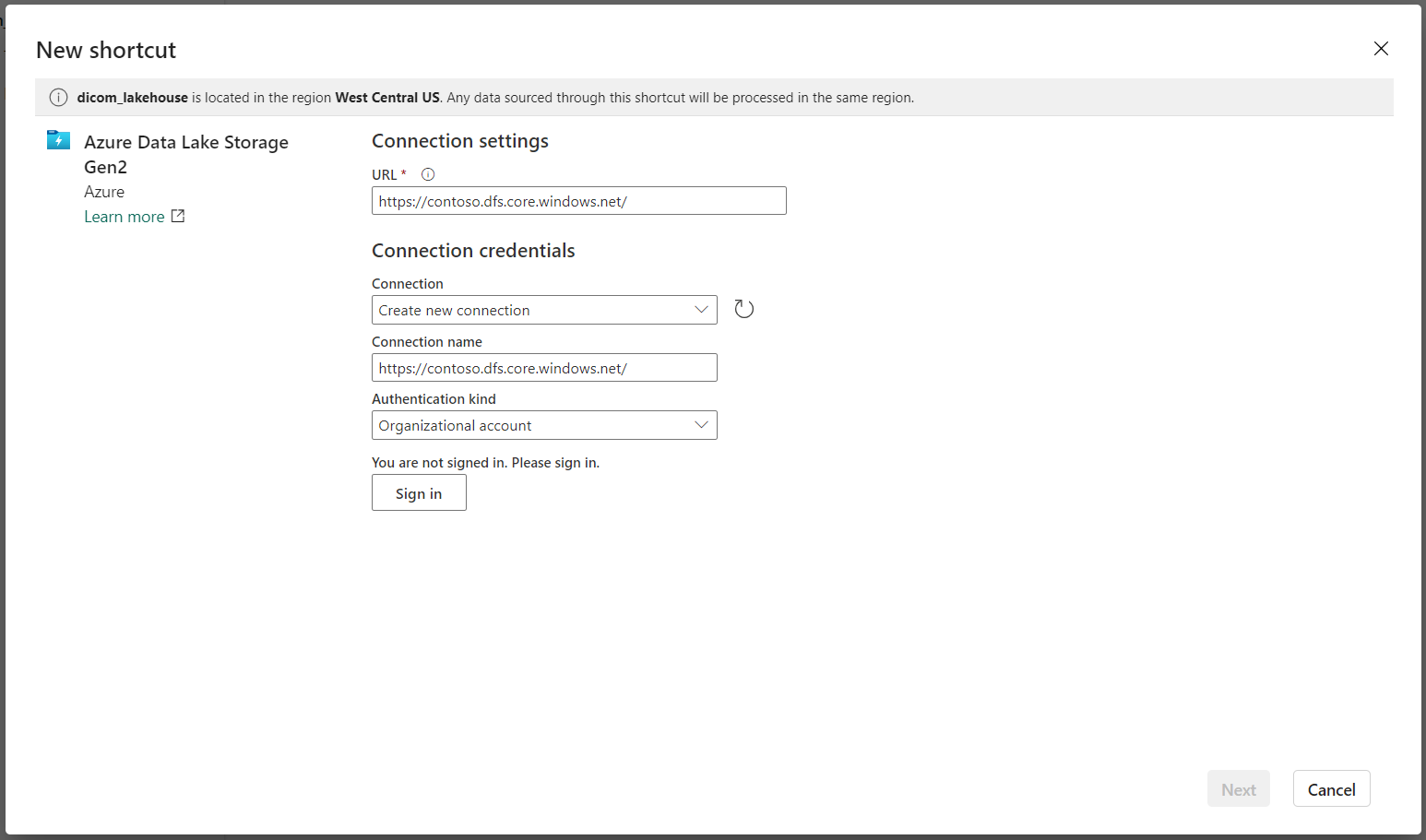
Selecteer een bestaande verbinding of maak een nieuwe verbinding door het verificatietype te selecteren dat u wilt gebruiken.
Notitie
Er zijn enkele opties voor verificatie tussen Data Lake Storage Gen2 en Fabric. U kunt een organisatieaccount of een service-principal gebruiken. Het is niet raadzaam om accountsleutels of shared access Signature-tokens te gebruiken.
Selecteer Volgende.
Voer een snelkoppelingsnaam in die de gegevens vertegenwoordigt die zijn gemaakt door de Data Factory-pijplijn. Voor de Delta-tabel moet de naam van de
instancesnelkoppeling bijvoorbeeld waarschijnlijk een exemplaar zijn.Voer het subpad in dat overeenkomt met de parameter uit de
ContainerNameconfiguratie van uitvoeringsparameters en de naam van de tabel voor de snelkoppeling. Gebruik bijvoorbeeld/dicom/instancevoor de Delta-tabel met het padinstancein dedicomcontainer.Selecteer Maken om de snelkoppeling te maken.
Herhaal stap 2 tot en met 9 om de resterende snelkoppelingen toe te voegen aan de andere Delta-tabellen in het opslagaccount (bijvoorbeeld
seriesenstudy).



Nadat u de snelkoppelingen hebt gemaakt, vouwt u een tabel uit om de namen en typen kolommen weer te geven.

Snelkoppelingen naar bestanden maken
Als u een DICOM-service gebruikt met Data Lake Storage, kunt u ook een snelkoppeling maken naar de DICOM-bestandsgegevens die zijn opgeslagen in de data lake.
Ga naar het lakehouse dat is gemaakt in de vereisten. Selecteer in de Verkenner-weergave het beletseltekenmenu (...) naast de map Bestanden .
Selecteer Nieuwe snelkoppeling om een nieuwe snelkoppeling te maken naar het opslagaccount dat de DICOM-gegevens bevat.
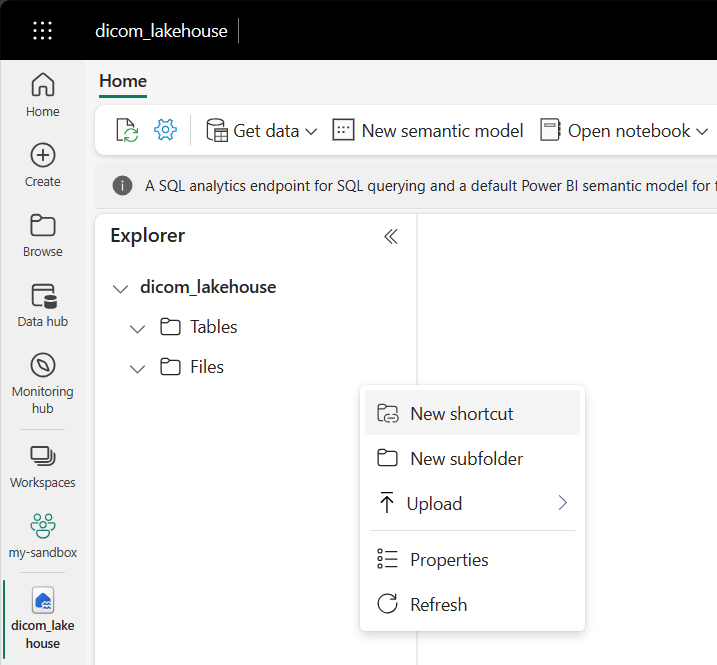
Selecteer Azure Data Lake Storage Gen2 als bron voor de snelkoppeling.
Voer onder Verbindingsinstellingen de URL in die u hebt gebruikt in de sectie Gekoppelde services .
Selecteer een bestaande verbinding of maak een nieuwe verbinding door het verificatietype te selecteren dat u wilt gebruiken.
Selecteer Volgende.
Voer een snelkoppelingsnaam in waarmee de DICOM-gegevens worden beschreven. Bijvoorbeeld contoso-dicom-files.
Voer het subpad in dat overeenkomt met de naam van de opslagcontainer en map die door de DICOM-service wordt gebruikt. Als u bijvoorbeeld een koppeling naar de hoofdmap wilt maken, is het subpad /dicom/AHDS. De hoofdmap is altijd
AHDS, maar u kunt desgewenst een koppeling maken naar een onderliggende map voor een specifieke werkruimte of EEN DICOM-service-exemplaar.Selecteer Maken om de snelkoppeling te maken.


Notebooks gebruiken
Nadat de tabellen zijn gemaakt in lakehouse, kunt u deze opvragen vanuit Fabric-notebooks. U kunt notitieblokken rechtstreeks vanuit lakehouse maken door Open Notebook te selecteren in de menubalk.
Op de notitieblokpagina kan de inhoud van het lakehouse aan de linkerkant worden bekeken, inclusief zojuist toegevoegde tabellen. Selecteer bovenaan de pagina de taal voor het notitieblok. De taal kan ook worden geconfigureerd voor afzonderlijke cellen. In het volgende voorbeeld wordt Spark SQL gebruikt.
Query's uitvoeren op tabellen met behulp van Spark SQL
Voer in de celeditor een Spark SQL-query in, zoals een SELECT instructie.
SELECT * from instance
Met deze query selecteert u alle inhoud uit de instance tabel. Wanneer u klaar bent, selecteert u Cel uitvoeren om de query uit te voeren.

Na een paar seconden worden de resultaten van de query weergegeven in een tabel onder de cel, zoals in het volgende voorbeeld. De tijd kan langer zijn als deze Spark-query de eerste in de sessie is omdat de Spark-context moet worden geïnitialiseerd.

Toegang tot DICOM-bestandsgegevens in notebooks
Als u een sjabloon hebt gebruikt om de pijplijn te maken en een snelkoppeling naar de DICOM-bestandsgegevens hebt gemaakt, kunt u de filePath kolom in de instance tabel gebruiken om metagegevens van exemplaren te correleren met de bestandsgegevens.
SELECT sopInstanceUid, filePath from instance

Samenvatting
In dit artikel hebt u het volgende geleerd:
- Gebruik Data Factory-sjablonen om een pijplijn te maken van de DICOM-service naar een Data Lake Storage Gen2-account.
- Configureer een trigger voor het extraheren van DICOM-metagegevens volgens een uurschema.
- Gebruik snelkoppelingen om DICOM-gegevens in een opslagaccount te verbinden met een Fabric Lakehouse.
- Gebruik notebooks om query's uit te voeren op DICOM-gegevens in lakehouse.
Volgende stappen
Notitie
DICOM® is het gedeponeerde handelsmerk van de National Electrical Manufacturers Association voor haar standaardenpublicaties met betrekking tot digitale communicatie van medische informatie.