Uw eerste data science-experiment maken in Machine Learning Studio (klassiek)
VAN TOEPASSING OP: Machine Learning Studio (klassiek)
Machine Learning Studio (klassiek)  Azure Machine Learning
Azure Machine Learning
Belangrijk
De ondersteuning voor Azure Machine Learning-studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden om vóór die datum over te stappen naar Azure Machine Learning.
Vanaf 1 december 2021 kunt u geen nieuwe resources voor Azure Machine Learning-studio (klassiek) meer maken. Tot en met 31 augustus 2024 kunt u de bestaande resources van Azure Machine Learning-studio (klassiek) blijven gebruiken.
- Zie informatie over het verplaatsen van machine learning-projecten van ML Studio (klassiek) naar Azure Machine Learning.
- Meer informatie over Azure Machine Learning
De documentatie van ML-studio (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet meer bijgewerkt.
In dit artikel maakt u een machine learning-experiment in Machine Learning Studio (klassiek) dat de prijs van een auto voorspelt op basis van verschillende variabelen, zoals merk- en technische specificaties.
Als u nog geen ervaring hebt met machine learning, is de videoserie Data Science for Beginners een geweldige inleiding tot machine learning, in gewone taal en met bekende begrippen.
In deze quickstart wordt de standaardwerkstroom voor een experiment gevolgd:
- Een model maken
- Het model trainen
- Het model beoordelen en testen
De gegevens ophalen
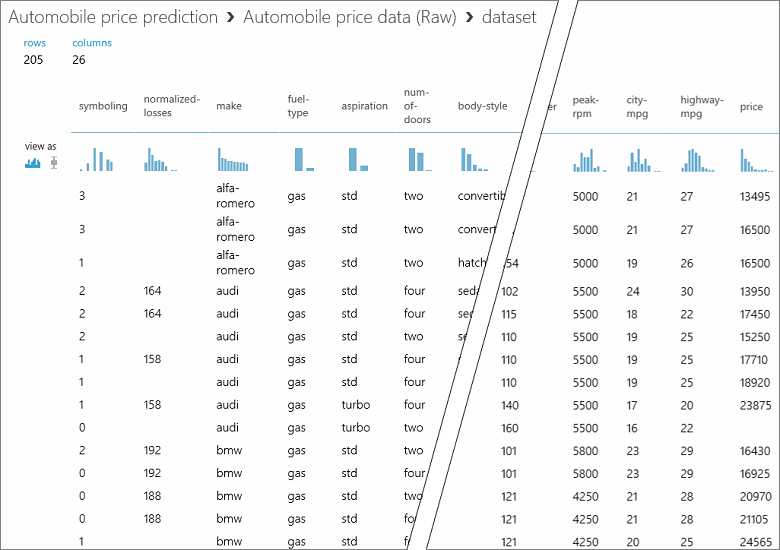
Het eerste wat u voor machine learning nodig hebt, zijn gegevens. Studio (klassiek) bevat een aantal voorbeeldgegevenssets die u kunt gebruiken. Daarnaast kunt u uit tal van bronnen gegevens importeren. Voor dit voorbeeld gebruiken we de voorbeeldgegevensset Automobile price data (Raw) . Deze is opgenomen in de werkruimte. Deze gegevensset bevat vermeldingen voor verschillende auto's, inclusief informatie over het merk, het model, de technische specificaties en de prijs.
Tip
U vindt een werkende kopie van het volgende experiment in de Azure AI Gallery. Ga naar Your first data science experiment - Automobile price prediction en klik op Open in Studio om een kopie van het experiment naar uw Machine Learning Studio-werkruimte (klassiek) te downloaden.
U voegt de gegevensset als volgt toe aan uw experiment.
Maak een nieuw experiment door onderaan het venster Machine Learning Studio (klassiek) op +NEW te klikken. Selecteer EXPERIMENT>Blank Experiment.
Het experiment krijgt een standaardnaam die boven aan het canvas wordt weergegeven. Selecteer deze tekst en wijzig de naam in iets relevants, bijvoorbeeld prijzen auto's voorspellen. De naam hoeft niet uniek te zijn.
Aan de linkerkant van het experimentcanvas bevindt zich een palet met gegevenssets en modules. Typ in het zoekvak boven aan dit palet automobile om de gegevensset met het label Automobile price data (Raw) te zoeken. Sleep deze gegevensset naar het experimentcanvas.
Als u wilt zien hoe deze gegevens eruitzien, klikt u op de uitvoerpoort onderaan de 'automobile'-gegevensset en selecteert u Visualize.
Tip
De invoer- en uitvoerpoorten van gegevenssets en modules worden aangeduid met kleine cirkels, waarbij de invoerpoorten zich boven en de uitvoerpoorten zich onder bevinden. Als u een gegevensstroom door uw experiment wilt maken, verbindt u een uitvoerpoort van één module met een invoerpoort van een andere. U kunt op elk gewenst moment op de uitvoerpoort van een gegevensset of module klikken om te zien hoe de gegevens eruitzien op dat punt in de gegevensstroom.
In deze gegevensset wordt elke auto weergegeven als een rij. De variabelen die aan elke auto zijn gekoppeld, worden weergegeven als kolommen. Aan de hand van de variabelen voor een specifieke auto wordt de prijs voorspeld in de kolom price, uiterst rechts (kolom 26).
Sluit het visualisatievenster door op de x in de rechterbovenhoek te klikken.
De gegevens voorbereiden
Normaal gesproken moet een gegevensset worden voorverwerkt voordat deze kan worden geanalyseerd. Het is u mogelijk opgevallen dat er in verschillende rijen ontbreken in de kolommen van verschillende rijen. Deze ontbrekende waarden moeten worden opgeschoond, zodat de gegevens correct kunnen worden geanalyseerd. We verwijderen de rijen met ontbrekende waarden. Ook in de kolom normalized-losses ontbreekt een groot deel van de waarden. Deze kolom zal daarom helemaal worden uitgesloten van het model.
Tip
Voor de meeste modules geldt dat voor het gebruik van de module de ontbrekende invoergegevens moeten worden opgeschoond.
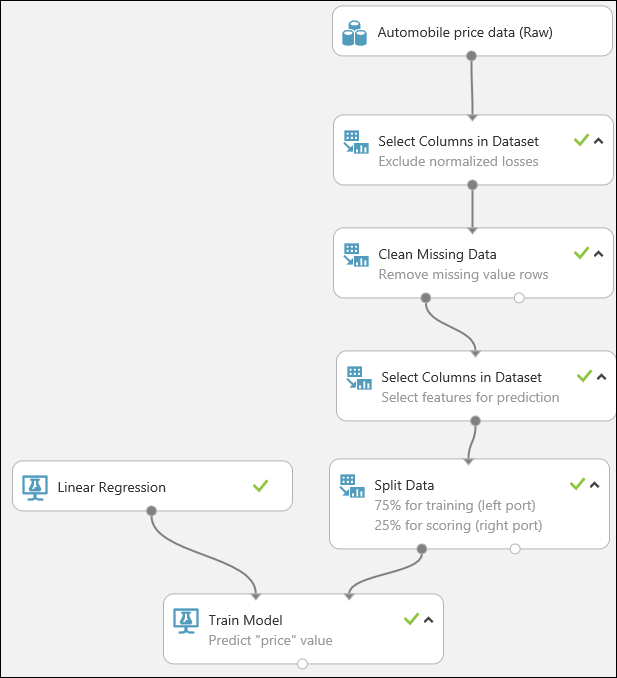
Eerst voegen we een module toe waarmee de kolom normalized-losses volledig wordt verwijderd. Vervolgens voegen we een andere module toe waarmee alle rijen met ontbrekende gegevens worden verwijderd.
Typ select columns in het zoekvak bovenaan het modulepalet om de module Select Columns in Dataset te vinden. Sleep deze vervolgens naar het experimentcanvas. Met deze module kunt u selecteren welke kolommen met gegevens u wilt opnemen in of uitsluiten voor het model.
Koppel de uitvoerpoort van de gegevensset Automobile price data (Raw) aan de invoerpoort van de module Select Columns in Dataset.
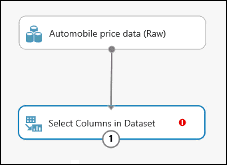
Klik op de module Select Columns in Dataset en klik in het deelvenster Properties op Launch column selector.
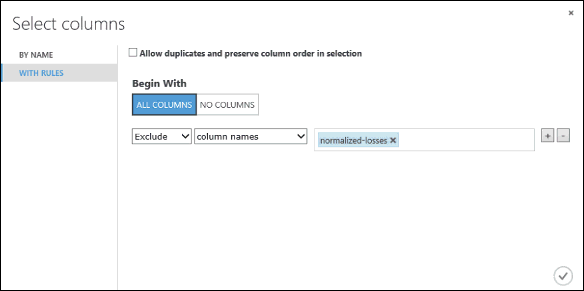
Klik links op With rules
Klik onder Begin With op All columns. Deze regels zorgen ervoor dat Select Columns in Dataset alle kolommen doorgeeft (met uitzondering van de kolommen die we dadelijk zullen uitsluiten).
Selecteer in de vervolgkeuzelijsten Exclude en column names en klik in het tekstvak. Er wordt een lijst met kolommen weergegeven. Selecteer normalized-losses om dit aan het tekstvak toe te voegen.
Klik rechtsonder op de knop met het vinkje (OK) om de kolomkiezer te sluiten.
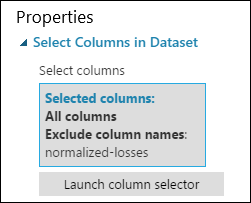
Het deelvenster met eigenschappen van de module Select Columns in Dataset geeft nu aan dat alle kolommen uit de gegevensset worden doorgegeven, met uitzondering van normalized-losses.
Tip
U kunt een opmerking aan een module toevoegen door te dubbelklikken op de module en tekst in te voeren. Zodoende kunt u in één oogopslag zien wat de module in uw experiment doet. Dubbelklik in dit geval op de module Select Columns in Dataset en typ de opmerking 'normalized-losses uitsluiten'.
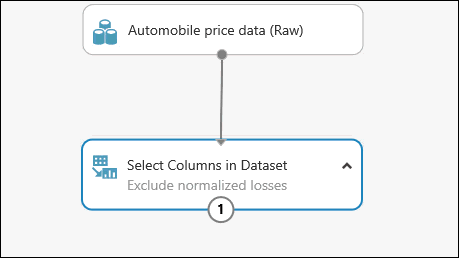
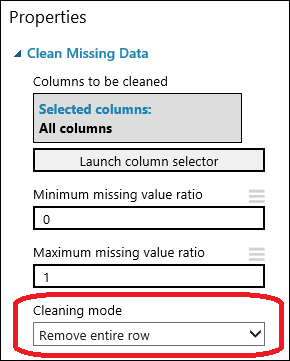
Sleep de module Clean Missing Data naar het canvas en verbindt deze met de module Select Columns in Dataset. Selecteer in het deelvenster Properties de optie Remove entire row onder Cleaning mode. Deze opties zorgen ervoor dat de module Clean Missing Data de gegevens opschoont door rijen met ontbrekende waarden te verwijderen. Dubbelklik op de module en typ de opmerking 'Rijen met ontbrekende waarde verwijderen'.
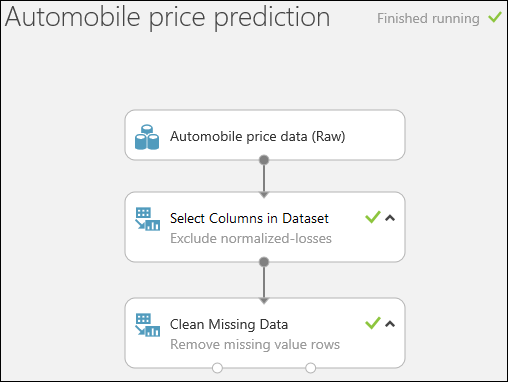
Voer het experiment uit door onder aan de pagina op RUN te klikken.
Wanneer het experiment is voltooid, wordt er bij alle modules een groen vinkje weergegeven om aan te geven dat deze zijn voltooid. In de rechterbovenhoek wordt de status Finished running weergegeven.
Tip
Waarom voeren we het experiment nu uit? Door het experiment uit te voeren, worden de kolomdefinities voor onze gegevens van de gegevensset doorgegeven via de module Select Columns in Dataset en via de module Clean Missing Data. Hierdoor beschikken alle modules die u koppelt aan Clean Missing Data over dezelfde informatie.
Nu hebben we opgeschoonde gegevens. Als u de opgeschoonde gegevensset wilt weergeven, klikt u op de uitvoerpoort links van de module Clean Missing Data en selecteert u Visualize. Zoals u kunt zien, is de kolom normalized-losses verwijderd en ontbreken er geen waarden meer.
Nu de gegevens zijn opgeschoond, kunt u opgeven welke functies u wilt gebruiken in het voorspellende model.
Functies definiëren
In machine learning zijn functies afzonderlijke meetbare eigenschappen van iets waarin u geïnteresseerd bent. In onze gegevensset staat elke rij voor één auto en elke kolom bevat een kenmerk van die auto.
Voor een goede set kenmerken voor het maken van een voorspellend model, moet u experimenteren en beschikken over kennis van het probleem dat u wilt oplossen. Bepaalde kenmerken zijn beter voor het voorspellen van het doel dan andere. Sommige kenmerken hebben een nauwe correlatie met andere kenmerken en kunnen worden verwijderd. City-mpg en highway-mpg lijken bijvoorbeeld sterk op elkaar, waardoor we een van de twee kunnen verwijderen zonder de voorspelling al te veel te beïnvloeden.
Laten we een model bouwen dat gebruikmaakt van een subset kenmerken onze gegevensset. U kunt later terugkeren en andere kenmerken selecteren om het experiment vervolgens opnieuw uit te voeren en te zien of u betere resultaten krijgt. Maar probeer om te beginnen de volgende functies:
make, body-style, wheel-base, engine-size, horsepower, peak-rpm, highway-mpg, price
Sleep nog een module Select Columns in Dataset naar het experimentcanvas. Koppel de linkeruitvoerpoort van de module Clean Missing Data aan de invoerpoort van de module Select Columns in Dataset.
Dubbelklik op de module en typ 'Select features for prediction' (Kenmerken voor de voorspelling selecteren).
Klik in het deelvenster Properties op Launch column selector.
Klik op With rules.
Klik onder Begin With op No columns. Selecteer in de filterrij Include en column names en selecteer onze lijst met kolomnamen in het tekstvak. Dit filter zorgt ervoor dat de module alleen de kolommen (kenmerken) doorgeeft die wij opgeven.
Klik op de knop met het vinkje (OK).
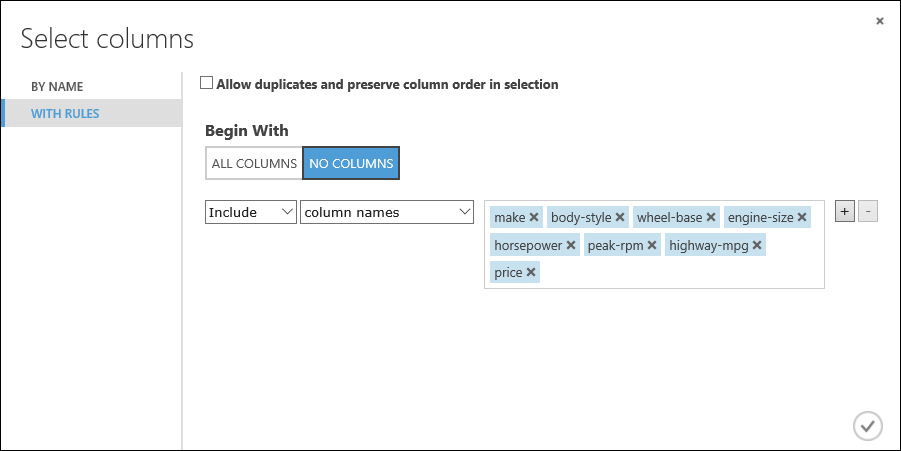
Deze module produceert een gefilterde gegevensset met alleen de kenmerken die we willen doorgeven aan het learning-algoritme dat we in de volgende stap gebruiken. U kunt later terugkeren en het opnieuw proberen met een andere selectie kenmerken.
Een algoritme kiezen en toepassen
Nu de gegevens klaar zijn, kunt u een voorspellend model bouwen door het model te trainen en te testen. We gebruiken onze gegevens om het model te trainen. Vervolgens testen we het model om te controleren in hoeverre de prijzen met dit model kunnen worden voorspeld.
Classificatie en regressie zijn twee soorten beheerde machine learning-algoritmen. Classificatie voorspelt een antwoord uit een gedefinieerde set categorieën, zoals een kleur (rood, blauw of groen). Regressie wordt gebruikt om een getal te voorspellen.
Omdat we de prijs willen voorspellen, wat een getal is, gebruiken we een regressiealgoritme. In dit voorbeeld gebruiken we een lineair regressiemodel.
We trainen het model met behulp van een gegevensset die de prijs bevat. Het model scant de gegevens en zoekt naar correlaties tussen de kenmerken van een auto en de prijs. Vervolgens gaan we het model testen. We voeren een aantal kenmerken in van auto's waarvan we de prijs kennen en kijken hoe dicht de voorspellingen van het model bij de bekende prijzen komen.
We gebruiken onze gegevens zowel voor trainings- als testdoeleinden door ze op te splitsen in afzonderlijke trainings- en testsets.
Selecteer de module Split Data, sleep deze naar het experimentcanvas en koppel de module aan de laatste module Select Columns in Dataset.
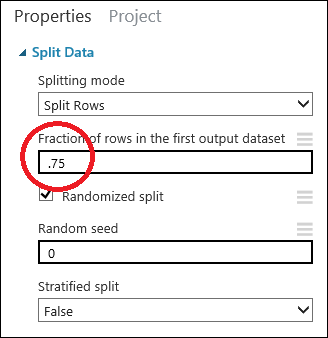
Klik op de module Split Data om deze te selecteren. Stel Fraction of rows in the first output dataset in het deelvenster Properties (rechts van het canvas) in op 0,75. Zodoende gebruiken we 75 procent van de gegevens om het model te trainen en gebruiken we 25 procent van de gegevens om het model te testen.
Tip
Door de parameter Random seed te wijzigen, kunt u verschillende willekeurig samples voor trainings- en testdoeleinden gebruiken. Deze parameter bepaalt de seeding van de pseudo-willekeurige nummergenerator.
Voer het experiment uit. De modules Select Columns in Dataset en Split Data geven daarop kolomdefinities door aan de modules die we hierna zullen toevoegen.
Als u een leeralgoritme wilt selecteren, moet u de categorie Machine Learning in het modulepalet links van het canvas uitvouwen en vouwt u vervolgens Initialize Model uit. Er worden verschillende categorieën weergegeven die kunnen worden gebruikt om de machine learning-algoritmen te initialiseren. Selecteer voor dit experiment de module Linear Regression in de categorie Regression en sleep de module naar het experimentcanvas. (U kunt de module ook zoeken door 'linear regression' in het zoekvak van het palet te typen.)
Zoek de module Train Model en sleep deze naar het experimentcanvas. Koppel de uitvoer van de module Linear Regression aan de linkerinvoer van de module Train model en koppel de trainingsgegevensuitvoer (linkerpoort) van de module Split Data aan de rechterinvoer van de module Train Model.
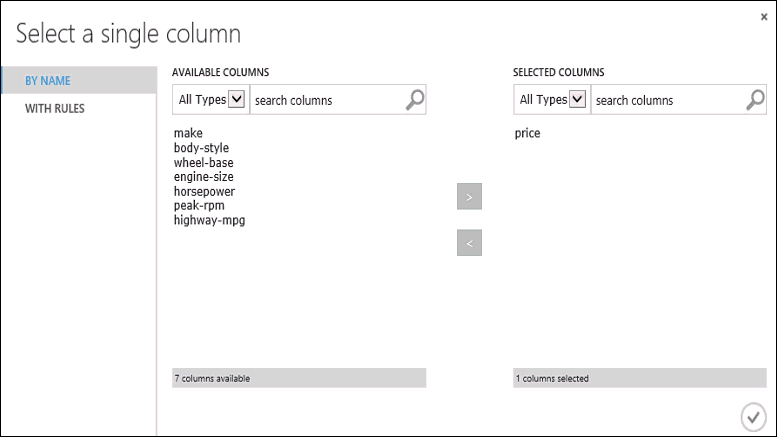
Klik op de module Train Model, klik in het deelvenster Properties op Launch column selector en selecteer vervolgens de kolom price. Price is de waarde die door het model wordt voorspeld.
U selecteert de kolom prijs in de kolomkiezer door deze vanuit de lijst Available columns te verplaatsen naar de lijst Selected columns.
Voer het experiment uit.
Nu beschikken we over een getraind regressiemodel dat kan worden gebruikt om nieuwe autogegevens te beoordelen voor het maken van prijsvoorspellingen.
Prijzen van nieuwe auto's voorspellen
Nu we het model met 75 procent van de gegevens hebben getraind, kunnen we het model gebruiken om de overige 25 procent van onze gegevens te beoordelen om te zien hoe goed het model werkt.
Zoek de module Score Model en sleep deze naar het experimentcanvas. Koppel de uitvoer van de module Train Model aan de linkerinvoerpoort van de module Score Model. Koppel de testgegevensuitvoer (rechterpoort) van de module Split Data aan de rechterinvoerpoort van de module Score Model.
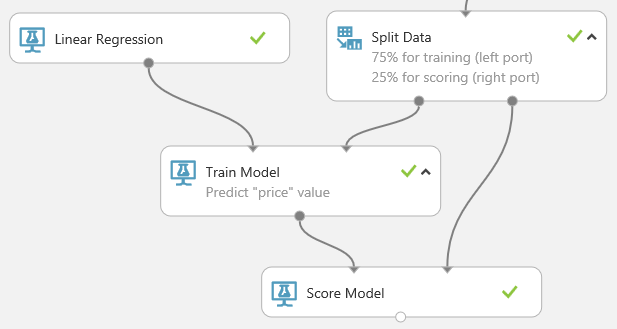
Voer het experiment uit en geef de uitvoer van de module Score Model. Hiervoor klikt u op de uitvoerpoort van Score Model en selecteert u Visualize. De uitvoer bevat de voorspelde waarden voor de prijs en de bekende waarden uit de testgegevens.
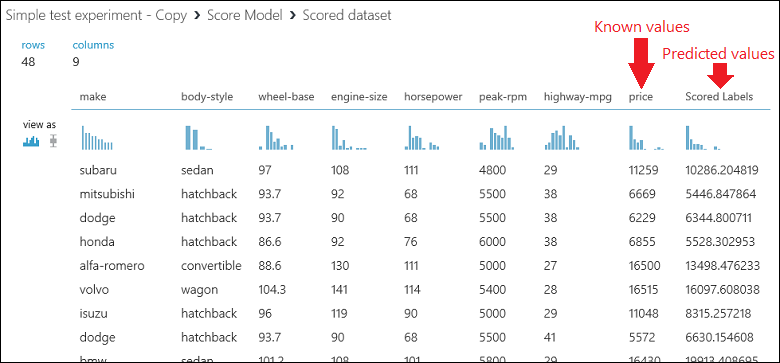
Ten slotte testen we de kwaliteit van de resultaten. Selecteer de module Evaluate Model, sleep deze naar het experimentcanvas en koppel de uitvoer van de module Score Model aan de linkerinvoer van de module Evaluate Model. Het laatste experiment ziet er ongeveer als volgt uit:
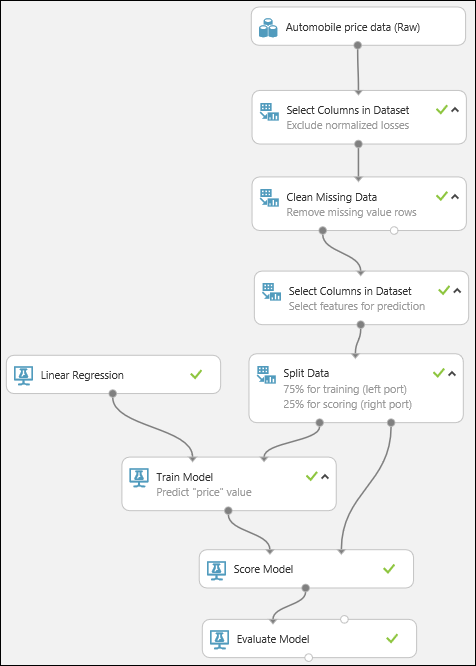
Voer het experiment uit.
Als u de uitvoer van de module Evaluate Model wilt weergeven, klikt u op de uitvoerpoort en selecteert u Visualize.
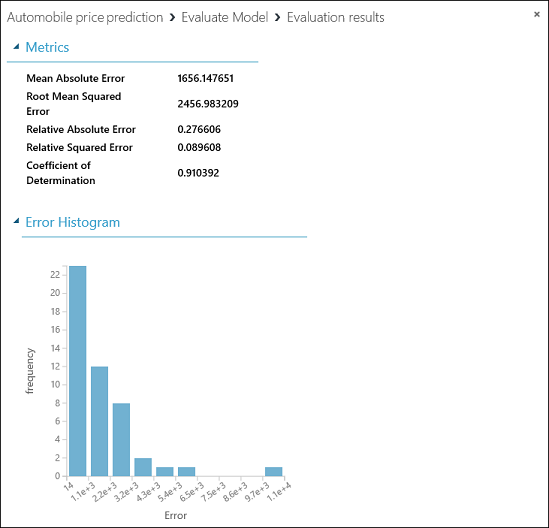
De volgende statistieken worden weergegeven voor het model:
- Gemiddelde absolute fout (Mean Absolute Error of MAE): Het gemiddelde aan absolute fouten (een fout is het verschil tussen de voorspelde waarde en de werkelijke waarde).
- Standaardafwijking (Root Mean Squared Error of RMSE): De vierkantswortel uit het gemiddelde aan kwadratische fouten voor de voorspellingen op basis van de testgegevensset.
- Relatieve absolute fout: Het gemiddelde aan absolute fouten ten opzichte van het absolute verschil tussen de werkelijke waarden en het gemiddelde van alle werkelijke waarden.
- Relatieve kwadratische fout: Het gemiddelde aan kwadratische fouten ten opzichte van het kwadratische verschil tussen de werkelijke waarden en het gemiddelde van alle werkelijke waarden.
- Determinatiecoëfficiënt: ook wel R²-waarde genoemd, is een statistische meetwaarde die aangeeft hoe goed het model is in het voorspellen van de gegevens.
Voor elk van de foutstatistieken geldt: hoe kleiner hoe beter. Een kleine waarde geeft aan dat de voorspelling dichter bij de werkelijke waarde ligt. Hoe dichter de determinatiecoëfficiënt bij één (1.0) ligt, hoe nauwkeuriger de voorspellingen.
Resources opschonen
Als u de resources die u aan de hand van dit artikel hebt gemaakt, niet meer nodig hebt, verwijdert u ze om te voorkomen dat er kosten in rekening worden gebracht. Instructies hierover vindt u in het artikel Gebruikersgegevens binnen producten exporteren en verwijderen.
Volgende stappen
In deze quickstart hebt u een eenvoudig experiment uitgevoerd met behulp van een voorbeeldgegevensset. Als u het proces van het maken en implementeren van een model nader wilt verkennen, gaat u naar de zelfstudie over voorspellende oplossingen.