Zelfstudie 1: Kredietrisico voorspellen - Machine Learning Studio (klassiek)
VAN TOEPASSING OP:  Machine Learning Studio (klassiek)
Machine Learning Studio (klassiek)  Azure Machine Learning
Azure Machine Learning
Belangrijk
De ondersteuning voor Azure Machine Learning-studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden om vóór die datum over te stappen naar Azure Machine Learning.
Vanaf 1 december 2021 kunt u geen nieuwe resources voor Azure Machine Learning-studio (klassiek) meer maken. Tot en met 31 augustus 2024 kunt u de bestaande resources van Azure Machine Learning-studio (klassiek) blijven gebruiken.
- Zie informatie over het verplaatsen van machine learning-projecten van ML Studio (klassiek) naar Azure Machine Learning.
- Meer informatie over Azure Machine Learning
De documentatie van ML-studio (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet meer bijgewerkt.
In deze zelfstudie wordt uitgebreid ingegaan op het ontwikkelingsproces van een predictive analytics-oplossing. U ontwikkelt een eenvoudig model in Machine Learning Studio (klassiek). Vervolgens implementeert u het model als een Machine Learning-webservice. Dit geïmplementeerde model kan voorspellingen doen op basis van nieuwe gegevens. Deze zelfstudie is deel één van een driedelige serie.
Stel dat u iemands kredietrisico moet voorspellen op basis van de gegevens die deze persoon in een kredietaanvraag heeft ingevuld.
Kredietrisicobeoordeling is een complex probleem, maar in deze zelfstudie wordt het enigszins vereenvoudigd. U gebruikt deze als voorbeeld van hoe u een predictive analytics-oplossing kunt maken met behulp van Machine Learning Studio (klassiek). U gebruikt aMachine Learning Studio (klassiek) en een Machine Learning-webservice voor deze oplossing.
In deze driedelige zelfstudie begint u met openbaar beschikbare kredietrisicogegevens. Vervolgens ontwikkelt en traint u een voorspellend model. En ten slotte implementeert u het model als een webservice.
In dit deel van de zelfstudie gaat u het volgende doen:
- Een werkruimte maken in Azure Machine Learning Studio (klassiek)
- Bestaande gegevens uploaden
- Een experiment maken
U kunt dit experiment vervolgens gebruiken om modellen te trainen in deel 2 en deze te implementeren in deel 3.
Vereisten
In deze zelfstudie gaan we ervan uit dat u Machine Learning Studio (klassiek) al minstens één keer hebt gebruikt en dat u enig inzicht hebt in de concepten van machine learning. Er wordt niet van uitgegaan dat u een expert bent.
Als u Machine Learning Studio (klassiek) nog nooit eerder hebt gebruikt, kunt u beginnen met de quickstart, uw eerste data science-experiment maken in Machine Learning Studio (klassiek). In die quickstart maakt u kennis met Machine Learning Studio (klassiek). U ziet hoe u modules naar uw experiment sleept, ze aan elkaar koppelt, het experiment uitvoert en de resultaten weergeeft.
Tip
In de Azure AI Gallery vindt u een werkende kopie van het experiment dat u in deze zelfstudie gaat ontwikkelen. Ga naar Zelfstudie – Kredietrisico voorspellen en klik op Openen in Studio om een kopie van het experiment naar uw werkruimte in Machine Learning Studio (klassiek) te downloaden.
Een werkruimte maken in Azure Machine Learning Studio (klassiek)
Als u Machine Learning Studio (klassiek) wilt gebruiken, moet u een Machine Learning Studio-werkruimte (klassiek) hebben. Deze werkruimte bevat de hulpprogramma's die u nodig hebt om experimenten te maken, beheren en publiceren.
Zie Een Machine Learning Studio-werkruimte (klassiek) maken en delen om een werkruimte te maken.
Nadat uw werkruimte is gemaakt, opent u Machine Learning Studio (klassiek) (https://studio.azureml.net/Home). Als u meer dan één werkruimte hebt, kunt u de werkruimte selecteren op de werkbalk in de rechterbovenhoek van het venster.
Tip
Als u eigenaar bent van de werkruimte, kunt u de experimenten waaraan u werkt met anderen delen door ze uit te nodigen in de werkruimte. U kunt dit doen in Machine Learning Studio (klassiek) op de pagina INSTELLINGEN. U hebt alleen het Microsoft- of organisatie-account van elke gebruiker nodig.
Klik op de pagina SETTINGS op USERS (gebruikers) en klik op INVITE MORE USERS (meer gebruikers uitnodigen) onderaan het venster.
Bestaande gegevens uploaden
Voor het ontwikkelen van een voorspellend model voor kredietrisico hebt u gegevens nodig die u kunt gebruiken om het model te trainen en vervolgens te testen. Voor deze zelfstudie gebruikt u "UCI Statlog (German Credit Data) Data Set" uit de UC Irvine Machine Learning-opslagplaats. U vindt deze hier:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
U gebruikt het bestand met de naam german.data. Download dit bestand naar uw lokale vaste schijf.
De gegevensset german.data bevat rijen met 20 variabelen voor 1000 kredietaanvragers uit het verleden. Deze 20 variabelen vertegenwoordigen de set kenmerken van de gegevensset (de functievector), die identificerende eigenschappen bevat voor elke kredietaanvrager. Een extra kolom in elke rij vertegenwoordigt het berekende kredietrisico van de aanvrager, met 700 aanvragers geïdentificeerd als een laag kredietrisico en 300 als een hoog risico.
De UCI-website bevat een beschrijving van de kenmerken van de functievector voor deze gegevens. Deze gegevens omvatten financiële gegevens, kredietgeschiedenis, werknemersstatus en persoonlijke gegevens. Voor elke aanvrager is een binaire beoordeling gegeven die aangeeft of deze een laag of een hoog kredietrisico heeft.
U gebruikt deze gegevens om een voorspellend model te trainen. Wanneer u klaar bent, moet uw model in staat zijn om een functievector voor een nieuw individu te accepteren en te voorspellen of hij of zij een laag of hoog kredietrisico heeft.
Er is een interessante wending.
De beschrijving van de dataset op de UCI-website geeft aan wat het kost als u het kredietrisico van een persoon verkeerd classificeert. Als het model een hoog kredietrisico voorspelt voor iemand die feitelijk een laag kredietrisico heeft, heeft het model een misclassificatie gemaakt.
Maar de omgekeerde misclassificatie is vijf keer zo duur voor de financiële instelling: als het model een laag kredietrisico voorspelt voor iemand die daadwerkelijk een hoog kredietrisico loopt.
U moet uw model dus zo trainen dat de kosten van dit laatste type misclassificatie vijf keer zo hoog zijn als die van de andere manier van verkeerd klasseren.
Een eenvoudige manier om dit te doen is door bij het trainen van het model in uw experiment de items die iemand met een hoog kredietrisico vertegenwoordigen, vijf keer te dupliceren.
Als het model iemand vervolgens ten onrechte classificeert als een laag kredietrisico terwijl het een hoog risico betreft, voert het model vijfmaal dezelfde misclassificatie uit, één keer voor elk duplicaat. Dit verhoogt de kosten van deze fout in de trainingsresultaten.
De gegevenssetindeling converteren
In de oorspronkelijke gegevensset worden de gegevens gescheiden door witruimte. Machine Learning Studio (klassiek) werkt beter met een bestand met door komma's gescheiden waarden (CSV), dus moet u de gegevensset converteren door spaties te vervangen door komma's.
Er zijn veel manieren om deze gegevens te converteren. Eén manier is de volgende Windows PowerShell-opdracht te gebruiken:
cat german.data | %{$_ -replace " ",","} | sc german.csv
Een andere manier is met behulp van de sed-opdracht van Unix:
sed 's/ /,/g' german.data > german.csv
In beide gevallen hebt u een door komma's gescheiden versie van de gegevens gemaakt in een bestand met de naam german.csv dat u in uw experiment kunt gebruiken.
Upload de gegevensset naar Machine Learning Studio (klassiek)
Nadat de gegevens zijn geconverteerd naar CSV-indeling, moet u deze uploaden naar Machine Learning Studio (klassiek).
Open de startpagina van Machine Learning Studio (klassiek) (https://studio.azureml.net).
Klik op het menu
 in de linkerbovenhoek van het venster, klik op Azure Machine Learning, selecteer Studio en meld u aan.
in de linkerbovenhoek van het venster, klik op Azure Machine Learning, selecteer Studio en meld u aan.Klik onderaan het venster op +NEW (+nieuw).
Selecteer DATASET (gegevensset).
Selecteer FROM LOCAL FILE (uit lokaal bestand).
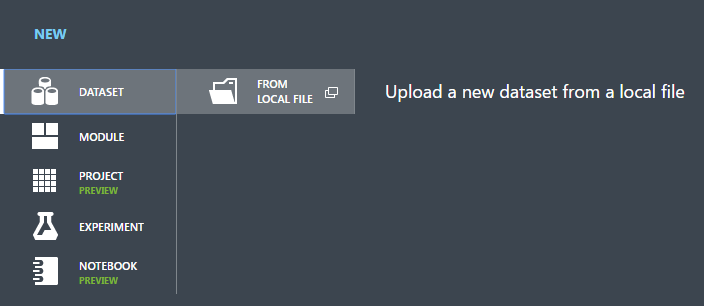
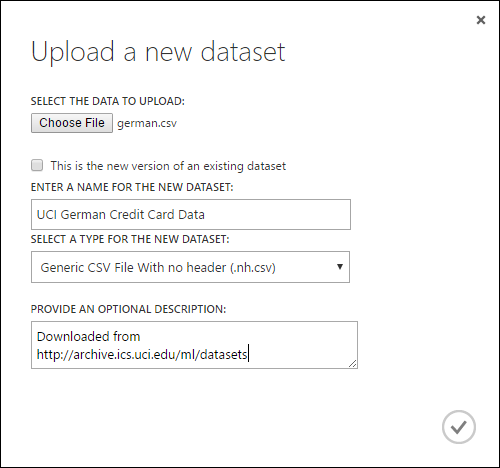
Klik in het dialoogvenster Upload a new dataset (een nieuwe gegevensset uploaden) op Browse (bladeren) en zoek het bestand german.csv dat u hebt gemaakt.
Voer een naam in voor de gegevensset. Noem hem voor deze zelfstudie "UCI German Credit Card Data".
Selecteer als gegevenstype Generic CSV File With no header (.nh.csv) (generiek CSV-bestand zonder koptekst).
Voeg desgewenst een beschrijving toe.
Klik op het vinkje OK.
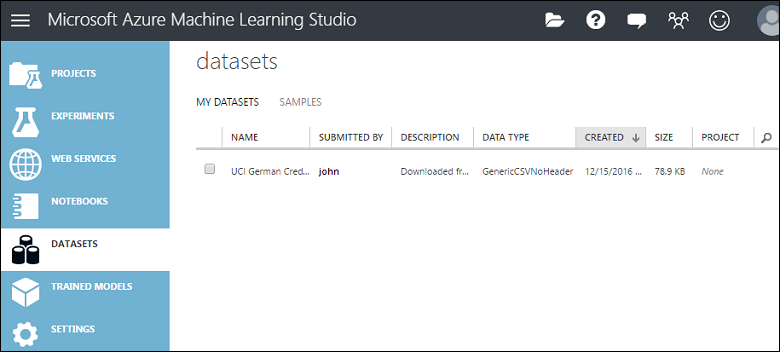
Hiermee worden de gegevens geüpload naar een gegevenssetmodule die u in een experiment kunt gebruiken.
U kunt gegevenssets die u naar Studio (klassiek) hebt geüpload, beheren door op het tabblad DATASETS aan de linkerkant van het Studio (klassiek)-venster te klikken.
Zie Uw trainingsgegevens importeren in Machine Learning Studio (klassiek) voor meer informatie over het importeren van andere typen gegevens in een experiment.
Een experiment maken
De volgende stap in deze zelfstudie is om een experiment te maken in Machine Learning Studio (klassiek) dat gebruikmaakt van de gegevensset die u hebt geüpload.
Klik in Studio (klassiek) onderaan het venster op +NIEUW.
Selecteer EXPERIMENT en selecteer 'Blank Experiment' (leeg experiment).
Selecteer bovenaan het canvas de standaardnaam voor een experiment en wijzig deze in een beschrijvende naam.

Tip
Het is een goede gewoonte om Summary (samenvatting) en Description (beschrijving) voor het experiment in het deelvenster Properties (eigenschappen) in te vullen. Met deze eigenschappen kunt u het experiment documenteren, zodat iedereen die er later naar kijkt, uw doelen en methodologie begrijpt.

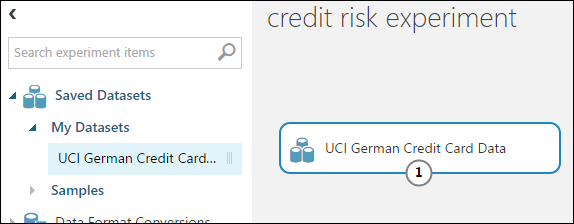
Vouw in het modulepalet links van het experimentcanvas Saved Datasets uit (opgeslagen gegevenssets).
Zoek de gegevensset die u hebt gemaakt op onder My Datasets (mijn gegevenssets) en sleep deze naar het canvas. U kunt de gegevensset ook vinden door de naam in te voeren in het vak Search (zoeken) boven het palet.
De gegevens voorbereiden
U kunt de eerste 100 rijen van de gegevens en enkele statistische gegevens voor de hele gegevensset bekijken: klik op de uitvoerpoort van de gegevensset (de kleine cirkel onderaan) en selecteer Visualiseren.
Omdat het gegevensbestand geen kolomkoppen had, heeft Studio (klassiek) generieke koppen (Col1, Col2, enzovoort) gemaakt. Goede koppen zijn niet essentieel voor het maken van een model, maar ze maken het gemakkelijker om met de gegevens in het experiment te werken. Wanneer u dit model uiteindelijk publiceert in een webservice, helpen de koppen u ook bij het identificeren van de kolommen voor de gebruiker van de service.
U kunt kolomkoppen toevoegen met behulp van de module Edit Metadata (metagegevens bewerken).
U gebruikt de module Edit Metadata (metagegevens bewerken) om de metagegevens van een gegevensset te wijzigen. In dit geval om meer beschrijvende namen voor de kolomkoppen op te geven.
Als u metagegevens bewerken wilt gebruiken, geeft u eerst op welke kolommen u wilt wijzigen (in dit geval allemaal.) Vervolgens geeft u de actie op die moet worden uitgevoerd op deze kolommen (in dit geval worden kolomkoppen gewijzigd.)
Typ in het modulepalet 'metadata' in het vak Search. Edit Metadata (metagegevens bewerken) wordt weergegeven in de modulelijst.
Klik en sleep de module Edit Metadata (metagegevens bewerken) module naar het canvas en zet deze neer onder de gegevensset die u eerder hebt toegevoegd.
Verbind de gegevensset met Edit Metadata (metagegevens bewerken): klik op de uitvoerpoort van de gegevensset (het rondje onderaan de gegevensset), sleep naar de invoerpoort van Edit Metadata (metagegevens bewerken) (het rondje aan de bovenkant van de module) en laat de muisknop los. De gegevensset en de module blijven verbonden, zelfs als u een ervan op het canvas verplaatst.
Het experiment zou er nu ongeveer zo uit moeten zien:
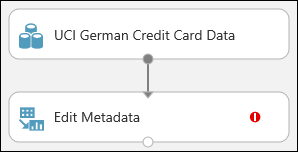
Het rode uitroepteken geeft aan dat u de eigenschappen voor deze module nog niet hebt ingesteld. Dat doet u als volgende.
Tip
U kunt een opmerking aan een module toevoegen door te dubbelklikken op de module en tekst in te voeren. Zodoende kunt u in één oogopslag zien wat de module in uw experiment doet. In dit geval dubbelklikt u op de module Edit Metadata (metagegevens bewerken) en typt u de opmerking “Add column headings” (kolomkoppen toevoegen). Klik ergens anders op het canvas om het tekstvak te sluiten. Klik op de pijl-omlaag in de module om de opmerking weer te geven.
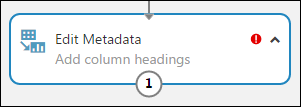
Selecteer Edit Metadata (metagegevens bewerken) en klik in het deelvenster Properties (eigenschappen) rechts van het canvas op Launch column selector (kolomkiezer starten).
Selecteer in het dialoogvenster Kolommen selecteren alle rijen in Beschikbare kolommen en klik > om ze naar Geselecteerde kolommen te verplaatsen. Het dialoogvenster zou er zo uit moeten zien:
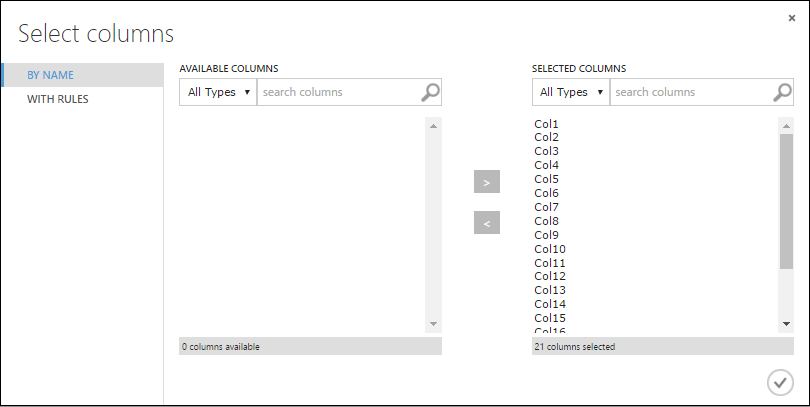
Klik op het vinkje OK.
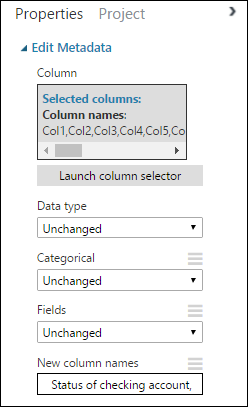
Zoek in het deelvenster Properties de parameter New column names (nieuwe kolomnamen). Voer in dit veld een lijst met namen in voor de 21 kolommen in de gegevensset, gescheiden door komma's, in de volgorde van de kolommen. U kunt de kolomnamen verkrijgen uit de datasetdocumentatie op de UCI-website, of voor het gemak kunt u de volgende lijst kopiëren en plakken:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskHet deelvenster Properties ziet er zo uit:
Tip
Als u de kolomkoppen wilt controleren, voert u het experiment uit (klik op RUN onder het experimentcanvas). Wanneer het experiment is uitgevoerd (er verschijnt een groen vinkje op Edit Metadata (metagegevens bewerken)), klikt u op de uitvoerpoort van de module Edit Metadata en selecteert u Visualize (visualiseren). U kunt de uitvoer van elke module op dezelfde manier bekijken om de voortgang van de gegevens door het experiment te bekijken.
Training- en testgegevenssets maken
U hebt gegevens nodig om het model te trainen, en andere gegevens om het te testen. In de volgende stap van het experiment splitst u de gegevensset dus in twee afzonderlijke gegevenssets: een voor het trainen van ons model en een voor het testen ervan.
U doet dit met behulp van de module Split Data (gegevens splitsen).
Zoek de module Split Data (gegevens splitsen), sleep deze naar het canvas en verbindt deze met de module Edit Metadata (metagegevens bewerken).
Standaard is de splitsingsverhouding 0,5 en is de Randomized split-parameter ingesteld. Dit betekent dat een willekeurige helft van de gegevens wordt uitgevoerd via één poort van de module Split Data (gegevens splitsen), en de andere helft door de andere. U kunt deze parameters aanpassen, evenals de parameter Random seed (willekeurige seed), om de verdeling in trainings- en testgegevens te wijzigen. In dit voorbeeld laat u staan zoals ze zijn.
Tip
De eigenschap Fraction of rows in the first output dataset (fractie van rijen in de eerste uitgevoerde gegevensset) bepaalt welk deel van de gegevens wordt uitgevoerd via de linker uitvoerpoort. Als u bijvoorbeeld de verhouding instelt op 0,7, wordt 70% van de gegevens uitgevoerd via de linker poort en 30% via de rechter poort.
Dubbelklik op de module Split Data (gegevens splitsen) en voer de volgende opmerking in: “Training/testing data split 50%” (50% splitsing van trainings- en testgegevens).
U kunt de uitvoer van de Split Data-module (gegevens splitsen) zo gebruiken als u wilt, maar wij gebruiken de linker uitvoer als trainingsgegevens, en de rechter uitvoer als testgegevens.
Zoals gezegd in de vorige stap, zijn de kosten van het verkeerd classificeren van een hoog kredietrisico als laag vijf keer zo hoog als de kosten van het verkeerd classificeren van een laag kredietrisico als hoog. Om hier rekening mee te houden, genereert u een nieuwe gegevensset die deze kostenfunctie weergeeft. In de nieuwe gegevensset wordt elk voorbeeld met een hoog risico vijf keer gerepliceerd, terwijl elk voorbeeld met een laag risico niet wordt gerepliceerd.
U kunt deze replicatie uitvoeren met behulp van R-code:
Zoek de module Execute R Script (R-script uitvoeren) en sleep deze naar het experimentcanvas.
Koppel de linkeruitvoerpoort van de module Split Data (gegevens splitsen) aan de eerste invoerpoort (“Dataset1”) van de module Execute R Script (R-script uitvoeren).
Dubbelklik op de module Execute R Script (R-script uitvoeren) en voer de opmerking “Set cost adjustment” (kostencorrectie instellen) in.
Verwijder in het deelvenster Properties (eigenschappen), de standaardtekst bij de parameter R Script en voer het volgende script in:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")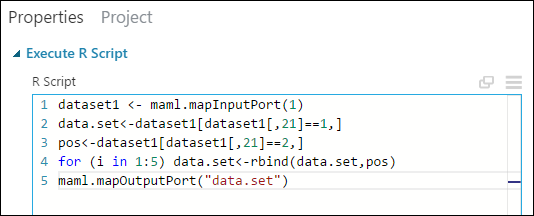
U moet dezelfde replicatiebewerking uitvoeren voor elke uitvoer van de module Split Data (gegevens splitsen), zodat de trainings- en testgegevens dezelfde kostenaanpassing hebben. De eenvoudigste manier om dit te doen is de module Execute R Script (R-script uitvoeren) die u hebt gemaakt te dupliceren en de kopie te koppelen aan de andere uitvoerpoort van de module Split Data (gegevens splitsen).
Klik met de rechtermuisknop op de module Execute R Script (R-script uitvoeren) en selecteer Copy (kopiëren).
Klik met de rechtermuisknop op het experimentcanvas en selecteer Paste (plakken).
Sleep de nieuwe module naar de juiste positie en verbind vervolgens de rechteruitvoerpoort van de module Split Data (gegevens splitsen) met de eerste invoerpoort van deze nieuwe module Execute R Script (R-script uitvoeren).
Klik onderaan het canvas op Run (uitvoeren).
Tip
De kopie van de Execute R Script-module bevat hetzelfde script als de oorspronkelijke module. Wanneer u een module op het canvas kopieert en plakt, behoudt de kopie alle eigenschappen van het origineel.
Ons experiment ziet er nu ongeveer uit als volgt:
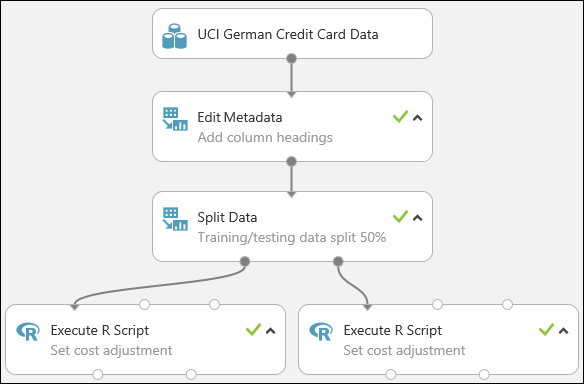
Zie voor meer informatie over het gebruik van R-scripts in uw experimenten Extend your experiment with R (uw experiment uitbreiden met R).
Resources opschonen
Als u de resources die u aan de hand van dit artikel hebt gemaakt, niet meer nodig hebt, verwijdert u ze om te voorkomen dat er kosten in rekening worden gebracht. Instructies hierover vindt u in het artikel Gebruikersgegevens binnen producten exporteren en verwijderen.
Volgende stappen
In deze zelfstudie hebt u de volgende stappen voltooid:
- Een werkruimte maken in Azure Machine Learning Studio (klassiek)
- Bestaande gegevens uploaden naar de werkruimte
- Een experiment maken
U bent nu klaar om modellen voor deze gegevens te trainen en te evalueren.