Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP:  Machine Learning Studio (klassiek)
Machine Learning Studio (klassiek)  Azure Machine Learning
Azure Machine Learning
Belangrijk
De ondersteuning voor Azure Machine Learning-studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden om vóór die datum over te stappen naar Azure Machine Learning.
Vanaf 1 december 2021 kunt u geen nieuwe resources voor Azure Machine Learning-studio (klassiek) meer maken. Tot en met 31 augustus 2024 kunt u de bestaande resources van Azure Machine Learning-studio (klassiek) blijven gebruiken.
- Zie informatie over het verplaatsen van machine learning-projecten van ML Studio (klassiek) naar Azure Machine Learning.
- Meer informatie over Azure Machine Learning
De documentatie van ML-studio (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet meer bijgewerkt.
Als u uw eigen gegevens in Machine Learning Studio (klassiek) wilt gebruiken om een predictive analytics-oplossing te ontwikkelen en te trainen, kunt u gegevens gebruiken uit:
- Lokaal bestand : laad lokale gegevens van tevoren vanaf uw harde schijf om een gegevenssetmodule in uw werkruimte te maken
- Onlinegegevensbronnen : gebruik de module Gegevens importeren om toegang te krijgen tot gegevens uit een van de verschillende onlinebronnen terwijl uw experiment wordt uitgevoerd
- Machine Learning Studio-experiment (klassiek): gegevens gebruiken die zijn opgeslagen als een gegevensset in Machine Learning Studio (klassiek)
- SQL Server-database : gegevens uit een SQL Server-database gebruiken zonder gegevens handmatig te hoeven kopiëren
Notitie
Er zijn een aantal voorbeeldgegevenssets beschikbaar in Machine Learning Studio (klassiek) die u kunt gebruiken voor trainingsgegevens. Zie De voorbeeldgegevenssets gebruiken in Machine Learning Studio (klassiek) voor meer informatie hierover.
Gegevens voorbereiden
Machine Learning Studio (klassiek) is ontworpen voor gebruik met rechthoekige of tabellaire gegevens, zoals tekstgegevens die zijn gescheiden of gestructureerde gegevens uit een database, hoewel in sommige gevallen niet-rechthoekige gegevens kunnen worden gebruikt.
Het is het beste als uw gegevens relatief schoon zijn voordat u deze in Studio importeert (klassiek). U wilt bijvoorbeeld zorgen voor problemen zoals niet-aanhalingstekens.
Er zijn echter modules beschikbaar in Studio (klassiek) die enige manipulatie van gegevens in uw experiment mogelijk maken nadat u uw gegevens hebt geïmporteerd. Afhankelijk van de machine learning-algoritmen die u gaat gebruiken, moet u mogelijk bepalen hoe u structurele problemen met gegevens, zoals ontbrekende waarden en parseringsgegevens, gaat afhandelen, en er zijn modules die u hierbij kunnen helpen. Zoek in de sectie Gegevenstransformatie van het modulepalet voor modules die deze functies uitvoeren.
U kunt op elk moment in uw experiment de gegevens bekijken of downloaden die door een module worden geproduceerd door op de uitvoerpoort te klikken. Afhankelijk van de module zijn er mogelijk verschillende downloadopties beschikbaar of kunt u de gegevens in uw webbrowser in Studio (klassiek) visualiseren.
Ondersteunde gegevensindelingen en gegevenstypen
U kunt een aantal gegevenstypen importeren in uw experiment, afhankelijk van het mechanisme dat u gebruikt om gegevens te importeren en waar deze vandaan komen:
- Tekst zonder opmaak (.txt)
- Door komma's gescheiden waarden (CSV) met een koptekst (.csv) of zonder (.nh.csv)
- Door tabs gescheiden waarden (TSV) met een header (.tsv) of zonder (.nh.tsv)
- Excel-bestand
- Azure-tabel
- Hive-tabel
- SQL-databasetabel
- OData-waarden
- SVMLight-gegevens (.svmlight) (zie de SVMLight-definitie voor informatie over de indeling)
- ARFF-gegevens (Attribute Relation File Format) (.arff) (zie de ARFF-definitie voor indelingsinformatie)
- Zip-bestand (.zip)
- R-object of werkruimtebestand (. RData)
Als u gegevens importeert in een indeling zoals ARFF die metagegevens bevat, gebruikt Studio (klassiek) deze metagegevens om de kop en het gegevenstype van elke kolom te definiëren.
Als u gegevens importeert zoals TSV of CSV-indeling die deze metagegevens niet bevat, wordt in Studio (klassiek) het gegevenstype voor elke kolom afgeleid door een steekproef uit de gegevens te nemen. Als de gegevens ook geen kolomkoppen hebben, bevat Studio (klassiek) standaardnamen.
U kunt de koppen en gegevenstypen voor kolommen expliciet opgeven of wijzigen met behulp van de module Metagegevens bewerken.
De volgende gegevenstypen worden herkend door Studio (klassiek):
- String
- Geheel getal
- Dubbel
- Booleaanse waarde
- Datum en tijd
- TimeSpan
Studio maakt gebruik van een intern gegevenstype dat gegevenstabel wordt genoemd om gegevens door te geven tussen modules. U kunt uw gegevens expliciet converteren naar gegevenstabelindeling met behulp van de module Converteren naar gegevensset .
Elke module die andere indelingen accepteert dan de gegevenstabel, converteert de gegevens naar de gegevenstabel op de achtergrond voordat deze wordt doorgegeven aan de volgende module.
Indien nodig kunt u de indeling van de gegevenstabel weer converteren naar csv-, TSV-, ARFF- of SVMLight-indeling met behulp van andere conversiemodules. Zoek in de sectie Conversies van gegevensindeling van het modulepalet voor modules die deze functies uitvoeren.
Gegevenscapaciteiten
Modules in Machine Learning Studio (klassiek) ondersteunen gegevenssets van maximaal 10 GB aan compacte numerieke gegevens voor veelvoorkomende gebruiksvoorbeelden. Als een module meer dan één invoer heeft, is de waarde 10 GB de totale invoergrootte. U kunt grotere gegevenssets samplen met behulp van query's uit Hive of Azure SQL Database, of u kunt Learning by Counts vooraf verwerken voordat u de gegevens importeert.
U kunt de volgende typen gegevens in grotere gegevenssets opnemen tijdens het normaliseren van kenmerken, tot maximaal 10 GB:
- Sparse
- Categorische gegevens
- Tekenreeksen
- Binaire gegevens
De volgende modules zijn beperkt tot gegevenssets die kleiner zijn dan 10 GB:
- Aanbevelingsmodules
- De module Synthetic Minority Oversampling Technique (SMOTE)
- Scriptmodules: R, Python, SQL
- Modules waarbij de grootte van de uitvoer groter is dan invoergegevens, zoals Join- of hash-functies
- Kruisvalidatie, Tune Model Hyperparameters, ordinale regressie en One-vs-All-multiklasse, wanneer het aantal herhalingen groot is
Upload de gegevens naar Azure Storage of Azure SQL Database voor gegevenssets die groter zijn dan een paar GB, of gebruik Azure HDInsight in plaats van rechtstreeks vanuit een lokaal bestand te uploaden.
U vindt informatie over afbeeldingsgegevens in de naslaginformatie over importinstallatiekopieën .
Importeren uit een lokaal bestand
U kunt een gegevensbestand uploaden vanaf uw harde schijf om te gebruiken als trainingsgegevens in Studio (klassiek). Wanneer u een gegevensbestand importeert, maakt u een gegevenssetmodule die klaar is voor gebruik in experimenten in uw werkruimte.
Ga als volgt te werk om gegevens van een lokale harde schijf te importeren:
- Klik op +NIEUW onderaan het studiovenster (klassiek).
- Selecteer GEGEVENSSET en UIT LOKAAL BESTAND.
- Blader in het dialoogvenster Een nieuwe gegevensset uploaden naar het bestand dat u wilt uploaden.
- Voer een naam in, identificeer het gegevenstype en voer desgewenst een beschrijving in. Een beschrijving wordt aanbevolen. Hiermee kunt u eventuele kenmerken van de gegevens vastleggen die u wilt onthouden wanneer u de gegevens in de toekomst gebruikt.
- Met het selectievakje Dit is de nieuwe versie van een bestaande gegevensset waarmee u een bestaande gegevensset kunt bijwerken met nieuwe gegevens. Hiervoor klikt u op dit selectievakje en voert u de naam van een bestaande gegevensset in.
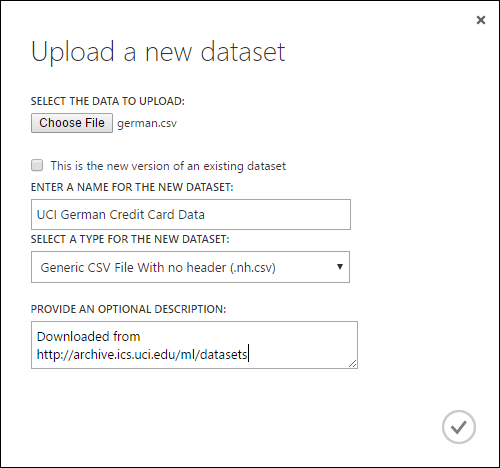
De uploadtijd is afhankelijk van de grootte van uw gegevens en de snelheid van de verbinding met de service. Als u weet dat het bestand lang duurt, kunt u andere dingen doen in Studio (klassiek) terwijl u wacht. Als u de browser echter sluit voordat het uploaden van gegevens is voltooid, mislukt het uploaden.
Zodra uw gegevens zijn geüpload, worden deze opgeslagen in een gegevenssetmodule en zijn ze beschikbaar voor elk experiment in uw werkruimte.
Wanneer u een experiment bewerkt, vindt u de gegevenssets die u hebt geüpload in de lijst Mijn gegevenssets onder de lijst Opgeslagen gegevenssets in het modulepalet. U kunt de gegevensset naar het experimentcanvas slepen en neerzetten wanneer u de gegevensset wilt gebruiken voor verdere analyse en machine learning.
Importeren uit onlinegegevensbronnen
Met behulp van de module Gegevens importeren kan uw experiment gegevens importeren uit verschillende onlinegegevensbronnen terwijl het experiment wordt uitgevoerd.
Notitie
Dit artikel bevat algemene informatie over de module Gegevens importeren. Zie het naslagonderwerp voor de module Import Data voor meer gedetailleerde informatie over de typen gegevens die u kunt openen, opmaken, parameters en antwoorden op veelgestelde vragen.
Met behulp van de module Gegevens importeren hebt u toegang tot gegevens uit een van de verschillende onlinegegevensbronnen terwijl uw experiment wordt uitgevoerd:
- Een web-URL met HTTP
- Hadoop met HiveQL
- Azure Blob Storage
- Azure-tabel
- Azure SQL-database. SQL Managed Instance of SQL Server
- Een gegevensfeedprovider, momenteel OData
- Azure Cosmos DB
Omdat deze trainingsgegevens worden geopend terwijl uw experiment wordt uitgevoerd, is het alleen beschikbaar in dat experiment. Ter vergelijking: gegevens die zijn opgeslagen in een gegevenssetmodule, zijn beschikbaar voor elk experiment in uw werkruimte.
Als u toegang wilt krijgen tot onlinegegevensbronnen in uw Studio-experiment (klassiek), voegt u de module Gegevens importeren toe aan uw experiment. Selecteer vervolgens de wizard Gegevens importeren starten onder Eigenschappen voor stapsgewijze instructies om de gegevensbron te selecteren en te configureren. U kunt ook handmatig gegevensbron selecteren onder Eigenschappen en de parameters opgeven die nodig zijn voor toegang tot de gegevens.
De onlinegegevensbronnen die worden ondersteund, worden opgenomen in de onderstaande tabel. Deze tabel bevat ook een overzicht van de bestandsindelingen die worden ondersteund en parameters die worden gebruikt voor toegang tot de gegevens.
Belangrijk
Op dit moment kunnen de modules Gegevens importeren en Gegevens exporteren alleen gegevens lezen en schrijven uit Azure-opslag die zijn gemaakt met het klassieke implementatiemodel. Met andere woorden, het nieuwe Azure Blob Storage-accounttype dat een dynamische-opslagtoegangslaag of statische-opslagtoegangslaag biedt, wordt nog niet ondersteund.
Over het algemeen geldt dat alle Azure-opslagaccounts die u mogelijk hebt gemaakt voordat deze serviceoptie beschikbaar werd, niet worden beïnvloed. Als u een nieuw account wilt maken, selecteert u Klassiek voor het implementatiemodel of gebruikt u Resource Manager en selecteert u Algemeen gebruik in plaats van Blob Storage voor accounttype.
Zie Azure Blob Storage: Dynamische en statische opslaglagen voor meer informatie.
Ondersteunde onlinegegevensbronnen
De Machine Learning Studio (klassiek) Import Data-module ondersteunt de volgende gegevensbronnen:
| Gegevensbron | Beschrijving | Parameters |
|---|---|---|
| Web-URL via HTTP | Leest gegevens in door komma's gescheiden waarden (CSV), door tabs gescheiden waarden (TSV), kenmerk-relationele bestandsindelingen (ARFF) en Support Vector Machines (SVM-light) vanaf elke web-URL die gebruikmaakt van HTTP | URL: Hiermee geeft u de volledige naam van het bestand, inclusief de site-URL en de bestandsnaam, met een willekeurige extensie. Gegevensindeling: Hiermee geeft u een van de ondersteunde gegevensindelingen op: CSV, TSV, ARFF of SVM-light. Als de gegevens een veldnamenrij hebben, worden deze gebruikt om kolomnamen toe te wijzen. |
| Hadoop/HDFS | Leest gegevens uit gedistribueerde opslag in Hadoop. U geeft de gewenste gegevens op met behulp van HiveQL, een SQL-achtige querytaal. HiveQL kan ook worden gebruikt om gegevens te aggregeren en gegevensfiltering uit te voeren voordat u de gegevens toevoegt aan Studio (klassiek). | Hive-databasequery: Hiermee geeft u de Hive-query op die wordt gebruikt om de gegevens te genereren. HCatalog-server-URI : Geef de naam van uw cluster op met behulp van de indeling <van de clusternaam.azurehdinsight.net>. Hadoop-gebruikersaccountnaam: Hiermee geeft u de Hadoop-gebruikersaccountnaam op die wordt gebruikt om het cluster in te richten. Wachtwoord voor Hadoop-gebruikersaccount : hiermee geeft u de referenties op die worden gebruikt bij het inrichten van het cluster. Zie Hadoop-clusters maken in HDInsight voor meer informatie. Locatie van uitvoergegevens: hiermee geeft u op of de gegevens zijn opgeslagen in een Hadoop Distributed File System (HDFS) of in Azure.
Als u uw uitvoergegevens opslaat in Azure, moet u de naam van het Azure-opslagaccount, de opslagtoegangssleutel en de naam van de opslagcontainer opgeven. |
| SQL-database | Leest gegevens die zijn opgeslagen in Azure SQL Database, SQL Managed Instance of in een SQL Server-database die wordt uitgevoerd op een virtuele Azure-machine. | Databaseservernaam: Hiermee geeft u de naam op van de server waarop de database wordt uitgevoerd.
Voer in het geval van een SQL-server die wordt gehost op een virtuele Azure-machine tcp:<Virtual Machine DNS-naam> in, 1433 Databasenaam : Hiermee geeft u de naam van de database op de server. Servergebruikersaccountnaam: Hiermee geeft u een gebruikersnaam op voor een account met toegangsmachtigingen voor de database. Wachtwoord voor servergebruikersaccount: hiermee geeft u het wachtwoord voor het gebruikersaccount op. Databasequery:Voer een SQL-instructie in die de gegevens beschrijft die u wilt lezen. |
| On-premises SQL-database | Leest gegevens die zijn opgeslagen in een SQL-database. | Gegevensgateway: hiermee geeft u de naam op van de Gegevensbeheer Gateway die is geïnstalleerd op een computer waarop deze toegang heeft tot uw SQL Server-database. Zie Geavanceerde analyses uitvoeren met Machine Learning Studio (klassiek) met behulp van gegevens van een SQL-server voor meer informatie over het instellen van de gateway. Databaseservernaam: Hiermee geeft u de naam op van de server waarop de database wordt uitgevoerd. Databasenaam : Hiermee geeft u de naam van de database op de server. Servergebruikersaccountnaam: Hiermee geeft u een gebruikersnaam op voor een account met toegangsmachtigingen voor de database. Gebruikersnaam en wachtwoord: klik op Waarden invoeren om uw databasereferenties in te voeren. U kunt geïntegreerde Windows-verificatie of SQL Server-verificatie gebruiken, afhankelijk van hoe uw SQL Server is geconfigureerd. Databasequery:Voer een SQL-instructie in die de gegevens beschrijft die u wilt lezen. |
| Azure-tabel | Leest gegevens uit de Table-service in Azure Storage. Als u grote hoeveelheden gegevens niet vaak leest, gebruikt u de Azure Table Service. Het biedt een flexibele, niet-relationele (NoSQL), zeer schaalbare, goedkope en maximaal beschikbare opslagoplossing. |
De opties in de wijziging Gegevens importeren zijn afhankelijk van of u toegang hebt tot openbare informatie of een privéopslagaccount waarvoor aanmeldingsreferenties zijn vereist. Dit wordt bepaald door het verificatietype dat de waarde 'PublicOrSAS' of 'Account' kan hebben, die elk een eigen set parameters heeft. Sas-URI (Public or Shared Access Signature): De parameters zijn:
Hiermee geeft u de rijen op die moeten worden gescand op eigenschapsnamen: de waarden zijn TopN om het opgegeven aantal rijen te scannen, of ScanAll om alle rijen in de tabel op te halen. Als de gegevens homogeen en voorspelbaar zijn, wordt u aangeraden TopN te selecteren en een getal voor N in te voeren. Voor grote tabellen kan dit leiden tot snellere leestijden. Als de gegevens zijn gestructureerd met sets eigenschappen die variëren op basis van de diepte en positie van de tabel, kiest u de optie ScanAll om alle rijen te scannen. Dit zorgt voor de integriteit van uw resulterende eigenschap en metagegevensconversie.
Accountsleutel: Hiermee geeft u de opslagsleutel op die is gekoppeld aan het account. Tabelnaam : hiermee geeft u de naam op van de tabel die de gegevens bevat die moeten worden gelezen. Rijen die moeten worden gescand op eigenschapsnamen: de waarden zijn TopN om het opgegeven aantal rijen te scannen, of ScanAll om alle rijen in de tabel op te halen. Als de gegevens homogeen en voorspelbaar zijn, raden we u aan TopN te selecteren en een getal voor N in te voeren. Voor grote tabellen kan dit leiden tot snellere leestijden. Als de gegevens zijn gestructureerd met sets eigenschappen die variëren op basis van de diepte en positie van de tabel, kiest u de optie ScanAll om alle rijen te scannen. Dit zorgt voor de integriteit van uw resulterende eigenschap en metagegevensconversie. |
| Azure Blob-opslag | Leest gegevens die zijn opgeslagen in de Blob-service in Azure Storage, inclusief afbeeldingen, ongestructureerde tekst of binaire gegevens. U kunt de Blob-service gebruiken om gegevens openbaar te maken of om toepassingsgegevens privé op te slaan. U hebt overal toegang tot uw gegevens via HTTP- of HTTPS-verbindingen. |
De opties in de module Gegevens importeren worden gewijzigd, afhankelijk van of u toegang hebt tot openbare informatie of een privéopslagaccount waarvoor aanmeldingsreferenties zijn vereist. Dit wordt bepaald door het verificatietype dat een waarde van 'PublicOrSAS' of 'Account' kan hebben. Sas-URI (Public or Shared Access Signature): De parameters zijn:
Bestandsindeling: Hiermee geeft u de indeling van de gegevens in de Blob-service op. De ondersteunde indelingen zijn CSV, TSV en ARFF.
Accountsleutel: Hiermee geeft u de opslagsleutel op die is gekoppeld aan het account. Pad naar container, map of blob : hiermee geeft u de naam op van de blob die de gegevens bevat die moeten worden gelezen. Blob-bestandsindeling: hiermee geeft u de indeling van de gegevens in de blobservice op. De ondersteunde gegevensindelingen zijn CSV, TSV, ARFF, CSV met een opgegeven codering en Excel.
U kunt de Excel-optie gebruiken om gegevens uit Excel-werkmappen te lezen. Geef in de optie Gegevensindeling van Excel aan of de gegevens zich in een Excel-werkbladbereik of in een Excel-tabel bevinden. Geef in het Excel-blad of de ingesloten tabeloptie de naam op van het blad of de tabel waaruit u wilt lezen. |
| Gegevensfeedprovider | Leest gegevens van een ondersteunde feedprovider. Momenteel wordt alleen de OData-indeling (Open Data Protocol) ondersteund. | Gegevensinhoudstype: Hiermee geeft u de OData-indeling op. Bron-URL: Hiermee geeft u de volledige URL voor de gegevensfeed op. De volgende URL leest bijvoorbeeld uit de Northwind-voorbeelddatabase: https://services.odata.org/northwind/northwind.svc/ |
Importeren uit een ander experiment
Er zijn momenten waarop u een tussenliggend resultaat uit het ene experiment wilt nemen en wilt gebruiken als onderdeel van een ander experiment. Hiervoor slaat u de module op als een gegevensset:
- Klik op de uitvoer van de module die u wilt opslaan als een gegevensset.
- Klik op Opslaan als gegevensset.
- Wanneer u hierom wordt gevraagd, voert u een naam en een beschrijving in waarmee u de gegevensset eenvoudig kunt identificeren.
- Klik op het vinkje OK .
Wanneer het opslaan is voltooid, is de gegevensset beschikbaar voor gebruik binnen elk experiment in uw werkruimte. U vindt deze in de lijst Opgeslagen gegevenssets in het modulepalet.