Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In this article, you learn how to set up and configure Apache Hadoop, Apache Spark, Apache Kafka, Interactive Query, or Apache HBase in Azure HDInsight. You also learn how to customize clusters and add security by joining them to a domain.
A Hadoop cluster consists of several virtual machines (VMs, also known as nodes) that are used for the distributed processing of tasks. HDInsight handles the implementation details of installation and configuration of individual nodes. You provide only general configuration information.
Important
HDInsight cluster billing starts after a cluster is created and stops when the cluster is deleted. Billing is prorated per minute, so always delete your cluster when it's no longer in use. Learn how to delete a cluster.
If you use multiple clusters together, you want to create a virtual network. If you use a Spark cluster, you also want to use the Hive Warehouse Connector. For more information, see Plan a virtual network for Azure HDInsight and Integrate Apache Spark and Apache Hive with the Hive Warehouse Connector.
Cluster setup methods
The following table shows the different methods you can use to set up an HDInsight cluster.
| Clusters created with | Web browser | Command line | REST API | SDK |
|---|---|---|---|---|
| Azure portal | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| Azure CLI | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Azure Resource Manager templates | ✅ |
This article walks you through setup in the Azure portal, where you can create an HDInsight cluster.
Basics
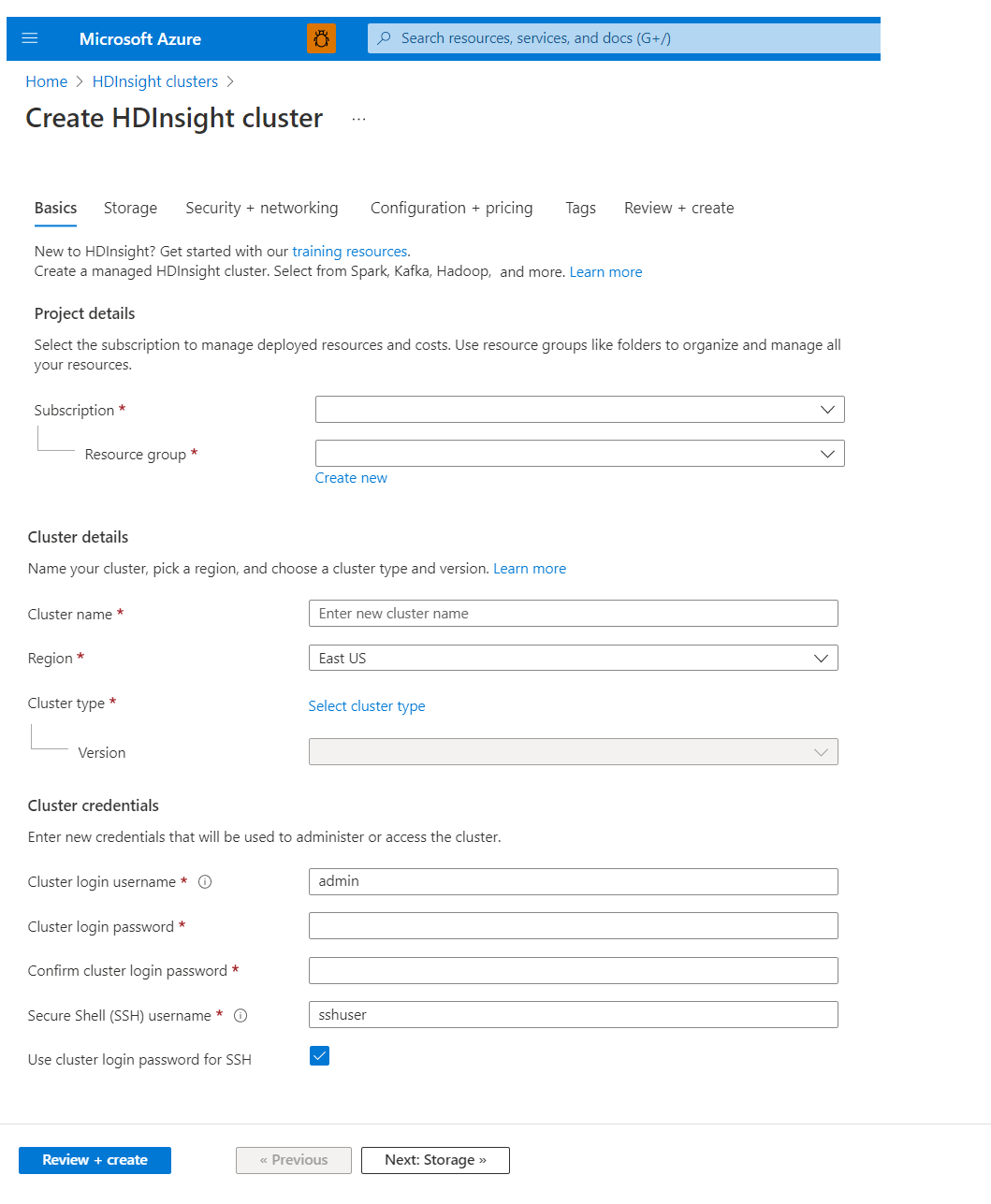
Project details
Azure Resource Manager helps you work with the resources in your application as a group, which is known as an Azure resource group. You can deploy, update, monitor, or delete all the resources for your application in a single coordinated operation.
Cluster details
Cluster details include the name, region, type, and version.
Cluster name
HDInsight cluster names have the following restrictions:
- Allowed characters: a-z, 0-9, and A-Z
- Maximum length: 59
- Reserved names: apps
- Cluster naming: The scope is for all Azure, across all subscriptions. The cluster name must be unique worldwide. The first six characters must be unique within a virtual network.
Region
You don't need to specify the cluster location explicitly. The cluster is in the same location as the default storage. For a list of supported regions, select the Region dropdown list on HDInsight pricing.
Cluster type
In the following table, HDInsight currently provides the cluster types, each with a set of components to provide certain functionalities.
Important
HDInsight clusters are available in various types, each for a single workload or technology. No supported method creates a cluster that combines multiple types, such as HBase on one cluster. If your solution requires technologies that are spread across multiple HDInsight cluster types, an Azure virtual network can connect the required cluster types.
| Cluster type | Functionality |
|---|---|
| Hadoop | Batch query and analysis of stored data. |
| HBase | Processing for large amounts of schemaless, NoSQL data. |
| Interactive Query | In-memory caching for interactive and faster Hive queries. |
| Kafka | A distributed streaming platform that you can use to build real-time streaming data pipelines and applications. |
| Spark | In-memory processing, interactive queries, micro-batch stream processing. |
Version
Choose the version of HDInsight for this cluster. For more information, see Supported HDInsight versions.
Cluster credentials
With HDInsight clusters, you can configure two user accounts during cluster creation:
- Cluster login username: Default username is admin. It uses the basic configuration on the Azure portal. It's also called Cluster user or HTTP user.
- Secure Shell (SSH) username: Used to connect to the cluster through SSH. For more information, see Use SSH with HDInsight.
The HTTP username has the following restrictions:
- Allowed special characters: _ and @
- Characters not allowed: #;."',/:!*?$(){}[]<>|&--=+%~^space
- Maximum length: 20
The SSH username has the following restrictions:
- Allowed special characters: _ and @
- Characters not allowed: #;."',/:!*?$(){}[]<>|&--=+%~^space
- Maximum length: 64
- Reserved names: hadoop, users, oozie, hive, mapred, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, administrator, admin, user, user1, test, user2, test1, user3, admin1, 1, 123, a, actuser, adm, admin2, aspnet, backup, console, David, guest, John, owner, root, server, sql, support, support_388945a0, sys, test2, test3, user4, user5, spark
Storage
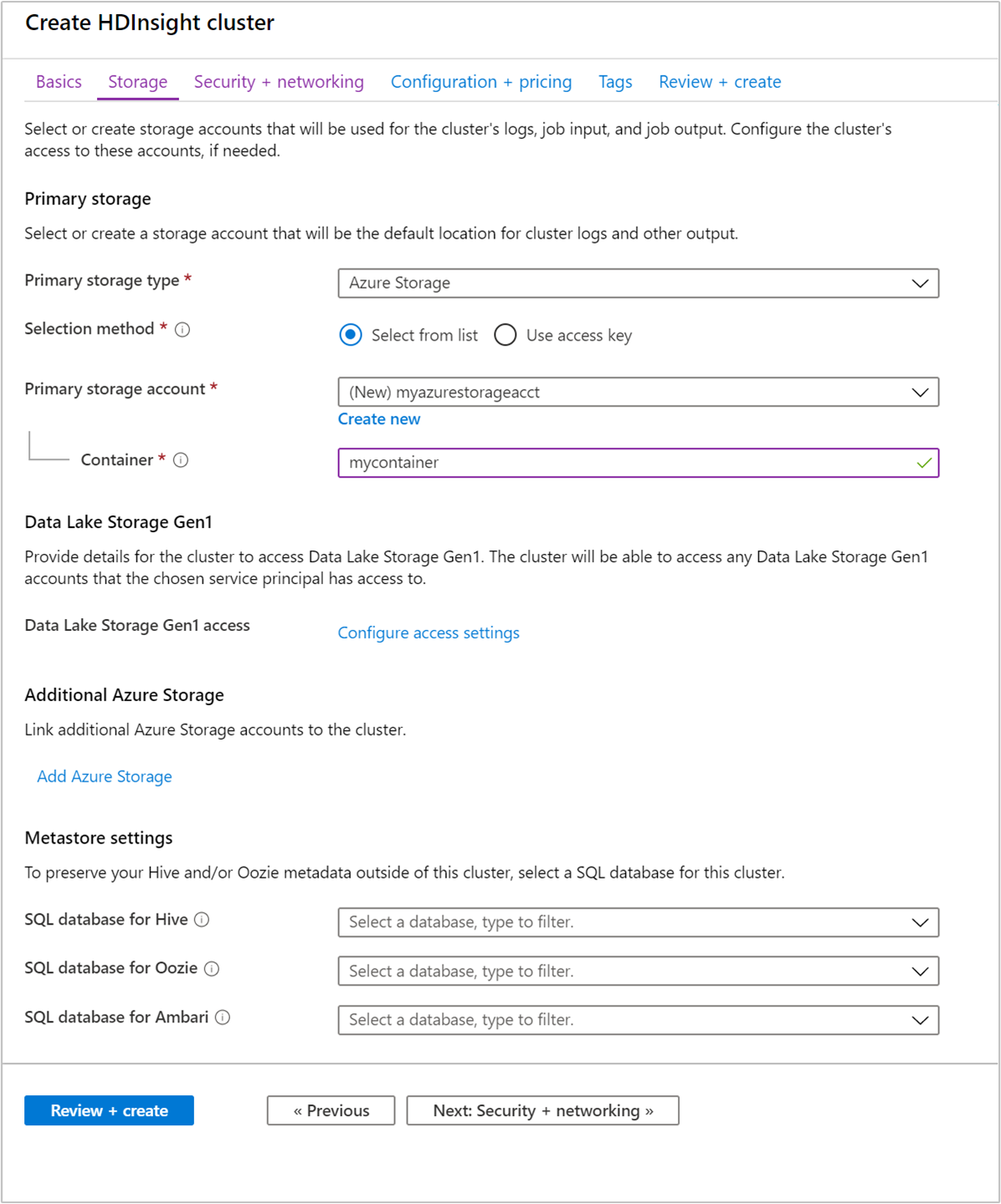
Although an on-premises installation of Hadoop uses the Hadoop Distributed File System (HDFS) for storage on the cluster, in the cloud you use storage endpoints connected to the cluster. Using cloud storage means that you can safely delete the HDInsight clusters used for computation while still retaining your data.
HDInsight clusters can use the following storage options:
- Azure Data Lake Storage Gen2
- Azure Storage General Purpose v2
- Azure Storage Block blob (only supported as secondary storage)
For more information on storage options with HDInsight, see Compare storage options for use with Azure HDInsight clusters.
Using more storage accounts in a different location from the HDInsight cluster isn't supported.
During configuration, for the default storage endpoint, you specify a blob container of a storage account or Data Lake Storage. The default storage contains application and system logs. Optionally, you can specify more linked storage accounts and Data Lake Storage accounts that the cluster can access. The HDInsight cluster and the dependent storage accounts must be in the same Azure location.
Note
The feature that requires secure transfer enforces all requests to your account through a secure connection. Only HDInsight cluster version 3.6 or newer supports this feature. For more information, see Create Apache Hadoop cluster with secure transfer storage accounts in Azure HDInsight.
Don't enable secure storage transfer after you create a cluster because using your storage account can result in errors. It's better to create a new cluster by using a storage account with secure transfer already enabled.
HDInsight doesn't automatically transfer, move, or copy your data stored in storage from one region to another.
Metastore settings
You can create optional Hive or Apache Oozie metastores. Not all cluster types support metastores, and Azure Synapse Analytics isn't compatible with metastores.
For more information, see Use external metadata stores in Azure HDInsight.
When you create a custom metastore, don't use dashes, hyphens, or spaces in the database name. These characters can cause the cluster creation process to fail.
SQL database for Hive
If you want to retain your Hive tables after you delete an HDInsight cluster, use a custom metastore. You can then attach the metastore to another HDInsight cluster.
An HDInsight metastore that's created for one HDInsight cluster version can't be shared across different HDInsight cluster versions. For a list of HDInsight versions, see Supported HDInsight versions.
You can use managed identities to authenticate with SQL database for Hive. For more information, see Use managed identity for SQL Database authentication in HDInsight.
The default metastore provides a SQL database with a basic tier 5 DTU limit (not upgradeable). It's suitable for basic testing purposes. For large or production workloads, we recommend that you migrate to an external metastore.
SQL database for Oozie
To increase performance when you use Oozie, use a custom metastore. A metastore can also provide access to Oozie job data after you delete your cluster.
You can use managed identities to authenticate with SQL database for Oozie. For more information, see Use managed identity for SQL Database authentication in HDInsight.
SQL database for Ambari
Ambari is used to monitor HDInsight clusters, make configuration changes, and store cluster management information and job history. With the custom Ambari database feature, you can deploy a new cluster and set up Ambari in an external database that you manage. For more information, see Custom Ambari database.
You can use managed identities to authenticate with SQL database for Ambari. For more information, see Use managed identity for SQL Database authentication in HDInsight.
You can't reuse a custom Oozie metastore. To use a custom Oozie metastore, you must provide an empty SQL database when you create the HDInsight cluster.
Security + networking
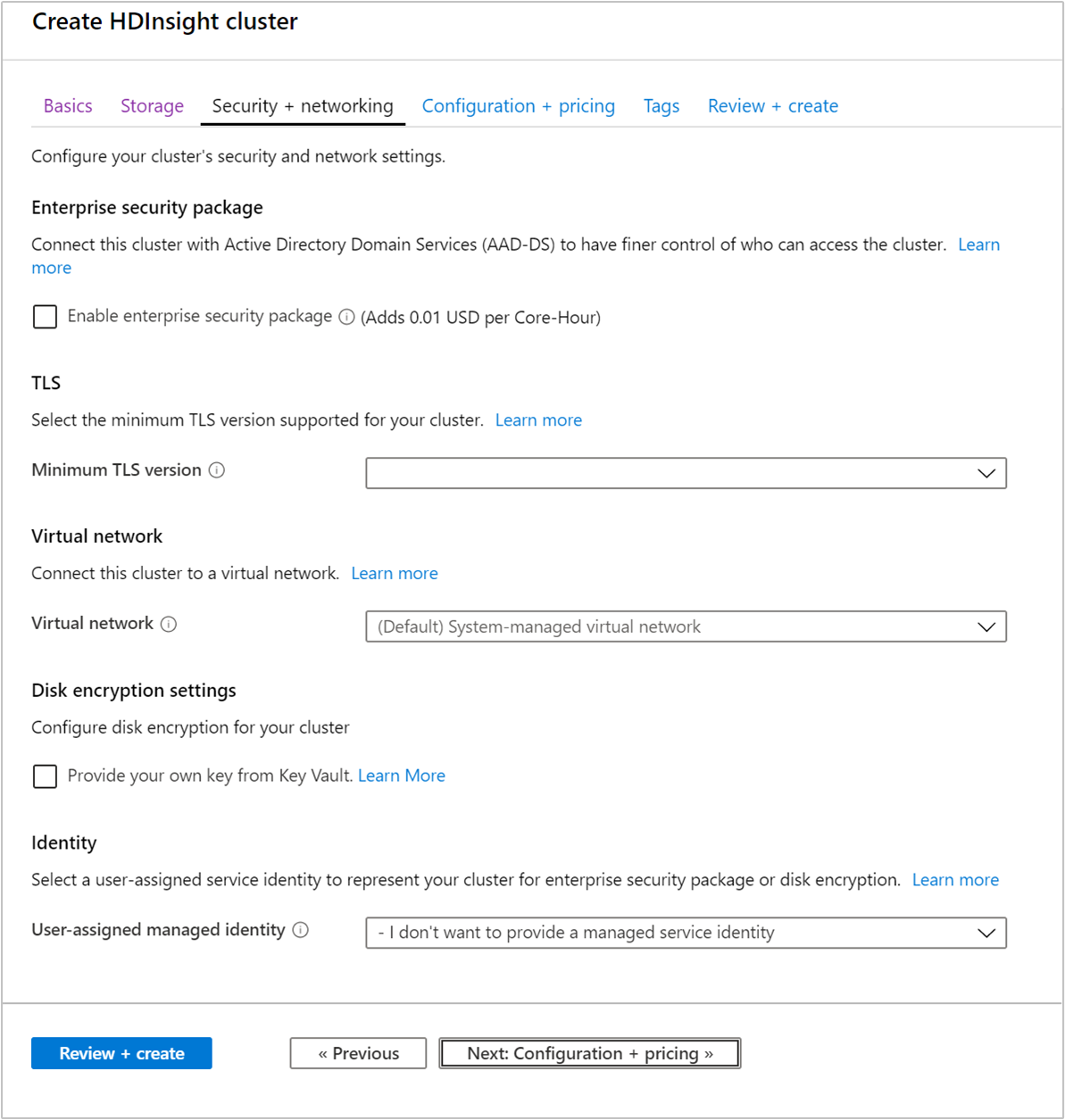
Enterprise security package
For Hadoop, Spark, HBase, Kafka, and Interactive Query cluster types, you can choose to enable the enterprise security package. This package provides the option to have a more secure cluster setup by using Apache Ranger and integrating with Microsoft Entra. For more information, see Overview of enterprise security in Azure HDInsight.
With the enterprise security package, you can integrate HDInsight with Microsoft Entra and Apache Ranger. You can use the enterprise security package to create multiple users.
For more information on creating a domain-joined HDInsight cluster, see Create domain-joined HDInsight sandbox environment.
Transport Layer Security
For more information, see Transport Layer Security.
Virtual network
If your solution requires technologies that are spread across multiple HDInsight cluster types, an Azure virtual network can connect the required cluster types. This configuration allows the clusters, and any code you deploy to them, to directly communicate with each other.
For more information on using an Azure virtual network with HDInsight, see Plan a virtual network for HDInsight.
For an example of using two cluster types within an Azure virtual network, see Use Apache Spark Structured Streaming with Apache Kafka. For more information about using HDInsight with a virtual network, including specific configuration requirements for the virtual network, see Plan a virtual network for HDInsight.
Disk encryption setting
For more information, see Customer-managed key disk encryption.
Kafka REST proxy
This setting is available only for the Kafka cluster type. For more information, see Using a REST proxy.
Identity
For more information, see Managed identities in Azure HDInsight.
Configuration + pricing
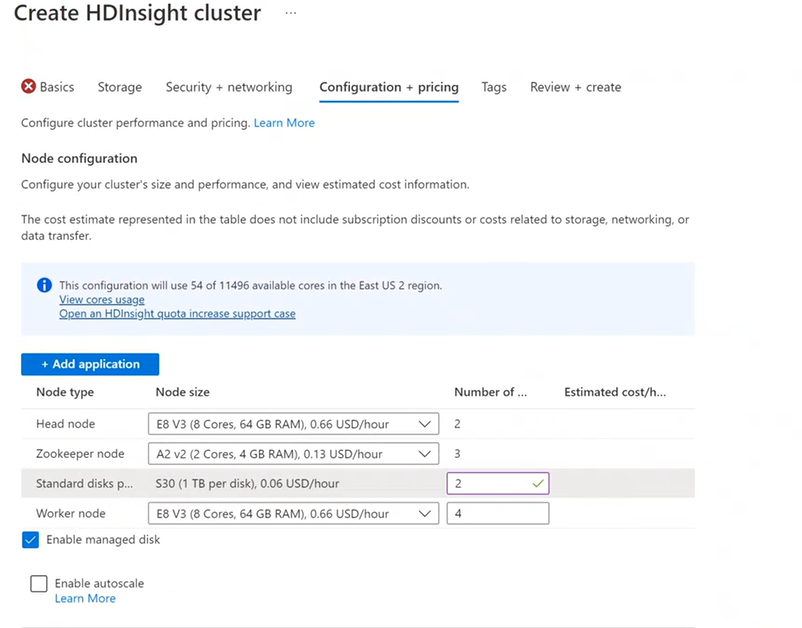
You're billed for node usage for as long as the cluster exists. Billing starts when a cluster is created and stops when the cluster is deleted. Clusters can't be deallocated or put on hold.
Node configuration
Each cluster type has its own number of nodes, terminology for nodes, and default VM size. In the following table, the number of nodes for each node type is listed in parentheses.
| Type | Nodes | Diagram |
|---|---|---|
| Hadoop | Head node (2), Worker node (1+) |
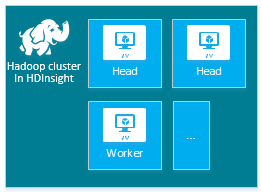
|
| HBase | Head server (2), Region server (1+), Master/ZooKeeper node (3) |
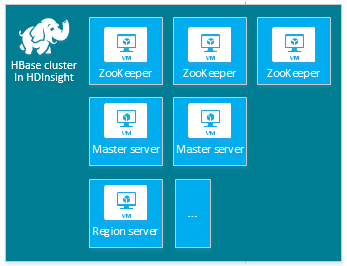
|
| Spark | Head node (2), Worker node (1+), ZooKeeper node (3) (free for A1 ZooKeeper VM size) |
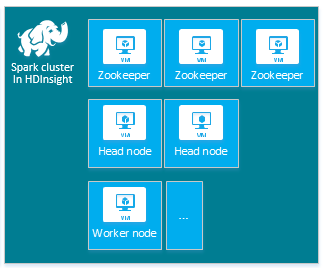
|
For more information, see Default node configuration and VM sizes for clusters.
The cost of HDInsight clusters determined by the number of nodes and the VM sizes for the nodes.
Different cluster types have different node types, numbers of nodes, and node sizes:
Hadoop cluster type default:
- Two head nodes
- Four worker nodes
If you're trying out HDInsight, we recommend that you use one worker node. For more information about HDInsight pricing, see HDInsight pricing.
Note
The cluster size limit varies among Azure subscriptions. Contact Azure billing support to increase the limit.
When you use the Azure portal to configure the cluster, the node size is available through the Configuration + pricing tab. In the portal, you can also see the cost associated with the different node sizes.
Virtual machine sizes
When you deploy clusters, choose compute resources based on the solution that you plan to deploy. The following VMs are used for HDInsight clusters:
- A and D1-4 series VMs: General-purpose Linux VM sizes
- D11-14 series VM: Memory-optimized Linux VM sizes
To find out what value you should use to specify a VM size when you create a cluster by using the different SDKs or Azure PowerShell, see VM sizes to use for HDInsight clusters. From this linked article, use the value in the Size column of the tables.
Important
If you need more than 32 worker nodes in a cluster, you must select a head node size with at least 8 cores and 14 GB of RAM.
For more information, see Sizes for VMs. For information about pricing of the various sizes, see HDInsight pricing.
Disk attachment
Note
The added disks are configured only for node manager local directories and not for datanode directories.
An HDInsight cluster comes with predefined disk space based on the version. Running some large applications can lead to insufficient disk space, with the disk-full error LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE and job failures.
You can add more disks to the cluster by using the local directory new feature NodeManager. At the time of Hive and Spark cluster creation, you can select the number of disks and add them to the worker nodes. The selected disks can be 1 TB each and are part of NodeManager local directories.
- On the Configuration + pricing tab, select Enable managed disk.
- From Standard disks, enter the number of disks.
- Select your worker node.
You can verify the number of disks on the Review + create tab, under Cluster configuration.
Add application
You can install HDInsight applications on a Linux-based HDInsight cluster. You can use applications that are provided by Microsoft or third parties or that you developed. For more information, see Install third-party Apache Hadoop applications on Azure HDInsight.
Most of the HDInsight applications are installed on an empty edge node. An empty edge node is a Linux VM with the same client tools installed and configured as in the head node. You can use the edge node for accessing the cluster, testing your client applications, and hosting your client applications. For more information, see Use empty edge nodes in HDInsight.
Script actions
You can install more components or customize cluster configuration by using scripts during creation. Such scripts are invoked via script actions, which is a configuration option that you can use from the Azure portal, HDInsight Windows PowerShell cmdlets, or the HDInsight .NET SDK. For more information, see Customize HDInsight cluster by using script actions.
Some native Java components, like Apache Mahout and Cascading, can run on the cluster as Java Archive (JAR) files. You can distribute these JAR files to storage and submit them to HDInsight clusters with Hadoop job submission mechanisms. For more information, see Submit Apache Hadoop jobs programmatically.
Note
If you have issues deploying JAR files to HDInsight clusters or calling JAR files on HDInsight clusters, contact Microsoft Support.
HDInsight doesn't support cascading and it isn't eligible for Microsoft Support. For lists of supported components, see What's new in the cluster versions provided by HDInsight.
Sometimes, you want to configure the following configuration files during the creation process:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
For more information, see Customize HDInsight clusters by using Bootstrap.