Zelfstudie 2: Kredietrisicomodellen trainen - Machine Learning Studio (klassiek)
VAN TOEPASSING OP: Machine Learning Studio (klassiek)
Machine Learning Studio (klassiek)  Azure Machine Learning
Azure Machine Learning
Belangrijk
De ondersteuning voor Azure Machine Learning-studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden om vóór die datum over te stappen naar Azure Machine Learning.
Vanaf 1 december 2021 kunt u geen nieuwe resources voor Azure Machine Learning-studio (klassiek) meer maken. Tot en met 31 augustus 2024 kunt u de bestaande resources van Azure Machine Learning-studio (klassiek) blijven gebruiken.
- Zie informatie over het verplaatsen van machine learning-projecten van ML Studio (klassiek) naar Azure Machine Learning.
- Meer informatie over Azure Machine Learning
De documentatie van ML-studio (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet meer bijgewerkt.
In deze zelfstudie wordt uitgebreid ingegaan op het ontwikkelingsproces van een predictive analytics-oplossing. U ontwikkelt een eenvoudig model in Machine Learning Studio (klassiek). Vervolgens implementeert u het model als een Machine Learning-webservice. Dit geïmplementeerde model kan voorspellingen doen op basis van nieuwe gegevens. Deze zelfstudie is deel twee van een driedelige reeks.
Stel dat u iemands kredietrisico moet voorspellen op basis van de gegevens die deze persoon in een kredietaanvraag heeft ingevuld.
Kredietrisicobeoordeling is een complex probleem, maar in deze zelfstudie wordt het enigszins vereenvoudigd. U gebruikt deze oplossing als voorbeeld van hoe u een predictive analytics-oplossing kunt maken met behulp van Machine Learning Studio (klassiek). U gebruikt Machine Learning Studio (klassiek) en een Machine Learning-webservice voor deze oplossing.
In deze driedelige zelfstudie begint u met openbaar beschikbare kredietrisicogegevens. Vervolgens ontwikkelt en traint u een voorspellend model. En ten slotte implementeert u het model als een webservice.
In deel één van de zelfstudie hebt u een Machine Learning Studio (klassiek)-werkruimte gemaakt, gegevens geüpload en een experiment gemaakt.
In dit deel van de zelfstudie gaat u het volgende doen:
- Meerdere modellen trainen
- De modellen beoordelen en evalueren
In deel drie van de zelfstudie, implementeert u het model als een webservice.
Vereisten
Voltooi deel één van de zelfstudie.
Meerdere modellen trainen
Een van de voordelen van het gebruik van Machine Learning Studio (klassiek) voor het maken van machine learning-modellen is de mogelijkheid om meer dan één type model tegelijk in één experiment uit te proberen en de resultaten te vergelijken. Dit type experiment helpt u de beste oplossing voor uw probleem te vinden.
In het experiment dat we ontwikkelen in deze zelfstudie, maakt u twee verschillende soorten modellen en vergelijkt vervolgens hun scoreresultaten om te beslissen welk algoritme u wilt gebruiken in ons laatste experiment.
Er zijn verschillende modellen waaruit u kunt kiezen. Als u de beschikbare modellen wilt zien, vouwt u het Machine Learning-knooppunt uit in het modulepalet en vervolgens Initialize Model en de knooppunten eronder. Voor dit experiment selecteert u de modules Ondersteuningsvectormachine met twee klassen (SVM) en de module Versterkte beslissingsstructuur met twee klassen.
U voegt zowel de module Versterkte beslissingsstructuur met twee klassen als de module Ondersteuningsvectormachine met twee klassen toe aan dit experiment.
Two-Class Boosted Decision Tree
Stel eerst het Boosted Decision Tree-model in.
Zoek de module Versterkte beslissingsstructuur met twee klassen in het modulepalet en sleep deze naar het canvas.
Zoek de module Train Model, sleep deze naar het canvas en sluit vervolgens de uitvoer van de module Two-Class Boosted Decision Tree aan op de linkerinvoerpoort van de module Train Model.
De module Versterkte beslissingsstructuur met twee klassen initialiseert het algemene model en Trainingsmodel gebruikt trainingsgegevens voor het trainen van het model.
Koppel de uitvoer naar linkeruitvoerpoort van de linkermodule Execute R Script aan de rechterinvoerpoort van de module Train Model (in deze zelfstudie gebruikt u de gegevens die afkomstig zijn van de linkerkant van de module Split Data voor het trainen).
Tip
U hoeft twee van de invoer- en een van de uitvoerpoorten van de module Execute R Script niet nodig voor dit experiment, daarom kunt u ze ongekoppeld laten.
Dit gedeelte van ons experiment ziet er nu ongeveer als volgt uit:
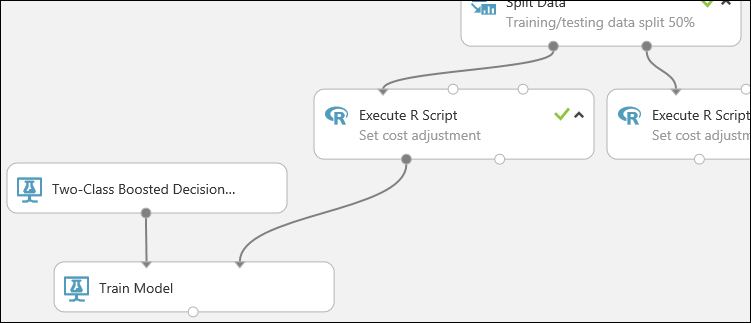
Nu moet u de module Trainingsmodel vertellen dat u wilt dat het model de waarde van het kredietrisico voorspelt.
Selecteer de module Train Model. Klik in het deelvenster Properties op Launch column selector.
In het dialoogvenster Select a single column typt u "Kredietrisico" in het zoekveld onder Available Columns, selecteert u "Kredietrisico" hieronder en klikt u op de rechter pijlknop ( > ) om "Kredietrisico’s" naar Selected Columns te verplaatsen.
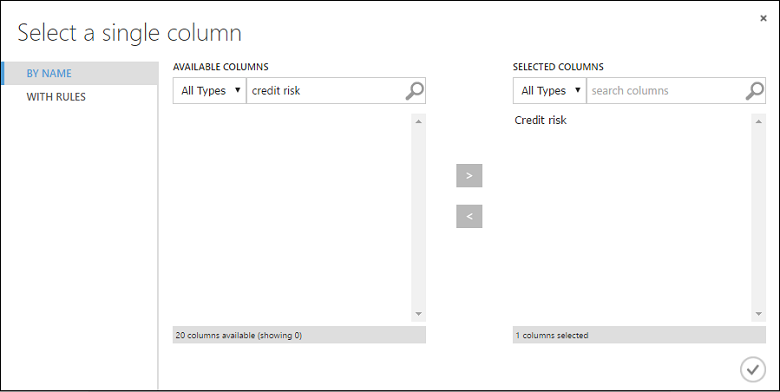
Klik op het OK-selectievakje.
Two-Class Support Vector Machine
Vervolgens stelt u het SVM-model in.
Eerst een beetje uitleg over SVM. Boosted Decision Trees werken goed met functies van elk type. Omdat de SVM-module een lineaire classificatie genereert, heeft het model dat wordt gegenereerd echter de beste testfout wanneer alle numerieke functies dezelfde schaal hebben. Als u alle numerieke functies naar dezelfde schaal wilt converteren, gebruikt u een 'Tanh'-transformatie (met de module Gegevens normaliseren). Dit transformeert onze cijfers naar het bereik [0,1]. De SVM-module converteert tekenreeksfuncties naar categorische functies en vervolgens naar binaire 0/1-functies, zodat u niet handmatig tekenreeksfuncties hoeft te transformeren. Ook moet u de kolom Kredietrisico (kolom 21) niet transformeren - deze is numeriek, maar het is de waarde die we het model aanleren om te voorspellen, daarom moet u deze ongewijzigd laten.
Als u het SVM-model instelt, doe dan het volgende:
Zoek de module Ondersteuningsvectormachine met twee klassen in het modulepalet en sleep deze naar het canvas.
Klik met de rechtermuisknop op de module Trainingsmodel, selecteer Kopiëren, klik vervolgens met de rechtermuisknop op het canvas en selecteer Plakken. De kopie van de module Trainingsmodel bevat dezelfde kolomselectie als het origineel.
Koppel de uitvoer van de module Ondersteuningsvectormachine met twee klassen aan de linkerinvoerpoort van de tweede Trainingsmodel-module.
Zoek de module Gegevens normaliseren en sleep deze naar het canvas.
Koppel de linkeruitvoer van de linkermodule Execute R Script aan de invoerpoort van deze module (let op dat de uitvoerpoort van een module met meer dan één andere module kan zijn verbonden).
Koppel de linkeruitvoerpoort van de module Gegevens normaliseren aan de rechterinvoerpoort van de tweede Trainingsmodel-module.
Zo ziet dit deel van het experiment er ongeveer uit nadat het is uitgevoerd:
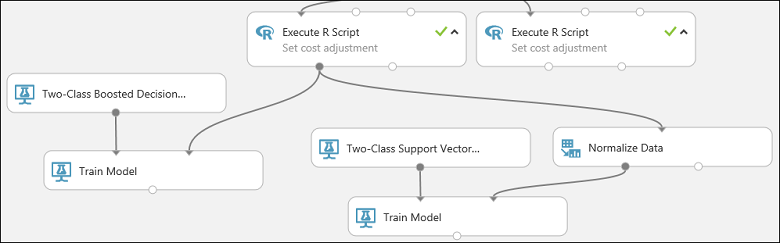
Configureer nu de module Gegevens normaliseren:
Selecteer de module Gegevens normaliseren. Selecteer in het Properties-venster Tanh als parameter voor Transformation method.
Klik op Launch column selector, selecteer "No columns" voor Begin With, selecteer Include in de eerste vervolgkeuzelijst, selecteer column type in de tweede vervolgkeuzelijst en selecteer Numeric in de derde vervolgkeuzelijst. Hiermee wordt aangegeven dat alle numerieke kolommen (en alleen numerieke) worden getransformeerd.
Klik op het plusteken (+) aan de rechterkant van deze rij. Hiermee maakt u een rij van de vervolgkeuzelijsten. Selecteer Exclude in de eerste vervolgkeuzelijst, selecteer column names in de tweede vervolgkeuzelijst en voer "Kredietrisico" in het tekstveld in. Hiermee wordt aangegeven dat de kolom Kredietrisico's moet worden genegeerd (u moet dit doen omdat deze kolom numeriek is en zou worden omgezet als u deze niet uitsluit).
Klik op het OK-selectievakje.
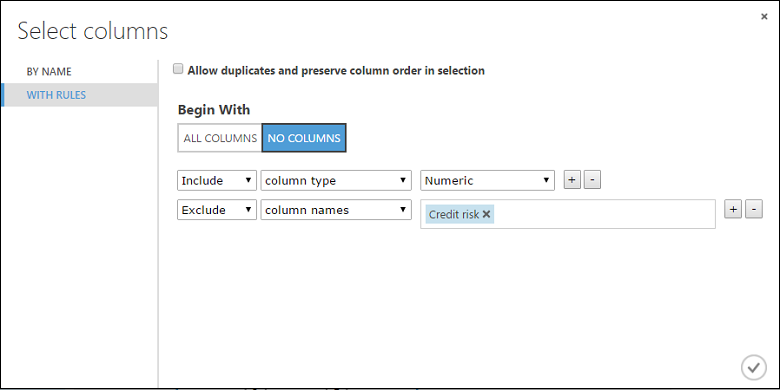
De module Gegevens normaliseren is nu ingesteld om een Tanh-transformatie uit te voeren op alle numerieke kolommen, met uitzondering van de kolom Kredietrisico's.
De modellen beoordelen en evalueren
U gebruikt de testgegevens die waren gescheiden door de module Gegevens splitsen om onze getrainde modellen te beoordelen. U kunt vervolgens de resultaten van de twee modellen vergelijken om te zien welke betere resultaten heeft gegenereerd.
De modules Score Model toevoegen
Zoek de module Beoordelingsmodel en sleep deze naar het canvas.
Zoek de module Train Model, sleep deze naar het canvas en sluit vervolgens de uitvoer van de module Two-Class Boosted Decision Tree aan op de linkerinvoerpoort van de module Score Model.
Verbind de rechtermodule R-script uitvoeren (onze testgegevens) met de rechterinvoerpoort van de module Beoordelingsmodel.
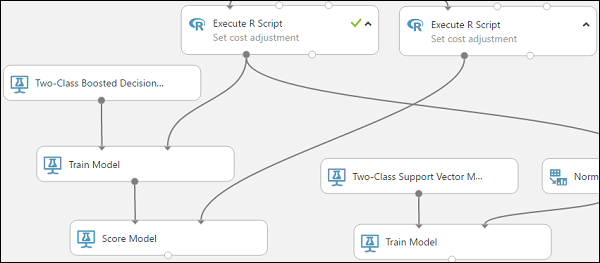
De module Score Model kan nu de kredietinformatie uit de testgegevens halen via het model en de voorspellingen vergelijken die het model genereert met de kolom Kredietrisico in de testgegevens.
Kopieer en plak de module Beoordelingsmodel om een tweede kopie te maken.
Koppel de uitvoer van het SVM-model (de uitvoerpoort van de module Train Model die verbonden is met de module Two-Class Support Vector Machine) aan de invoerpoort van de tweede Score Model-module.
Voor het SVM-model moet u de dezelfde transformatie uitvoeren op de testgegevens als u met de trainingsgegevens heeft gedaan. Kopieer en plak daarom de module Gegevens normaliseren om een tweede kopie te maken en verbind deze met de rechtermodule R-script uitvoeren.
Koppel de linkeruitvoerpoort van de tweede module Gegevens normaliseren aan de rechterinvoerpoort van de tweede Trainingsmodel-module.
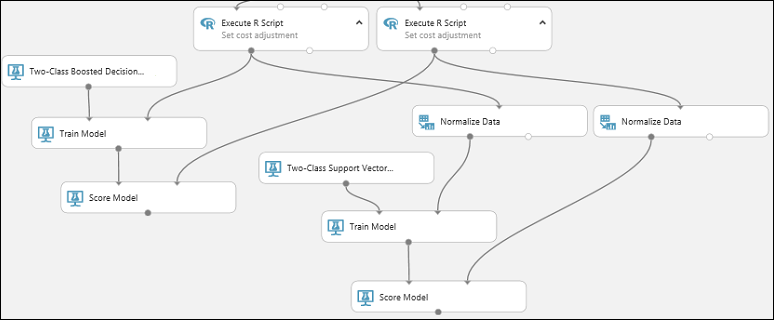
De module Evaluate Model toevoegen
Voor het evalueren van de twee beoordelingsresultaten en om deze te vergelijken, gebruikt u een module Model evalueren.
Zoek de module Model evalueren en sleep deze naar het canvas.
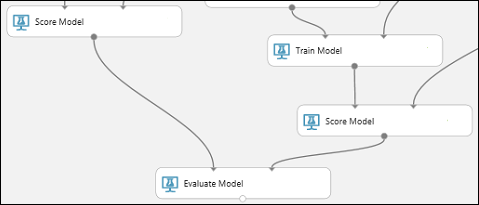
Koppel de uitvoerpoort van de Score Model-module die is gekoppeld aan het Boosted Decision Tree-model aan de linkerinvoerpoort van de Evaluate Model-module.
Verbind de andere module Beoordelingsmodel met de rechterinvoerpoort.
Voer het experiment uit en controleer de resultaten
Als u wilt het experiment uitvoeren, klikt u op de knop RUN onder het canvas. Dit kan enkele minuten duren. Een draaiende indicator op elke module laat zien dat deze wordt uitgevoerd en er wordt een groen vinkje weergegeven wanneer de module is voltooid. Wanneer alle modules een groen vinkje hebben, is het experiment voltooid.
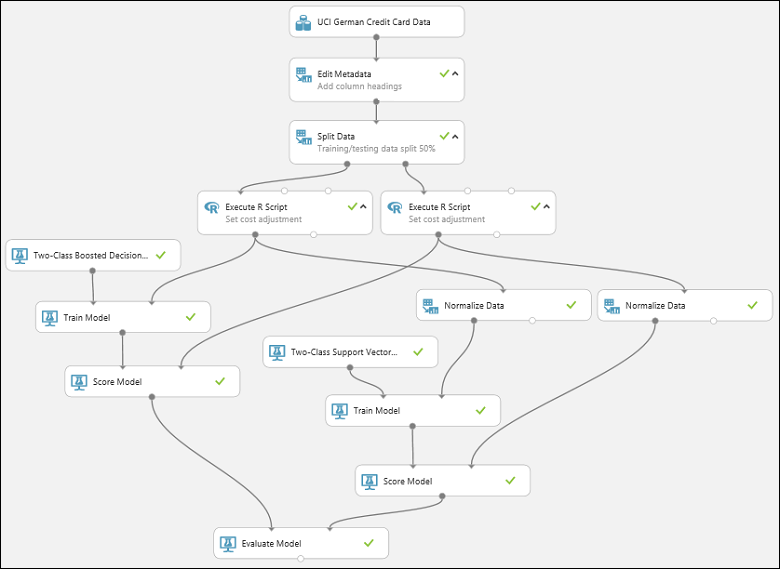
Het experiment zou er nu ongeveer zo uit moeten zien:
Klik op de uitvoerpoort onder in de module Model evalueren en klik op Visualiseren.
De module Model evalueren produceert een tweetal curven en metrische gegevens waarmee u de resultaten van de twee modellen kunt vergelijken. U kunt de resultaten als Receiver Operator Characteristic (ROC)-curven, Precision/Recall-curven of Lift-curven weergeven. Aanvullende gegevens die worden weergegeven, bevatten een verwarringsmatrix, cumulatieve waarden voor het gebied onder de curve (AUC) en andere metrische gegevens. U kunt de drempelwaarde wijzigen door de schuifregelaar naar links of rechts te bewegen en te zien hoe dit van invloed is op de set met metrische gegevens.
Aan de rechterkant van de grafiek, klikt u op Scored dataset of Scored dataset to compare om de bijbehorende curve te markeren en de bijbehorende metrische gegevens te tonen die hieronder worden weergegeven. In de legenda voor de curven komt "Scored dataset" overeen met de linkerinvoerpoort van de moduleEvaluate Model. In ons geval is dit het Boosted Decision Tree-model. "Scored dataset to compare" komt overeen met de juiste invoerpoort - het SVM-model in ons geval. Wanneer u op een van deze labels klikt, wordt de curve voor dit model gemarkeerd en de worden bijbehorende metrische gegevens weergegeven, zoals u ziet in de volgende afbeelding.
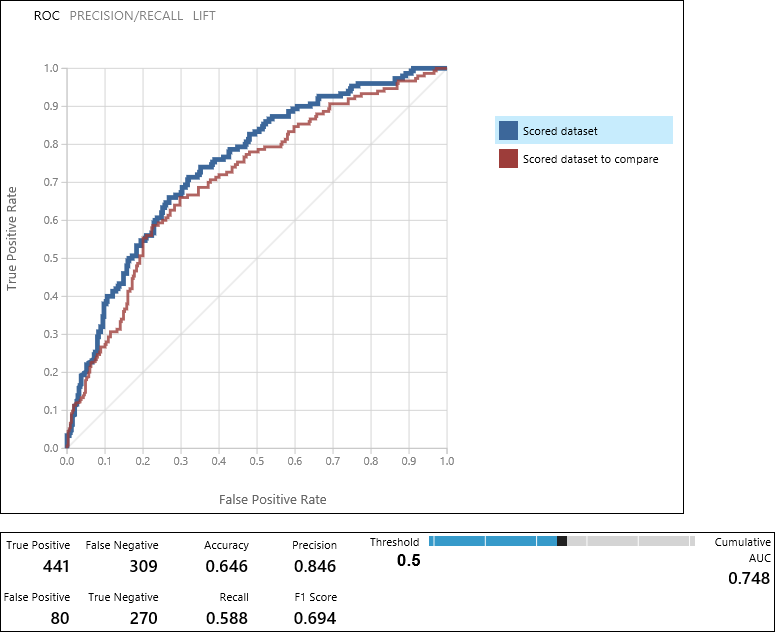
Door deze waarden te onderzoeken, kunt u bepalen welk model de resultaten die u zoekt het dichtst benadert. U kunt teruggaan en uw experiment herhalen door parameterwaarden in de verschillende modellen te wijzigen.
De wetenschap en kunst van het interpreteren van deze resultaten en het afstemmen van de modelprestaties vallen buiten deze zelfstudie. U kunt de volgende artikelen lezen voor meer informatie:
- Modelprestaties evalueren in Machine Learning Studio (klassiek)
- Parameters kiezen om uw algoritmen te optimaliseren in Machine Learning Studio (klassiek)
- Modelresultaten interpreteren in Machine Learning Studio (klassiek)
Tip
Telkens wanneer u het experiment uitvoert, wordt een record van deze iteratie opgeslagen in de uitvoeringsgeschiedenis. U kunt deze iteraties bekijken en ze opnieuw bekijken door te klikken op VIEW RUN HISTORY onder het canvas. U kunt ook klikken op Prior Ru in het Properties-venster om terug te keren naar de iteratie direct vóór de versie die u hebt geopend.
U kunt een kopie van de iteraties van uw experiment maken door te klikken op SAVE AS onder het canvas. Gebruik de eigenschappen Summary en Description van het experiment om bij te houden wat u hebt geprobeerd in uw iteraties.
Zie Experimentiteraties beheren in Machine Learning Studio (klassiek) voor meer informatie.
Resources opschonen
Als u de resources die u aan de hand van dit artikel hebt gemaakt, niet meer nodig hebt, verwijdert u ze om te voorkomen dat er kosten in rekening worden gebracht. Instructies hierover vindt u in het artikel Gebruikersgegevens binnen producten exporteren en verwijderen.
Volgende stappen
In deze zelfstudie hebt u de volgende stappen voltooid:
- Een experiment maken
- Meerdere modellen trainen
- De modellen beoordelen en evalueren
U kunt nu de modellen voor deze gegevens implementeren.