Functieselectie op basis van filters
In dit artikel wordt beschreven hoe u het onderdeel Functieselectie op basis van filters gebruikt in de Azure Machine Learning-ontwerpfunctie. Dit onderdeel helpt u bij het identificeren van de kolommen in uw invoergegevensset die de grootste voorspellende kracht hebben.
Over het algemeen verwijst functieselectie naar het proces van het toepassen van statistische tests op invoer, op basis van een opgegeven uitvoer. Het doel is om te bepalen welke kolommen beter voorspellend zijn voor de uitvoer. Het onderdeel Functieselectie op basis van filter biedt meerdere algoritmen voor functieselectie waaruit u kunt kiezen. Het onderdeel bevat correlatiemethoden zoals Pearson-correlatie en chi-kwadraatwaarden.
Wanneer u het onderdeel Functieselectie op basis van filter gebruikt, geeft u een gegevensset op en identificeert u de kolom die het label of de afhankelijke variabele bevat. Vervolgens geeft u één methode op voor het meten van de urgentie van functies.
Het onderdeel voert een gegevensset uit die de beste functiekolommen bevat, gerangschikt op voorspellend vermogen. Ook worden de namen van de functies en hun scores uit de geselecteerde metrische gegevens uitgevoerd.
Wat is functieselectie op basis van filters?
Dit onderdeel voor functieselectie wordt 'op basis van filters' genoemd, omdat u de geselecteerde metrische gegevens gebruikt om irrelevante kenmerken te vinden. Vervolgens filtert u redundante kolommen uit uw model. U kiest één statistische meting die bij uw gegevens past en het onderdeel berekent een score voor elke functiekolom. De kolommen worden geretourneerd op basis van hun functiescores.
Door de juiste functies te kiezen, kunt u de nauwkeurigheid en efficiëntie van de classificatie mogelijk verbeteren.
Normaal gesproken gebruikt u alleen de kolommen met de beste scores om uw voorspellende model te bouwen. Kolommen met slechte functieselectiescores kunnen in de gegevensset worden achtergelaten en genegeerd wanneer u een model bouwt.
Een metrische waarde voor functieselectie kiezen
Het onderdeel Filter-Based Functieselectie biedt diverse metrische gegevens voor het beoordelen van de informatiewaarde in elke kolom. In deze sectie vindt u een algemene beschrijving van elk metrische gegeven en de wijze waarop deze wordt toegepast. Aanvullende vereisten voor het gebruik van elk metrische gegeven vindt u in de technische opmerkingen en in de instructies voor het configureren van elk onderdeel.
Pearson correlatie
De correlatiestatistiek van Pearson, of de correlatiecoëfficiënt van Pearson, wordt in statistische modellen ook wel de
rwaarde genoemd. Voor twee variabelen wordt een waarde geretourneerd die de sterkte van de correlatie aangeeft.De correlatiecoëfficiënt van Pearson wordt berekend door de covariantie van twee variabelen te nemen en te delen door het product van hun standaarddeviaties. Schaalwijzigingen in de twee variabelen hebben geen invloed op de coëfficiënt.
Chi-kwadraat
De tweewegs chi-kwadraattest is een statistische methode die meet hoe dicht de verwachte waarden bij de werkelijke resultaten liggen. Bij de methode wordt ervan uitgegaan dat variabelen willekeurig zijn en zijn genomen uit een adequate steekproef van onafhankelijke variabelen. De resulterende chi-kwadraatstatistiek geeft aan hoe ver de resultaten af liggen van het verwachte (willekeurige) resultaat.
Tip
Als u een andere optie nodig hebt voor de aangepaste functieselectiemethode, gebruikt u het onderdeel R-script uitvoeren .
Selectie van Filter-Based-functie configureren
U kiest een standaard statistische metrische waarde. Het onderdeel berekent de correlatie tussen een paar kolommen: de labelkolom en een functiekolom.
Voeg het onderdeel Filter-Based Functieselectie toe aan uw pijplijn. U vindt deze in de categorie Functieselectie in de ontwerpfunctie.
Verbinding maken met een invoergegevensset die ten minste twee kolommen bevat die mogelijke functies zijn.
Als u ervoor wilt zorgen dat een kolom wordt geanalyseerd en een functiescore wordt gegenereerd, gebruikt u het onderdeel Metagegevens bewerken om het kenmerk IsFeature in te stellen.
Belangrijk
Zorg ervoor dat de kolommen die u als invoer oplevert, potentiële functies zijn. Een kolom met één waarde heeft bijvoorbeeld geen informatiewaarde.
Als u weet dat sommige kolommen slechte functies zouden hebben, kunt u deze verwijderen uit de kolomselectie. U kunt ook het onderdeel Metagegevens bewerken gebruiken om ze te markeren als Categorisch.
Kies voor Functiescoremethode een van de volgende tot stand gebrachte statistische methoden die u wilt gebruiken bij het berekenen van scores.
Methode Vereisten Pearson correlatie Label kan tekst of numeriek zijn. Functies moeten numeriek zijn. Chi-kwadraat Labels en functies kunnen tekst of numeriek zijn. Gebruik deze methode voor het berekenen van het belang van functies voor twee categorische kolommen. Tip
Als u de geselecteerde metrische waarde wijzigt, worden alle andere selecties opnieuw ingesteld. Zorg er dus voor dat u deze optie eerst instelt.
Selecteer de optie Alleen functiekolommen gebruiken om alleen een score te genereren voor kolommen die eerder zijn gemarkeerd als functies.
Als u deze optie uitschakelt, maakt het onderdeel een score voor elke kolom die anders aan de criteria voldoet, tot het aantal kolommen dat is opgegeven in Aantal gewenste functies.
Selecteer voor Doelkolom de optie Kolomkiezer starten om de labelkolom op naam of index te kiezen. (Indexen zijn gebaseerd op één.)
Een labelkolom is vereist voor alle methoden waarvoor statistische correlatie is vereist. Het onderdeel retourneert een ontwerptijdfout als u geen labelkolom of meerdere labelkolommen kiest.Voer bij Aantal gewenste functies het aantal functiekolommen in dat u wilt retourneren als resultaat:
Het minimum aantal functies dat u kunt opgeven is één, maar we raden u aan deze waarde te verhogen.
Als het opgegeven aantal gewenste functies groter is dan het aantal kolommen in de gegevensset, worden alle functies geretourneerd. Zelfs functies met nul scores worden geretourneerd.
Als u minder resultaatkolommen opgeeft dan er functiekolommen zijn, worden de functies gerangschikt op aflopende score. Alleen de belangrijkste functies worden geretourneerd.
Verzend de pijplijn.
Belangrijk
Als u op filter gebaseerde functieselectie wilt gebruiken in deductie, moet u Transformatie kolommen selecteren gebruiken om het geselecteerde resultaat op te slaan en Transformatie toepassen om de geselecteerde functietransformatie toe te passen op de scoregegevensset.
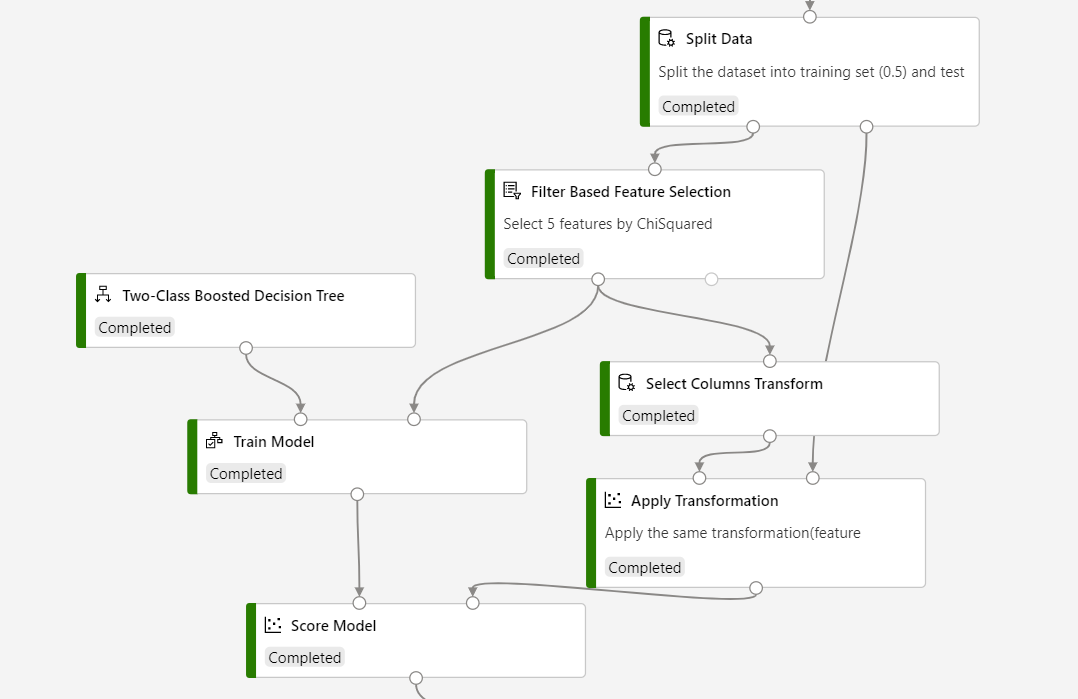
Raadpleeg de volgende schermopname om uw pijplijn te bouwen om ervoor te zorgen dat de kolomselecties hetzelfde zijn voor het scoreproces.
Resultaten
Nadat de verwerking is voltooid:
Als u een volledige lijst met de geanalyseerde functiekolommen en de bijbehorende scores wilt zien, klikt u met de rechtermuisknop op het onderdeel en selecteert u Visualiseren.
Als u de gegevensset wilt weergeven op basis van uw selectiecriteria voor functies, klikt u met de rechtermuisknop op het onderdeel en selecteert u Visualiseren.
Als de gegevensset minder kolommen bevat dan verwacht, controleert u de onderdeelinstellingen. Controleer ook de gegevenstypen van de kolommen die als invoer zijn opgegeven. Als u bijvoorbeeld Aantal gewenste functies instelt op 1, bevat de uitvoergegevensset slechts twee kolommen: de labelkolom en de meest gerangschikte functiekolom.
Technische opmerkingen
Implementatiegegevens
Als u Pearson-correlatie gebruikt voor een numerieke functie en een categorisch label, wordt de functiescore als volgt berekend:
Voor elk niveau in de categorische kolom berekent u het voorwaardelijke gemiddelde van de numerieke kolom.
Correleert de kolom met voorwaardelijke gemiddelden met de numerieke kolom.
Vereisten
Er kan geen functieselectiescore worden gegenereerd voor een kolom die is aangewezen als een kolom Label of Score .
Als u een scoremethode probeert te gebruiken met een kolom van een gegevenstype die niet door de methode wordt ondersteund, treedt er een fout op in het onderdeel. Of er wordt een nulscore toegewezen aan de kolom.
Als een kolom logische waarden (waar/onwaar) bevat, worden deze verwerkt als
True = 1enFalse = 0.Een kolom kan geen functie zijn als deze is aangewezen als label of score.
Hoe ontbrekende waarden worden verwerkt
U kunt geen kolom met alle ontbrekende waarden opgeven als doelkolom (label).
Als een kolom ontbrekende waarden bevat, negeert het onderdeel deze wanneer de score voor de kolom wordt berekenen.
Als een kolom die is aangewezen als een functiekolom alle ontbrekende waarden bevat, wijst het onderdeel een nulscore toe.
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.