Kolomtransformatie selecteren
In dit artikel wordt beschreven hoe u het onderdeel Select Columns Transform gebruikt in Azure Machine Learning Designer. Het doel van het onderdeel Select Columns Transform is ervoor te zorgen dat een voorspelbare, consistente set kolommen wordt gebruikt in downstream machine learning-bewerkingen.
Dit onderdeel is handig voor taken zoals scoren, waarvoor specifieke kolommen nodig zijn. Wijzigingen in de beschikbare kolommen kunnen de pijplijn verbreken of de resultaten wijzigen.
U gebruikt Select Columns Transform om een set kolommen te maken en op te slaan. Gebruik vervolgens het onderdeel Transformatie toepassen om deze selecties toe te passen op nieuwe gegevens.
Select Columns Transform gebruiken
In dit scenario wordt ervan uitgegaan dat u functieselectie wilt gebruiken om een dynamische set kolommen te genereren die worden gebruikt voor het trainen van een model. Om ervoor te zorgen dat kolomselecties hetzelfde zijn voor het scoreproces, gebruikt u het onderdeel Kolommen transformeren selecteren om de kolomselecties vast te leggen en deze elders in de pijplijn toe te passen.
Voeg een invoergegevensset toe aan uw pijplijn in de ontwerpfunctie.
Voeg een exemplaar van functieselectie op basis van filters toe.
Verbind de onderdelen en configureer het onderdeel voor functieselectie om automatisch een aantal beste functies in de invoergegevensset te vinden.
Voeg een exemplaar van Train Model toe en gebruik de uitvoer van functieselectie op basis van filters als invoer voor training.
Belangrijk
Omdat het belang van functies is gebaseerd op de waarden in de kolom, kunt u niet van tevoren weten welke kolommen beschikbaar zijn voor invoer voor Train Model.
Voeg een exemplaar van het onderdeel Kolommen transformeren selecteren toe.
Met deze stap wordt een kolomselectie gegenereerd als een transformatie die kan worden opgeslagen of toegepast op andere gegevenssets. Deze stap zorgt ervoor dat de kolommen die in de functieselectie worden geïdentificeerd, worden opgeslagen zodat andere onderdelen opnieuw kunnen worden gebruikt.
Voeg het onderdeel Score Model toe.
Verbind de invoergegevensset niet. Voeg in plaats daarvan het onderdeel Transformatie toepassen toe en verbind de uitvoer van de functieselectietransformatie.
De pijplijnstructuur moet er als volgt uitzien:
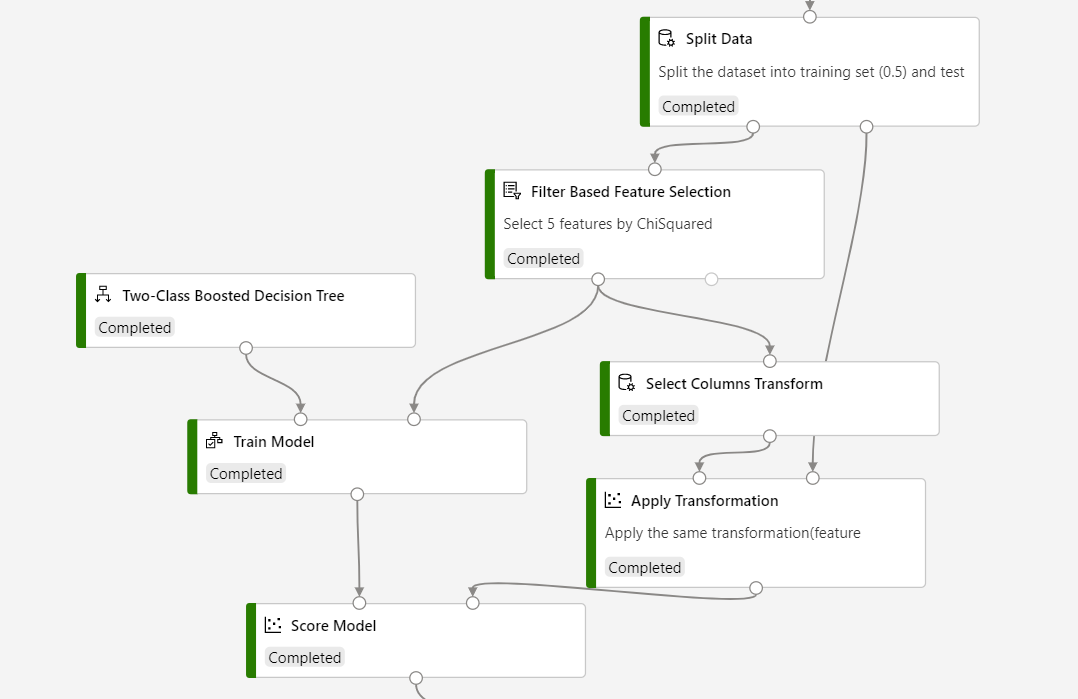
Belangrijk
U kunt niet verwachten dat u functieselectie op basis van filters toepast op de scoregegevensset en dezelfde resultaten krijgt. Omdat functieselectie is gebaseerd op waarden, kan het een andere set kolommen kiezen, waardoor de scorebewerking mislukt.
Verzend de pijplijn.
Dit proces voor het opslaan en vervolgens toepassen van een kolomselectie zorgt ervoor dat hetzelfde gegevensschema beschikbaar is voor training en scoren.
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.