Overzicht van prognosemethoden in AutoML
Dit artikel is gericht op de methoden die AutoML gebruikt om tijdreeksgegevens voor te bereiden en prognosemodellen te bouwen. Instructies en voorbeelden voor het trainen van prognosemodellen in AutoML vindt u in ons artikel over het instellen van AutoML voor het voorspellen van tijdreeksen .
AutoML gebruikt verschillende methoden om tijdreekswaarden te voorspellen. Deze methoden kunnen grofweg worden toegewezen aan twee categorieën:
- Tijdreeksmodellen die gebruikmaken van historische waarden van de doelhoeveelheid om voorspellingen in de toekomst te doen.
- Regressie- of verklarende modellen die voorspellende variabelen gebruiken om waarden van het doel te voorspellen.
Denk bijvoorbeeld aan het probleem van het voorspellen van de dagelijkse vraag naar een bepaald merk sinaasappelsap uit een supermarkt. Laat $y_t$ de vraag voor dit merk op dag $t$ vertegenwoordigen. Een tijdreeksmodel voorspelt de vraag op $t+1$ met behulp van een functie van historische vraag,
$y_{t+1} = f(y_t, y_{t-1}, \ldots, y_{t-s})$.
De functie $f$ heeft vaak parameters die we afstemmen met behulp van waargenomen vraag uit het verleden. De hoeveelheid geschiedenis die $f$ gebruikt om voorspellingen te doen, $s$, kan ook worden beschouwd als een parameter van het model.
Het tijdreeksmodel in het voorbeeld van de vraag naar sinaasappelsap is mogelijk niet nauwkeurig genoeg, omdat er alleen informatie over eerdere vraag wordt gebruikt. Er zijn veel andere factoren die waarschijnlijk invloed hebben op de toekomstige vraag, zoals prijs, dag van de week en of het een vakantie is of niet. Overweeg een regressiemodel dat gebruikmaakt van deze voorspellingsvariabelen,
$y = g(\text{price}, \text{day of week}, \text{holiday})$.
Nogmaals, $g$ heeft over het algemeen een set parameters, waaronder die voor regularisatie, dat AutoML tunest met behulp van eerdere waarden van de vraag en de voorspellers. We laten $t$ weg uit de expressie om te benadrukken dat het regressiemodel correlatiepatronen gebruikt tussen gelijktijdig gedefinieerde variabelen om voorspellingen te doen. Dat wil zeggen, om $y_{t+1}$ te voorspellen van $g$, moeten we weten op welke dag van de week $t+1$ valt, of het nu een vakantie is en de sinaasappelsapprijs op dag $t+1$. De eerste twee stukjes informatie zijn altijd gemakkelijk te vinden door een kalender te raadplegen. Een detailhandelsprijs wordt meestal vooraf ingesteld, dus de prijs van sinaasappelsap is waarschijnlijk ook een dag vooruit bekend. De prijs is echter mogelijk niet bekend 10 dagen in de toekomst! Het is belangrijk om te begrijpen dat het nut van deze regressie wordt beperkt door hoe ver in de toekomst we prognoses nodig hebben, ook wel de prognosehorizor genoemd, en in welke mate we de toekomstige waarden van de voorspellingsfactoren kennen.
Belangrijk
Bij de voorspellingsregressiemodellen van AutoML wordt ervan uitgegaan dat alle functies van de gebruiker in de toekomst bekend zijn, ten minste tot aan de prognose horizon.
Regressiemodellen van AutoML kunnen ook worden uitgebreid om historische waarden van het doel en de voorspellers te gebruiken. Het resultaat is een hybride model met kenmerken van een tijdreeksmodel en een puur regressiemodel. Historische hoeveelheden zijn extra predictorvariabelen in de regressie en we verwijzen ernaar als onregelmatige hoeveelheden. De volgorde van de vertraging verwijst naar de mate waarin de waarde bekend is. De huidige waarde van een order-twee vertraging van het doel voor ons voorbeeld van de vraag naar sinaasappelsap is bijvoorbeeld de waargenomen vraag naar sap van twee dagen geleden.
Een ander opmerkelijk verschil tussen de tijdreeksmodellen en de regressiemodellen is de manier waarop ze prognoses genereren. Tijdreeksmodellen worden over het algemeen gedefinieerd door recursierelaties en produceren prognoses een-op-een-tijd. Als u veel perioden in de toekomst wilt voorspellen, herhalen ze de horizon van de prognose, zodat eerdere prognoses weer in het model worden ingevoerd om zo nodig de volgende prognose voor één periode te genereren. De regressiemodellen zijn daarentegen zogenaamde directe voorspellingen die alle prognoses binnen één uur tot aan de horizon genereren. Directe prognosefuncties kunnen de voorkeur geven aan recursieve voorspellingen, omdat recursieve modellen samengestelde voorspellingsfout wanneer ze eerdere prognoses weer in het model invoeren. Wanneer vertragingsfuncties zijn opgenomen, brengt AutoML enkele belangrijke wijzigingen aan in de trainingsgegevens, zodat de regressiemodellen als directe prognose kunnen functioneren. Zie het artikel over vertragingsfuncties voor meer informatie.
Modellen voorspellen in AutoML
De volgende tabel bevat de prognosemodellen die zijn geïmplementeerd in AutoML en de categorie waartoe ze behoren:
| Time Series-modellen | Regressiemodellen |
|---|---|
| Naïef, Seizoensgebonden Naïef, Gemiddelde, Seizoensgemiddelde, ARIMA(X), Exponentieel gladmaken | Linear SGD, LARS LASSO, Elastic Net, Prophet, K Nearest Neighbors, Decision Tree, Random Forest, Extreem randomized Trees, Gradient Boosted Trees, LightGBM, XGBoost, TCNForecaster |
De modellen in elke categorie worden ruwweg weergegeven in volgorde van de complexiteit van patronen die ze kunnen opnemen, ook wel bekend als de modelcapaciteit. Een Naïef model, dat eenvoudigweg de laatst waargenomen waarde voorspelt, heeft een lage capaciteit terwijl het Tijdelijke Convolutional Network (TCNForecaster), een diep neuraal netwerk met mogelijk miljoenen niet-instelbare parameters, een hoge capaciteit heeft.
Belangrijk is dat AutoML ook ensemblemodellen bevat die gewogen combinaties maken van de best presterende modellen om de nauwkeurigheid verder te verbeteren. Voor prognoses gebruiken we een soft voting ensemble waar compositie en gewichten worden gevonden via het Caruana Ensemble Selection Algorithm.
Notitie
Er zijn twee belangrijke opmerkingen voor het voorspellen van model ensembles:
- De TCN kan momenteel niet worden opgenomen in ensembles.
- AutoML schakelt standaard een andere ensemblemethode uit, het stack-ensemble, dat is opgenomen in standaardregressie- en classificatietaken in AutoML. Het stack ensemble past bij een metamodel op de beste modelprognoses om ensemblegewichten te vinden. We hebben in interne benchmarking vastgesteld dat deze strategie de neiging heeft om over te gaan op fitte tijdreeksgegevens. Dit kan leiden tot slechte generalisatie, dus het stack-ensemble is standaard uitgeschakeld. Het kan echter desgewenst worden ingeschakeld in de AutoML-configuratie.
Hoe AutoML uw gegevens gebruikt
AutoML accepteert tijdreeksgegevens in tabelvorm, 'breed' formaat; Dat wil zeggen dat elke variabele een eigen corresponderende kolom moet hebben. Voor AutoML moet een van de kolommen de tijdsas zijn voor het prognoseprobleem. Deze kolom moet worden geparseerd in een datum/tijd-type. De eenvoudigste tijdreeksgegevensset bestaat uit een tijdkolom en een numerieke doelkolom. Het doel is de variabele die men in de toekomst wil voorspellen. Hier volgt een voorbeeld van de indeling in dit eenvoudige geval:
| timestamp | hoeveelheid |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-02 | 97 |
| 2012-01-03 | 106 |
| ... | ... |
| 2013-12-31 | 347 |
In complexere gevallen kunnen de gegevens andere kolommen bevatten die zijn afgestemd op de tijdindex.
| timestamp | SKU | price | Geadverteerd | hoeveelheid |
|---|---|---|---|---|
| 2012-01-01 | SAP1 | 3.5 | 0 | 100 |
| 2012-01-01 | BREAD3 | 5.76 | 0 | 47 |
| 2012-01-02 | SAP1 | 3.5 | 0 | 97 |
| 2012-01-02 | BREAD3 | 5.5 | 1 | 68 |
| ... | ... | ... | ... | ... |
| 2013-12-31 | SAP1 | 3,75 | 0 | 347 |
| 2013-12-31 | BREAD3 | 5.7 | 0 | 94 |
In dit voorbeeld is er een SKU, een detailhandelsprijs en een vlag die aangeeft of een item naast de tijdstempel en de doelhoeveelheid is geadverteerd. Er zijn blijkbaar twee reeksen in deze gegevensset: één voor de JUICE1-SKU en één voor de BREAD3-SKU; de SKU kolom is een kolom met tijdreeks-id's, omdat deze groepeert door twee groepen die elk één reeks bevatten. Voordat u modellen overspoelt, voert AutoML basisvalidatie uit van de invoerconfiguratie en -gegevens en voegt ontworpen functies toe.
Vereisten voor gegevenslengte
Als u een prognosemodel wilt trainen, moet u voldoende historische gegevens hebben. Deze drempelwaarde is afhankelijk van de trainingsconfiguratie. Als u validatiegegevens hebt opgegeven, wordt het minimum aantal trainingsobservaties dat per tijdreeks is vereist, gegeven door:
$T_{\text{user validation}} = H + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
waarbij $H$ de prognose horizon is, is $l_{\text{max}}$ de maximale vertragingsvolgorde en is $s_{\text{window}}$ de venstergrootte voor rolling aggregatiefuncties. Als u kruisvalidatie gebruikt, is het minimumaantal waarnemingen:
$T_{\text{CV}} = 2H + (n_{\text{CV}} - 1) n_{\text{step}} + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
waarbij $n_{\text{CV}}$ het aantal kruisvalidatievouwen is en $n_{\text{step}}$ de grootte van de CV-stap of verschuiving tussen CV-vouwen is. De basislogica achter deze formules is dat u altijd ten minste een horizon van trainingsobservaties moet hebben voor elke tijdreeks, inclusief een opvulling voor vertragingen en kruisvalidatiesplitsingen. Zie de selectie van het prognosemodel voor meer informatie over kruisvalidatie voor prognose.
Ontbrekende gegevensverwerking
Voor de tijdreeksmodellen van AutoML zijn regelmatig ruimteobservaties in tijd vereist. Regelmatig gespoerd, hier, omvat gevallen zoals maandelijkse of jaarlijkse waarnemingen waarbij het aantal dagen tussen waarnemingen kan variëren. Voorafgaand aan het modelleren moet AutoML ervoor zorgen dat er geen reekswaarden ontbreken en dat de waarnemingen regelmatig zijn. Daarom ontbreken er twee ontbrekende gegevenscases:
- Er ontbreekt een waarde voor een bepaalde cel in de tabelgegevens
- Er ontbreekt een rij die overeenkomt met een verwachte observatie op basis van de tijdreeksfrequentie
In het eerste geval brengt AutoML ontbrekende waarden in gebruik met behulp van algemene, configureerbare technieken.
Een voorbeeld van een ontbrekende, verwachte rij wordt weergegeven in de volgende tabel:
| timestamp | hoeveelheid |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-03 | 106 |
| 2012-01-04 | 103 |
| ... | ... |
| 2013-12-31 | 347 |
Deze serie heeft een dagelijkse frequentie, maar er is geen observatie voor 2 januari 2012. In dit geval probeert AutoML de gegevens in te vullen door een nieuwe rij toe te voegen voor 2 januari 2012. De nieuwe waarde voor de quantity kolom en eventuele andere kolommen in de gegevens worden vervolgens als andere ontbrekende waarden ingerekend. AutoML moet de frequentie van de reeks duidelijk kennen om zo gaten in te vullen. Deze frequentie wordt automatisch gedetecteerd door AutoML, of optioneel kan de gebruiker deze in de configuratie opgeven.
De imputatiemethode voor het invullen van ontbrekende waarden kan worden geconfigureerd in de invoer. De standaardmethoden worden weergegeven in de volgende tabel:
| Kolomsoort | Standaardmethode voor imputatie |
|---|---|
| Doel | Opvulling vooruit (laatste waarneming) |
| Numerieke functie | Mediaanwaarde |
Ontbrekende waarden voor categorische functies worden verwerkt tijdens numerieke codering door een extra categorie op te geven die overeenkomt met een ontbrekende waarde. In dit geval is de imputatie impliciet.
Geautomatiseerde functie-engineering
AutoML voegt doorgaans nieuwe kolommen toe aan gebruikersgegevens om de nauwkeurigheid van modellen te verhogen. De functie ontworpen kan het volgende bevatten:
| Functiegroep | Standaard/optioneel |
|---|---|
| Kalenderfuncties die zijn afgeleid van de tijdindex (bijvoorbeeld dag van de week) | Standaardinstelling |
| Categorische functies die zijn afgeleid van tijdreeks-id's | Standaardinstelling |
| Categorische typen coderen naar numeriek type | Standaardinstelling |
| Indicatorfuncties voor feestdagen die zijn gekoppeld aan een bepaald land of bepaalde regio | Optioneel |
| Vertraging van doelhoeveelheid | Optioneel |
| Vertragingen in functiekolommen | Optioneel |
| Aggregaties van rolling window (bijvoorbeeld rolling average) van doelhoeveelheid | Optioneel |
| Seizoensgebonden ontleding (STL) | Optioneel |
U kunt featurization configureren vanuit de AutoML SDK via de klasse ForecastingJob of vanuit de Azure Machine Learning-studio-webinterface.
Detectie en verwerking van niet-stationaire tijdreeksen
Een tijdreeks waarbij gemiddelde en variantie in de loop van de tijd veranderen, wordt een niet-stationair genoemd. Tijdreeksen die stochastische trends vertonen, zijn bijvoorbeeld niet-stationair van aard. Om dit te visualiseren, plot de volgende afbeelding een reeks die over het algemeen naar boven gaat. Bereken en vergelijk nu de gemiddelde (gemiddelde) waarden voor de eerste en de tweede helft van de reeks. Zijn ze hetzelfde? Hier is het gemiddelde van de reeks in de eerste helft van de plot aanzienlijk kleiner dan in de tweede helft. Het feit dat het gemiddelde van de reeks afhankelijk is van het tijdsinterval dat men bekijkt, is een voorbeeld van de tijdsafhankelijke momenten. Hier is het gemiddelde van een reeks het eerste moment.
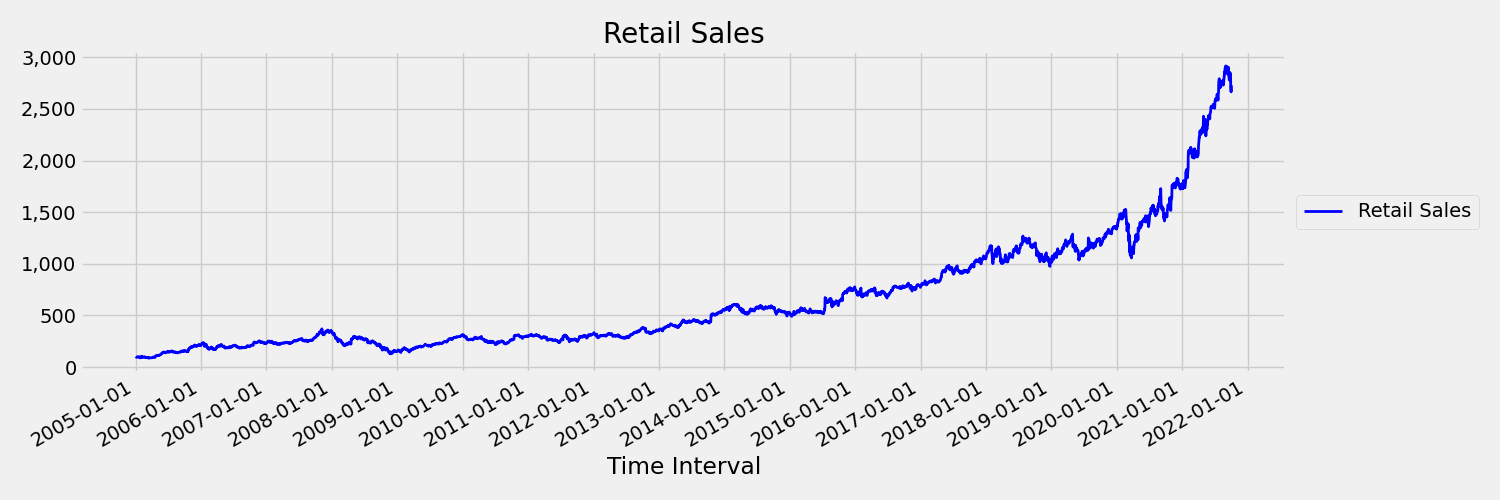
Laten we vervolgens de volgende afbeelding bekijken, waarmee de oorspronkelijke reeks in eerste verschillen wordt uitgelezen: $\Delta y_{t} = y_t - y_{t-1}$. Het gemiddelde van de reeks is ongeveer constant gedurende het tijdsbereik, terwijl de variantie lijkt te variëren. Dit is dus een voorbeeld van een eerste order stationaire tijdreeks.
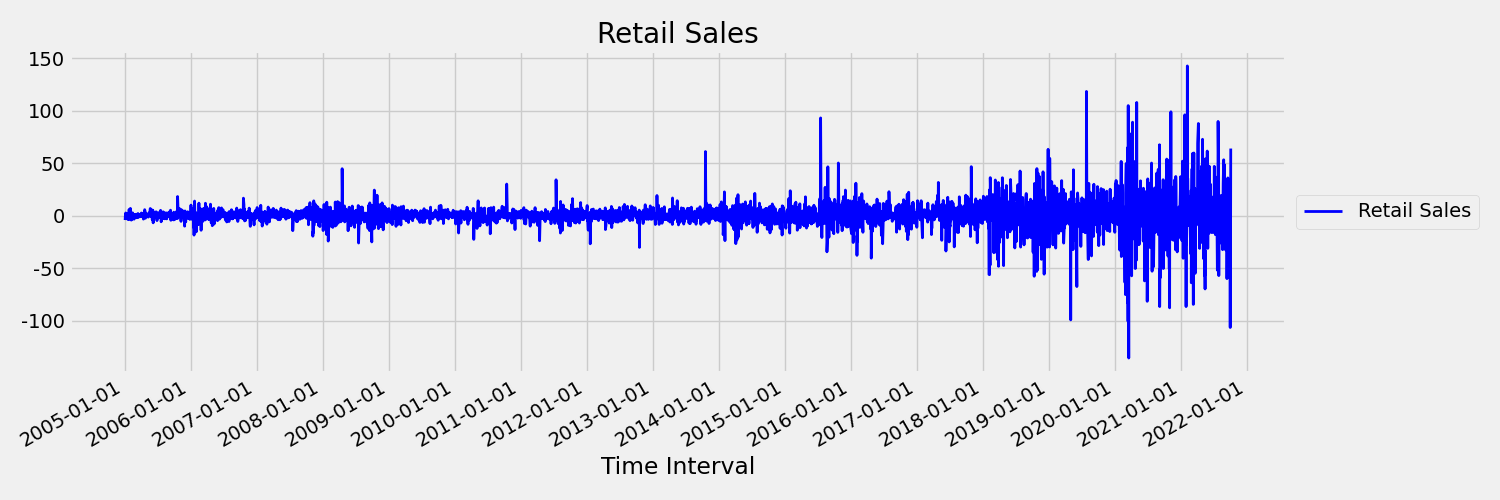
AutoML-regressiemodellen kunnen niet inherent omgaan met stochastische trends of andere bekende problemen die verband houden met niet-stationaire tijdreeksen. Als gevolg hiervan kan de nauwkeurigheid van out-of-sampleprognoses slecht zijn als dergelijke trends aanwezig zijn.
AutoML analyseert automatisch de tijdreeksgegevensset om de stationariteit te bepalen. Wanneer niet-stationaire tijdreeksen worden gedetecteerd, past AutoML automatisch een differentiërende transformatie toe om de impact van niet-stationair gedrag te beperken.
Model opruimen
Nadat gegevens zijn voorbereid met ontbrekende gegevensverwerking en functie-engineering, veegt AutoML over een set modellen en hyperparameters met behulp van een modelaanbevelingsservice. De modellen worden gerangschikt op basis van validatie- of kruisvalidatiegegevens en vervolgens kunnen de topmodellen eventueel worden gebruikt in een ensemblemodel. Het beste model, of een van de getrainde modellen, kan indien nodig worden geïnspecteerd, gedownload of geïmplementeerd om prognoses te produceren. Zie het artikel over het opruimen en selecteren van modellen voor meer informatie.
Modelgroepering
Wanneer een gegevensset meer dan één tijdreeks bevat, zoals in het opgegeven gegevensvoorbeeld, zijn er meerdere manieren om die gegevens te modelleren. We kunnen bijvoorbeeld eenvoudig groeperen op de kolom(s) van de tijdreeks-id's en onafhankelijke modellen trainen voor elke reeks. Een meer algemene benadering is het partitioneren van de gegevens in groepen die elk meerdere, waarschijnlijk gerelateerde reeksen bevatten en een model per groep trainen. AutoML-prognose maakt standaard gebruik van een gemengde benadering voor het groeperen van modellen. Tijdreeksmodellen, plus ARIMAX en Prophet, wijzen één reeks toe aan één groep en andere regressiemodellen wijzen alle reeksen toe aan één groep. De volgende tabel bevat een overzicht van de modelgroepen in twee categorieën: een-op-een en veel-op-een:
| Elke reeks in eigen groep (1:1) | Alle reeksen in één groep (N:1) |
|---|---|
| Naïef, Seizoensgebonden Naïef, Gemiddelde, Seizoensgemiddelde, Exponentiële smoothing, ARIMA, ARIMAX, Prophet | Linear SGD, LARS LASSO, Elastic Net, K Nearest Neighbors, Decision Tree, Random Forest, Extremely Randomized Trees, Gradient Boosted Trees, LightGBM, XGBoost, TCNForecaster |
Meer algemene modelgroepen zijn mogelijk via de oplossing Veel-modellen van AutoML; zie onze veel modellen- geautomatiseerde ML-notebook.
Volgende stappen
- Meer informatie over deep learning-modellen voor prognoses in AutoML
- Meer informatie over het opruimen en selecteren van modellen voor prognoses in AutoML.
- Meer informatie over hoe AutoML functies maakt op basis van de agenda.
- Meer informatie over hoe AutoML vertragingsfuncties maakt.
- Lees antwoorden op veelgestelde vragen over prognoses in AutoML.