Batch-eindpunten
Met Azure Machine Learning kunt u batch-eindpunten en -implementaties implementeren om langdurige, asynchrone deductie uit te voeren met machine learning-modellen en -pijplijnen. Wanneer u een machine learning-model of pijplijn traint, moet u het implementeren zodat anderen het kunnen gebruiken met nieuwe invoergegevens om voorspellingen te genereren. Dit proces voor het genereren van voorspellingen met het model of de pijplijn wordt deductie genoemd.
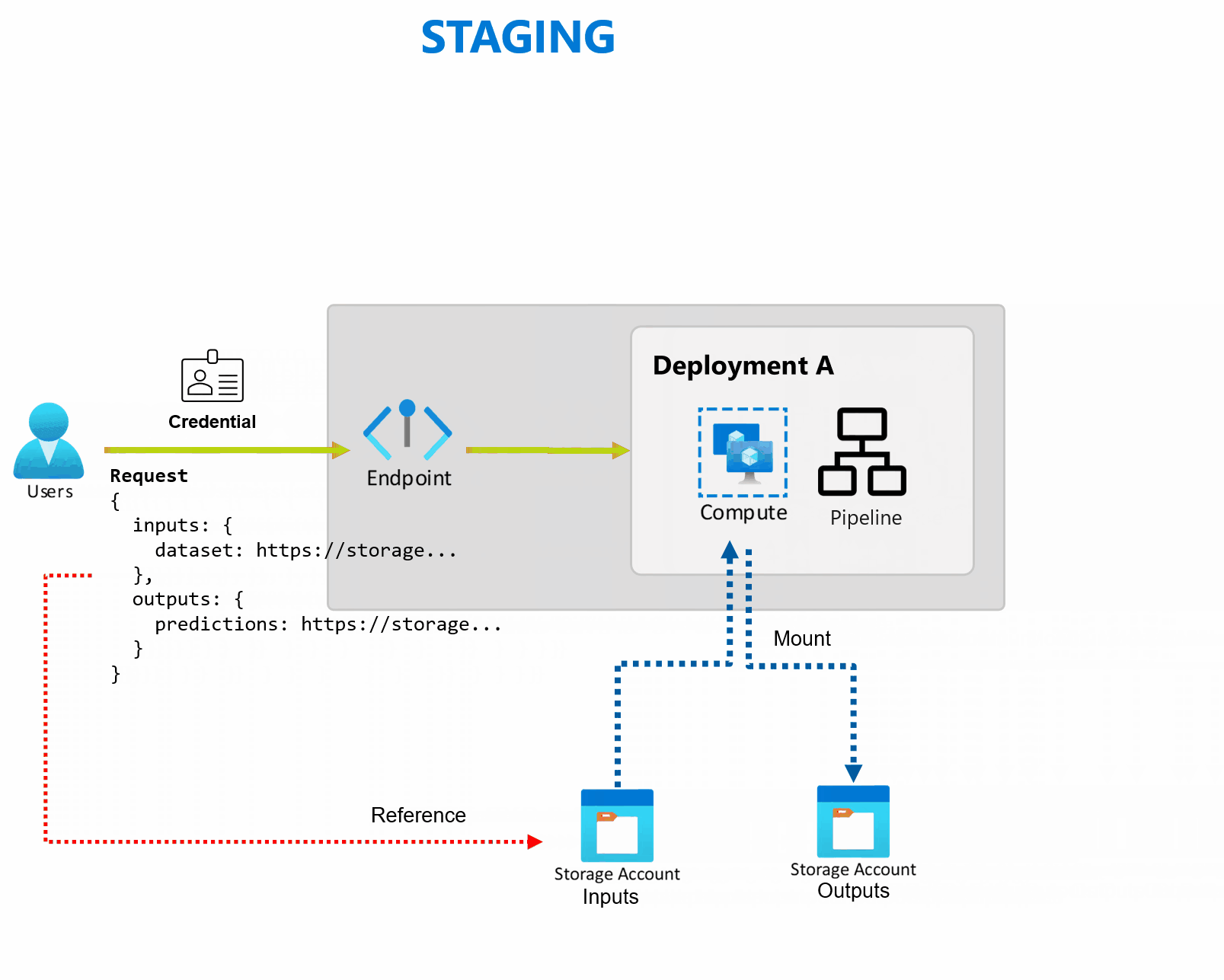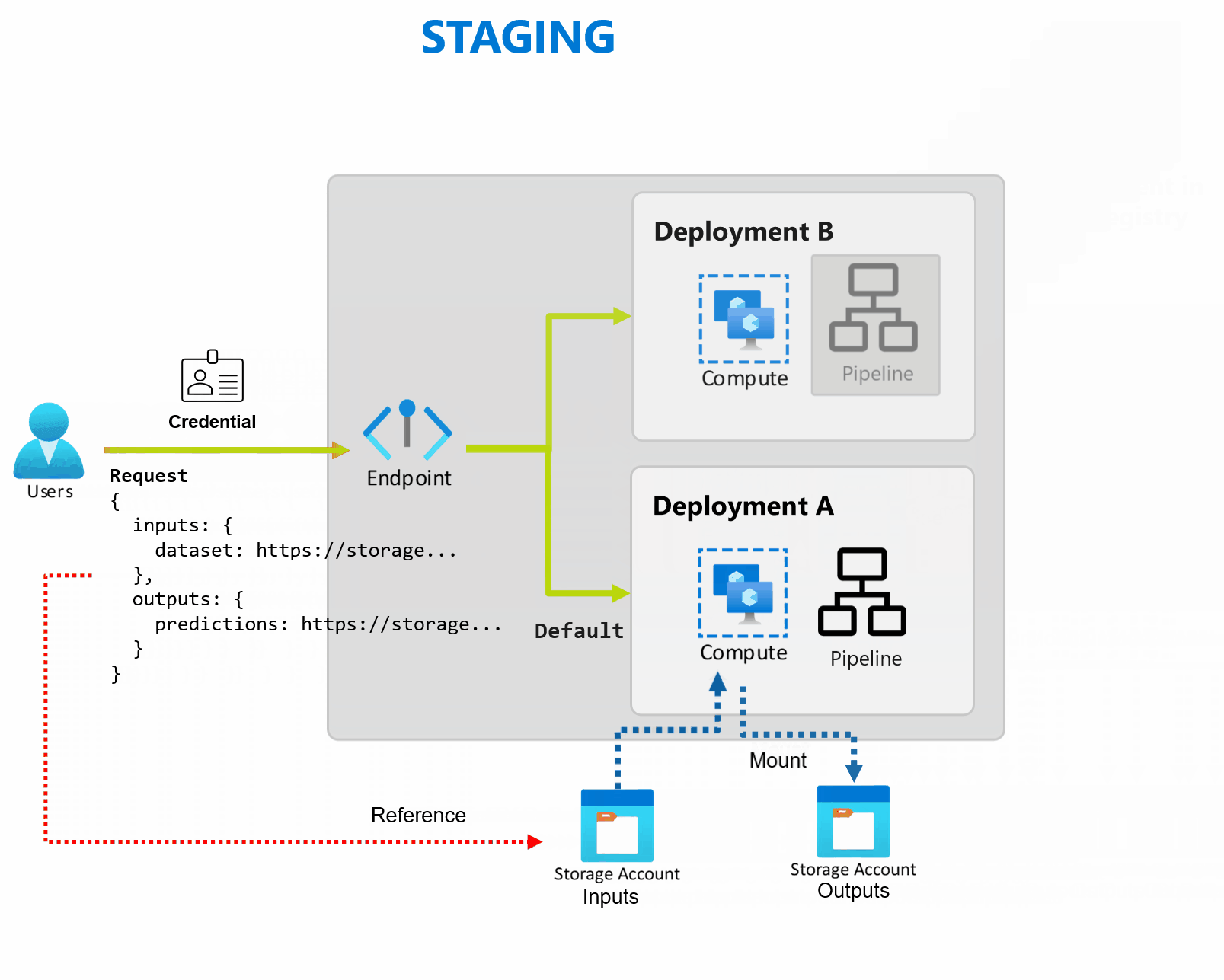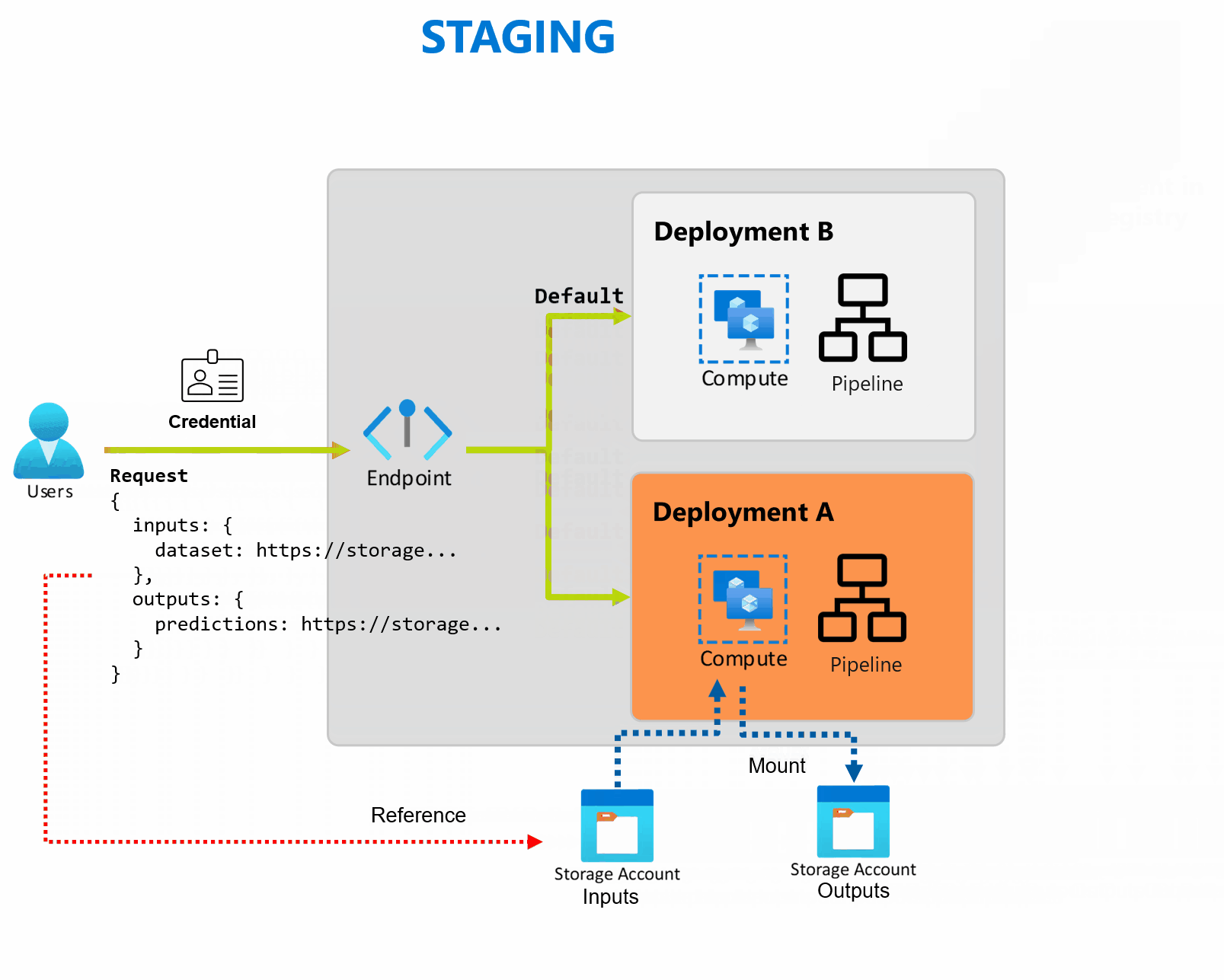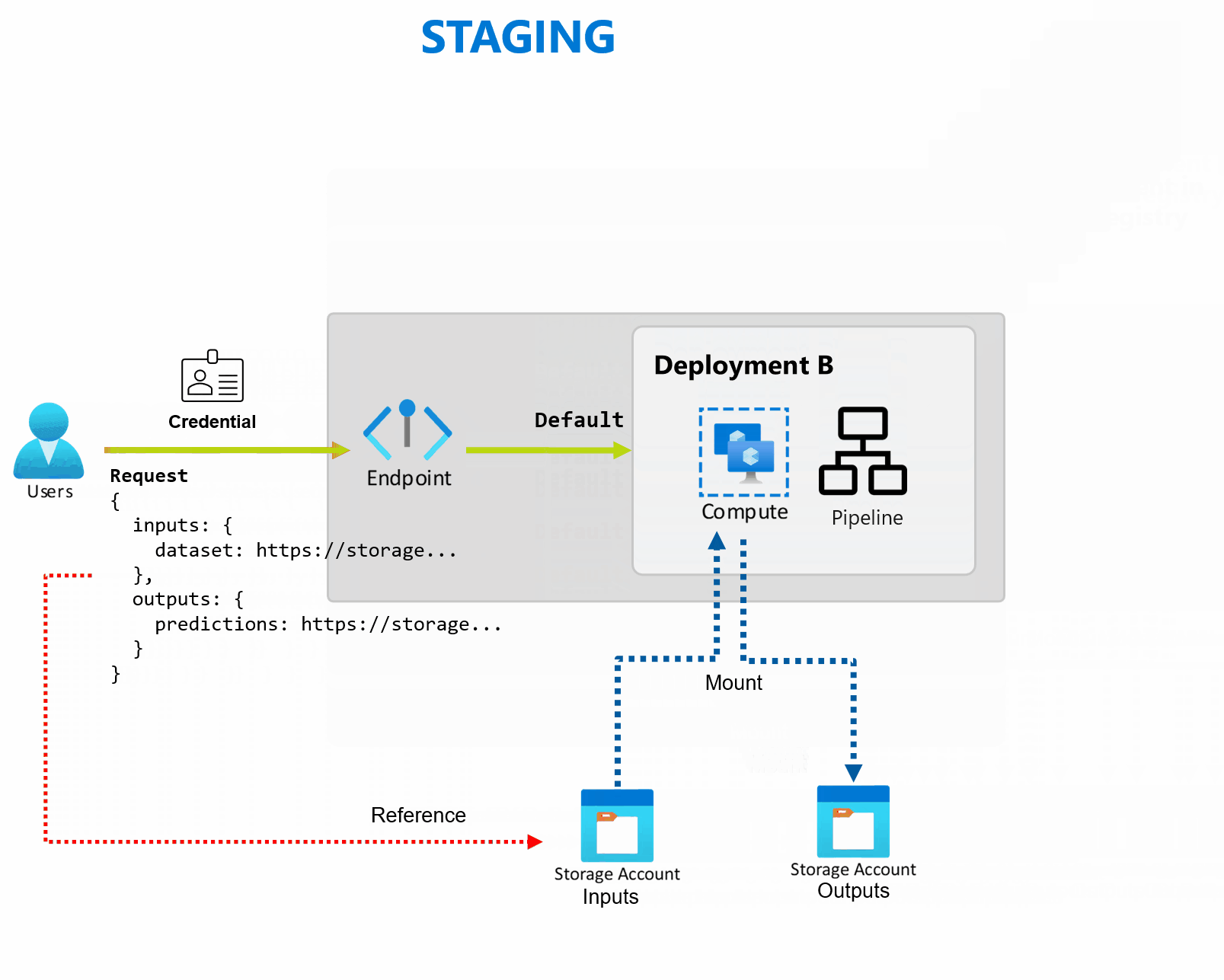
Batch-eindpunten ontvangen pointers naar gegevens en voeren taken asynchroon uit om de gegevens parallel op rekenclusters te verwerken. Batch-eindpunten slaan uitvoer op in een gegevensarchief voor verdere analyse. Batch-eindpunten gebruiken wanneer:
- U hebt dure modellen of pijplijnen waarvoor langere tijd nodig is om uit te voeren.
- U wilt machine learning-pijplijnen operationeel maken en onderdelen opnieuw gebruiken.
- U moet deductie uitvoeren over grote hoeveelheden gegevens, gedistribueerd in meerdere bestanden.
- U hebt geen vereisten voor lage latentie.
- De invoer van uw model wordt opgeslagen in een opslagaccount of in een Azure Machine Learning-gegevensasset.
- U kunt profiteren van parallelle uitvoering.
Batch-implementaties
Een implementatie is een set resources en berekeningen die nodig zijn om de functionaliteit te implementeren die het eindpunt biedt. Elk eindpunt kan verschillende implementaties met verschillende configuraties hosten en deze functionaliteit helpt de interface van het eindpunt los te koppelen van de implementatiedetails die zijn gedefinieerd door de implementatie. Wanneer een batch-eindpunt wordt aangeroepen, wordt de client automatisch doorgestuurd naar de standaardimplementatie. Deze standaardimplementatie kan op elk gewenst moment worden geconfigureerd en gewijzigd.

Er zijn twee typen implementaties mogelijk in Azure Machine Learning-batcheindpunten:
Modelimplementatie
Met modelimplementatie kunt u modeldeductie op schaal operationeel maken, zodat u grote hoeveelheden gegevens op een lage latentie en asynchrone manier kunt verwerken. Azure Machine Learning instrumenteert automatisch schaalbaarheid door parallelle uitvoering van de deductieprocessen over meerdere knooppunten in een rekencluster te bieden.
Modelimplementatie gebruiken wanneer:
- U hebt dure modellen waarvoor langere tijd nodig is om deductie uit te voeren.
- U moet deductie uitvoeren over grote hoeveelheden gegevens, gedistribueerd in meerdere bestanden.
- U hebt geen vereisten voor lage latentie.
- U kunt profiteren van parallelle uitvoering.
Het belangrijkste voordeel van modelimplementaties is dat u dezelfde assets kunt gebruiken die zijn geïmplementeerd voor realtime deductie naar online-eindpunten, maar nu kunt u ze op schaal uitvoeren in batch. Als uw model eenvoudige voorverwerking of naverwerking vereist, kunt u een scorescript maken waarmee de vereiste gegevenstransformaties worden uitgevoerd.
Als u een modelimplementatie in een batch-eindpunt wilt maken, moet u de volgende elementen opgeven:
- Modelleren
- Rekencluster
- Scorescript (optioneel voor MLflow-modellen)
- Omgeving (optioneel voor MLflow-modellen)
Implementatie van pijplijnonderdelen
Implementatie van pijplijnonderdelen maakt het mogelijk om volledige verwerkingsgrafieken (of pijplijnen) op een lage latentie en asynchrone manier batchdeductie uit te voeren.
Implementatie van pijplijnonderdelen gebruiken wanneer:
- U moet volledige rekengrafieken operationeel maken die in meerdere stappen kunnen worden uitgevouwen.
- U moet onderdelen uit trainingspijplijnen in uw deductiepijplijn opnieuw gebruiken.
- U hebt geen vereisten voor lage latentie.
Het belangrijkste voordeel van implementaties van pijplijnonderdelen is de herbruikbaarheid van onderdelen die al bestaan in uw platform en de mogelijkheid om complexe deductieroutines te operationeel te maken.
Als u een implementatie van een pijplijnonderdeel in een batch-eindpunt wilt maken, moet u de volgende elementen opgeven:
- Pijplijnonderdeel
- Configuratie van rekencluster
Met Batch-eindpunten kunt u ook pijplijnonderdeelimplementaties maken vanuit een bestaande pijplijntaak. Wanneer u dit doet, maakt Azure Machine Learning automatisch een pijplijnonderdeel buiten de taak. Dit vereenvoudigt het gebruik van dit soort implementaties. Het is echter een best practice om altijd pijplijnonderdelen expliciet te maken om uw MLOps-praktijk te stroomlijnen.
Kostenbeheer
Als u een batch-eindpunt aanroept, wordt een asynchrone batchdeductietaak geactiveerd. Azure Machine Learning richt automatisch rekenresources in wanneer de taak wordt gestart en de toewijzing wordt automatisch ongedaan gemaakt wanneer de taak is voltooid. Op deze manier betaalt u alleen voor rekenkracht wanneer u deze gebruikt.
Tip
Bij het implementeren van modellen kunt u de instellingen voor rekenresources (zoals aantal exemplaren) en geavanceerde instellingen (zoals minibatchgrootte, foutdrempel, enzovoort) overschrijven voor elke afzonderlijke batchdeductietaak. Door gebruik te maken van deze specifieke configuraties, kunt u mogelijk de uitvoering versnellen en de kosten verlagen.
Batch-eindpunten kunnen ook worden uitgevoerd op VM's met lage prioriteit. Batch-eindpunten kunnen automatisch herstellen van niet-toegewezen VM's en het werk hervatten van waar het was gebleven bij het implementeren van modellen voor deductie. Zie Vm's met lage prioriteit gebruiken in batcheindpunten voor meer informatie over het gebruik van VM's met lage prioriteit om de kosten van batchdeductieworkloads te verlagen.
Ten slotte worden in Azure Machine Learning geen kosten in rekening gebracht voor batch-eindpunten of batchimplementaties zelf, zodat u uw eindpunten en implementaties kunt organiseren als het beste bij uw scenario past. Eindpunten en implementaties kunnen gebruikmaken van onafhankelijke of gedeelde clusters, zodat u nauwkeurige controle kunt bereiken over welke rekentaken de taken verbruiken. Gebruik scale-to-zero in clusters om ervoor te zorgen dat er geen resources worden verbruikt wanneer ze niet actief zijn.
De MLOps-praktijk stroomlijnen
Batch-eindpunten kunnen meerdere implementaties onder hetzelfde eindpunt verwerken, zodat u de implementatie van het eindpunt kunt wijzigen zonder de URL te wijzigen die uw consumenten gebruiken om het aan te roepen.
U kunt implementaties toevoegen, verwijderen en bijwerken zonder dat dit van invloed is op het eindpunt zelf.
Flexibele gegevensbronnen en opslag
Batch-eindpunten lezen en schrijven gegevens rechtstreeks vanuit de opslag. U kunt Azure Machine Learning-gegevensarchieven, Azure Machine Learning-gegevensassets of opslagaccounts opgeven als invoer. Zie Taken en invoergegevens maken voor batcheindpunten voor meer informatie over de ondersteunde invoeropties en hoe u deze opgeeft.
Beveiliging
Batch-eindpunten bieden alle mogelijkheden die nodig zijn voor het uitvoeren van workloads op productieniveau in een bedrijfsinstelling. Ze ondersteunen privénetwerken voor beveiligde werkruimten en Microsoft Entra-verificatie, hetzij met behulp van een gebruikersprincipaal (zoals een gebruikersaccount) of een service-principal (zoals een beheerde of onbeheerde identiteit). Taken die door een batch-eindpunt worden gegenereerd, worden uitgevoerd onder de identiteit van de aanroeper, wat u de flexibiliteit biedt om elk scenario te implementeren. Zie Verificatie op batch-eindpunten voor meer informatie over autorisatie tijdens het gebruik van batcheindpunten.