Modellen implementeren voor scoren in batch-eindpunten
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Batch-eindpunten bieden een handige manier om modellen te implementeren die deductie uitvoeren over grote hoeveelheden gegevens. Deze eindpunten vereenvoudigen het proces van het hosten van uw modellen voor batchgewijs scoren, zodat uw focus op machine learning ligt in plaats van op de infrastructuur.
Batch-eindpunten gebruiken voor modelimplementatie wanneer:
- U hebt dure modellen waarvoor langere tijd nodig is om deductie uit te voeren.
- U moet deductie uitvoeren op grote hoeveelheden gegevens die in meerdere bestanden worden gedistribueerd.
- U hebt geen vereisten voor lage latentie.
- U kunt profiteren van parallelle uitvoering.
In dit artikel gebruikt u een batch-eindpunt om een machine learning-model te implementeren waarmee het klassieke MNIST-cijferherkenningsprobleem (Modified National Institute of Standards and Technology) wordt opgelost. Uw geïmplementeerde model voert vervolgens batchdeductie uit over grote hoeveelheden gegevens, in dit geval afbeeldingsbestanden. U begint met het maken van een batchimplementatie van een model dat is gemaakt met behulp van Torch. Deze implementatie wordt de standaardimplementatie in het eindpunt. Later maakt u een tweede implementatie van een modus die is gemaakt met TensorFlow (Keras), test u de tweede implementatie en stelt u deze vervolgens in als de standaardimplementatie van het eindpunt.
Als u de codevoorbeelden en bestanden wilt volgen die nodig zijn om de opdrachten in dit artikel lokaal uit te voeren, raadpleegt u de sectie De voorbeeldenopslagplaats klonen. De codevoorbeelden en -bestanden bevinden zich in de opslagplaats azureml-examples .
Vereisten
Voordat u de stappen in dit artikel uitvoert, moet u ervoor zorgen dat u aan de volgende vereisten voldoet:
Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint. Probeer de gratis of betaalde versie van Azure Machine Learning.
Een Azure Machine Learning-werkruimte. Als u nog geen werkruimte hebt, gebruikt u de stappen in het artikel Werkruimten beheren om er een te maken.
Als u de volgende taken wilt uitvoeren, moet u ervoor zorgen dat u over deze machtigingen beschikt in de werkruimte:
Batch-eindpunten en -implementaties maken/beheren: gebruik de rol eigenaar, inzenderrol of een aangepaste rol die toestaat
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.ARM-implementaties maken in de werkruimteresourcegroep: gebruik de rol eigenaar, inzender of een aangepaste rol die is toegestaan
Microsoft.Resources/deployments/writein de resourcegroep waarin de werkruimte wordt geïmplementeerd.
U moet de volgende software installeren om te kunnen werken met Azure Machine Learning:
VAN TOEPASSING OP:
Azure CLI ml-extensie v2 (huidige)De Azure CLI en de
mlextensie voor Azure Machine Learning.az extension add -n ml
De opslagplaats met voorbeelden klonen
Het voorbeeld in dit artikel is gebaseerd op codevoorbeelden in de opslagplaats azureml-examples . Als u de opdrachten lokaal wilt uitvoeren zonder YAML en andere bestanden te hoeven kopiëren/plakken, kloont u eerst de opslagplaats en wijzigt u vervolgens mappen in de map:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Uw systeem voorbereiden
Verbinding maken met uw werkruimte
Maak eerst verbinding met de Azure Machine Learning-werkruimte waar u werkt.
Als u de standaardinstellingen voor de Azure CLI nog niet hebt ingesteld, slaat u de standaardinstellingen op. Voer deze code uit om te voorkomen dat de waarden voor uw abonnement, werkruimte, resourcegroep en locatie meerdere keren worden doorgegeven:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Rekenproces maken
Batch-eindpunten worden uitgevoerd op rekenclusters en ondersteunen zowel Azure Machine Learning-rekenclusters (AmlCompute) als Kubernetes-clusters. Clusters zijn een gedeelde resource, dus één cluster kan een of meer batchimplementaties hosten (samen met andere workloads, indien gewenst).
Maak een rekenproces met de naam batch-cluster, zoals wordt weergegeven in de volgende code. U kunt naar behoefte aanpassen en naar uw rekenproces verwijzen met behulp van azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Notitie
Er worden op dit moment geen kosten in rekening gebracht voor de berekening, omdat het cluster op 0 knooppunten blijft totdat een batch-eindpunt wordt aangeroepen en er een batchscoretaak wordt verzonden. Zie Kosten voor AmlCompute beheren en optimaliseren voor meer informatie over rekenkosten.
Een batch-eindpunt maken
Een batch-eindpunt is een HTTPS-eindpunt dat clients kunnen aanroepen om een batchscoretaak te activeren. Een batchscoretaak is een taak waarmee meerdere invoer wordt gescoord. Een batchimplementatie is een set rekenresources die als host fungeren voor het model dat de werkelijke batchscore (of batchdeductie) uitvoert. Eén batch-eindpunt kan meerdere batchimplementaties hebben. Zie Wat zijn batch-eindpunten ? voor meer informatie over batcheindpunten.
Tip
Een van de batchimplementaties fungeert als de standaardimplementatie voor het eindpunt. Wanneer het eindpunt wordt aangeroepen, voert de standaardimplementatie de werkelijke batchscore uit. Zie batcheindpunten en batchimplementaties voor meer informatie over batcheindpunten en implementaties.
Geef het eindpunt een naam. De naam van het eindpunt moet uniek zijn binnen een Azure-regio, omdat de naam is opgenomen in de URI van het eindpunt. Er kan bijvoorbeeld slechts één batcheindpunt zijn met de naam
mybatchendpointinwestus2.Het batch-eindpunt configureren
Het volgende YAML-bestand definieert een batch-eindpunt. U kunt dit bestand gebruiken met de CLI-opdracht voor het maken van batcheindpunten.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningIn de volgende tabel worden de belangrijkste eigenschappen van het eindpunt beschreven. Zie HET YAML-schema van het CLI-batcheindpunt (v2) voor het volledige YAML-schema voor batcheindpunten.
Toets Beschrijving nameDe naam van het batch-eindpunt. Moet uniek zijn op het niveau van de Azure-regio. descriptionDe beschrijving van het batch-eindpunt. Deze eigenschap is optioneel. tagsDe tags die moeten worden opgenomen in het eindpunt. Deze eigenschap is optioneel. Maak het eindpunt:
Een batchimplementatie maken
Een modelimplementatie is een set resources die vereist is voor het hosten van het model dat de werkelijke deductie uitvoert. Als u een batchmodelimplementatie wilt maken, hebt u het volgende nodig:
- Een geregistreerd model in de werkruimte
- De code voor het scoren van het model
- Een omgeving waarop de afhankelijkheden van het model zijn geïnstalleerd
- De vooraf gemaakte reken- en resource-instellingen
Begin met het registreren van het model dat moet worden geïmplementeerd: een Torch-model voor het populaire probleem met cijferherkenning (MNIST). Batch-implementaties kunnen alleen modellen implementeren die zijn geregistreerd in de werkruimte. U kunt deze stap overslaan als het model dat u wilt implementeren al is geregistreerd.
Tip
Modellen zijn gekoppeld aan de implementatie in plaats van aan het eindpunt. Dit betekent dat één eindpunt verschillende modellen (of modelversies) onder hetzelfde eindpunt kan leveren, mits de verschillende modellen (of modelversies) in verschillende implementaties worden geïmplementeerd.
Nu is het tijd om een scorescript te maken. Batch-implementaties vereisen een scorescript dat aangeeft hoe een bepaald model moet worden uitgevoerd en hoe invoergegevens moeten worden verwerkt. Batch-eindpunten ondersteunen scripts die zijn gemaakt in Python. In dit geval implementeert u een model dat afbeeldingsbestanden leest die cijfers vertegenwoordigen en het bijbehorende cijfer uitvoert. Het scorescript is als volgt:
Notitie
Voor MLflow-modellen genereert Azure Machine Learning automatisch het scorescript, zodat u er geen hoeft op te geven. Als uw model een MLflow-model is, kunt u deze stap overslaan. Zie het artikel MLflow-modellen gebruiken in batchimplementaties voor meer informatie over hoe batch-eindpunten met MLflow-modellen werken.
Waarschuwing
Als u een AutoML-model (Automated Machine Learning) implementeert onder een batcheindpunt, moet u er rekening mee houden dat het scorescript dat AutoML alleen biedt voor online-eindpunten en niet is ontworpen voor batchuitvoering. Zie Scorescripts maken voor batchimplementaties voor informatie over het maken van een scorescript voor uw batchimplementatie.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Maak een omgeving waarin uw batchimplementatie wordt uitgevoerd. De omgeving moet de pakketten
azureml-corebevatten enazureml-dataset-runtime[fuse], die vereist zijn voor batch-eindpunten, plus eventuele afhankelijkheid die uw code nodig heeft om uit te voeren. In dit geval zijn de afhankelijkheden vastgelegd in eenconda.yamlbestand:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Belangrijk
De pakketten
azureml-coreenazureml-dataset-runtime[fuse]zijn vereist voor batchimplementaties en moeten worden opgenomen in de omgevingsafhankelijkheden.Geef de omgeving als volgt op:
De omgevingsdefinitie wordt opgenomen in de implementatiedefinitie zelf als een anonieme omgeving. U ziet de volgende regels in de implementatie:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlWaarschuwing
Gecureerde omgevingen worden niet ondersteund in batchimplementaties. U moet uw eigen omgeving opgeven. U kunt altijd de basisafbeelding van een gecureerde omgeving gebruiken als uw omgeving om het proces te vereenvoudigen.
Een implementatiedefinitie maken
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoIn de volgende tabel worden de belangrijkste eigenschappen van de batchimplementatie beschreven. Zie HET YAML-schema voor de volledige batchimplementatie van de BATCH-implementatie (v2) voor het YAML-schema voor de volledige batchimplementatie.
Toets Beschrijving nameDe naam van de implementatie. endpoint_nameDe naam van het eindpunt voor het maken van de implementatie onder. modelHet model dat moet worden gebruikt voor batchgewijs scoren. In het voorbeeld wordt een model inline gedefinieerd met behulp van path. Met deze definitie kunnen modelbestanden automatisch worden geüpload en geregistreerd met een automatisch gegenereerde naam en versie. Zie het modelschema voor meer opties. Als best practice voor productiescenario's moet u het model afzonderlijk maken en hiernaar verwijzen. Als u naar een bestaand model wilt verwijzen, gebruikt u deazureml:<model-name>:<model-version>syntaxis.code_configuration.codeDe lokale map die alle Python-broncode bevat om het model te scoren. code_configuration.scoring_scriptHet Python-bestand in de code_configuration.codemap. Dit bestand moet eeninit()functie en eenrun()functie hebben. Gebruik deinit()functie voor kostbare of algemene voorbereiding (bijvoorbeeld om het model in het geheugen te laden).init()wordt slechts één keer aan het begin van het proces aangeroepen. Gebruikrun(mini_batch)dit om elke vermelding te scoren. De waardemini_batchis een lijst met bestandspaden. Derun()functie moet een Pandas DataFrame of een matrix retourneren. Elk geretourneerd element geeft een geslaagde uitvoering van het invoerelement in demini_batch. Zie Inzicht in het scorescript voor meer informatie over het maken van een scorescript.environmentDe omgeving om het model te scoren. In het voorbeeld wordt een inline omgeving gedefinieerd met behulp van conda_fileenimage. Deconda_fileafhankelijkheden worden bovenop deimage. De omgeving wordt automatisch geregistreerd met een automatisch gegenereerde naam en versie. Zie het omgevingsschema voor meer opties. Als best practice voor productiescenario's moet u de omgeving afzonderlijk maken en hiernaar verwijzen. Als u naar een bestaande omgeving wilt verwijzen, gebruikt u deazureml:<environment-name>:<environment-version>syntaxis.computeDe berekening voor het uitvoeren van batchgewijs scoren. In het voorbeeld wordt de batch-clustergemaakte aan het begin gebruikt en wordt ernaar verwezen met behulp van deazureml:<compute-name>syntaxis.resources.instance_countHet aantal exemplaren dat moet worden gebruikt voor elke batchscoretaak. settings.max_concurrency_per_instanceHet maximum aantal parallelle scoring_scriptuitvoeringen per exemplaar.settings.mini_batch_sizeHet aantal bestanden dat in scoring_scriptéénrun()gesprek kan worden verwerkt.settings.output_actionHoe de uitvoer moet worden geordend in het uitvoerbestand. append_rowalle geretourneerde uitvoerresultaten worden samengevoegdrun()tot één bestand met de naamoutput_file_name.summary_onlyde uitvoerresultaten worden niet samengevoegd en worden alleen berekenderror_threshold.settings.output_file_nameDe naam van het uitvoerbestand voor batchgewijs scoren voor append_rowoutput_action.settings.retry_settings.max_retriesHet aantal mislukte pogingen voor een mislukte scoring_scriptrun()poging.settings.retry_settings.timeoutDe time-out in seconden voor een scoring_scriptrun()voor het scoren van een minibatch.settings.error_thresholdHet aantal fouten bij het scoren van invoerbestanden die moeten worden genegeerd. Als het aantal fouten voor de volledige invoer boven deze waarde gaat, wordt de batchscoretaak beëindigd. In het voorbeeld wordt -1gebruikgemaakt van , wat aangeeft dat een willekeurig aantal fouten is toegestaan zonder de batchscoretaak te beëindigen.settings.logging_levelUitgebreidheid van het logboek. Waarden in toenemende uitgebreidheid zijn: WAARSCHUWING, INFO en FOUTOPSPORING. settings.environment_variablesWoordenlijst van naam-waardeparen van omgevingsvariabelen die moeten worden ingesteld voor elke batchscoretaak. De implementatie maken:
Voer de volgende code uit om een batch-implementatie te maken onder het batch-eindpunt en stel deze in als de standaardimplementatie.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultTip
Met
--set-defaultde parameter wordt de zojuist gemaakte implementatie ingesteld als de standaardimplementatie van het eindpunt. Het is een handige manier om een nieuwe standaardimplementatie van het eindpunt te maken, met name voor het maken van de eerste implementatie. Als best practice voor productiescenario's wilt u mogelijk een nieuwe implementatie maken zonder deze als standaardinstelling in te stellen. Controleer of de implementatie werkt zoals verwacht en werk de standaardimplementatie later bij. Zie de sectie Een nieuw model implementeren voor meer informatie over het implementeren van dit proces.Controleer de details van het batch-eindpunt en de implementatie.

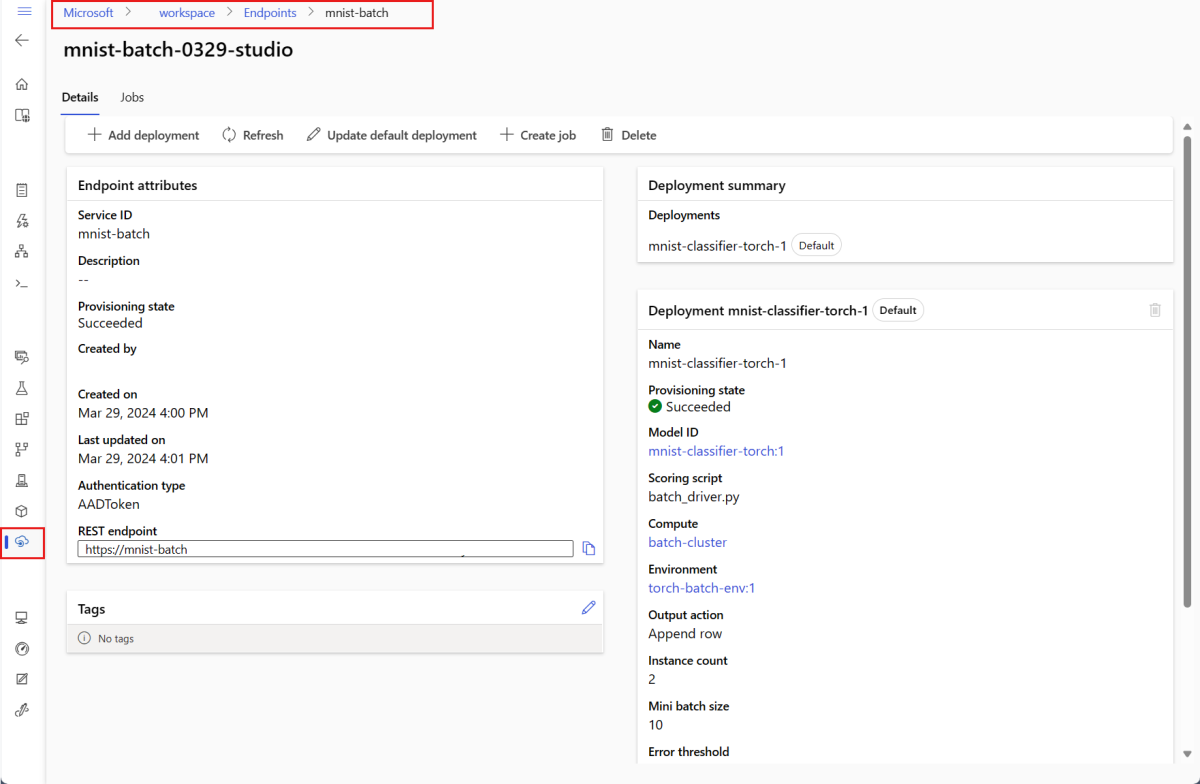
Batch-eindpunten uitvoeren en resultaten openen
Als u een batcheindpunt aanroept, wordt een batchscoretaak geactiveerd. De taak name wordt geretourneerd vanuit het aanroepende antwoord en kan worden gebruikt om de voortgang van de batchscore bij te houden. Wanneer u modellen uitvoert voor scoren in batch-eindpunten, moet u het pad naar de invoergegevens opgeven, zodat de eindpunten de gegevens kunnen vinden die u wilt scoren. In het volgende voorbeeld ziet u hoe u een nieuwe taak start op basis van een voorbeeldgegevens van de MNIST-gegevensset die is opgeslagen in een Azure Storage-account.
U kunt een batch-eindpunt uitvoeren en aanroepen met behulp van Azure CLI, Azure Machine Learning SDK of REST-eindpunten. Zie Taken en invoergegevens maken voor batcheindpunten voor meer informatie over deze opties.
Notitie
Hoe werkt parallelle uitvoering?
Batch-implementaties distribueren werk op bestandsniveau, wat betekent dat een map met 100 bestanden met minibatches van 10 bestanden elk 10 batches van 10 bestanden genereert. U ziet dat dit gebeurt, ongeacht de grootte van de betrokken bestanden. Als uw bestanden te groot zijn om te worden verwerkt in grote minibatches, raden we u aan om de bestanden te splitsen in kleinere bestanden om een hoger niveau van parallelle uitvoering te bereiken of u verlaagt het aantal bestanden per minibatch. Momenteel kunnen batchimplementaties geen rekening houden met scheeftrekken in de grootteverdeling van een bestand.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Batch-eindpunten ondersteunen het lezen van bestanden of mappen die zich op verschillende locaties bevinden. Zie Toegang tot gegevens uit batch-eindpunttaken voor meer informatie over de ondersteunde typen en hoe u deze opgeeft.
Voortgang van batchtaakuitvoering bewaken
Batchgewijs scoretaken duren meestal enige tijd om de volledige set invoer te verwerken.
De volgende code controleert de taakstatus en voert een koppeling naar de Azure Machine Learning-studio uit voor meer informatie.
az ml job show -n $JOB_NAME --web

Resultaten van batchscore controleren
De taakuitvoer wordt opgeslagen in cloudopslag, ofwel in de standaard-blobopslag van de werkruimte of de opslag die u hebt opgegeven. Zie De uitvoerlocatie configureren voor meer informatie over het wijzigen van de standaardinstellingen. Met de volgende stappen kunt u de scoreresultaten weergeven in Azure Storage Explorer wanneer de taak is voltooid:
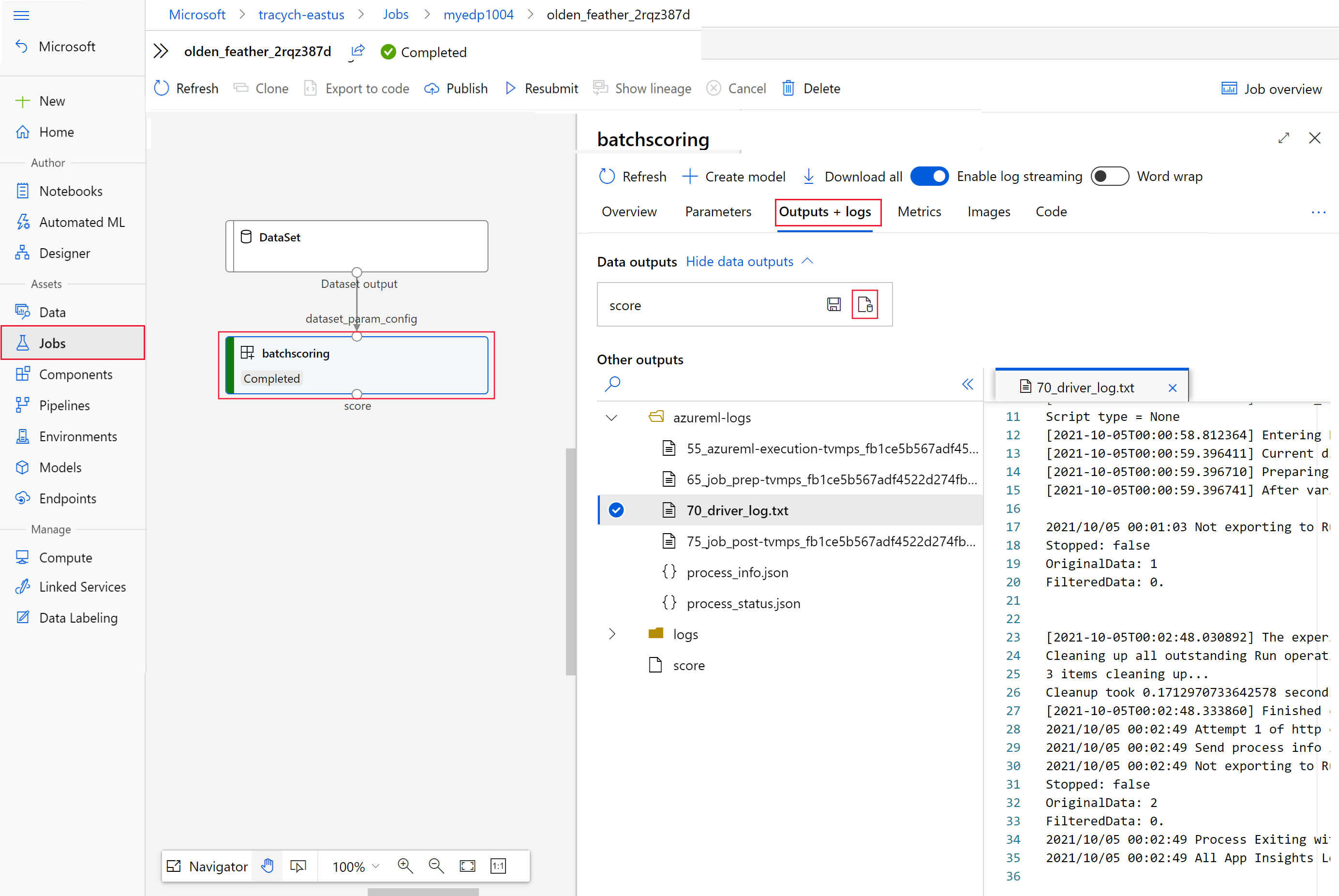
Voer de volgende code uit om de batchscoretaak in Azure Machine Learning-studio te openen. De job studio-koppeling wordt ook opgenomen in het antwoord van
invoke, als de waarde vaninteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webSelecteer de
batchscoringstap in de grafiek van de taak.Selecteer het tabblad Uitvoer en logboeken en selecteer vervolgens Gegevensuitvoer weergeven.
Selecteer in gegevensuitvoer het pictogram om Storage Explorer te openen.
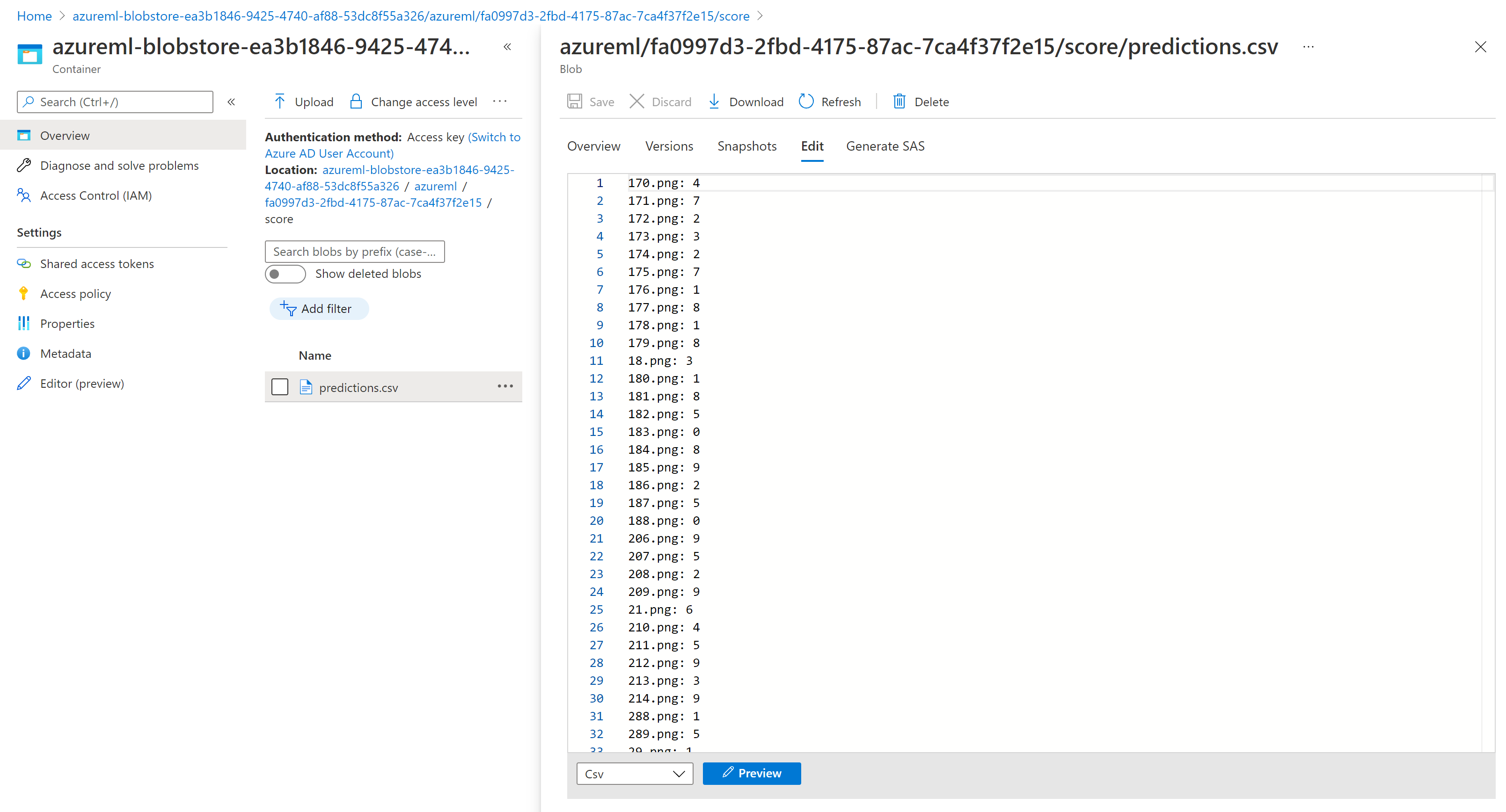
De scoreresultaten in Storage Explorer zijn vergelijkbaar met de volgende voorbeeldpagina:


De uitvoerlocatie configureren
De resultaten voor batchgewijs scoren worden standaard opgeslagen in het standaardblobarchief van de werkruimte in een map met de naam van de taak (een door het systeem gegenereerde GUID). U kunt configureren waar de score-uitvoer moet worden opgeslagen wanneer u het batch-eindpunt aanroept.
Hiermee output-path configureert u een map in een geregistreerde Azure Machine Learning-gegevensopslag. De syntaxis voor de --output-path map is hetzelfde als --input wanneer u een map opgeeft, dat wil azureml://datastores/<datastore-name>/paths/<path-on-datastore>/gezegd. Hiermee --set output_file_name=<your-file-name> configureert u een nieuwe naam voor het uitvoerbestand.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Waarschuwing
U moet een unieke uitvoerlocatie gebruiken. Als het uitvoerbestand bestaat, mislukt de batchscoretaak.
Belangrijk
In tegenstelling tot invoer kunnen uitvoer alleen worden opgeslagen in Azure Machine Learning-gegevensarchieven die worden uitgevoerd op blobopslagaccounts.
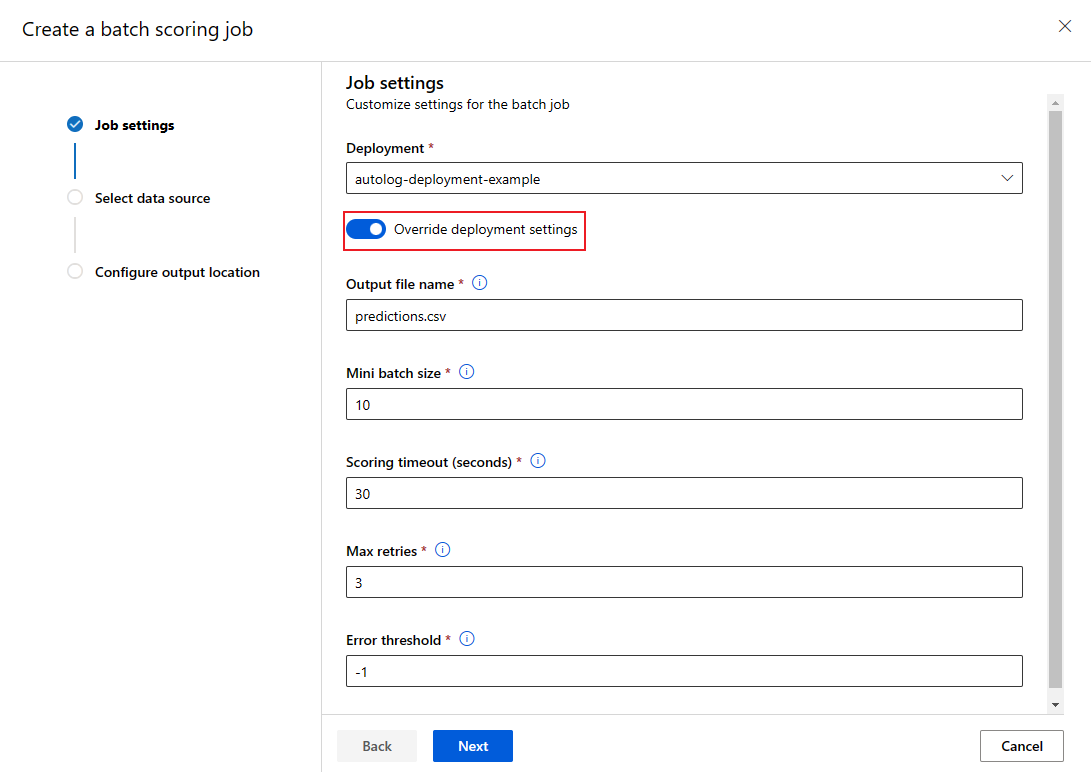
Implementatieconfiguratie voor elke taak overschrijven
Wanneer u een batch-eindpunt aanroept, kunnen sommige instellingen worden overschreven om optimaal gebruik te maken van de rekenresources en om de prestaties te verbeteren. De volgende instellingen kunnen per taak worden geconfigureerd:
- Aantal exemplaren: gebruik deze instelling om het aantal exemplaren te overschrijven dat moet worden aangevraagd vanuit het rekencluster. Voor een groter volume aan gegevensinvoer wilt u bijvoorbeeld meer exemplaren gebruiken om het end-to-end batchgewijs scoren te versnellen.
- Minibatchgrootte: gebruik deze instelling om het aantal bestanden te overschrijven dat in elke minibatch moet worden opgenomen. Het aantal minibatches wordt bepaald door het totale aantal invoerbestanden en de minibatchgrootte. Een kleinere minibatchgrootte genereert meer minibatches. Minibatches kunnen parallel worden uitgevoerd, maar er kan extra plannings- en aanroepoverhead zijn.
- Andere instellingen, zoals het maximum aantal nieuwe pogingen, time-outs en foutdrempels , kunnen worden overschreven. Deze instellingen kunnen van invloed zijn op de end-to-end batchscoretijd voor verschillende workloads.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Implementaties toevoegen aan een eindpunt
Zodra u een batch-eindpunt met een implementatie hebt, kunt u uw model verder verfijnen en nieuwe implementaties toevoegen. Batch-eindpunten blijven de standaardimplementatie leveren terwijl u nieuwe modellen onder hetzelfde eindpunt ontwikkelt en implementeert. Implementaties hebben geen invloed op elkaar.
In dit voorbeeld voegt u een tweede implementatie toe die gebruikmaakt van een model dat is gebouwd met Keras en TensorFlow om hetzelfde MNIST-probleem op te lossen.
Een tweede implementatie toevoegen
Maak een omgeving waarin uw batchimplementatie wordt uitgevoerd. Neem de omgeving op voor elke afhankelijkheid die uw code nodig heeft om uit te voeren. U moet ook de bibliotheek
azureml-coretoevoegen, omdat batchimplementaties moeten werken. De volgende omgevingsdefinitie bevat de vereiste bibliotheken voor het uitvoeren van een model met TensorFlow.De omgevingsdefinitie is opgenomen in de implementatiedefinitie zelf als een anonieme omgeving.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlHet gebruikte Conda-bestand ziet er als volgt uit:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Maak een scorescript voor het model:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Een implementatiedefinitie maken
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvDe implementatie maken:
Voer de volgende code uit om een batch-implementatie te maken onder het batch-eindpunt en deze in te stellen als de standaardimplementatie.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMETip
De
--set-defaultparameter ontbreekt in dit geval. Als best practice voor productiescenario's maakt u een nieuwe implementatie zonder deze als standaardinstelling in te stellen. Controleer deze en werk de standaardimplementatie later bij.
Een niet-standaard batchimplementatie testen
Als u de nieuwe niet-standaardimplementatie wilt testen, moet u de naam weten van de implementatie die u wilt uitvoeren.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Kennisgeving --deployment-name wordt gebruikt om de implementatie op te geven die moet worden uitgevoerd. Met deze parameter kunt u een niet-standaardimplementatie uitvoeren invoke zonder de standaardimplementatie van het batch-eindpunt bij te werken.
De standaardbatchimplementatie bijwerken
Hoewel u een specifieke implementatie binnen een eindpunt kunt aanroepen, wilt u meestal het eindpunt zelf aanroepen en het eindpunt laten bepalen welke implementatie moet worden gebruikt, de standaardimplementatie. U kunt de standaardimplementatie wijzigen (en dus het model dat de implementatie bedient) wijzigen zonder uw contract te wijzigen met de gebruiker die het eindpunt aanroept. Gebruik de volgende code om de standaardimplementatie bij te werken:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
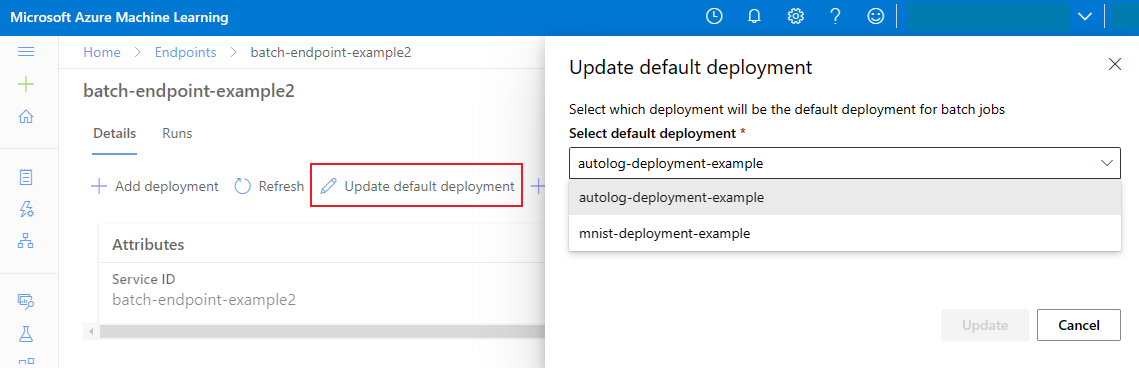
Het batch-eindpunt en de implementatie verwijderen
Als u de oude batchimplementatie niet gebruikt, verwijdert u deze door de volgende code uit te voeren. --yes wordt gebruikt om de verwijdering te bevestigen.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Voer de volgende code uit om het batch-eindpunt en alle onderliggende implementaties te verwijderen. Batchscoretaken worden niet verwijderd.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes