Informatie over entiteiten op het hoogste niveau in het beheerde functiearchief
In dit document worden de entiteiten op het hoogste niveau in het beheerde functiearchief beschreven.
Zie Wat is het beheerde functiearchief voor meer informatie over het beheerde functiearchief?
Functiearchief
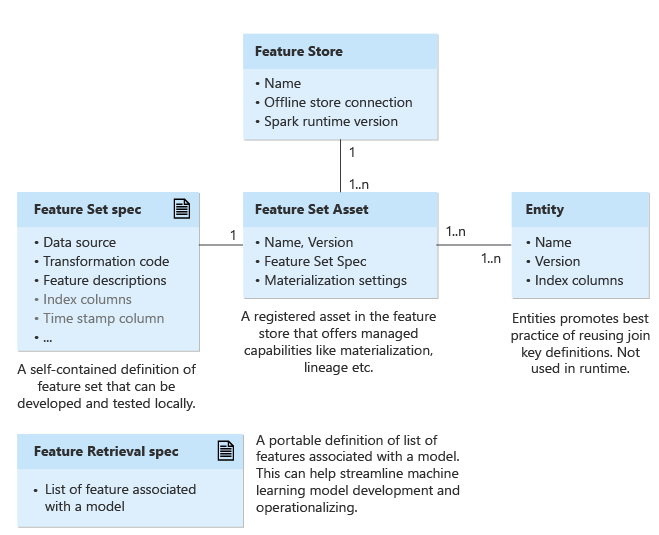
U kunt functiesets maken en beheren via een functiearchief. Functiesets zijn een verzameling functies. U kunt eventueel een materialisatiearchief (offline winkelverbinding) koppelen aan een functiearchief om de functies regelmatig vooraf te compileren en te behouden. Het kan het ophalen van functies tijdens de training of deductie sneller en betrouwbaarder maken.
Zie HET YAML-schema voor CLI-functies (v2) voor meer informatie over de configuratie
Entiteiten
Entiteiten bevatten de indexkolommen voor logische entiteiten in een onderneming. Voorbeelden van entiteiten zijn accountentiteit, klantentiteit, enzovoort. Entiteiten helpen bij het afdwingen van, zoals best practice, het gebruik van dezelfde indexkolomdefinities in de functiesets die gebruikmaken van dezelfde logische entiteiten.
Entiteiten worden doorgaans eenmaal gemaakt en vervolgens opnieuw gebruikt in functiesets. Entiteiten zijn versiebeheer.
Zie HET YAML-schema van cli (v2) voor meer informatie over de configuratie
Specificatie en asset van functieset
Functiesets zijn een verzameling functies die worden gegenereerd door transformaties toe te passen op bronsysteemgegevens. Functiesets bevatten een bron, de transformatiefunctie en de materialisatie-instellingen. Momenteel ondersteunen we pySpark-functietransformatiecode.
Begin met het maken van een specificatie van een functieset. Een specificatie van een functieset is een zelfstandige definitie van een functieset die u lokaal kunt ontwikkelen en testen.
Een specificatie van een functieset bestaat doorgaans uit de volgende parameters:
source: Aan welke bron(en) wordt deze functie toegewezentransformation(optioneel): De transformatielogica, toegepast op de brongegevens, om functies te maken. In ons geval gebruiken we Spark als de ondersteunde rekenkracht.- Namen van de kolommen die de
index_columnsen detimestamp_column: Deze namen zijn vereist wanneer gebruikers functiegegevens proberen samen te voegen met observatiegegevens (meer hierover later) materialization_settings(optioneel): Vereist om de functiewaarden in een materialisatiearchief in de cache op te slaan voor efficiënt ophalen.
Na het ontwikkelen en testen van de functiesetspecificatie in uw lokale/ontwikkelomgeving, kunt u de specificatie registreren als een functiesetasset bij het functiearchief. De functiesetasset biedt beheerde mogelijkheden, zoals versiebeheer en materialisatie.
Zie voor meer informatie over de YAML-specificatie van de functieset CLI (v2) specificatie YAML-schema
Specificatie voor het ophalen van functies
Een specificatie voor het ophalen van functies is een draagbare definitie van een functielijst die is gekoppeld aan een model. Het kan helpen bij het stroomlijnen van het ontwikkelen en operationeel maken van machine learning-modellen. Een specificatie voor het ophalen van functies is doorgaans een invoer voor de trainingspijplijn. Het helpt bij het genereren van de trainingsgegevens. Het kan worden verpakt met het model. Daarnaast wordt deze door deductiestap gebruikt om de functies op te zoeken. Het integreert alle fasen van de levenscyclus van machine learning. Wijzigingen in uw trainings- en deductiepijplijn kunnen worden geminimaliseerd tijdens het experimenteren en implementeren.
Het gebruik van een specificatie voor het ophalen van functies en het ingebouwde onderdeel voor het ophalen van functies zijn optioneel. U kunt de get_offline_features() API desgewenst rechtstreeks gebruiken.
Zie HET YAML-schema van cli (v2) voor meer informatie over de YAML-specificatie voor het ophalen van functies.