Wat is het beheerde functiearchief?
In onze visie voor het beheerde functiearchief willen we machine learning-professionals in staat stellen om onafhankelijk functies te ontwikkelen en te produceren. U geeft een specificatie van een functieset op en laat het systeem vervolgens de bediening, beveiliging en bewaking van de functies afhandelen. Dit maakt u vrij van de overhead van het instellen en beheren van onderliggende functie-engineeringpijplijnen.
Dankzij de integratie van onze functieopslag in de levenscyclus van machine learning kunt u sneller experimenteren en modellen verzenden, de betrouwbaarheid van hun modellen verhogen en uw operationele kosten verlagen. De herdefinitie van de machine learning-ervaring biedt deze voordelen.
Zie Informatie over entiteiten op het hoogste niveau in het functiearchief, inclusief specificaties voor functieset, voor meer informatie over entiteiten op het hoogste niveau in het beheerde functiearchief.
Wat zijn functies?
Functies fungeren als invoergegevens voor uw model. Voor gegevensgestuurde gebruiksvoorbeelden in een bedrijfscontext transformeren functies vaak historische gegevens (eenvoudige aggregaties, vensteraggregaties, transformaties op rijniveau, enzovoort). Denk bijvoorbeeld aan een machine learning-model voor klantverloop. De modelinvoer kan bestaan uit klantinteractiegegevens zoals 7day_transactions_sum (aantal transacties in de afgelopen zeven dagen) of 7day_complaints_sum (aantal klachten in de afgelopen zeven dagen). Beide statistische functies worden berekend op de vorige zevendaagse gegevens.
Problemen opgelost door functiearchief
Als u beter inzicht wilt krijgen in het beheerde functiearchief, moet u eerst de problemen begrijpen die door het functiearchief kunnen worden opgelost.
Met functieopslag kunt u functies zoeken en hergebruiken die door uw team zijn gemaakt, om redundant werk te voorkomen en consistente voorspellingen te leveren.
U kunt nieuwe functies maken met de mogelijkheid voor transformaties om te voldoen aan de technische vereisten voor functies op een flexibele, dynamische manier.
Het systeem implementeert en beheert de functie-engineeringpijplijnen die nodig zijn voor transformatie en materialisatie om uw team te bevrijden van de operationele aspecten.
U kunt dezelfde functiepijplijn gebruiken, oorspronkelijk gebruikt voor het genereren van trainingsgegevens, voor nieuw gebruik voor deductiedoeleinden om online/offline consistentie te bieden en om scheefheid van training/servering te voorkomen.
Beheerde functieopslag delen
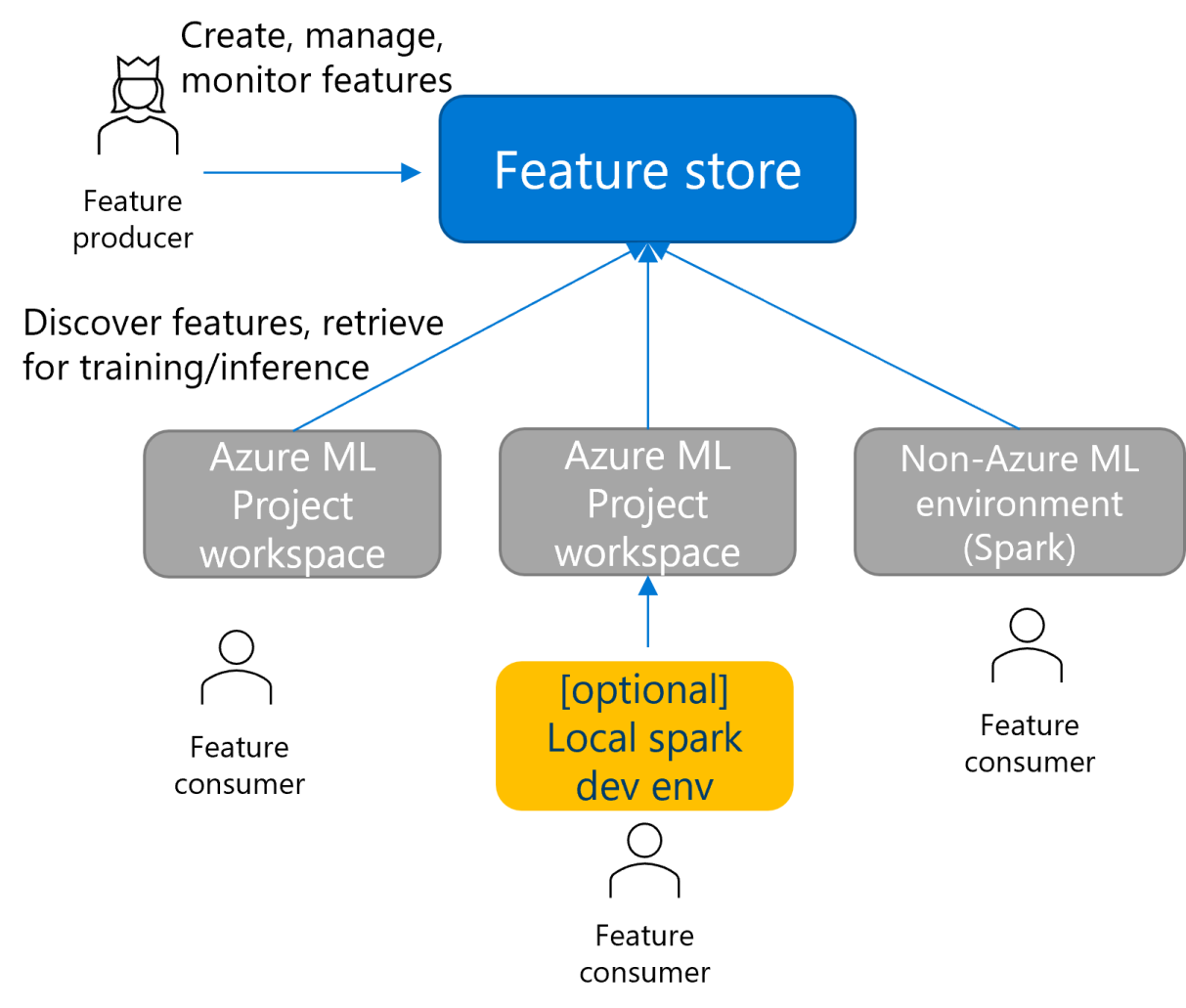
Functiearchief is een nieuw type werkruimte dat meerdere projectwerkruimten kunnen gebruiken. U kunt functies van andere Spark-omgevingen dan Azure Machine Learning gebruiken, zoals Azure Databricks. U kunt ook lokale ontwikkeling en testen van functies uitvoeren.
Overzicht van functiearchief
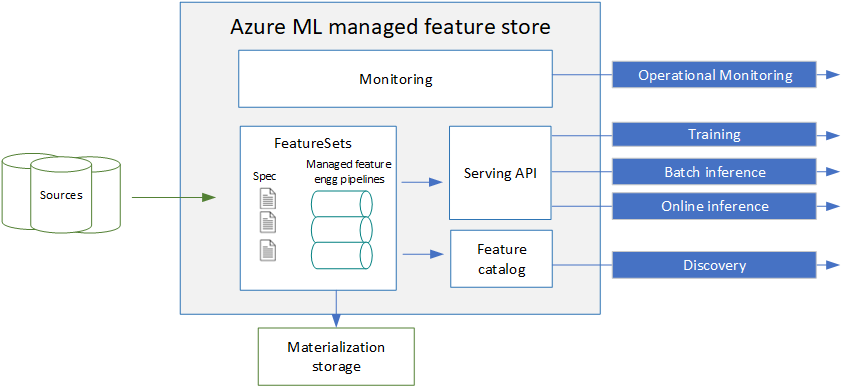
Voor het beheerde functiearchief geeft u een specificatie van de functieset op. Vervolgens verwerkt het systeem de bediening, beveiliging en bewaking van uw functies. Een specificatie van een functieset bevat functiedefinities en optionele transformatielogica. U kunt ook declaratief materialisatie-instellingen opgeven om te materialiseren naar een offlinearchief (ADLS Gen2). Het systeem genereert en beheert de onderliggende functie materialisatiepijplijnen. U kunt de functiecatalogus gebruiken om functies te zoeken, te delen en opnieuw te gebruiken. Met de ondersteunende API kunnen gebruikers functies opzoeken om gegevens te genereren voor training en deductie. De ondersteunende API kan de gegevens rechtstreeks uit de bron ophalen of uit een offline materialisatiearchief voor training/batchdeductie. Het systeem biedt ook mogelijkheden voor het bewaken van functie-materialisatietaken.
Voordelen van het gebruik van het beheerde functiearchief van Azure Machine Learning
- Vergroot de flexibiliteit bij het verzenden van het model (prototypen naar operationalisatie):
- Functies ontdekken en opnieuw gebruiken in plaats van helemaal opnieuw functies te maken
- Snellere experimenten met lokale ontwikkeling/test van nieuwe functies met transformatieondersteuning en het gebruik van functieherstelspecificaties als bindweefsel in de MLOps-stroom
- Declaratieve materialisatie en backfill
- Vooraf gedefinieerde constructies: onderdeel voor het ophalen van functies en het ophalen van onderdelenspecificaties
- Verbetert de betrouwbaarheid van ML-modellen
- Een consistente functiedefinitie voor bedrijfseenheid/organisatie
- Onderdelensets zijn versiebeheer en onveranderbaar: nieuwere versie van modellen kan nieuwere functieversies gebruiken zonder de oudere versie van het model te verstoren
- Materialisatie van functieset bewaken
- Materialisatie vermijdt training/scheeftrekken
- Het ophalen van functies ondersteunt tijdelijke joins van een bepaald tijdstip (ook wel bekend als tijdreizen) om gegevenslekken te voorkomen.
- Verlaagt de kosten
- Functies die door anderen in de organisatie zijn gemaakt, opnieuw gebruiken
- Materialisatie en bewaking worden beheerd door het systeem, om de technische kosten te verlagen
Functies ontdekken en beheren
Het beheerde functiearchief biedt deze mogelijkheden voor functiedetectie en -beheer:
- Functies zoeken en hergebruiken - U kunt functies zoeken en opnieuw gebruiken in functiearchieven
- Ondersteuning voor versiebeheer: onderdelensets zijn versiebeheer en onveranderbaar, zodat u de levenscyclus van de functieset onafhankelijk kunt beheren. U kunt nieuwe modelversies implementeren met verschillende functieversies en onderbreking van de oudere modelversie voorkomen
- Kosten weergeven op functiearchiefniveau : de primaire kosten die zijn gekoppeld aan het gebruik van het functiearchief, zijn beheerde Spark-materialisatietaken. U kunt deze kosten zien op het niveau van het functiearchief
- Gebruik van functieset : u kunt de lijst met geregistreerde modellen bekijken met behulp van de functiesets.
Functietransformatie
Functietransformatie omvat het wijzigen van gegevenssetfuncties om de modelprestaties te verbeteren. Transformatiecode, gedefinieerd in een functiespecificatie, verwerkt functietransformatie. Voor snellere experimenten voert transformatiecode berekeningen uit op brongegevens en maakt lokale ontwikkeling en testen van transformaties mogelijk.
Het beheerde functiearchief biedt deze mogelijkheden voor functietransformatie:
- Ondersteuning voor aangepaste transformaties : u kunt een Spark-transformator schrijven om functies te ontwikkelen met aangepaste transformaties, zoals aggregaties op basis van vensters, bijvoorbeeld
- Ondersteuning voor vooraf samengestelde functies : u kunt vooraf samengestelde functies in het functiearchief opnemen en deze leveren zonder code te schrijven
- Lokale ontwikkeling en testen : met een Spark-omgeving kunt u functiesets volledig lokaal ontwikkelen en testen
Functie-materialisatie
Materialisatie omvat de berekening van functiewaarden voor een bepaald functievenster en persistentie van deze waarden in een materialisatiearchief. Nu kunnen functiegegevens sneller en betrouwbaarder worden opgehaald voor trainings- en deductiedoeleinden.
- Materialisatiepijplijn voor beheerde functies: u geeft declaratief het materialisatieschema op en het systeem verwerkt vervolgens de planning, precomputatie en materialisatie van de waarden in het materialisatiearchief.
- Ondersteuning voor backfill : u kunt functiesets on-demand materialisatie uitvoeren voor een bepaald functievenster
- Beheerde Spark-ondersteuning voor materialisatie : met Azure Machine Learning beheerde Spark (in serverloze rekenprocessen) worden de materialisatietaken uitgevoerd. Het maakt u vrij van het instellen en beheren van de Spark-infrastructuur.
Notitie
De materialisatie van zowel offlinestore (ADLS Gen2) als de online winkel (Redis) wordt momenteel ondersteund.
Functie ophalen
Azure Machine Learning bevat een ingebouwd onderdeel dat het ophalen van offlinefuncties afhandelt. Hiermee kunt u de functies in de trainings- en batchdeductiestappen van een Azure Machine Learning-pijplijntaak gebruiken.
Het beheerde functiearchief biedt deze mogelijkheden voor het ophalen van functies:
- Declaratieve trainingsgegevens genereren - Met het ingebouwde onderdeel voor het ophalen van functies kunt u trainingsgegevens in uw pijplijnen genereren zonder code te schrijven
- Declaratieve batchdeductiegegevens genereren : met hetzelfde ingebouwde onderdeel voor het ophalen van functies kunt u batchdeductiegegevens genereren
- Programmatisch ophalen van functies : u kunt python-SDK
get_offline_features()ook gebruiken om de training/deductiegegevens te genereren
Bewaking
Het beheerde functiearchief biedt de volgende bewakingsmogelijkheden:
- Status van materialisatietaken : u kunt de status van materialisatietaken weergeven met behulp van de gebruikersinterface, CLI of SDK
- Melding over materialisatietaken - U kunt e-mailmeldingen instellen voor de verschillende statussen van de materialisatietaken
Beveiliging
Het beheerde functiearchief biedt de volgende beveiligingsmogelijkheden:
- RBAC : op rollen gebaseerd toegangsbeheer voor het functiearchief, de functieset en entiteiten.
- Query's uitvoeren in functiearchieven : u kunt meerdere functiearchieven maken met verschillende toegangsmachtigingen voor gebruikers, maar query's toestaan (bijvoorbeeld trainingsgegevens genereren) uit meerdere functiearchieven