Een afbeeldingslabelproject instellen
Meer informatie over het maken en uitvoeren van projecten voor gegevenslabels om installatiekopieën te labelen in Azure Machine Learning. Gebruik machine learning (ML)-ondersteunde gegevenslabels of human-in-the-loop-labeling om u te helpen met de taak.
Labels instellen voor classificatie, objectdetectie (begrenzingsvak), exemplaarsegmentatie (veelhoek) of semantische segmentatie (preview).
U kunt ook het hulpprogramma voor gegevenslabels in Azure Machine Learning gebruiken om een tekstlabelproject te maken.
Belangrijk
Items die in dit artikel zijn gemarkeerd (preview) zijn momenteel beschikbaar als openbare preview. De preview-versie wordt aangeboden zonder Service Level Agreement en wordt niet aanbevolen voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt. Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Mogelijkheden voor het labelen van afbeeldingen
Azure Machine Learning-gegevenslabels is een hulpprogramma dat u kunt gebruiken om projecten voor gegevenslabels te maken, beheren en bewaken. Gebruik deze voor het volgende:
- Coördineer gegevens, labels en teamleden om de labeltaken efficiënt te beheren.
- Houd de voortgang bij en onderhoud de wachtrij met onvolledige labeltaken.
- Start en stop het project en beheer de voortgang van het labelen.
- Controleer en exporteer de gelabelde gegevens als een Azure Machine Learning-gegevensset.
Belangrijk
De gegevensafbeeldingen waarmee u werkt in het hulpprogramma voor gegevenslabels van Azure Machine Learning moeten beschikbaar zijn in een Azure Blob Storage-gegevensarchief. Als u geen bestaand gegevensarchief hebt, kunt u uw gegevensbestanden uploaden naar een nieuw gegevensarchief wanneer u een project maakt.
Afbeeldingsgegevens kunnen elk bestand met een van deze bestandsextensies zijn:
.jpg.jpeg.png.jpe.jfif.bmp.tif.tiff.dcm.dicom
Elk bestand is een item dat moet worden gelabeld.
U kunt ook een MLTable gegevensasset gebruiken als invoer voor een afbeeldingslabelproject, zolang de afbeeldingen in de tabel een van de bovenstaande indelingen hebben. Zie Gegevensassets gebruiken MLTable voor meer informatie.
Vereisten
U gebruikt deze items voor het instellen van afbeeldingslabels in Azure Machine Learning:
- De gegevens die u wilt labelen, in lokale bestanden of in Azure Blob Storage.
- De set labels die u wilt toepassen.
- De instructies voor het labelen.
- Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint.
- Een Azure Machine Learning-werkruimte. Raadpleeg Een Azure Machine Learning-werkruimte maken.
Een labelingsproject voor installatiekopieën maken
Labelprojecten worden beheerd in Azure Machine Learning. Gebruik de pagina Gegevenslabeling in Machine Learning om uw projecten te beheren.
Als uw gegevens zich al in Azure Blob Storage bevinden, moet u ervoor zorgen dat deze beschikbaar zijn als een gegevensarchief voordat u het labelproject maakt.
Als u een project wilt maken, selecteert u Project toevoegen.
Voer voor projectnaam een naam in voor het project.
U kunt de projectnaam niet opnieuw gebruiken, zelfs niet als u het project verwijdert.
Als u een afbeeldingslabelproject wilt maken, selecteert u Afbeelding voor mediatype.
Selecteer een optie voor het type labeltaak voor uw scenario:
- Als u slechts één label wilt toepassen op een afbeelding uit een set labels, selecteert u Afbeeldingsclassificatie met meerdere klassen.
- Als u een of meer labels wilt toepassen op een afbeelding uit een set labels, selecteert u Afbeeldingsclassificatie met meerdere labels. Een foto van een hond kan bijvoorbeeld worden gelabeld met zowel hond als overdag.
- Als u een label wilt toewijzen aan elk object in een afbeelding en begrenzingsvakken wilt toevoegen, selecteert u Objectidentificatie (Begrenzingsvak).
- Als u een label wilt toewijzen aan elk object in een afbeelding en een veelhoek rond elk object wilt tekenen, selecteert u Polygoon (exemplaarsegmentatie).
- Als u maskers op een afbeelding wilt tekenen en een labelklasse wilt toewijzen op pixelniveau, selecteert u Semantische segmentatie (preview).
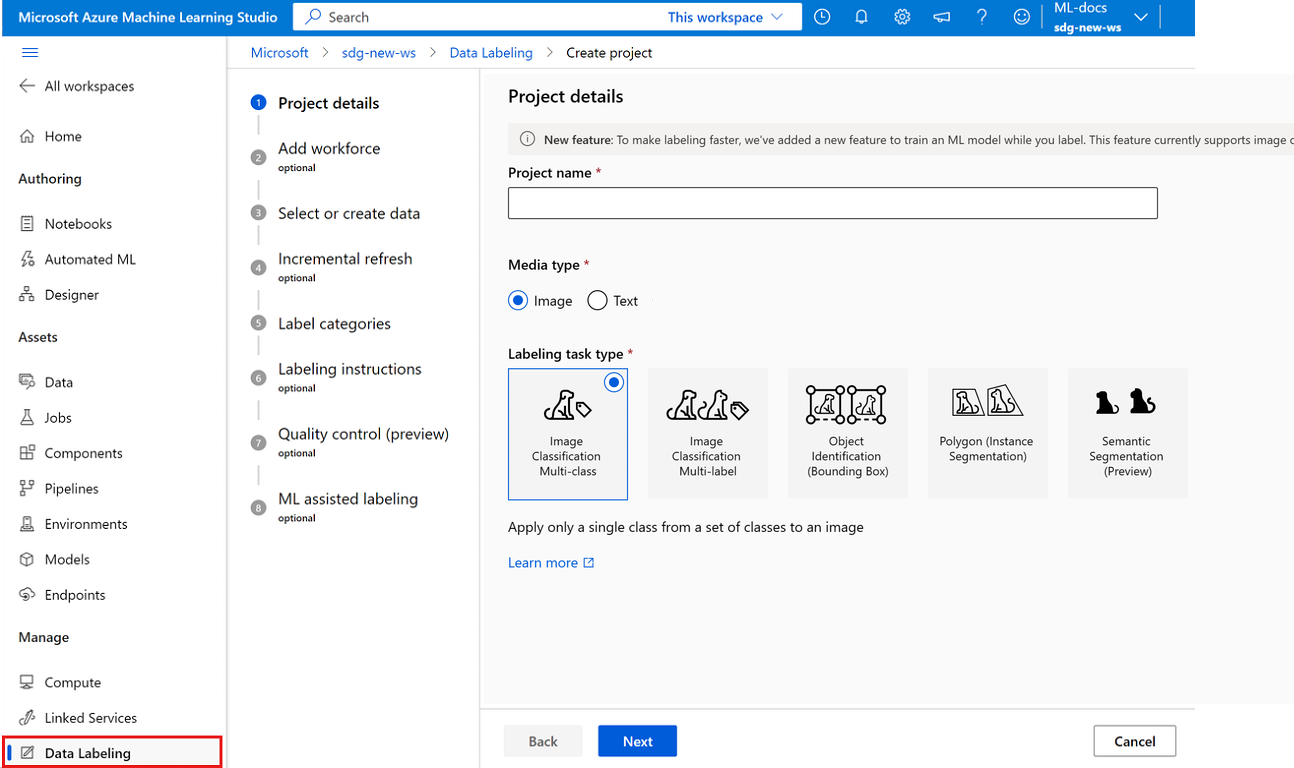
Selecteer Volgende om door te gaan.
Personeel toevoegen (optioneel)
Selecteer Alleen een leverancierlabelbedrijf uit Azure Marketplace gebruiken als u een gegevenslabelbedrijf hebt ingeschakeld vanuit Azure Marketplace. Selecteer vervolgens de leverancier. Als uw leverancier niet in de lijst wordt weergegeven, schakelt u deze optie uit.
Zorg ervoor dat u eerst contact op neemt met de leverancier en een contract ondertekent. Zie Werken met een leverancier van gegevenslabels (preview) voor meer informatie.
Selecteer Volgende om door te gaan.
Geef de gegevens op die u wilt labelen
Als u al een gegevensset hebt gemaakt die uw gegevens bevat, selecteert u de gegevensset in de vervolgkeuzelijst Een bestaande gegevensset selecteren.
U kunt ook Een gegevensset maken selecteren om een bestaand Azure-gegevensarchief te gebruiken of lokale bestanden te uploaden.
Notitie
Een project mag niet meer dan 500.000 bestanden bevatten. Als uw gegevensset het aantal bestanden overschrijdt, worden alleen de eerste 500.000 bestanden geladen.
Toewijzing van gegevenskolommen (preview)
Als u een MLTable-gegevensasset selecteert, wordt er een andere stap voor gegevenskolomtoewijzing weergegeven om de kolom op te geven die de afbeeldings-URL's bevat.
U moet een kolom opgeven die is toegewezen aan het veld Afbeelding . U kunt eventueel ook andere kolommen toewijzen die aanwezig zijn in de gegevens. Als uw gegevens bijvoorbeeld een kolom Label bevatten, kunt u deze toewijzen aan het veld Categorie . Als uw gegevens een kolom Betrouwbaarheid bevatten, kunt u deze toewijzen aan het veld Betrouwbaarheid .
Als u labels uit een vorig project importeert, moeten de labels dezelfde indeling hebben als de labels die u maakt. Als u bijvoorbeeld begrenzingsvaklabels maakt, moeten de labels die u importeert ook begrenzingsvaklabels zijn.
Importopties (preview)
Wanneer u een categoriekolom opneemt in de stap Gegevenskolomtoewijzing , gebruikt u Importopties om op te geven hoe de gelabelde gegevens moeten worden behandeld.
U moet een kolom opgeven die is toegewezen aan het veld Afbeelding . U kunt eventueel ook andere kolommen toewijzen die aanwezig zijn in de gegevens. Als uw gegevens bijvoorbeeld een kolom Label bevatten, kunt u deze toewijzen aan het veld Categorie . Als uw gegevens een kolom Betrouwbaarheid bevatten, kunt u deze toewijzen aan het veld Betrouwbaarheid .
Als u labels uit een vorig project importeert, moeten de labels dezelfde indeling hebben als de labels die u maakt. Als u bijvoorbeeld begrenzingsvaklabels maakt, moeten de labels die u importeert ook begrenzingsvaklabels zijn.
Een gegevensset maken uit een Azure-gegevensopslag
In veel gevallen kunt u lokale bestanden uploaden. Azure Storage Explorer biedt echter een snellere en krachtigere manier om een grote hoeveelheid gegevens over te dragen. We raden Storage Explorer aan als de standaardmanier om bestanden te verplaatsen.
Een gegevensset maken op basis van gegevens die al zijn opgeslagen in Blob Storage:
- Selecteer Maken.
- Voer bij Naam een naam in voor uw gegevensset. Voer desgewenst een beschrijving in.
- Zorg ervoor dat het type gegevensset is ingesteld op Bestand. Alleen bestandstypen worden ondersteund voor afbeeldingen.
- Selecteer Volgende.
- Selecteer In Azure Storage en selecteer vervolgens Volgende.
- Selecteer het gegevensarchief en selecteer vervolgens Volgende.
- Als uw gegevens zich in een submap in Blob Storage bevinden, kiest u Bladeren om het pad te selecteren.
- Als u alle bestanden in de submappen van het geselecteerde pad wilt opnemen, voegt u het pad toe
/**. - Als u alle gegevens in de huidige container en de bijbehorende submappen wilt opnemen, voegt
**/*.*u het pad toe.
- Als u alle bestanden in de submappen van het geselecteerde pad wilt opnemen, voegt u het pad toe
- Selecteer Maken.
- Selecteer de gegevensasset die u hebt gemaakt.
Een gegevensset maken uit geüploade gegevens
Uw gegevens rechtstreeks uploaden:
- Selecteer Maken.
- Voer bij Naam een naam in voor uw gegevensset. Voer desgewenst een beschrijving in.
- Zorg ervoor dat het type gegevensset is ingesteld op Bestand. Alleen bestandstypen worden ondersteund voor afbeeldingen.
- Selecteer Volgende.
- Selecteer Uit lokale bestanden en selecteer vervolgens Volgende.
- (Optioneel) Selecteer een gegevensarchief. U kunt ook de standaardwaarde laten staan om te uploaden naar het standaard-blobarchief (workspaceblobstore) voor uw Machine Learning-werkruimte.
- Selecteer Volgende.
- Selecteer Uploadbestanden>uploaden of Uploadmap uploaden> om de lokale bestanden of mappen te selecteren die u wilt uploaden.
- Zoek uw bestanden of mappen in het browservenster en selecteer Vervolgens Openen.
- Ga door met het selecteren van Uploaden totdat u al uw bestanden en mappen opgeeft.
- Desgewenst kunt u ervoor kiezen om het selectievakje Overschrijven in te schakelen als dit al bestaat . Controleer de lijst met bestanden en mappen.
- Selecteer Volgende.
- Bevestig de details. Selecteer Terug om de instellingen te wijzigen of selecteer Maken om de gegevensset te maken.
- Selecteer ten slotte de gegevensasset die u hebt gemaakt.
Incrementeel vernieuwen configureren
Als u nieuwe gegevensbestanden aan uw gegevensset wilt toevoegen, gebruikt u incrementeel vernieuwen om de bestanden aan uw project toe te voegen.
Wanneer incrementeel vernieuwen met regelmatige tussenpozen is ingesteld, wordt de gegevensset periodiek gecontroleerd of nieuwe bestanden aan een project worden toegevoegd op basis van de voltooiingssnelheid van labels. De controle op nieuwe gegevens stopt wanneer het project maximaal 500.000 bestanden bevat.
Selecteer Incrementeel vernieuwen met regelmatige tussenpozen inschakelen wanneer u wilt dat uw project voortdurend controleert op nieuwe gegevens in het gegevensarchief.
Schakel de selectie uit als u niet wilt dat nieuwe bestanden in het gegevensarchief automatisch worden toegevoegd aan uw project.
Belangrijk
Wanneer incrementeel vernieuwen is ingeschakeld, maakt u geen nieuwe versie voor de gegevensset die u wilt bijwerken. Als u dit wel doet, worden de updates niet weergegeven omdat het gegevenslabelproject is vastgemaakt aan de eerste versie. Gebruik in plaats daarvan Azure Storage Explorer om uw gegevens te wijzigen in de juiste map in Blob Storage.
Verwijder ook geen gegevens. Als u gegevens verwijdert uit de gegevensset die uw project gebruikt, wordt er een fout in het project veroorzaakt.
Nadat het project is gemaakt, gebruikt u het tabblad Details om incrementeel vernieuwen te wijzigen, bekijkt u het tijdstempel voor de laatste vernieuwing en vraagt u een onmiddellijke vernieuwing van gegevens aan.
Labelklassen opgeven
Geef op de pagina Labelcategorieën een set klassen op om uw gegevens te categoriseren.
De nauwkeurigheid en snelheid van uw labelers worden beïnvloed door hun vermogen om te kiezen tussen klassen. Gebruik bijvoorbeeld, in plaats van het hele geslacht en soort van planten, alleen een veldcode op of gebruik een afkorting voor het plantengeslacht.
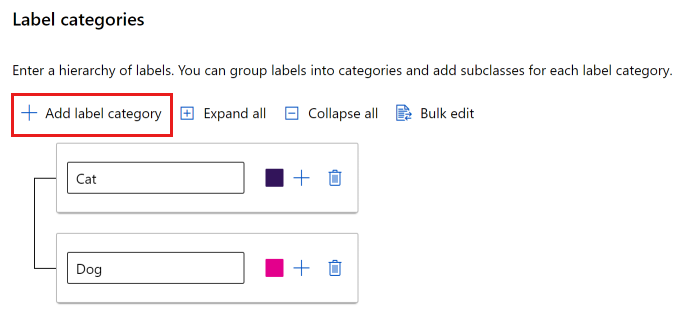
U kunt een platte lijst gebruiken of groepen labels maken.
Als u een platte lijst wilt maken, selecteert u Labelcategorie toevoegen om elk label te maken.
Als u labels in verschillende groepen wilt maken, selecteert u Labelcategorie toevoegen om de labels op het hoogste niveau te maken. Selecteer vervolgens het plusteken (+) onder elk hoogste niveau om het volgende niveau van labels voor die categorie te maken. U kunt maximaal zes niveaus maken voor elke groepering.
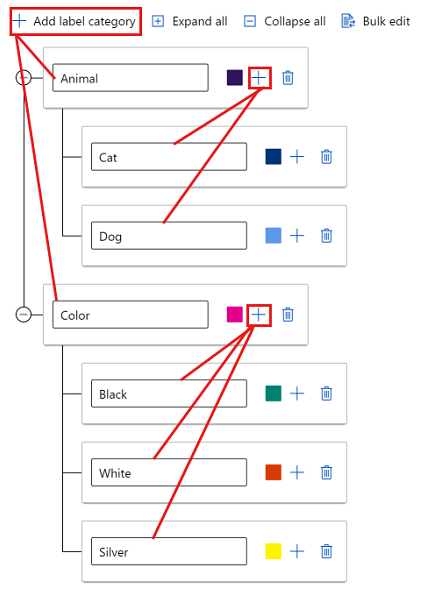
U kunt labels op elk niveau selecteren tijdens het tagproces. De labelsAnimal, Animal/Cat, Animal/Dog, , Color, Color/Blacken Color/Silver Color/Whitezijn bijvoorbeeld allemaal beschikbare opties voor een label. In een project met meerdere labels hoeft u geen van elke categorie te kiezen. Als dat uw bedoeling is, moet u deze informatie in uw instructies opnemen.
De taak voor het labelen van afbeeldingen beschrijven
Het is belangrijk om de labeltaak duidelijk uit te leggen. Op de pagina Labelinstructies kunt u een koppeling toevoegen aan een externe site met labelinstructies of u kunt instructies opgeven in het invoervak op de pagina. Houd de instructies taakgericht en geschikt voor de doelgroep. Houd rekening met deze vragen:
- Wat zijn de labels die labelaars zien en hoe kiezen ze ertussen? Is er een referentietekst waarnaar kan worden verwezen?
- Wat moeten ze doen als er geen geschikt label aanwezig is?
- Wat moeten ze doen als meerdere labels geschikt zijn?
- Welke drempelwaarde voor betrouwbaarheid moeten ze toepassen op een label? Wilt u de beste schatting van de labeler als ze het niet zeker weten?
- Wat moeten labelaars doen met belangrijke objecten die gedeeltelijk buiten beeld vallen of overlappen?
- Wat moeten ze doen wanneer een belangrijk object wordt afgesneden door de rand van de afbeelding?
- Wat moeten ze doen als ze denken dat ze een fout hebben gemaakt nadat ze een label hebben ingediend?
- Wat moeten ze doen als ze problemen met de beeldkwaliteit ontdekken, waaronder slechte lichtomstandigheden, reflecties, verlies van focus, ongewenste achtergrond, abnormale camerahoeken, enzovoort?
- Wat moeten ze doen als meerdere revisoren verschillende meningen hebben over het toepassen van een label?
Voor begrenzingsvakken zijn dit een aantal belangrijke vragen:
- Hoe wordt het begrenzingsvak voor deze taak gedefinieerd? Moet het volledig op het interieur van het object blijven of moet het aan de buitenkant liggen? Moet het vak zo klein mogelijk om het object vallen, of mag er wat speelruimte zijn?
- Hoe zorgvuldig en consistent verwacht u dat labelaars zijn bij het definiëren van begrenzingsvakken?
- Wat is de visuele definitie van elke labelklasse? Kunt u voor elke klasse een lijst met normale, rand- en tellercases opgeven?
- Wat moeten de labelaars doen als het object klein is? Moet het worden gelabeld als een object of moeten ze dat object negeren als achtergrond?
- Hoe moeten labelers een object verwerken dat slechts gedeeltelijk in de afbeelding wordt weergegeven?
- Hoe moeten labelers een object verwerken dat gedeeltelijk wordt gedekt door een ander object?
- Hoe moeten labelers een object verwerken dat geen duidelijke grens heeft?
- Hoe moeten labelers een object verwerken dat niet de objectklasse van belang is, maar visuele overeenkomsten heeft met een relevant objecttype?
Notitie
Labelers kunnen de eerste negen labels selecteren met nummertoetsen 1 tot en met 9. U kunt deze informatie in uw instructies opnemen.
Kwaliteitscontrole (preview)
Als u nauwkeurigere labels wilt krijgen, gebruikt u de pagina Kwaliteitscontrole om elk item naar meerdere labelaars te verzenden.
Belangrijk
Consensuslabeling is momenteel beschikbaar als openbare preview.
De preview-versie wordt aangeboden zonder Service Level Agreement en wordt niet aanbevolen voor productieworkloads. Misschien worden bepaalde functies niet ondersteund of zijn de mogelijkheden ervan beperkt.
Zie Aanvullende gebruiksvoorwaarden voor Microsoft Azure-previews voor meer informatie.
Als u elk item naar meerdere labelaars wilt laten verzenden, selecteert u Consensuslabeling inschakelen (preview). Stel vervolgens waarden in voor Minimumlabels en Maximumlabels om op te geven hoeveel labelers moeten worden gebruikt. Zorg ervoor dat u zoveel labelers beschikbaar hebt als uw maximumaantal. U kunt deze instellingen niet wijzigen nadat het project is gestart.
Als een consensus wordt bereikt vanaf het minimum aantal labelaars, wordt het item gelabeld. Als er geen consensus wordt bereikt, wordt het item naar meer labelaars verzonden. Als er geen consensus is nadat het item naar het maximum aantal labelers is gegaan, is de status Controle vereist en is de projecteigenaar verantwoordelijk voor het labelen van het item.
Notitie
Segmentatieprojecten voor exemplaren kunnen geen consensuslabels gebruiken.
Met ML ondersteund labelen van gegevens gebruiken
Als u labeltaken wilt versnellen, kunt u op de pagina met ondersteunde ML-labels automatische machine learning-modellen activeren. Medische afbeeldingen (bestanden met een .dcm extensie) worden niet opgenomen in geassisteerde labels. Als het projecttype Semantische segmentatie (preview) is, is labelen met ML niet beschikbaar.
Aan het begin van het labelproject worden de items in een willekeurige volgorde geplaatst om potentiële vooroordelen te verminderen. Het getrainde model weerspiegelt echter eventuele vooroordelen die aanwezig zijn in de gegevensset. Als bijvoorbeeld 80 procent van uw items van één klasse is, komt ongeveer 80 procent van de gegevens die worden gebruikt voor het trainen van het model in die klasse terecht.
Als u geassisteerde labels wilt inschakelen, selecteert u Met ML ondersteund labelen inschakelen en geeft u een GPU op. Als u geen GPU in uw werkruimte hebt, wordt er een GPU-cluster (resourcenaam: DefLabelNC6v3, vmsize: Standard_NC6s_v3) voor u gemaakt en toegevoegd aan uw werkruimte. Het cluster wordt gemaakt met een minimum van nul knooppunten, wat betekent dat het niets kost wanneer het niet in gebruik is.
Door ML ondersteund labelen bestaat uit twee fasen:
- Clustering
- Prelabelen
Het aantal gelabelde gegevensitems dat nodig is om geassisteerde labels te starten, is geen vast nummer. Dit aantal kan aanzienlijk verschillen van het ene labelproject naar het andere. Voor sommige projecten is het soms mogelijk om prelabel- of clustertaken te zien nadat 300 items handmatig zijn gelabeld. Door ML ondersteund labelen maakt gebruik van een techniek die transfer learning wordt genoemd. Transfer learning maakt gebruik van een vooraf getraind model om het trainingsproces te starten. Als de klassen van uw gegevensset lijken op de klassen in het vooraf getrainde model, kunnen prelabels beschikbaar komen na slechts enkele honderd handmatig gelabelde items. Als uw gegevensset aanzienlijk verschilt van de gegevens die worden gebruikt om het model vooraf te trainen, kan het proces langer duren.
Wanneer u consensuslabels gebruikt, wordt het consensuslabel gebruikt voor training.
Omdat de uiteindelijke labels nog steeds afhankelijk zijn van invoer van de labeler, wordt deze technologie ook wel human-in-the-loop labeling genoemd.
Notitie
Door ML ondersteunde gegevenslabels bieden geen ondersteuning voor standaardopslagaccounts die zijn beveiligd achter een virtueel netwerk. U moet een niet-standaardopslagaccount gebruiken voor door ML ondersteunde gegevenslabels. Het niet-standaard opslagaccount kan worden beveiligd achter het virtuele netwerk.
Clustering
Nadat u enkele labels hebt verzonden, begint het classificatiemodel vergelijkbare items te groeperen. Deze vergelijkbare afbeeldingen worden weergegeven aan labelers op dezelfde pagina om handmatige tagging efficiënter te maken. Clustering is vooral handig wanneer een labeler een raster van vier, zes of negen afbeeldingen bekijkt.
Nadat een machine learning-model is getraind op uw handmatig gelabelde gegevens, wordt het model afgekapt tot de laatste volledig verbonden laag. Niet-gelabelde afbeeldingen worden vervolgens doorgegeven via het afgekapte model in een proces dat insluiten of featurization wordt genoemd. Met dit proces wordt elke afbeelding ingesloten in een hoogdimensionale ruimte die door de modellaag wordt gedefinieerd. Andere installatiekopieën in de ruimte die zich het dichtst bij de installatiekopieën bevinden, worden gebruikt voor clustertaken.
De clusterfase wordt niet weergegeven voor objectdetectiemodellen of tekstclassificatie.
Prelabelen
Nadat u voldoende labels voor training hebt ingediend, voorspelt een classificatiemodel tags of voorspelt een objectdetectiemodel begrenzingsvakken. De labeler ziet nu pagina's die voorspelde labels bevatten die al aanwezig zijn op elk item. Voor objectdetectie worden ook voorspelde vakken weergegeven. De taak omvat het controleren van deze voorspellingen en het corrigeren van eventuele onjuist gelabelde afbeeldingen voordat pagina's worden verzonden.
Nadat een machine learning-model is getraind op uw handmatig gelabelde gegevens, wordt het model geëvalueerd op een testset met handmatig gelabelde items. De evaluatie helpt bij het bepalen van de nauwkeurigheid van het model bij verschillende betrouwbaarheidsdrempels. In het evaluatieproces wordt een betrouwbaarheidsdrempel ingesteld waarboven het model nauwkeurig genoeg is om prelabels weer te geven. Het model wordt vervolgens geëvalueerd op basis van niet-gelabelde gegevens. Items met voorspellingen die betrouwbaarder zijn dan de drempelwaarde, worden gebruikt voor prelabeling.
Het afbeeldingslabelproject initialiseren
Nadat het labelproject is geïnitialiseerd, kunnen sommige aspecten van het project niet meer worden gewijzigd. U kunt het taaktype of de gegevensset niet wijzigen. U kunt labels en de URL voor de taakbeschrijving wel wijzigen. Controleer zorgvuldig de instellingen voordat u het project maakt. Nadat u het project hebt ingediend, keert u terug naar de overzichtspagina gegevenslabels , waarin het project wordt weergegeven als Initialiseren.
Notitie
De overzichtspagina wordt mogelijk niet automatisch vernieuwd. Vernieuw de pagina na een pauze handmatig om de status van het project te zien als Gemaakt.
Probleemoplossing
Zie Problemen met het maken van een project of het openen van gegevens oplossen problemen met labelen van gegevens.