Problemen met machine learning-pijplijnen oplossen
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In dit artikel leert u hoe u problemen kunt oplossen wanneer u fouten krijgt bij het uitvoeren van een machine learning-pijplijn in de Azure Machine Learning SDK en Azure Machine Learning Designer.
Tips voor probleemoplossing
De volgende tabel bevat veelvoorkomende problemen tijdens het ontwikkelen van pijplijnen, met mogelijke oplossingen.
| Probleem | Mogelijke oplossing |
|---|---|
Kan geen gegevens doorgeven aan de map PipelineData |
Zorg ervoor dat u een map hebt gemaakt in het script dat overeenkomt met de locatie van de gegevens van de stapuitvoer. In de meeste gevallen definieert een invoerargument de uitvoermap en maakt u de map expliciet. Gebruik os.makedirs(args.output_dir, exist_ok=True) om de uitvoermap te maken. Raadpleeg de zelfstudie voor een voorbeeldscorescript waarin dit ontwerppatroon wordt weergegeven. |
| Afhankelijkheidsfouten | Als u afhankelijkheidsfouten in uw externe pijplijn ziet die niet zijn opgetreden tijdens het lokaal testen, controleert u of de afhankelijkheden en versies van uw externe omgeving overeenkomen met die in uw testomgeving. (Zie Omgeving bouwen, opslaan in cache en hergebruik |
| Ambigue fouten met rekendoelen | Probeer rekendoelen te verwijderen en opnieuw te maken. Het opnieuw maken van rekendoelen gaat snel en kan een aantal tijdelijke problemen oplossen. |
| Pijplijn hergebruikt stappen niet | Het opnieuw gebruiken van stappen is standaard ingeschakeld, maar zorg ervoor dat u het niet hebt uitgeschakeld in een pijplijnstap. Als hergebruik is uitgeschakeld, wordt de allow_reuse parameter in de stap ingesteld op False. |
| Pijplijn wordt onnodig hergebruikt | Om ervoor te zorgen dat stappen alleen opnieuw worden uitgevoerd wanneer de onderliggende gegevens of scripts worden gewijzigd, moet u de broncodemappen voor elke stap loskoppelen. Als u dezelfde bronmap voor meerdere stappen gebruikt, kan het zijn dat er onnodig opnieuw wordt uitgevoerd. Gebruik de source_directory parameter voor een pijplijnstapobject om te verwijzen naar uw geïsoleerde map voor die stap en zorg ervoor dat u niet hetzelfde source_directory pad gebruikt voor meerdere stappen. |
| Stap vertraagt tijdens trainingstijdvakken of ander lusgedrag | Probeer schrijf- en logboekregistratie om te schakelen van as_mount() naar as_upload(). De modus mount maakt gebruik van een extern gevirtualiseerd bestandssysteem en uploadt het hele bestand telkens als er iets aan wordt toegevoegd. |
| Het duurt lang voordat het rekendoel wordt gestart | Docker-afbeeldingen voor rekendoelen worden geladen vanuit Azure Container Registry (ACR). Azure Machine Learning maakt standaard een ACR die gebruikmaakt van de basic-servicelaag . Het wijzigen van de ACR voor uw werkruimte in de Standaard- of Premium-laag kan de tijd verminderen die nodig is om afbeeldingen te bouwen en te laden. Zie Azure Container Registry-servicelagen voor meer informatie. |
Verificatiefouten
Als u een beheerbewerking uitvoert op een rekendoel van een externe taak, ontvangt u een van de volgende fouten:
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
U ontvangt bijvoorbeeld een foutmelding als u probeert een rekendoel te maken of te koppelen vanuit een ML-pijplijn die wordt verzonden voor externe uitvoering.
Probleemoplossing ParallelRunStep
Het script voor een ParallelRunStep moet twee functies bevatten :
init(): Gebruik deze functie voor kostbare of algemene voorbereiding voor latere deductie. Gebruik het bijvoorbeeld om het model in een algemeen object te laden. Deze functie wordt slechts één keer aan het begin van het proces aangeroepen.run(mini_batch): De functie wordt uitgevoerd voor elkmini_batchexemplaar.mini_batch:ParallelRunSteproept de run-methode aan en geeft een lijst of pandasDataFramedoor als argument aan de methode. Elke vermelding in mini_batch is een bestandspad als invoer eenFileDatasetof een pandasDataFrameis als invoer eenTabularDataset.response: run()-methode moet resulteren in een pandas-DataFrameof een matrix. Voor append_row output_action worden deze geretourneerde elementen toegevoegd aan het algemene uitvoerbestand. Voor summary_only wordt de inhoud van de elementen genegeerd. Voor alle uitvoeracties geeft elk geretourneerde uitvoerelement een geslaagde uitvoering van een invoerelement in de mini-batch aan. Zorg dat er voldoende gegevens worden opgenomen in het resultaat van de uitvoering om invoer toe te wijzen aan de uitvoerresultaten. Uitvoer wordt geschreven in het uitvoerbestand en is niet gegarandeerd in volgorde. Gebruik een sleutel in de uitvoer om deze toe te wijzen aan invoer.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
Als u een ander bestand of een andere map hebt in dezelfde map als uw deductiescript, dan kunt u ernaar verwijzen door de huidige werkmap te zoeken.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
Parameters voor ParallelRunConfig
ParallelRunConfig is de voornaamste configuratie voor ParallelRunStep-exemplaar in de Azure Machine Learning-pijplijn. U gebruikt dit om uw script te verpakken en de nodige parameters te configureren, waaronder alle volgende vermeldingen:
entry_script: Een gebruikersscript als een lokaal bestandspad dat parallel wordt uitgevoerd op meerdere knooppunten. Alssource_directoryaanwezig is, gebruikt dan een relatief pad. Zoniet, gebruik dan een pad dat toegankelijk is op de machine.mini_batch_size: De grootte van de minibatch die aan éénrun()aanroep is doorgegeven. (optioneel; de standaardwaarde is10bestanden voorFileDataseten1MBvoorTabularDataset.)- Voor
FileDatasetis dit het aantal bestanden met een minimumwaarde1. U kunt meerdere bestanden combineren in één mini-batch. - Voor
TabularDatasetis dit de grootte van de gegevens. Voorbeeldwaarden zijn1024,1024KB,10MBen1GB. De aanbevolen waarde is1MB. De mini-batch vanTabularDatasetzal nooit bestandsgrenzen overschrijden. Als u bijvoorbeeld een .csv-bestand heeft met verschillende groottes, dan is het kleinste bestan 100 KB en het grootste 10 MB. Als u insteltmini_batch_size = 1MB, worden bestanden met een grootte kleiner dan 1 MB behandeld als één minibatch. Bestanden met een grootte groter dan 1 MB worden gesplitst in meerdere minibatches.
- Voor
error_threshold: Het aantal recordfouten voorTabularDataseten bestandsfoutenFileDatasethiervoor moet tijdens de verwerking worden genegeerd. Als het aantal fouten voor de volledige invoer boven deze waarde gaat, wordt de taak afgebroken. De drempelwaarde voor fouten geldt voor de volledige invoer, niet voor afzonderlijke mini-batches die naar derun()-methode verzonden worden. Het bereik is[-1, int.max]. Het deel-1geeft aan dat alle fouten tijdens de verwerking genegeerd worden.output_action: Een van de volgende waarden geeft aan hoe de uitvoer is ingedeeld:summary_only: Het gebruikersscript slaat de uitvoer op.ParallelRunStepgebruikt de uitvoer alleen voor de berekening van de foutdrempelwaarde.append_row: Voor alle invoer wordt slechts één bestand gemaakt in de uitvoermap om alle uitvoer toe te voegen, gescheiden door regel.
append_row_file_name: Als u de naam van het uitvoerbestand voor append_row output_action wilt aanpassen (optioneel; standaardwaarde isparallel_run_step.txt).source_directory: Paden naar mappen die alle bestanden bevatten die moeten worden uitgevoerd op het rekendoel (optioneel).compute_target: AlleenAmlComputewordt ondersteund.node_count: het aantal rekenknooppunten dat moet worden gebruikt voor het uitvoeren van het gebruikersscript.process_count_per_node: Het aantal processen per knooppunt. Het is aanbevolen om het aantal GPU of CPU voor één knooppunt in te stellen (optioneel; standaardwaarde is1).environment: de Python-omgevingsdefinitie. U kunt deze configureren om een bestaande Python-omgeving te gebruiken of om een tijdelijke omgeving in te stellen. De definitie zorgt er ook voor dat de vereiste toepassingsafhankelijkheden worden ingesteld (optioneel).logging_level: Uitgebreidheid van logboeken. De waarden om uitgebreidheid te verhogen zijn:WARNING,INFOenDEBUG. (optioneel; de standaardwaarde isINFO)run_invocation_timeout: Derun()time-out voor aanroepen van de methode in seconden. (optioneel; standaardwaarde is60)run_max_try: Maximum aantal pogingen voorrun()een minibatch. Eenrun()is mislukt als er een uitzondering wordt gegenereerd of er niets wordt geretourneerd wanneerrun_invocation_timeoutis bereikt (optioneel; de standaardwaarde is3).
U kunt mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout en run_max_try als PipelineParameter opgeven, zodat u de parameterwaarden kunt aanpassen wanneer u een pijplijnuitvoering opnieuw verzendt. In dit voorbeeld gebruikt PipelineParameter u deze mini_batch_size waarden en Process_count_per_node wijzigt u deze waarden wanneer u een uitvoering later opnieuw indient.
Parameters voor het maken van de ParallelRunStep
Maak de ParallelRunStep met het script, de omgevingsconfiguratie en de parameters. Geef het rekendoel op dat u al aan uw werkruimte hebt gekoppeld als het doel van de uitvoering voor uw deductiescript. Gebruik ParallelRunStep om de stap voor de batchdeductiepijplijn te maken, met de volgende parameters:
name: De naam van de stap, met de volgende naamgevingsbeperkingen: uniek, 3-32 tekens en regex ^[a-z]([-a-z0-9]*[a-z0-9])?$.parallel_run_config: EenParallelRunConfigobject, zoals eerder gedefinieerd.inputs: Een of meer Azure Machine Learning-gegevenssets met één type die moeten worden gepartitioneerd voor parallelle verwerking.side_inputs: een of meer referentiegegevens of gegevenssets die worden gebruikt als invoer aan de zijkant zonder dat ze hoeven te worden gepartitioneerd.output: EenOutputFileDatasetConfigobject dat overeenkomt met de uitvoermap.arguments: Een lijst met argumenten die zijn doorgegeven aan het gebruikersscript. Gebruik unknown_args om deze op te halen in uw invoerscript (optioneel).allow_reuse: Of de stap eerdere resultaten opnieuw moet gebruiken wanneer deze wordt uitgevoerd met dezelfde instellingen/invoer. Als deze parameter isFalse, wordt er een nieuwe uitvoering gegenereerd voor deze stap tijdens het uitvoeren van de pijplijn. (optioneel; de standaardwaarde isTrue.)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
Foutopsporingstechnieken
Er zijn drie belangrijke technieken voor het opsporen van fouten in pijplijnen:
- Fouten opsporen in afzonderlijke pijplijnstappen op de lokale computer
- Logboekregistratie en Application Insights gebruiken om de oorzaak van het probleem te isoleren en vast te stellen
- Een extern foutopsporingsprogramma koppelen aan een pijplijn die wordt uitgevoerd in Azure
Lokaal fouten opsporen in scripts
Een van de meest voorkomende fouten in een pijplijn is dat het domeinscript niet als bedoeld wordt uitgevoerd of runtimefouten bevat in de externe rekencontext die moeilijk te opsporen zijn.
Pijplijnen zelf kunnen niet lokaal worden uitgevoerd. Maar door de scripts in isolatie op uw lokale computer uit te voeren, kunt u sneller fouten opsporen omdat u niet hoeft te wachten op het proces voor het bouwen van berekeningen en omgevingen. Hiervoor is een aantal ontwikkelwerkzaamheden vereist:
- Als uw gegevens zich in een gegevensarchief in de cloud bevinden, moet u gegevens downloaden en beschikbaar maken voor uw script. Het gebruik van een klein voorbeeld van uw gegevens is een goede manier om runtime te verminderen en snel feedback te krijgen over scriptgedrag
- Als u een tussenliggende pijplijnstap probeert te simuleren, moet u mogelijk handmatig de objecttypen maken die het specifieke script verwacht in de vorige stap
- U moet uw eigen omgeving definiëren en de afhankelijkheden repliceren die zijn gedefinieerd in uw externe rekenomgeving
Zodra u een script hebt ingesteld dat moet worden uitgevoerd in uw lokale omgeving, is het eenvoudiger om foutopsporingstaken uit te voeren, zoals:
- Een aangepaste foutopsporingsconfiguratie koppelen
- Uitvoering onderbreken en objectstatus controleren
- Type- of logische fouten ondervangen die pas tijdens runtime worden weergegeven
Tip
Zodra u kunt controleren of uw script wordt uitgevoerd zoals verwacht, wordt het script in een pijplijn met één stap uitgevoerd voordat u het met meerdere stappen probeert uit te voeren in een pijplijn.
Pijplijnlogboeken configureren, schrijven en controleren
Het lokaal testen van scripts is een uitstekende manier om fouten op te sporen in belangrijke codefragmenten en complexe logica voordat u begint met het bouwen van een pijplijn. Op een bepaald moment moet u fouten opsporen in scripts tijdens de werkelijke pijplijnuitvoering zelf, met name bij het diagnosticeren van gedrag dat optreedt tijdens de interactie tussen pijplijnstappen. U wordt aangeraden vrij gebruik te maken van print() instructies in uw stapscripts, zodat u de objectstatus en verwachte waarden kunt zien tijdens het uitvoeren op afstand, vergelijkbaar met de manier waarop u fouten in JavaScript-code zou opsporen.
Opties en gedrag voor logboekregistratie
De volgende tabel bevat informatie over verschillende foutopsporingsopties voor pijplijnen. Het is geen volledige lijst, omdat er andere opties bestaan, naast de Azure Machine Learning-, Python- en OpenCensus-opties die hier worden weergegeven.
| Bibliotheek | Type | Voorbeeld | Doel | Resources |
|---|---|---|---|---|
| Azure Machine Learning-SDK | Metrisch | run.log(name, val) |
Azure Machine Learning Portal-gebruikersinterface | Experimenten bijhouden Klasse azureml.core.Run |
| Afdrukken/logboekregistratie met Python | Logboek | print(val)logging.info(message) |
Stuurprogrammalogboeken, Azure Machine Learning-ontwerpfunctie | Experimenten bijhouden Python-logboekregistratie |
| OpenCensus Python | Logboek | logger.addHandler(AzureLogHandler())logging.log(message) |
Application Insights - traceringen | Fouten met pijplijnen opsporen in Application Insights OpenCensus Azure Monitor Exporters Python-handleiding voor logboekregistratie |
Voorbeeld van opties voor logboekregistratie
import logging
from azureml.core.run import Run
from opencensus.ext.azure.log_exporter import AzureLogHandler
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
# Python logging with OpenCensus AzureLogHandler
logger.warning("I am an OpenCensus warning statement, find me in Application Insights!")
logger.error("I am an OpenCensus error statement with custom dimensions", {'step_id': run.id})
Azure Machine Learning-ontwerpprogramma
Voor pijplijnen die zijn gemaakt in de ontwerpfunctie, vindt u het 70_driver_log bestand op de ontwerppagina of op de detailpagina van de pijplijnuitvoering.
Logboekregistratie inschakelen voor realtime-eindpunten
Als u problemen met realtime-eindpunten in de ontwerpfunctie wilt oplossen en fouten wilt opsporen, moet u Application Insight-logboekregistratie inschakelen met behulp van de SDK. Met logboekregistratie kunt u problemen met de implementatie en het gebruik van modellen oplossen en fouten opsporen. Zie Logboekregistratie voor geïmplementeerde modellen voor meer informatie.
Logboeken ophalen van de ontwerppagina
Wanneer u een pijplijnuitvoering verzendt en op de ontwerppagina blijft staan, kunt u de logboekbestanden vinden die voor elk onderdeel worden gegenereerd wanneer elk onderdeel wordt uitgevoerd.
Selecteer een onderdeel dat is uitgevoerd op het ontwerpcanvas.
Ga in het rechterdeelvenster van het onderdeel naar het tabblad Uitvoer en logboeken .
Vouw het rechterdeelvenster uit en selecteer de 70_driver_log.txt om het bestand in de browser weer te geven. U kunt logboeken ook lokaal downloaden.
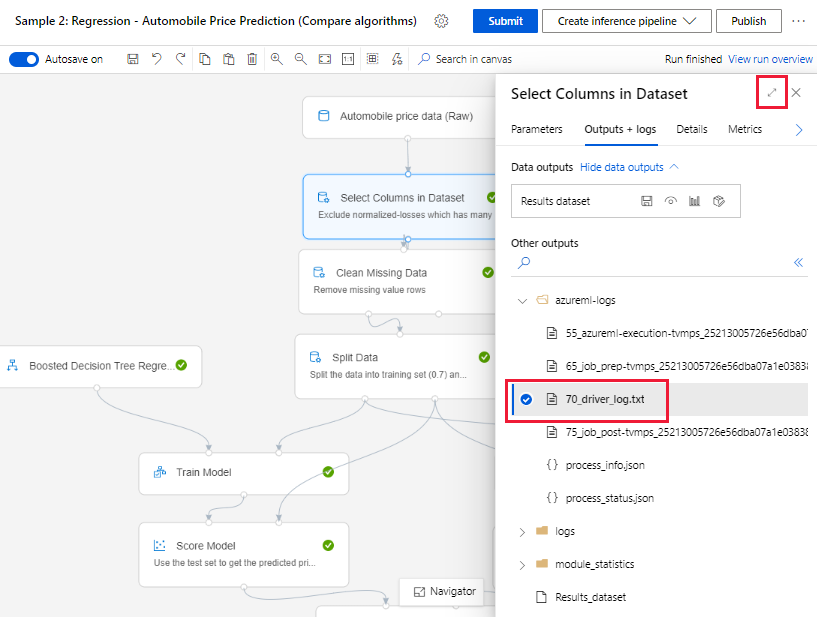
Logboeken ophalen uit pijplijnuitvoeringen
U kunt ook de logboekbestanden voor specifieke uitvoeringen vinden op de detailpagina van de pijplijnuitvoering, die u kunt vinden in de sectie Pijplijnen of Experimenten van de studio.
Selecteer een pijplijnuitvoering die is gemaakt in de ontwerpfunctie.
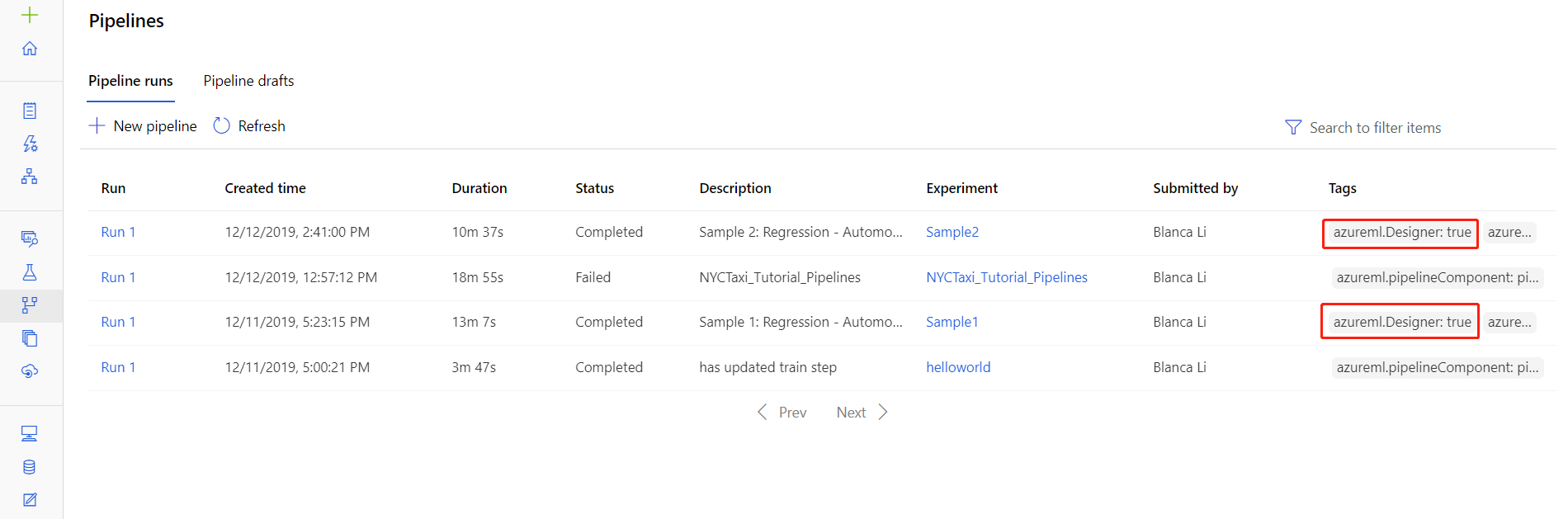
Selecteer een onderdeel in het voorbeeldvenster.
Ga in het rechterdeelvenster van het onderdeel naar het tabblad Uitvoer en logboeken .
Vouw het rechterdeelvenster uit om het std_log.txt bestand in de browser weer te geven of selecteer het bestand om de logboeken lokaal te downloaden.
Belangrijk
Als u een pijplijn wilt bijwerken vanaf de pagina met details van de pijplijnuitvoering, moet u de pijplijnuitvoering klonen naar een nieuw pijplijnconcept. Een pijplijnuitvoering is een momentopname van de pijplijn. Het is vergelijkbaar met een logboekbestand en kan niet worden gewijzigd.
Analyses van toepassingen
Zie deze handleiding voor meer informatie over het gebruik van de OpenCensus Python-bibliotheek: Fouten opsporen en problemen met machine learning-pijplijnen oplossen in Application Insights
Interactieve foutopsporing met Visual Studio Code
In sommige gevallen moet u mogelijk interactief fouten opsporen in de Python-code die wordt gebruikt in uw ML-pijplijn. Door Visual Studio Code (VS Code) en debugpy te gebruiken, kunt u koppelen aan de code terwijl deze wordt uitgevoerd in de trainingsomgeving. Ga naar de interactieve foutopsporing in de Visual Studio Code-handleiding voor meer informatie.
HyperdriveStep en AutoMLStep mislukken met netwerkisolatie
Nadat u HyperdriveStep en AutoMLStep hebt gebruikt, krijgt u mogelijk een foutmelding wanneer u het model probeert te registreren.
U gebruikt Azure Machine Learning SDK v1.
Uw Azure Machine Learning-werkruimte is geconfigureerd voor netwerkisolatie (VNet).
Uw pijplijn probeert het model te registreren dat door de vorige stap is gegenereerd. In het volgende voorbeeld is de
inputsparameter bijvoorbeeld de saved_model van een HyperdriveStep:register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
Tijdelijke oplossing
Belangrijk
Dit gedrag treedt niet op wanneer u Azure Machine Learning SDK v2 gebruikt.
Als u deze fout wilt omzeilen, gebruikt u de klasse Uitvoeren om het model op te halen dat is gemaakt op basis van HyperdriveStep of AutoMLStep. Hier volgt een voorbeeldscript waarmee het uitvoermodel wordt opgehaald uit een HyperdriveStep:
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
Het bestand kan vervolgens worden gebruikt vanuit een PythonScriptStep:
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
Volgende stappen
Zie Zelfstudie: Een Azure Machine Learning-pijplijn bouwen voor batchgewijs scoren voor een volledige zelfstudie met behulp
ParallelRunStepvan.Zie Geautomatiseerde ML gebruiken in een Azure Machine Learning-pijplijn in Python voor een volledig voorbeeld van geautomatiseerde machine learning in ML-pijplijnen.
Raadpleeg de SDK-referentie voor hulp bij het pakket azureml-pipelines-core en het pakket azureml-pipelines-steps .
Zie de lijst met uitzonderingen en foutcodes van de ontwerper.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor