Wat is Designer (v1) in Azure Machine Learning?
De Azure Machine Learning-ontwerpfunctie is een interface voor slepen en neerzetten die wordt gebruikt voor het trainen en implementeren van modellen in Azure Machine Learning-studio. In dit artikel worden de taken beschreven die u in de ontwerpfunctie kunt uitvoeren.
Belangrijk
Designer in Azure Machine Learning ondersteunt twee typen pijplijnen die gebruikmaken van klassieke vooraf gedefinieerde (v1) of aangepaste (v2) onderdelen. De twee onderdeeltypen zijn niet compatibel in pijplijnen en designer v1 is niet compatibel met CLI v2 en SDK v2. Dit artikel is van toepassing op pijplijnen die gebruikmaken van klassieke vooraf gedefinieerde onderdelen (v1).
Klassieke vooraf gebouwde onderdelen (v1) bevatten typische gegevensverwerkings- en machine learning-taken, zoals regressie en classificatie. Azure Machine Learning blijft ondersteuning bieden voor de bestaande vooraf gemaakte klassieke onderdelen, maar er worden geen nieuwe vooraf gemaakte onderdelen toegevoegd. Daarnaast biedt de implementatie van klassieke vooraf samengestelde onderdelen (v1) geen ondersteuning voor beheerde online-eindpunten (v2).
Met aangepaste onderdelen (v2) kunt u uw eigen code verpakken als onderdelen, waardoor u het delen tussen werkruimten en naadloze creatie in Azure Machine Learning-studio, CLI v2 en SDK v2-interfaces mogelijk maakt. Het is raadzaam om aangepaste onderdelen te gebruiken voor nieuwe projecten, omdat ze compatibel zijn met Azure Machine Learning v2 en nieuwe updates blijven ontvangen. Zie Azure Machine Learning Designer (v2) voor meer informatie over aangepaste onderdelen en Designer (v2).
In de volgende GIF-animatie ziet u hoe u een pijplijn visueel kunt bouwen in Designer door assets te slepen en neer te zetten en deze te verbinden.

Zie de naslaginformatie over algoritme en onderdelen voor meer informatie over de onderdelen die beschikbaar zijn in de ontwerpfunctie. Zie Zelfstudie: Een regressiemodel zonder code trainen om aan de slag te gaan met de ontwerpfunctie.
Modeltraining en -implementatie
De ontwerpfunctie gebruikt uw Azure Machine Learning-werkruimte om gedeelde resources te organiseren, zoals:
- Pijplijnen
- Data
- Rekenresources
- Geregistreerde modellen
- Gepubliceerde pijplijntaken
- Realtime-eindpunten
In het volgende diagram ziet u hoe u de ontwerpfunctie kunt gebruiken om een end-to-end machine learning-werkstroom te bouwen. U kunt modellen trainen, testen en implementeren, allemaal in de ontwerpinterface.
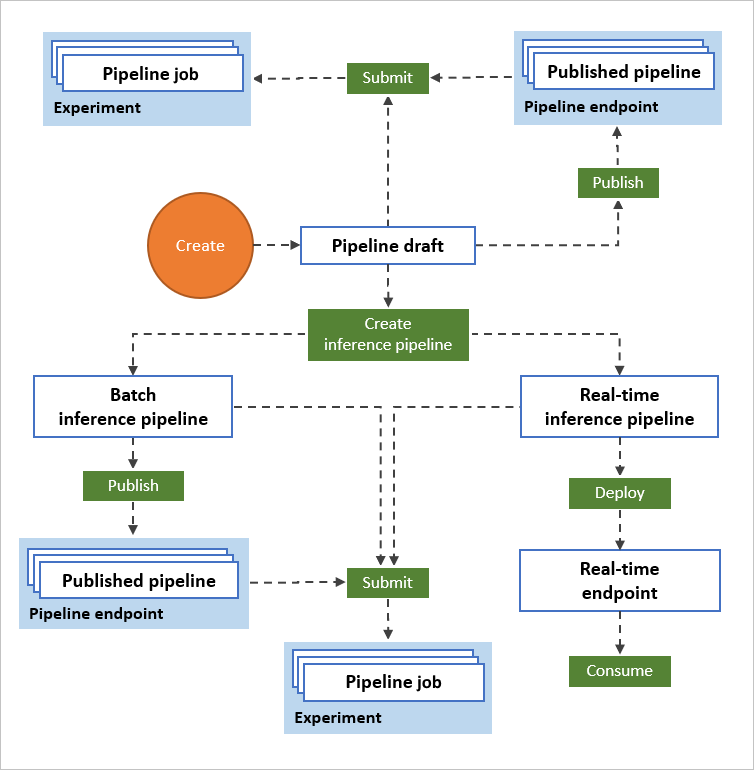
- Sleep gegevensassets en onderdelen naar het visuele canvas van de ontwerpfunctie en verbind de onderdelen om een pijplijnconcept te maken.
- Verzend een pijplijntaak die gebruikmaakt van de rekenresources in uw Azure Machine Learning-werkruimte.
- Converteer uw trainingspijplijnen naar deductiepijplijnen.
- Publiceer uw pijplijnen naar een REST-pijplijneindpunt om nieuwe pijplijnen te verzenden die worden uitgevoerd met verschillende parameters en gegevensassets.
- Publiceer een trainingspijplijn om één pijplijn opnieuw te gebruiken om meerdere modellen te trainen terwijl u parameters en gegevensassets wijzigt.
- Publiceer een pijplijn voor batchdeductie om voorspellingen te doen over nieuwe gegevens met behulp van een eerder getraind model.
- Implementeer een realtime deductiepijplijn naar een online-eindpunt om in realtime voorspellingen te doen over nieuwe gegevens.
Gegevens
Met een machine learning-gegevensasset kunt u eenvoudig uw gegevens openen en ermee werken. De ontwerpfunctie bevat verschillende voorbeeldgegevensassets waarmee u kunt experimenteren. U kunt meer gegevensassets registreren wanneer u ze nodig hebt.
Onderdelen
Een onderdeel is een algoritme dat u op uw gegevens kunt uitvoeren. De ontwerpfunctie bevat verschillende onderdelen, variërend van functies voor inkomend gegevensverkeer tot trainings-, score- en validatieprocessen.
Een onderdeel kan parameters bevatten die u gebruikt om de interne algoritmen van het onderdeel te configureren. Wanneer u een onderdeel op het canvas selecteert, worden de parameters en andere instellingen van het onderdeel weergegeven in een eigenschappenvenster aan de rechterkant van het canvas. U kunt de parameters wijzigen en de rekenresources voor afzonderlijke onderdelen in dat deelvenster instellen.
Zie de naslaginformatie over algoritmes en onderdelen voor meer informatie over de bibliotheek met beschikbare machine learning-algoritmen. Zie het cheatsheet van het Azure Machine Learning-algoritme voor hulp bij het kiezen van een algoritme.
Pipelines
Een pijplijn bestaat uit gegevensassets en analytische onderdelen die u verbindt. Met pijplijnen kunt u uw werk opnieuw gebruiken en uw projecten organiseren.
Pijplijnen hebben veel gebruik. U kunt pijplijnen maken die:
- Een enkel model trainen.
- Meerdere modellen trainen.
- Voorspellingen doen in realtime of in batch.
- Alleen gegevens opschonen.
Pijplijnconcepten
Wanneer u een pijplijn in de ontwerpfunctie bewerkt, wordt uw voortgang opgeslagen als een pijplijnconcept. U kunt op elk gewenst moment een pijplijnconcept bewerken door onderdelen toe te voegen of te verwijderen, rekendoelen te configureren of parameters in te stellen.
Een geldige pijplijn heeft de volgende kenmerken:
- Gegevensassets kunnen alleen verbinding maken met onderdelen.
- Onderdelen kunnen alleen verbinding maken met gegevensassets of andere onderdelen.
- Alle invoerpoorten voor onderdelen moeten een verbinding met de gegevensstroom hebben.
- Alle vereiste parameters voor elk onderdeel moeten worden ingesteld.
Wanneer u klaar bent om uw pijplijnconcept uit te voeren, slaat u de pijplijn op en verzendt u een pijplijntaak.
Pijplijntaken
Telkens wanneer u een pijplijn uitvoert, worden de configuratie van de pijplijn en de resultaten ervan als pijplijntaak opgeslagen in uw werkruimte. Pijplijntaken worden gegroepeerd in experimenten om de taakgeschiedenis te organiseren.
U kunt teruggaan naar elke pijplijntaak om deze te inspecteren voor probleemoplossing of controle. Kloon een pijplijntaak om een nieuw pijplijnconcept te maken dat u wilt bewerken.
Rekenresources
Rekendoelen worden gekoppeld aan uw Azure Machine Learning-werkruimte in Azure Machine Learning-studio. Gebruik rekenresources uit uw werkruimte om uw pijplijn uit te voeren en uw geïmplementeerde modellen als online-eindpunten of als pijplijneindpunten te hosten voor batchdeductie. De ondersteunde rekendoelen zijn als volgt:
| Rekendoel | Training | Implementatie |
|---|---|---|
| Azure Machine Learning-rekenproces | ✓ | |
| Azure Kubernetes Service (AKS) | ✓ |
Implementeren
Als u realtime deductie wilt uitvoeren, moet u een pijplijn implementeren als een online-eindpunt. Het online-eindpunt maakt een interface tussen een externe toepassing en uw scoremodel. Het eindpunt is gebaseerd op REST, een populaire architectuurkeuze voor webprogrammeringsprojecten. Een aanroep naar een online-eindpunt retourneert in realtime voorspellingsresultaten naar de toepassing.
Als u een aanroep naar een online-eindpunt wilt maken, geeft u de API-sleutel door die is gemaakt toen u het eindpunt implementeerde. Online-eindpunten moeten worden geïmplementeerd in een AKS-cluster. Zie Zelfstudie: Een machine learning-model implementeren met de ontwerpfunctie voor meer informatie over het implementeren van uw model.
Publiceren
U kunt ook een pijplijn publiceren naar een pijplijneindpunt. Net als bij een online-eindpunt kunt u met een pijplijneindpunt nieuwe pijplijntaken verzenden vanuit externe toepassingen met behulp van REST-aanroepen. U kunt echter geen gegevens in realtime verzenden of ontvangen met behulp van een pijplijneindpunt.
Gepubliceerde pijplijneindpunten zijn flexibel en kunnen worden gebruikt voor het trainen of opnieuw trainen van modellen, het uitvoeren van batchdeductie of het verwerken van nieuwe gegevens. U kunt meerdere pijplijnen publiceren naar één pijplijneindpunt en opgeven welke pijplijnversie moet worden uitgevoerd.
Een gepubliceerde pijplijn wordt uitgevoerd op de rekenresources die u definieert in het pijplijnconcept voor elk onderdeel. De ontwerpfunctie maakt hetzelfde PublishedPipeline-object als de SDK.
Gerelateerde inhoud
- Leer de grondbeginselen van predictive analytics en machine learning met zelfstudie: Autoprijs voorspellen met de ontwerpfunctie.
- Meer informatie over het wijzigen van bestaande ontwerpvoorbeelden om deze aan uw behoeften aan te passen.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor