Machine Learning-pijplijnen publiceren
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In dit artikel leest u hoe u een machine learning-pijplijn kunt delen met uw collega's of klanten.
Machine learning-pijplijnen zijn herbruikbare werkstromen voor machine learning-taken. Een voordeel van pijplijnen is een betere samenwerking. U kunt ook versiepijplijnen gebruiken, zodat klanten het huidige model kunnen gebruiken terwijl u aan een nieuwe versie werkt.
Vereisten
Een Azure Machine Learning-werkruimte maken om al uw pijplijnbronnen op te slaan
Configureer uw ontwikkelomgeving om de Azure Machine Learning SDK te installeren of gebruik een Azure Machine Learning-rekenproces met de SDK die al is geïnstalleerd
Een machine learning-pijplijn maken en uitvoeren, zoals in de volgende zelfstudie: Een Azure Machine Learning-pijplijn bouwen voor batchgewijs scoren. Zie Machine Learning-pijplijnen maken en uitvoeren met azure Machine Learning SDK voor andere opties
Een pijplijn publiceren
Zodra u een pijplijn hebt die actief is, kunt u een pijplijn publiceren zodat deze wordt uitgevoerd met verschillende invoerwaarden. Voor het REST-eindpunt van een reeds gepubliceerde pijplijn om parameters te accepteren, moet u de pijplijn configureren voor het gebruik PipelineParameter van objecten voor de argumenten die variëren.
Als u een pijplijnparameter wilt maken, gebruikt u een PipelineParameter-object met een standaardwaarde.
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Voeg dit
PipelineParameterobject als parameter toe aan een van de stappen in de pijplijn als volgt:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Publiceer deze pijplijn die een parameter accepteert wanneer deze wordt aangeroepen.
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")Nadat u uw pijplijn hebt gepubliceerd, kunt u deze controleren in de gebruikersinterface. De pijplijn-id is de unieke identificatie van de gepubliceerde pijplijn.


Een gepubliceerde pijplijn uitvoeren
Alle gepubliceerde pijplijnen hebben een REST-eindpunt. Met het pijplijneindpunt kunt u een uitvoering van de pijplijn activeren vanuit externe systemen, inclusief niet-Python-clients. Dit eindpunt maakt beheerde herhaalbaarheid mogelijk in scenario's voor batchgewijs scoren en opnieuw trainen.
Belangrijk
Als u op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) gebruikt om de toegang tot uw pijplijn te beheren, stelt u de machtigingen in voor uw pijplijnscenario (training of score).
Als u de uitvoering van de voorgaande pijplijn wilt aanroepen, hebt u een Header-token voor Microsoft Entra-verificatie nodig. Het ophalen van een dergelijk token wordt beschreven in de naslaginformatie over de AzureCliAuthentication-klasse en in de verificatie in Azure Machine Learning-notebook .
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
Het json argument voor de POST-aanvraag moet, voor de ParameterAssignments sleutel, een woordenlijst met de pijplijnparameters en de bijbehorende waarden bevatten. Daarnaast kan het json argument de volgende sleutels bevatten:
| Toets | Beschrijving |
|---|---|
ExperimentName |
De naam van het experiment dat is gekoppeld aan dit eindpunt |
Description |
Vrije-vormtekst die het eindpunt beschrijft |
Tags |
Vrije-vormsleutel-waardeparen die kunnen worden gebruikt om aanvragen te labelen en aantekeningen te maken |
DataSetDefinitionValueAssignments |
Woordenlijst die wordt gebruikt voor het wijzigen van gegevenssets zonder opnieuw trainen (zie de onderstaande discussie) |
DataPathAssignments |
Woordenlijst die wordt gebruikt voor het wijzigen van gegevenspaden zonder opnieuw trainen (zie de onderstaande discussie) |
Een gepubliceerde pijplijn uitvoeren met C#
De volgende code laat zien hoe u een pijplijn asynchroon aanroept vanuit C#. Het gedeeltelijke codefragment toont alleen de aanroepstructuur en maakt geen deel uit van een Microsoft-voorbeeld. Er worden geen volledige klassen of foutafhandeling weergegeven.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Een gepubliceerde pijplijn uitvoeren met Java
De volgende code toont een aanroep naar een pijplijn waarvoor verificatie is vereist (zie Verificatie instellen voor Azure Machine Learning-resources en -werkstromen). Als uw pijplijn openbaar wordt geïmplementeerd, hebt u de aanroepen die produceren authKeyniet nodig. In het gedeeltelijke codefragment worden geen Standaard voor Java-klasse en uitzonderingsafhandeling weergegeven. De code gebruikt Optional.flatMap voor het koppelen van functies die een lege Optionalfunctie kunnen retourneren. Het gebruik van flatMap verkorten en verduidelijkt de code, maar houd er rekening mee dat getRequestBody() uitzonderingen worden ingeslikt.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token);;
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Gegevenssets en gegevenspaden wijzigen zonder opnieuw te trainen
Mogelijk wilt u verschillende gegevenssets en gegevenspaden trainen en deductie uitvoeren. U wilt bijvoorbeeld trainen op een kleinere gegevensset, maar deductie op de volledige gegevensset. U schakelt tussen gegevenssets met de DataSetDefinitionValueAssignments sleutel in het argument van json de aanvraag. U schakelt over van datapath met DataPathAssignments. De techniek voor beide is vergelijkbaar:
Maak in het script voor de pijplijndefinitie een
PipelineParametervoor de gegevensset. Maak eenDatasetConsumptionConfigofDataPathvan dePipelineParametervolgende:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)Open in uw ML-script de dynamisch opgegeven gegevensset met behulp van
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc ...U ziet dat het ML-script toegang heeft tot de waarde die is opgegeven voor de
DatasetConsumptionConfig(tabular_dataset) en niet de waarde van dePipelineParameter(tabular_ds_param).Stel in het script voor de pijplijndefinitie de
DatasetConsumptionConfigals een parameter in op hetPipelineScriptStepvolgende:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Als u dynamisch wilt schakelen tussen gegevenssets in uw deductie-REST-aanroep, gebruikt u
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
De notebooks showcasing Dataset and PipelineParameter and Showcasing DataPath and PipelineParameter hebben volledige voorbeelden van deze techniek.
Een versie van een pijplijneindpunt maken
U kunt een pijplijneindpunt maken met meerdere gepubliceerde pijplijnen erachter. Met deze techniek krijgt u een vast REST-eindpunt terwijl u uw ML-pijplijnen doorgeeft en bijwerkt.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Een taak verzenden naar een pijplijneindpunt
U kunt een taak verzenden naar de standaardversie van een pijplijneindpunt:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
U kunt ook een taak verzenden naar een specifieke versie:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
Hetzelfde kan worden bereikt met behulp van de REST API:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Gepubliceerde pijplijnen gebruiken in de studio
U kunt ook een gepubliceerde pijplijn uitvoeren vanuit de studio:
Meld u aan bij Azure Machine Learning Studio.
Selecteer aan de linkerkant Eindpunten.
Selecteer bovenaan pijplijneindpunten.
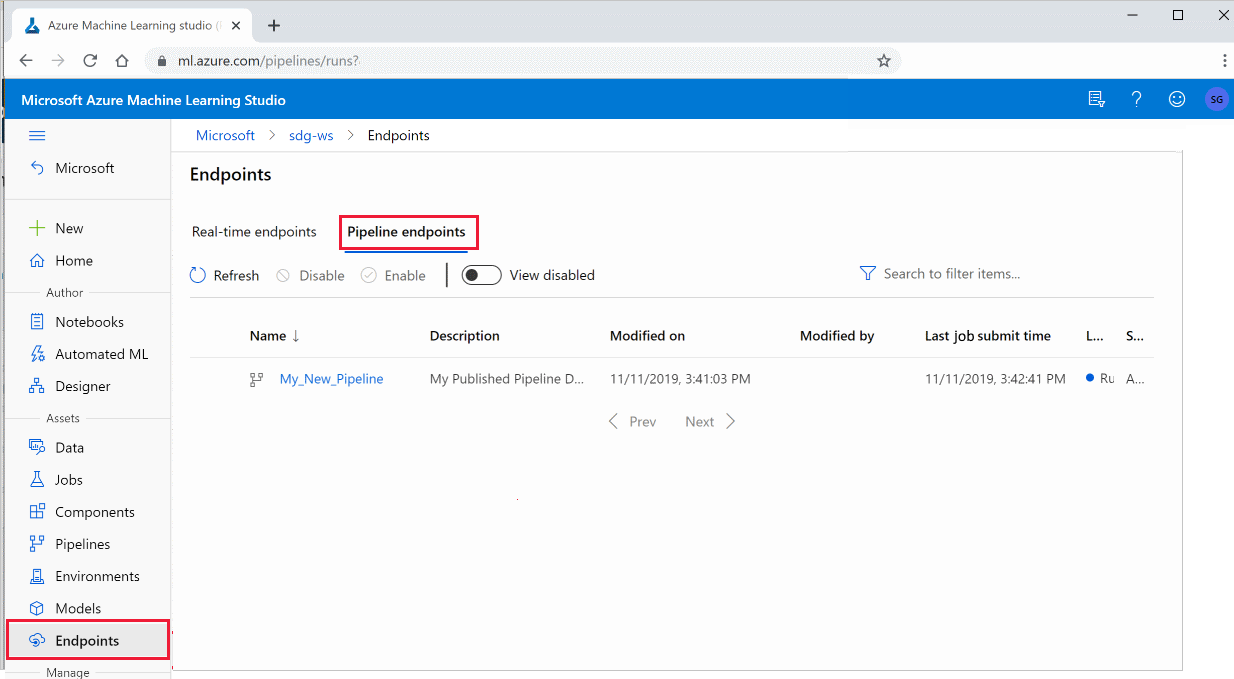
Selecteer een specifieke pijplijn om de resultaten van eerdere uitvoeringen van het pijplijneindpunt uit te voeren, te gebruiken of te bekijken.
Een gepubliceerde pijplijn uitschakelen
Als u een pijplijn wilt verbergen in uw lijst met gepubliceerde pijplijnen, schakelt u deze uit in de studio of in de SDK:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
U kunt het opnieuw inschakelen met p.enable(). Zie De klasseverwijzing PublishedPipeline voor meer informatie.
Volgende stappen
- Gebruik deze Jupyter-notebooks op GitHub om machine learning-pijplijnen verder te verkennen.
- Zie de SDK-referentiehulp voor het pakket azureml-pipelines-core en het pakket azureml-pipelines-steps .
- Zie de instructies voor tips voor het opsporen van fouten en het oplossen van problemen met pijplijnen.