Gegevens verzamelen van modellen in productie
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
In dit artikel wordt beschreven hoe u gegevens verzamelt uit een Azure Machine Learning-model dat is geïmplementeerd in een AKS-cluster (Azure Kubernetes Service). De verzamelde gegevens worden vervolgens opgeslagen in Azure Blob Storage.
Zodra het verzamelen is ingeschakeld, helpen de gegevens die u verzamelt u bij het volgende:
Bewaak gegevensdrift op de productiegegevens die u verzamelt.
Verzamelde gegevens analyseren met Power BI of Azure Databricks
Neem betere beslissingen over het opnieuw trainen of optimaliseren van uw model.
Uw model opnieuw trainen met de verzamelde gegevens.
Beperkingen
- De functie voor het verzamelen van modelgegevens kan alleen werken met de Ubuntu 18.04-installatiekopie.
Belangrijk
Vanaf 10-03-2023 is de Ubuntu 18.04-installatiekopie nu afgeschaft. Ondersteuning voor Ubuntu 18.04-installatiekopieën wordt vanaf januari 2023 verwijderd wanneer het EOL bereikt op 30 april 2023.
De MDC-functie is niet compatibel met een andere installatiekopie dan Ubuntu 18.04, die niet beschikbaar is nadat de Ubuntu 18.04-installatiekopie is afgeschaft.
mMore-informatie waarnaar u kunt verwijzen:
Notitie
De functie voor gegevensverzameling is momenteel beschikbaar als preview-versie. Alle preview-functies worden niet aanbevolen voor productieworkloads.
Wat wordt verzameld en waar het naartoe gaat
De volgende gegevens kunnen worden verzameld:
Modelinvoergegevens van webservices die zijn geïmplementeerd in een AKS-cluster. Spraakaudio, afbeeldingen en video worden niet verzameld.
Modelvoorspellingen met behulp van productie-invoergegevens.
Notitie
Vooraggregatie en voorberekeningen voor deze gegevens maken momenteel geen deel uit van de verzamelingsservice.
De uitvoer wordt opgeslagen in Blob Storage. Omdat de gegevens worden toegevoegd aan Blob Storage, kunt u uw favoriete hulpprogramma kiezen om de analyse uit te voeren.
Het pad naar de uitvoergegevens in de blob volgt deze syntaxis:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Notitie
In versies van de Azure Machine Learning SDK voor Python ouder dan versie 0.1.0a16 heeft het argument de designation naam identifier. Als u uw code hebt ontwikkeld met een eerdere versie, moet u deze dienovereenkomstig bijwerken.
Vereisten
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Een Azure Machine Learning-werkruimte, een lokale map met uw scripts en de Azure Machine Learning SDK voor Python moet zijn geïnstalleerd. Zie Een ontwikkelomgeving configureren voor meer informatie over het installeren ervan.
U hebt een getraind machine learning-model nodig om te worden geïmplementeerd in AKS. Als u geen model hebt, raadpleegt u de zelfstudie afbeeldingsclassificatiemodel trainen.
U hebt een AKS-cluster nodig. Zie Machine Learning-modellen implementeren in Azure voor meer informatie over het maken en implementeren ervan.
Stel uw omgeving in en installeer de Azure Machine Learning Monitoring SDK.
Gebruik een docker-installatiekopie op basis van Ubuntu 18.04, die wordt geleverd met
libssl 1.0.0, de essentiële afhankelijkheid van modeldatacollector. U kunt verwijzen naar vooraf gemaakte installatiekopieën.
Gegevensverzameling inschakelen
U kunt gegevensverzameling inschakelen, ongeacht het model dat u implementeert via Azure Machine Learning of andere hulpprogramma's.
Als u gegevensverzameling wilt inschakelen, moet u het volgende doen:
Open het scorebestand.
Voeg boven aan het bestand de volgende code toe:
from azureml.monitoring import ModelDataCollectorDeclareer uw gegevensverzamelingsvariabelen in uw
initfunctie:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId is een optionele parameter. U hoeft het niet te gebruiken als uw model dit niet nodig heeft. Het gebruik van CorrelationId helpt u gemakkelijker toe te wijzen met andere gegevens, zoals LoanNumber of CustomerId.
De id-parameter wordt later gebruikt voor het bouwen van de mapstructuur in uw blob. U kunt deze gebruiken om onbewerkte gegevens te onderscheiden van verwerkte gegevens.
Voeg de volgende regels code toe aan de
run(input_df)functie:data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobGegevensverzameling wordt niet automatisch ingesteld op waar wanneer u een service in AKS implementeert. Werk uw configuratiebestand bij, zoals in het volgende voorbeeld:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)U kunt Application Insights ook inschakelen voor servicebewaking door deze configuratie te wijzigen:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Zie Machine Learning-modellen implementeren in Azure om een nieuwe installatiekopieën te maken en het machine learning-model te implementeren.
Voeg het pip-pakket 'Azure-Monitoring' toe aan de conda-afhankelijkheden van de webserviceomgeving:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Gegevensverzameling uitschakelen
U kunt het verzamelen van gegevens op elk gewenst moment stoppen. Python-code gebruiken om gegevensverzameling uit te schakelen.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Uw gegevens valideren en analyseren
U kunt een hulpprogramma van uw voorkeur kiezen om de gegevens te analyseren die in uw Blob-opslag zijn verzameld.
Snel toegang krijgen tot uw blobgegevens
Meld u aan bij het Azure Portal.
Open uw werkruimte.
Selecteer Opslag.

Volg het pad naar de uitvoergegevens van de blob met deze syntaxis:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Modelgegevens analyseren met Power BI
Download en open Power BI Desktop.
Selecteer Gegevens ophalen en Selecteer Azure Blob Storage.
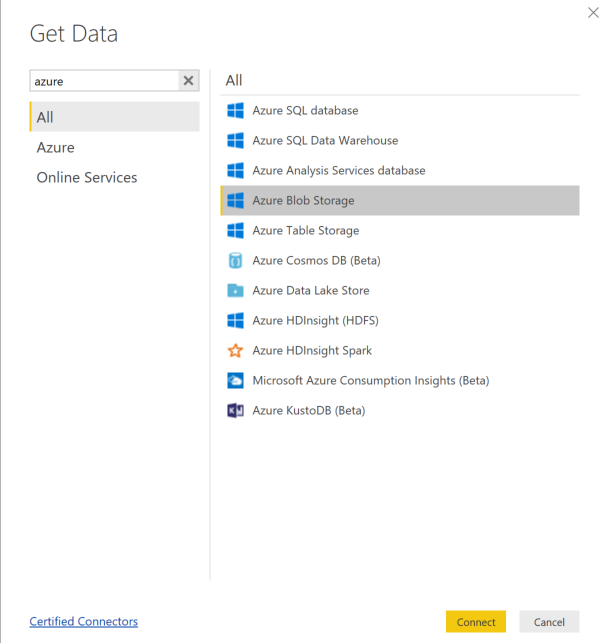
Voeg de naam van uw opslagaccount toe en voer uw opslagsleutel in. U vindt deze informatie door Instellingentoegangssleutels> te selecteren in uw blob.
Selecteer de modelgegevenscontainer en selecteer Bewerken.

Klik in de queryeditor onder de kolom Naam en voeg uw opslagaccount toe.
Voer het modelpad in het filter in. Als u alleen bestanden van een bepaald jaar of een bepaalde maand wilt bekijken, vouwt u het filterpad uit. Als u bijvoorbeeld alleen naar maartgegevens wilt kijken, gebruikt u dit filterpad:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
Filter de gegevens die relevant zijn voor u op basis van naamwaarden . Als u voorspellingen en invoer hebt opgeslagen, moet u voor elke query een query maken.
Selecteer de pijlen omlaag naast de kolomkop Inhoud om de bestanden te combineren.

Selecteer OK. De gegevens worden vooraf geladen.

Selecteer Sluiten en toepassen.
Als u invoer en voorspellingen hebt toegevoegd, worden uw tabellen automatisch gesorteerd op RequestId-waarden .
Begin met het bouwen van uw aangepaste rapporten op uw modelgegevens.




Modelgegevens analyseren met Behulp van Azure Databricks
Maak een Azure Databricks-werkruimte.
Ga naar uw Databricks-werkruimte.
Selecteer Gegevens uploaden in uw Databricks-werkruimte.

Selecteer Nieuwe tabel maken en selecteer Andere gegevensbronnen>in Azure Blob Storage>Create Table in Notebook.

Werk de locatie van uw gegevens bij. Dit is een voorbeeld:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/*/*/data.csv" file_type = "csv"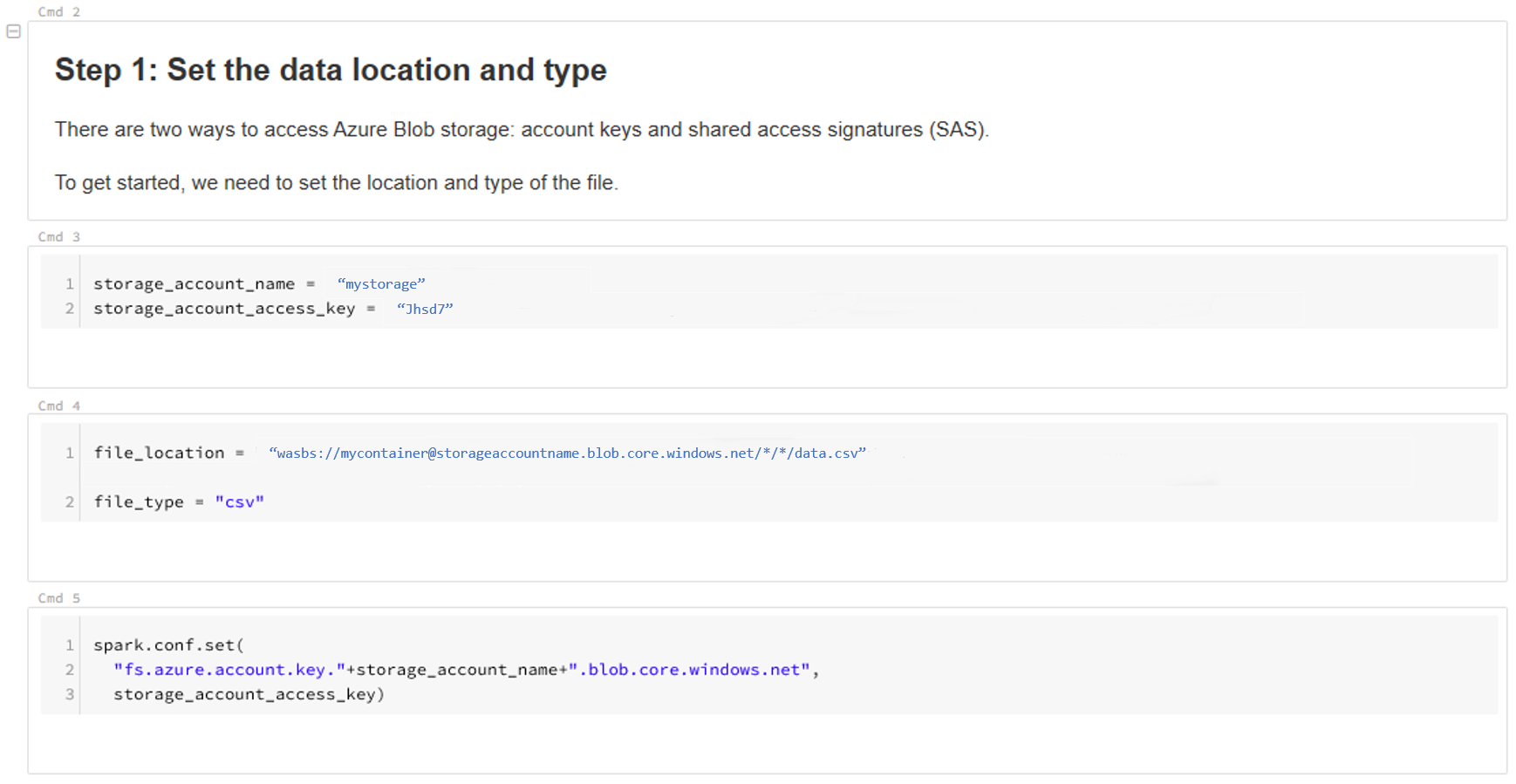
Volg de stappen op de sjabloon om uw gegevens weer te geven en te analyseren.



Volgende stappen
Detecteer gegevensdrift op de gegevens die u hebt verzameld.