Machine Learning-modellen implementeren in Azure
VAN TOEPASSING OP: Azure CLI ml-extensie v1Python SDK azureml v1
Azure CLI ml-extensie v1Python SDK azureml v1
Meer informatie over het implementeren van uw machine learning- of Deep Learning-model als een webservice in de Azure-cloud.
Notitie
Azure Machine Learning-eindpunten (v2) bieden een verbeterde, eenvoudigere implementatie-ervaring. Eindpunten ondersteunen zowel realtime- als batchdeductiescenario's. Eindpunten bieden een uniforme interface voor het aanroepen en beheren van modelimplementaties in verschillende rekentypen. Zie Wat zijn Azure Machine Learning-eindpunten?
Werkstroom voor het implementeren van een model
De werkstroom is vrijwel altijd hetzelfde, ongeacht waar u het model implementeert:
- Registreer het model.
- Bereid een invoerscript voor.
- Een deductieconfiguratie voorbereiden.
- Implementeer het model lokaal om ervoor te zorgen dat alles werkt.
- Kies een rekendoel.
- Implementeer het model in de cloud.
- Test de resulterende webservice.
Zie Modellen beheren, implementeren en bewaken met Azure Machine Learning voor meer informatie over de concepten die betrokken zijn bij de werkstroom voor machine learning-implementatie.
Vereisten
VAN TOEPASSING OP: Azure CLI ml-extensie v1
Belangrijk
Sommige Azure CLI-opdrachten in dit artikel gebruiken de azure-cli-mlextensie (of v1) voor Azure Machine Learning. Ondersteuning voor de v1-extensie eindigt op 30 september 2025. U kunt de v1-extensie tot die datum installeren en gebruiken.
U wordt aangeraden vóór 30 september 2025 over te stappen op de mlextensie of v2. Zie de Azure ML CLI-extensie en Python SDK v2 voor meer informatie over de v2-extensie.
- Een Azure Machine Learning-werkruimte. Zie Werkruimteresources maken voor meer informatie.
- Een model. In de voorbeelden in dit artikel wordt een vooraf getraind model gebruikt.
- Een computer waarop Docker kan worden uitgevoerd, zoals een rekenproces.
Verbinding maken met uw werkruimte
VAN TOEPASSING OP: Azure CLI ml-extensie v1
Gebruik de volgende opdrachten om de werkruimten te zien waartoe u toegang hebt:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Het model registreren
Een typische situatie voor een geïmplementeerde machine learning-service is dat u de volgende onderdelen nodig hebt:
- Resources die het specifieke model vertegenwoordigen dat u wilt implementeren (bijvoorbeeld: een pytorch-modelbestand).
- Code die u uitvoert in de service die het model uitvoert op een bepaalde invoer.
Met Azure Machine Learning kunt u de implementatie splitsen in twee afzonderlijke onderdelen, zodat u dezelfde code kunt behouden en alleen het model hoeft bij te werken. We definiëren het mechanisme waarmee u een model gescheiden van uw code uploadt als het model registreren.
Wanneer u een model registreert, uploaden we het model naar de cloud (in het standaardopslagaccount van uw werkruimte) en koppelen we het vervolgens aan dezelfde berekening als waarop uw webservice wordt uitgevoerd.
In de volgende voorbeelden ziet u hoe u een model registreert.
Belangrijk
Gebruik alleen modellen die u zelf maakt of van een vertrouwde bron verkrijgt. Behandel geserialiseerde modellen als code. Er zijn namelijk beveiligingslekken ontdekt in een aantal populaire indelingen. Het kan ook voorkomen dat modellen opzettelijk worden getraind met kwaadaardige bedoelingen om een vertekende of een onnauwkeurige uitvoer te genereren.
VAN TOEPASSING OP: Azure CLI ml-extensie v1
Met de volgende opdrachten downloadt u een model en registreert u het vervolgens bij uw Azure Machine Learning-werkruimte:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Stel -p in op het pad van een map of een bestand dat u wilt registreren.
Zie de referentiedocumentatie voor meer informatieaz ml model register.
Een model registreren bij een Azure Machine Learning-trainingstaak
Als u een model moet registreren dat eerder is gemaakt via een Azure Machine Learning-trainingstaak, kunt u het experiment, de uitvoering en het pad naar het model opgeven:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
De --asset-path parameter verwijst naar de cloudlocatie van het model. In dit voorbeeld wordt het pad van één bestand gebruikt. Als u meerdere bestanden in de modelregistratie wilt opnemen, stelt u het --asset-path pad in van een map die de bestanden bevat.
Zie de referentiedocumentatie voor meer informatieaz ml model register.
Notitie
U kunt ook een model registreren vanuit een lokaal bestand via de gebruikersinterface van de werkruimte.
Er zijn momenteel twee opties voor het uploaden van een lokaal modelbestand in de gebruikersinterface:
- Vanuit lokale bestanden, waarmee een v2-model wordt geregistreerd.
- Vanuit lokale bestanden (op basis van framework) waarmee een v1-model wordt geregistreerd.
Houd er rekening mee dat alleen modellen die zijn geregistreerd via de ingang van lokale bestanden (op basis van framework) (die bekend staan als v1-modellen) kunnen worden geïmplementeerd als webservices met SDKv1/CLIv1.
Een dummy-invoerscript definiëren
Het invoerscript ontvangt de gegevens die bij een geïmplementeerde webservice zijn ingediend en stuurt ze door naar het model. Vervolgens wordt het antwoord van het model geretourneerd op de client. Het script is specifiek voor uw model. Het invoerscript moet de gegevens begrijpen die het model verwacht en retourneert.
De twee dingen die u moet doen in uw invoerscript zijn:
- Uw model laden (met behulp van een functie met de naam
init()) - Uw model uitvoeren op invoergegevens (met behulp van een functie met de naam
run())
Gebruik voor uw eerste implementatie een dummy-invoerscript waarmee de gegevens worden afgedrukt die worden ontvangen.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Sla dit bestand op in echo_score.py een map met de naam source_dir. Dit dummy-script retourneert de gegevens die u naar het script verzendt, zodat het model niet wordt gebruikt. Het is echter handig om te testen of het scorescript wordt uitgevoerd.
Een deductieconfiguratie definiëren
Een deductieconfiguratie beschrijft de Docker-container en -bestanden die moeten worden gebruikt bij het initialiseren van uw webservice. Alle bestanden in uw bronmap, inclusief submappen, worden gezipt en geüpload naar de cloud wanneer u uw webservice implementeert.
De onderstaande deductieconfiguratie geeft aan dat de machine learning-implementatie het bestand echo_score.py in de ./source_dir map gebruikt om binnenkomende aanvragen te verwerken en dat deze de Docker-installatiekopie gebruikt met de Python-pakketten die zijn opgegeven in de project_environment omgeving.
U kunt elke Azure Machine Learning-deductieomgeving gebruiken als basis-Docker-installatiekopie bij het maken van uw projectomgeving. We installeren de vereiste afhankelijkheden bovenaan en slaan de resulterende Docker-installatiekopieën op in de opslagplaats die is gekoppeld aan uw werkruimte.
Notitie
Upload van bronmap voor Azure Machine Learning-deductie heeft geen respect voor .gitignore of .amlignore
VAN TOEPASSING OP: Azure CLI ml-extensie v1
Een minimale deductieconfiguratie kan worden geschreven als:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Sla dit bestand op met de naam dummyinferenceconfig.json.
Zie dit artikel voor een uitgebreidere bespreking van deductieconfiguraties.
Een implementatieconfiguratie definiëren
Een implementatieconfiguratie geeft de hoeveelheid geheugen en kernen aan die uw webservice nodig heeft om uit te voeren. Het biedt ook configuratiedetails van de onderliggende webservice. Met een implementatieconfiguratie kunt u bijvoorbeeld opgeven dat uw service 2 gigabyte geheugen, 2 CPU-kernen, 1 GPU-kern nodig heeft en dat u automatische schaalaanpassing wilt inschakelen.
De beschikbare opties voor een implementatieconfiguratie verschillen, afhankelijk van het rekendoel dat u kiest. In een lokale implementatie kunt u alleen opgeven op welke poort uw webservice wordt geleverd.
VAN TOEPASSING OP: Azure CLI ml-extensie v1
De vermeldingen in de documenttoewijzing deploymentconfig.json voor de parameters voor LocalWebservice.deploy_configuration. In de volgende tabel wordt de toewijzing tussen de entiteiten in het JSON-document en de parameters beschreven voor de methode:
| JSON-entiteit | Methodeparameter | Beschrijving |
|---|---|---|
computeType |
N.v.t. | Het rekendoel. Voor lokale doelen moet de waarde local zijn. |
port |
port |
De lokale poort waarop het HTTP-eindpunt van de service beschikbaar wordt gemaakt. |
De volgende JSON is een voorbeeld van een implementatieconfiguratie die gebruikt kan worden met de CLI:
{
"computeType": "local",
"port": 32267
}
Sla deze JSON op als een bestand met de naam deploymentconfig.json.
Zie het implementatieschema voor meer informatie.
Uw Machine Learning-model implementeren
U bent nu klaar om uw model te implementeren.
VAN TOEPASSING OP: Azure CLI ml-extensie v1
Vervang door bidaf_onnx:1 de naam van uw model en het bijbehorende versienummer.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Uw model aanroepen
Laten we controleren of uw echomodel is geïmplementeerd. U moet een eenvoudige liveness-aanvraag en een scoreaanvraag kunnen uitvoeren:
VAN TOEPASSING OP: Azure CLI ml-extensie v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Een invoerscript definiëren
Nu is het tijd om uw model daadwerkelijk te laden. Pas eerst het invoerscript aan:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Sla dit bestand op als score.py binnenkant van source_dir.
Let op het gebruik van de AZUREML_MODEL_DIR omgevingsvariabele om uw geregistreerde model te vinden. Nu u een aantal pip-pakketten hebt toegevoegd.
VAN TOEPASSING OP: Azure CLI ml-extensie v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Dit bestand opslaan als inferenceconfig.json
Opnieuw implementeren en uw service aanroepen
Implementeer uw service opnieuw:
VAN TOEPASSING OP: Azure CLI ml-extensie v1
Vervang door bidaf_onnx:1 de naam van uw model en het bijbehorende versienummer.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Zorg er vervolgens voor dat u een postaanvraag naar de service kunt verzenden:
VAN TOEPASSING OP: Azure CLI ml-extensie v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Een rekendoel kiezen
Het rekendoel dat u gebruikt als host voor uw model, is van invloed op de kosten en beschikbaarheid van het geïmplementeerde eindpunt. Gebruik deze tabel om een geschikt rekendoel te kiezen.
| Rekendoel | Gebruikt voor | GPU-ondersteuning | Beschrijving |
|---|---|---|---|
| Lokale webservice | Testen/fouten opsporen | Gebruiken voor testen en problemen oplossen. Hardwareversnelling is afhankelijk van het gebruik van bibliotheken in het lokale systeem. | |
| Azure Machine Learning Kubernetes | Realtime deductie | Ja | Deductieworkloads uitvoeren in de cloud. |
| Azure Container Instances | Realtime deductie Alleen aanbevolen voor ontwikkel-/testdoeleinden. |
Gebruiken voor lage CPU-werkbelastingen waarvoor minder dan 48 GB RAM-geheugen nodig is. U hoeft geen cluster te beheren. Alleen geschikt voor modellen die kleiner zijn dan 1 GB. Ondersteund in de ontwerpfunctie. |
Notitie
Wanneer u een cluster-SKU kiest, moet u eerst omhoog schalen en vervolgens uitschalen. Begin met een computer met 150% van het RAM-geheugen dat uw model nodig heeft, profileer het resultaat en zoek een machine met de prestaties die u nodig hebt. Zodra u dat weet, verhoogt u het aantal machines dat u nodig hebt voor gelijktijdige deductie.
Notitie
Azure Machine Learning-eindpunten (v2) bieden een verbeterde, eenvoudigere implementatie-ervaring. Eindpunten ondersteunen zowel realtime- als batchdeductiescenario's. Eindpunten bieden een uniforme interface voor het aanroepen en beheren van modelimplementaties in verschillende rekentypen. Zie Wat zijn Azure Machine Learning-eindpunten?
Implementeren in de cloud
Zodra u hebt bevestigd dat uw service lokaal werkt en een extern rekendoel hebt gekozen, bent u klaar om te implementeren in de cloud.
Wijzig de implementatieconfiguratie zodat deze overeenkomt met het rekendoel dat u hebt gekozen, in dit geval Azure Container Instances:
VAN TOEPASSING OP: Azure CLI ml-extensie v1
De beschikbare opties voor een implementatieconfiguratie verschillen, afhankelijk van het rekendoel dat u kiest.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Sla dit bestand op als re-deploymentconfig.json.
Zie deze naslaginformatie voor meer informatie.
Implementeer uw service opnieuw:
VAN TOEPASSING OP: Azure CLI ml-extensie v1
Vervang door bidaf_onnx:1 de naam van uw model en het bijbehorende versienummer.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Gebruik de volgende opdracht om de servicelogboeken weer te geven:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Uw externe webservice aanroepen
Wanneer u op afstand implementeert, is sleutelverificatie mogelijk ingeschakeld. In het onderstaande voorbeeld ziet u hoe u uw servicesleutel met Python kunt ophalen om een deductieaanvraag uit te voeren.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Zie het artikel over clienttoepassingen om webservices te gebruiken voor meer voorbeeldclients in andere talen.
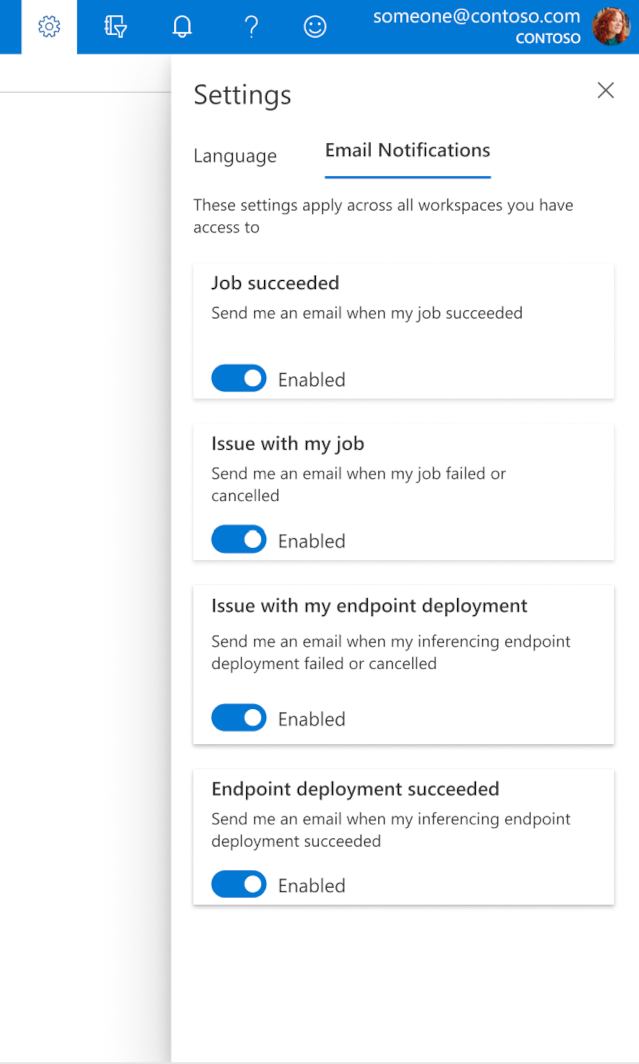
E-mailberichten configureren in de studio
Als u e-mailberichten wilt ontvangen wanneer uw taak, online-eindpunt of batcheindpunt is voltooid of als er een probleem is (mislukt, geannuleerd), gebruikt u de volgende stappen:
- Ga in Azure ML Studio naar instellingen door het tandwielpictogram te selecteren.
- Selecteer het tabblad E-mailmeldingen .
- Schakel deze wisselknop om e-mailmeldingen voor een specifieke gebeurtenis in of uit te schakelen.
Servicestatus begrijpen
Tijdens de modelimplementatie ziet u mogelijk dat de status van de service verandert terwijl deze volledig wordt geïmplementeerd.
In de volgende tabel worden de verschillende servicestatussen beschreven:
| Webservicestatus | Beschrijving | Laatste status? |
|---|---|---|
| Overgang maken | De service wordt geïmplementeerd. | Nee |
| Niet in orde | De service is geïmplementeerd, maar is momenteel niet bereikbaar. | Nee |
| Niet-gepland | De service kan momenteel niet worden geïmplementeerd vanwege een gebrek aan resources. | Nee |
| Mislukt | De service kan niet worden geïmplementeerd vanwege een fout of crash. | Ja |
| In orde | De service is in orde en het eindpunt is beschikbaar. | Ja |
Tip
Bij de implementatie worden Docker-installatiekopieën voor rekendoelen gebouwd en geladen vanuit Azure Container Registry (ACR). Azure Machine Learning maakt standaard een ACR die gebruikmaakt van de basic-servicelaag . Als u de ACR voor uw werkruimte wijzigt in de Standard- of Premium-laag, kan dit de tijd verminderen die nodig is om installatiekopieën te bouwen en te implementeren op uw rekendoelen. Zie Azure Container Registry-servicelagen voor meer informatie.
Notitie
Als u een model implementeert naar Azure Kubernetes Service (AKS), wordt u aangeraden Azure Monitor voor dat cluster in te schakelen. Dit helpt u inzicht te krijgen in de algehele clusterstatus en het resourcegebruik. Mogelijk vindt u de volgende resources ook nuttig:
- Controleren op Resource Health-gebeurtenissen die van invloed zijn op uw AKS-cluster
- Diagnostische gegevens van Azure Kubernetes Service
Als u een model wilt implementeren in een cluster dat niet in orde of overbelast is, levert dit waarschijnlijk problemen op. Neem contact op met AKS-ondersteuning als u hulp nodig hebt bij het oplossen van problemen met AKS-clusters.
Resources verwijderen
VAN TOEPASSING OP: Azure CLI ml-extensie v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Als u een geïmplementeerde webservice wilt verwijderen, gebruikt u az ml service delete <name of webservice>.
Als u een geregistreerd model uit uw werkruimte wilt verwijderen, gebruikt u az ml model delete <model id>
Lees meer over het verwijderen van een webservice en het verwijderen van een model.
Volgende stappen
- Problemen met een mislukte implementatie oplossen
- Webservice bijwerken
- Implementatie met één klik voor geautomatiseerde ML-uitvoeringen in de Azure Machine Learning-studio
- TLS gebruiken om een webservice te beveiligen via Azure Machine Learning
- Uw Azure Machine Learning-modellen bewaken met Application Insights
- Gebeurteniswaarschuwingen en triggers maken voor modelimplementaties