Trainingscode voor een geautomatiseerd ML-model weergeven
In dit artikel leert u hoe u de gegenereerde trainingscode kunt weergeven op basis van een geautomatiseerd machine learning-getraind model.
Met codegeneratie voor geautomatiseerde ML-getrainde modellen kunt u de volgende details bekijken die geautomatiseerde ML gebruikt om het model te trainen en te bouwen voor een specifieke uitvoering.
- Gegevensvoorverwerking
- Algoritmeselectie
- Parametrisatie
- Hyperparameters
U kunt elk geautomatiseerd, door ML getraind model, aanbevolen of onderliggend model selecteren en de gegenereerde Python-trainingscode bekijken die dat specifieke model heeft gemaakt.
Met de trainingscode van het gegenereerde model kunt u,
- Meer informatie over het featurization-proces en de hyperparameters die door het modelalgoritmen worden gebruikt.
- Getrainde modellen bijhouden/versie/controle . Sla versiecode op om bij te houden welke specifieke trainingscode wordt gebruikt met het model dat in productie moet worden geïmplementeerd.
- Pas de trainingscode aan door hyperparameters te wijzigen of de vaardigheden/ervaring van ml en algoritmen toe te passen en een nieuw model opnieuw te trainen met uw aangepaste code.
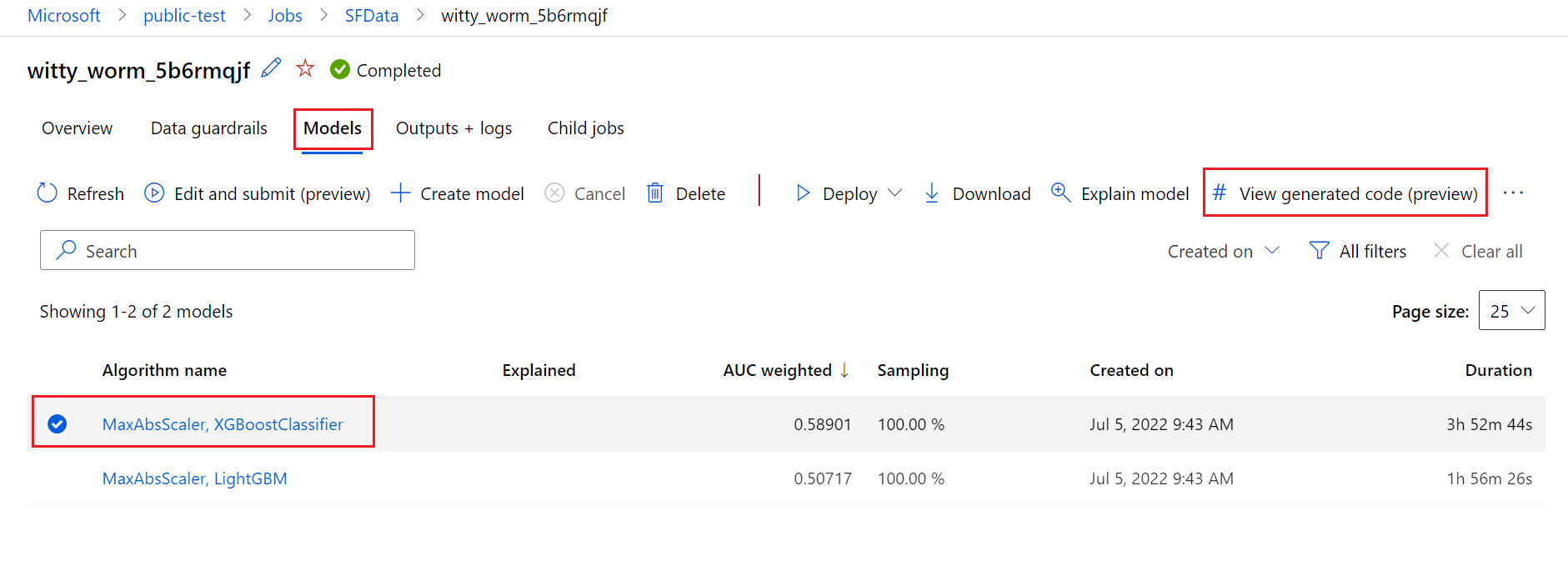
In het volgende diagram ziet u dat u de code voor geautomatiseerde ML-experimenten met alle taaktypen kunt genereren. Selecteer eerst een model. Het geselecteerde model wordt gemarkeerd. Vervolgens kopieert Azure Machine Learning de codebestanden die worden gebruikt om het model te maken en worden deze weergegeven in de gedeelde map met notitieblokken. Hier kunt u de code zo nodig bekijken en aanpassen.
Vereisten
Een Azure Machine Learning-werkruimte. Zie Werkruimtebronnen maken om de werkruimte te maken.
In dit artikel wordt ervan uitgegaan dat u bekend bent met het instellen van een geautomatiseerd machine learning-experiment. Volg de zelfstudie of instructies om de belangrijkste ontwerppatronen voor geautomatiseerde machine learning-experimenten te bekijken.
Geautomatiseerde ML-codegeneratie is alleen beschikbaar voor experimenten die worden uitgevoerd op externe Azure Machine Learning-rekendoelen. Het genereren van code wordt niet ondersteund voor lokale uitvoeringen.
Voor alle geautomatiseerde ML-uitvoeringen die worden geactiveerd via Azure Machine Learning-studio, SDKv2 of CLIv2, is het genereren van code ingeschakeld.
Gegenereerde code en modelartefacten ophalen
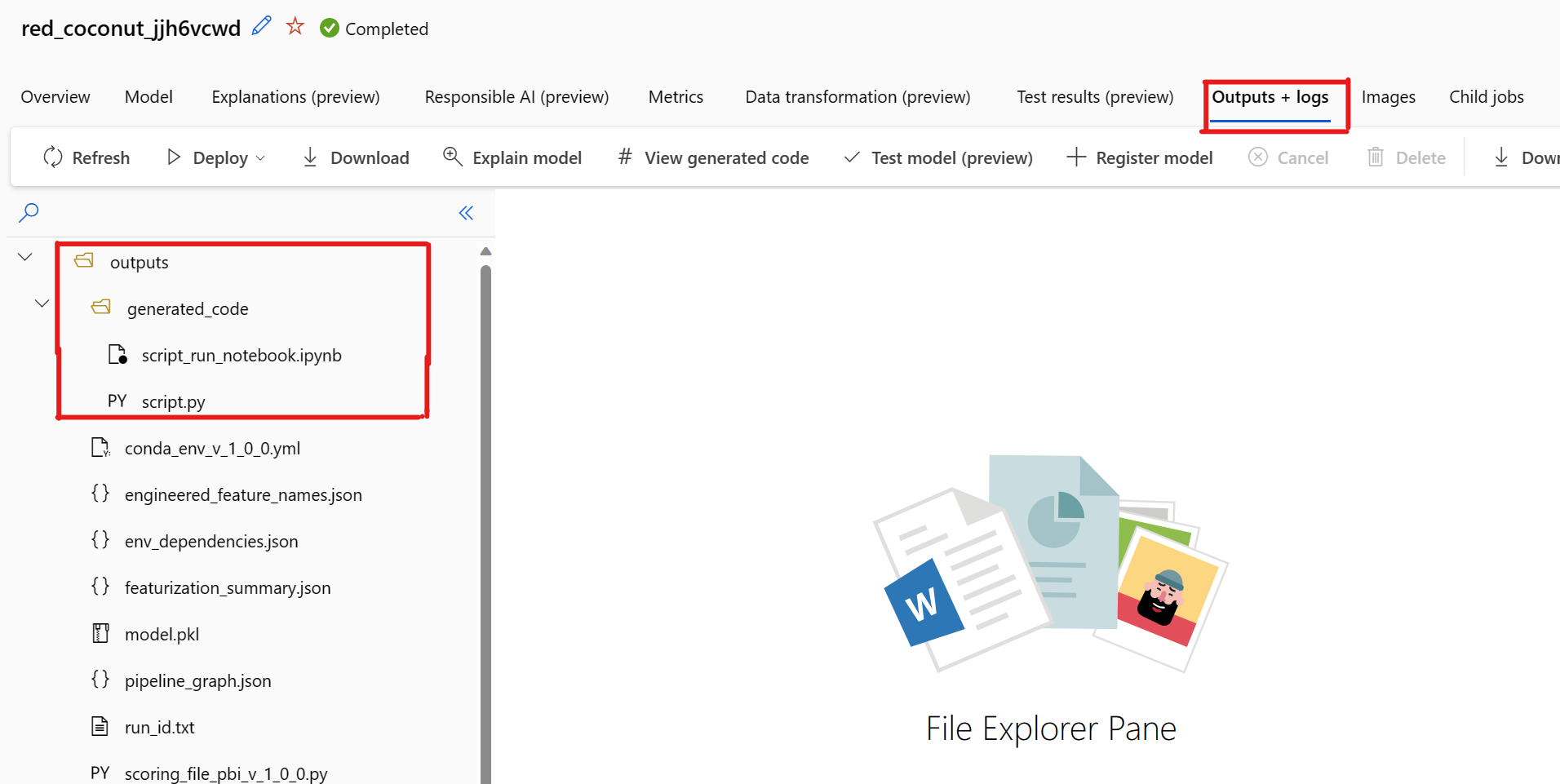
Standaard genereert elk geautomatiseerd ml getraind model de trainingscode nadat de training is voltooid. Geautomatiseerde ML slaat deze code op in het experiment outputs/generated_code voor dat specifieke model. U kunt ze bekijken in de Azure Machine Learning-studio gebruikersinterface op het tabblad Uitvoer en logboeken van het geselecteerde model.
script.py Dit is de trainingscode van het model die u waarschijnlijk wilt analyseren met de featurization-stappen, het specifieke algoritme dat wordt gebruikt en hyperparameters.
script_run_notebook.ipynb Notebook met standaardcode voor het uitvoeren van de trainingscode (script.py) van het model in Azure Machine Learning Compute via Azure Machine Learning SDKv2.
Nadat de geautomatiseerde ML-trainingsuitvoering is voltooid, hebt u toegang tot de script.py en de script_run_notebook.ipynb bestanden via de Azure Machine Learning-studio-gebruikersinterface.
Hiervoor gaat u naar het tabblad Modellen van de bovenliggende pagina van het geautomatiseerde ML-experiment. Nadat u een van de getrainde modellen hebt geselecteerd, kunt u de knop Gegenereerde code weergeven selecteren. Met deze knop wordt u omgeleid naar de portalextensie Notebooks , waar u de gegenereerde code voor dat geselecteerde model kunt bekijken, bewerken en uitvoeren.
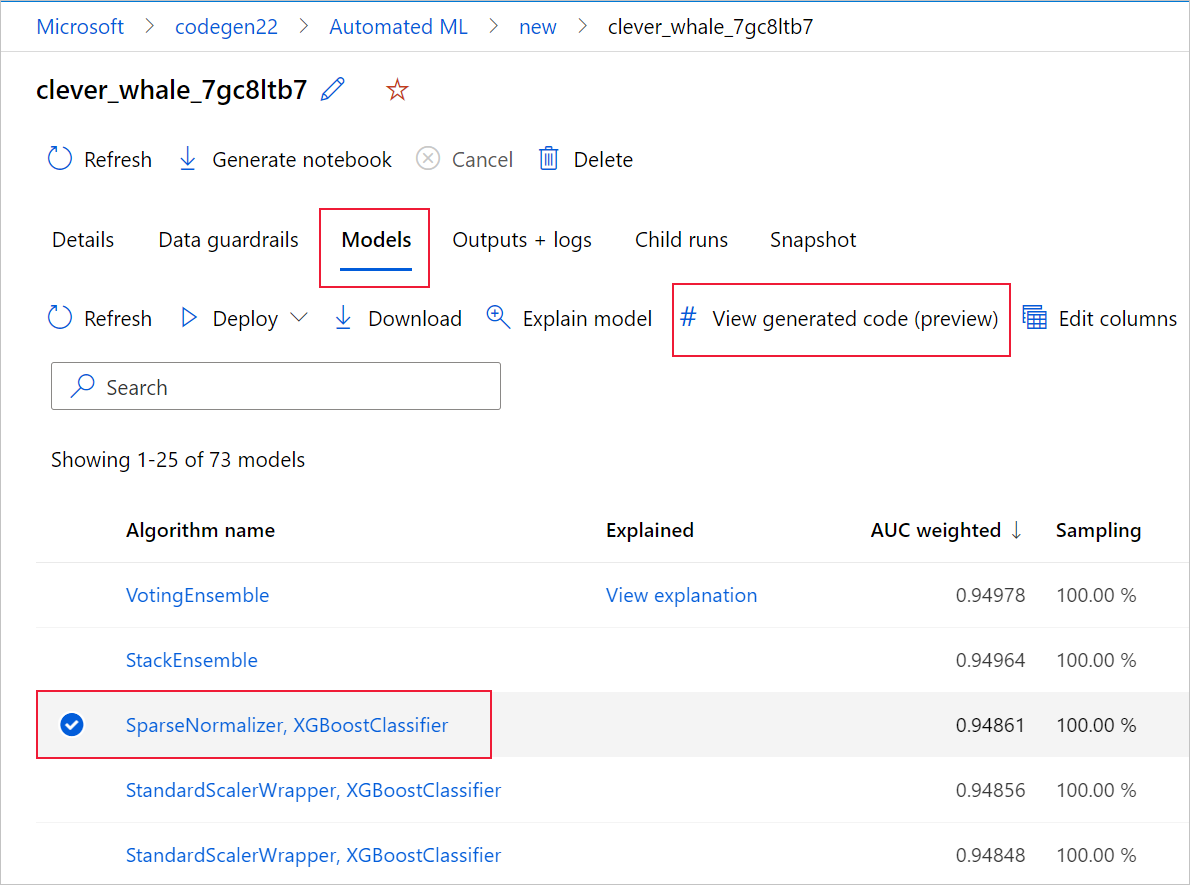
U kunt ook toegang krijgen tot de gegenereerde code van het model vanaf de bovenkant van de pagina van de onderliggende uitvoering zodra u naar de pagina van die onderliggende uitvoering van een bepaald model navigeert.
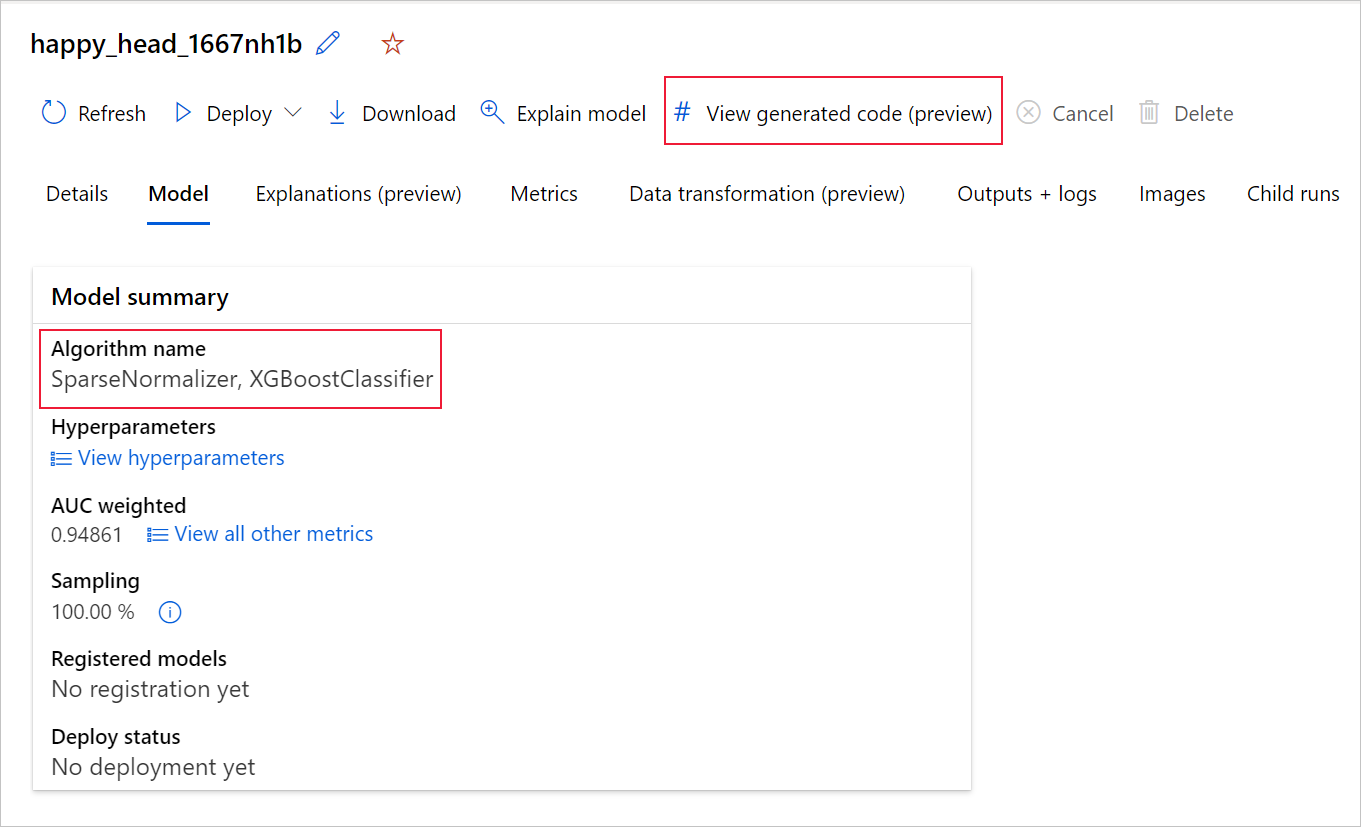
Als u de Python SDKv2 gebruikt, kunt u ook de 'script.py' en de 'script_run_notebook.ipynb' downloaden door de beste uitvoering op te halen via MLFlow en de resulterende artefacten te downloaden.
Beperkingen
Er is een bekend probleem bij het selecteren van gegenereerde code weergeven. Deze actie kan niet worden omgeleid naar de notebooks-portal wanneer de opslag zich achter een VNet bevindt. Als tijdelijke oplossing kan de gebruiker de script.py en de script_run_notebook.ipynb-bestanden handmatig downloaden door te navigeren naar het tabblad Uitvoer en logboeken> onder de uitvoermap generated_code. Deze bestanden kunnen handmatig worden geüpload naar de map notebooks om ze uit te voeren of te bewerken. Volg deze koppeling voor meer informatie over VNets in Azure Machine Learning.
script.py
Het script.py bestand bevat de kernlogica die nodig is om een model te trainen met de eerder gebruikte hyperparameters. Hoewel het is bedoeld om te worden uitgevoerd in de context van een Azure Machine Learning-scriptuitvoering, kan de trainingscode van het model ook zelfstandig worden uitgevoerd in uw eigen on-premises omgeving.
Het script kan ruwweg worden onderverdeeld in verschillende onderdelen: gegevens laden, gegevensvoorbereiding, gegevensvoorbereiding, specificatie van preprocessor/algoritme en training.
Gegevens laden
De functie get_training_dataset() laadt de eerder gebruikte gegevensset. Hierbij wordt ervan uitgegaan dat het script wordt uitgevoerd in een Azure Machine Learning-script dat wordt uitgevoerd onder dezelfde werkruimte als het oorspronkelijke experiment.
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
Bij uitvoering als onderdeel van een scriptuitvoering haalt Run.get_context().experiment.workspace u de juiste werkruimte op. Als dit script echter binnen een andere werkruimte wordt uitgevoerd of lokaal wordt uitgevoerd, moet u het script wijzigen om expliciet de juiste werkruimte op te geven.
Zodra de werkruimte is opgehaald, wordt de oorspronkelijke gegevensset opgehaald door de bijbehorende id. Een andere gegevensset met exact dezelfde structuur kan ook worden opgegeven door id of naam met respectievelijk of get_by_id() get_by_name(). U vindt de id verderop in het script, in een vergelijkbare sectie als de volgende code.
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
U kunt er ook voor kiezen om deze volledige functie te vervangen door uw eigen mechanisme voor het laden van gegevens; de enige beperkingen zijn dat de retourwaarde een Pandas-gegevensframe moet zijn en dat de gegevens dezelfde vorm moeten hebben als in het oorspronkelijke experiment.
Code voor gegevensvoorbereiding
De functie prepare_data() schoont de gegevens op, splitst de kolommen met het functie- en steekproefgewicht op en bereidt de gegevens voor op gebruik in de training.
Deze functie kan variëren, afhankelijk van het type gegevensset en het type experimenttaak: classificatie, regressie, prognose van tijdreeksen, afbeeldingen of NLP-taken.
In het volgende voorbeeld ziet u dat in het algemeen het gegevensframe van de stap voor het laden van gegevens wordt doorgegeven. De labelkolom en voorbeeldgewichten, indien oorspronkelijk opgegeven, worden geëxtraheerd en rijen die uit NaN de invoergegevens worden verwijderd.
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
Als u meer gegevensvoorbereiding wilt uitvoeren, kunt u dit in deze stap doen door uw aangepaste code voor gegevensvoorbereiding toe te voegen.
Code voor gegevensmetrisatie
De functie generate_data_transformation_config() geeft de featurization-stap op in de laatste scikit-learn-pijplijn. De featurizers uit het oorspronkelijke experiment worden hier samen met hun parameters gereproduceerd.
Een mogelijke gegevenstransformatie die in deze functie kan plaatsvinden, kan bijvoorbeeld worden gebaseerd op imputers zoals, en , SimpleImputer() of CatImputer()transformatoren zoals StringCastTransformer() en LabelEncoderTransformer().
Hier volgt een transformator van het type StringCastTransformer() dat kan worden gebruikt om een set kolommen te transformeren. In dit geval is de set aangegeven door column_names.
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
Als u veel kolommen hebt waarop dezelfde featurization/transformatie moet worden toegepast (bijvoorbeeld 50 kolommen in verschillende kolomgroepen), worden deze kolommen verwerkt door te groeperen op basis van het type.
In het volgende voorbeeld ziet u dat voor elke groep een unieke mapper is toegepast. Deze mapper wordt vervolgens toegepast op elk van de kolommen van die groep.
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
Met deze aanpak kunt u een meer gestroomlijnde code hebben, door niet het codeblok van een transformator voor elke kolom te hebben, wat vooral lastig kan zijn, zelfs wanneer u tientallen of honderden kolommen in uw gegevensset hebt.
Met classificatie- en regressietaken wordt [FeatureUnion] gebruikt voor featurizers.
Voor tijdreeksprognosemodellen worden meerdere tijdreeksbewuste featurizers verzameld in een scikit-learn-pijplijn en vervolgens verpakt in de TimeSeriesTransformer.
Alle door de gebruiker geleverde featurizations voor het voorspellen van tijdreeksmodellen vindt plaats vóór de modellen die worden geleverd door geautomatiseerde ML.
Preprocessorspecificatiecode
De functie generate_preprocessor_config(), indien aanwezig, geeft een voorverwerkingsstap op die moet worden uitgevoerd na featurization in de uiteindelijke scikit-learn-pijplijn.
Normaal gesproken bestaat deze voorverwerkingsstap alleen uit gegevensstandaardisatie/normalisatie die met sklearn.preprocessing.
Geautomatiseerde ML geeft alleen een voorverwerkingsstap op voor niet-lijkende classificatie- en regressiemodellen.
Hier volgt een voorbeeld van een gegenereerde preprocessorcode:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
Specificatiecode voor algoritme en hyperparameters
De code voor algoritme- en hyperparametersspecificatie is waarschijnlijk waar veel ML-professionals het meest in geïnteresseerd zijn.
De generate_algorithm_config() functie specificeert het werkelijke algoritme en de hyperparameters voor het trainen van het model als de laatste fase van de uiteindelijke scikit-learn-pijplijn.
In het volgende voorbeeld wordt een XGBoostClassifier-algoritme met specifieke hyperparameters gebruikt.
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
De gegenereerde code maakt in de meeste gevallen gebruik van OSS-pakketten (Open Source Software) en -klassen. Er zijn exemplaren waarin tussenliggende wrapperklassen worden gebruikt om complexere code te vereenvoudigen. XGBoost-classificatie en andere veelgebruikte bibliotheken, zoals LightGBM of Scikit-Learn-algoritmen, kunnen bijvoorbeeld worden toegepast.
Als ML Professional kunt u de configuratiecode van dat algoritme aanpassen door de hyperparameters zo nodig aan te passen op basis van uw vaardigheden en ervaring voor dat algoritme en uw specifieke ML-probleem.
Voor ensemblemodellen ( generate_preprocessor_config_N() indien nodig) en generate_algorithm_config_N() worden gedefinieerd voor elke cursist in het ensemblemodel, waarbij N de plaatsing van elke leerling in de lijst van het ensemblemodel wordt aangegeven. Voor stack ensemblemodellen wordt de meta-cursist generate_algorithm_config_meta() gedefinieerd.
End-to-end trainingscode
Codegeneratie verzendt build_model_pipeline() en train_model() voor het definiëren van de scikit-learn-pijplijn en voor het aanroepen fit() ervan.
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
De scikit-learn-pijplijn bevat de featurization-stap, een preprocessor (indien gebruikt) en het algoritme of model.
Voor tijdreeksprognosemodellen wordt de scikit-learn-pijplijn verpakt in een ForecastingPipelineWrapper, die aanvullende logica bevat die nodig is om tijdreeksgegevens correct te verwerken, afhankelijk van het toegepaste algoritme.
Voor alle taaktypen gebruiken PipelineWithYTransformer we in gevallen waarin de labelkolom moet worden gecodeerd.
Zodra u de scikit-Learn-pijplijn hebt, hoeft u alleen maar de fit() methode aan te roepen om het model te trainen:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
De retourwaarde van waaruit train_model() het model is aangepast/getraind op de invoergegevens.
De belangrijkste code waarmee alle vorige functies worden uitgevoerd, is het volgende:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
Zodra u het getrainde model hebt, kunt u het gebruiken voor het maken van voorspellingen met de methode predict(). Als uw experiment voor een tijdreeksmodel is, gebruikt u de methode forecast() voor voorspellingen.
y_pred = model.predict(X)
Ten slotte wordt het model geserialiseerd en opgeslagen als een .pkl bestand met de naam model.pkl:
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb
Het script_run_notebook.ipynb notebook fungeert als een eenvoudige manier om te worden uitgevoerd script.py op een Azure Machine Learning-rekenproces.
Dit notebook is vergelijkbaar met de bestaande geautomatiseerde ML-voorbeeldnotebooks, maar er zijn enkele belangrijke verschillen, zoals wordt uitgelegd in de volgende secties.
Omgeving
Normaal gesproken wordt de trainingsomgeving voor een geautomatiseerde ML-uitvoering automatisch ingesteld door de SDK. Wanneer u echter een aangepast script uitvoert zoals de gegenereerde code, wordt geautomatiseerde ML niet langer door het proces geleid, dus moet de omgeving worden opgegeven om de opdrachttaak te laten slagen.
Het genereren van code hergebruikt de omgeving die is gebruikt in het oorspronkelijke geautomatiseerde ML-experiment, indien mogelijk. Dit garandeert dat de uitvoering van het trainingsscript niet mislukt vanwege ontbrekende afhankelijkheden en heeft een voordeel van het niet nodig hebben van het opnieuw opbouwen van docker-installatiekopieën, waardoor tijd en rekenresources worden bespaard.
Als u wijzigingen script.py aanbrengt die aanvullende afhankelijkheden vereisen of als u uw eigen omgeving wilt gebruiken, moet u de omgeving in de script_run_notebook.ipynb omgeving dienovereenkomstig bijwerken.
Het experiment verzenden
Omdat de gegenereerde code niet meer wordt aangestuurd door geautomatiseerde ML, in plaats van een AutoML-taak te maken en te verzenden, moet u een Command Job gegenereerde code (script.py) maken en opgeven.
Het volgende voorbeeld bevat de parameters en reguliere afhankelijkheden die nodig zijn om een opdrachttaak uit te voeren, zoals berekening, omgeving, enzovoort.
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning studio
Volgende stappen
- Meer informatie over hoe en waar u een model kunt implementeren.
- Bekijk hoe u interpreteerbaarheidsfuncties specifiek kunt inschakelen binnen geautomatiseerde ML-experimenten.