Interactieve R-ontwikkeling
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel wordt beschreven hoe u R gebruikt in Azure Machine Learning-studio op een rekenproces waarop een R-kernel wordt uitgevoerd in een Jupyter-notebook.
De populaire RStudio IDE werkt ook. U kunt RStudio of Posit Workbench installeren in een aangepaste container op een rekenproces. Dit heeft echter beperkingen bij het lezen en schrijven naar uw Azure Machine Learning-werkruimte.
Belangrijk
De code die in dit artikel wordt weergegeven, werkt op een Azure Machine Learning-rekenproces. Het rekenproces heeft een omgevings- en configuratiebestand dat nodig is om de code te kunnen uitvoeren.
Vereisten
- Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint. Probeer vandaag nog de gratis of betaalde versie van Azure Machine Learning
- Een Azure Machine Learning-werkruimte en een rekenproces
- Een basiskennis van het gebruik van Jupyter-notebooks in Azure Machine Learning-studio. Ga naar de modelontwikkeling op een cloudwerkstationresource voor meer informatie.
R uitvoeren in een notebook in studio
U gebruikt een notebook in uw Azure Machine Learning-werkruimte op een rekenproces.
Meld u aan bij Azure Machine Learning-studio
Open uw werkruimte als deze nog niet is geopend
Selecteer notitieblokken in het linkernavigatievenster
Maak een nieuw notebook met de naam RunR.ipynb
Tip
Als u niet zeker weet hoe u notebooks maakt en gebruikt in studio, bekijkt u Jupyter-notebooks uitvoeren in uw werkruimte
Selecteer het notitieblok.
Controleer op de notebookwerkbalk of uw rekenproces wordt uitgevoerd. Zo niet, start het nu.
Schakel op de notebookwerkbalk de kernel over naar R.
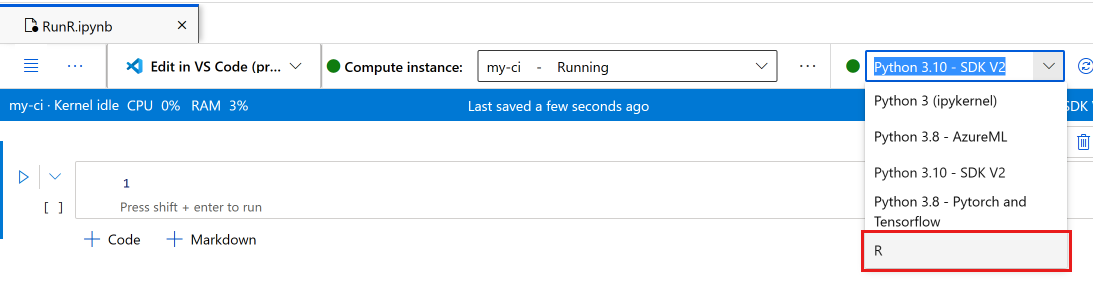

Uw notebook is nu klaar om R-opdrachten uit te voeren.
Toegang tot gegevens
U kunt bestanden uploaden naar de opslagresource voor werkruimtebestanden en deze bestanden vervolgens openen in R. Voor bestanden die zijn opgeslagen in Azure-gegevensassets of gegevens uit gegevensarchieven, moet u echter enkele pakketten installeren.
In deze sectie wordt beschreven hoe u Python en het reticulate pakket gebruikt om uw gegevensassets en gegevensarchieven vanuit een interactieve sessie in R te laden. U gebruikt het azureml-fsspec Python-pakket en het reticulate R-pakket om tabelgegevens te lezen als Pandas DataFrames. Deze sectie bevat ook een voorbeeld van het lezen van gegevensassets en gegevensarchieven in een R data.frame.
Ga als volgt te werk om deze pakketten te installeren:
Maak een nieuw bestand op het rekenproces met de naam setup.sh.
Kopieer deze code naar het bestand:
#!/bin/bash set -e # Installs azureml-fsspec in default conda environment # Does not need to run as sudo eval "$(conda shell.bash hook)" conda activate azureml_py310_sdkv2 pip install azureml-fsspec conda deactivate # Checks that version 1.26 of reticulate is installed (needs to be done as sudo) sudo -u azureuser -i <<'EOF' R -e "if (packageVersion('reticulate') >= 1.26) message('Version OK') else install.packages('reticulate')" EOFSelecteer Opslaan en script uitvoeren in terminal om het script uit te voeren
Het installatiescript verwerkt deze stappen:
pipwordtazureml-fsspecgeïnstalleerd in de standaardconda-omgeving voor het rekenproces- Installeert het R-pakket
reticulateindien nodig (versie moet 1.26 of hoger zijn)
Tabelgegevens lezen uit geregistreerde gegevensassets of gegevensarchieven
Voor gegevens die zijn opgeslagen in een gegevensasset die is gemaakt in Azure Machine Learning, gebruikt u deze stappen om dat tabellaire bestand te lezen in een Pandas DataFrame of een R data.frame:
Notitie
Het lezen van een bestand met reticulate alleen tabelgegevens werkt.
Zorg ervoor dat u de juiste versie van
reticulate. Probeer voor een versie kleiner dan 1.26 een nieuwer rekenproces te gebruiken.packageVersion("reticulate")De Conda-omgeving laden
reticulateen instellen waarazureml-fsspecdeze is geïnstalleerdlibrary(reticulate) use_condaenv("azureml_py310_sdkv2") print("Environment is set")Zoek het URI-pad naar het gegevensbestand.
Haal eerst een ingang op voor uw werkruimte
py_code <- "from azure.identity import DefaultAzureCredential from azure.ai.ml import MLClient credential = DefaultAzureCredential() ml_client = MLClient.from_config(credential=credential)" py_run_string(py_code) print("ml_client is configured")Gebruik deze code om de asset op te halen. Zorg ervoor dat u de naam en het nummer van uw gegevensasset vervangt
<MY_NAME>en<MY_VERSION>vervangt.Tip
Selecteer in studio Gegevens in de linkernavigatiebalk om de naam en het versienummer van uw gegevensasset te vinden.
# Replace <MY_NAME> and <MY_VERSION> with your values py_code <- "my_name = '<MY_NAME>' my_version = '<MY_VERSION>' data_asset = ml_client.data.get(name=my_name, version=my_version) data_uri = data_asset.path"Voer de code uit om de URI op te halen.
py_run_string(py_code) print(paste("URI path is", py$data_uri))
Gebruik Pandas-leesfuncties om het bestand of de bestanden in de R-omgeving te lezen.
pd <- import("pandas") cc <- pd$read_csv(py$data_uri) head(cc)
U kunt ook een gegevensarchief-URI gebruiken om toegang te krijgen tot verschillende bestanden in een geregistreerde gegevensopslag en deze resources te lezen in een R data.frame.
Maak in deze indeling een gegevensarchief-URI met uw eigen waarden:
subscription <- '<subscription_id>' resource_group <- '<resource_group>' workspace <- '<workspace>' datastore_name <- '<datastore>' path_on_datastore <- '<path>' uri <- paste0("azureml://subscriptions/", subscription, "/resourcegroups/", resource_group, "/workspaces/", workspace, "/datastores/", datastore_name, "/paths/", path_on_datastore)Tip
In plaats van de URI-indeling van het gegevensarchief te onthouden, kunt u de URI voor het gegevensarchief kopiëren en plakken vanuit de gebruikersinterface van Studio, als u de gegevensopslag kent waar het bestand zich bevindt:
- Navigeer naar het bestand/de map die u wilt lezen in R
- Selecteer het beletselteken (...) ernaast.
- Selecteer in het menu URI kopiëren.
- Selecteer de gegevensarchief-URI die u wilt kopiëren naar uw notebook/script.
Houd er rekening mee dat u een variabele moet maken voor
<path>in de code.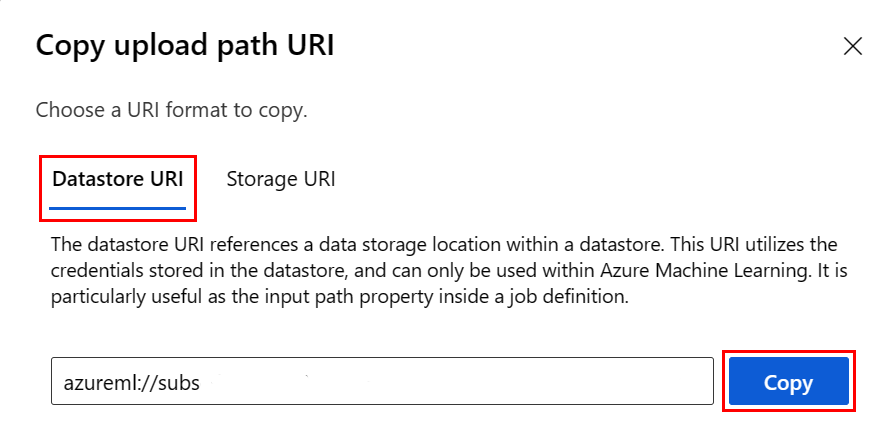
Maak een filestore-object met behulp van de eerder genoemde URI:
fs <- azureml.fsspec$AzureMachineLearningFileSystem(uri, sep = "")
- Inlezen in een R
data.frame:
df <- with(fs$open("<path>)", "r") %as% f, {
x <- as.character(f$read(), encoding = "utf-8")
read.csv(textConnection(x), header = TRUE, sep = ",", stringsAsFactors = FALSE)
})
print(df)
R-pakketten installeren
Een rekenproces heeft veel vooraf geïnstalleerde R-pakketten.
Als u andere pakketten wilt installeren, moet u expliciet de locatie en afhankelijkheden instellen.
Tip
Wanneer u een ander rekenproces maakt of gebruikt, moet u alle pakketten die u hebt geïnstalleerd, opnieuw installeren.
Als u bijvoorbeeld het tsibble pakket wilt installeren:
install.packages("tsibble",
dependencies = TRUE,
lib = "/home/azureuser")
Notitie
Als u pakketten installeert in een R-sessie die wordt uitgevoerd in een Jupyter-notebook, dependencies = TRUE is dit vereist. Anders worden afhankelijke pakketten niet automatisch geïnstalleerd. De lib-locatie is ook vereist om te installeren op de juiste locatie van het rekenproces.
R-bibliotheken laden
Toevoegen /home/azureuser aan het R-bibliotheekpad.
.libPaths("/home/azureuser")
Tip
U moet het .libPaths in elk interactief R-script bijwerken om toegang te krijgen tot door de gebruiker geïnstalleerde bibliotheken. Voeg deze code toe aan het begin van elk interactief R-script of notebook.
Zodra het libPath is bijgewerkt, laadt u bibliotheken zoals gewoonlijk.
library('tsibble')
R gebruiken in het notebook
Gebruik R net als in elke andere omgeving, met inbegrip van uw lokale werkstation, buiten de eerder beschreven problemen. In uw notebook of script kunt u lezen en schrijven naar het pad waar het notebook/script is opgeslagen.
Notitie
- Vanuit een interactieve R-sessie kunt u alleen schrijven naar het bestandssysteem van de werkruimte.
- Vanuit een interactieve R-sessie kunt u niet communiceren met MLflow (zoals logboekmodel of queryregister).