Het verantwoordelijke AI-dashboard gebruiken in Azure Machine Learning-studio
Verantwoorde AI-dashboards zijn gekoppeld aan uw geregistreerde modellen. Als u uw verantwoordelijke AI-dashboard wilt bekijken, gaat u naar het modelregister en selecteert u het geregistreerde model waarvoor u een verantwoordelijk AI-dashboard hebt gegenereerd. Selecteer vervolgens het tabblad Verantwoorde AI om een lijst met gegenereerde dashboards weer te geven.

U kunt meerdere dashboards configureren en deze koppelen aan uw geregistreerde model. Verschillende combinaties van onderdelen (interpreteerbaarheid, foutanalyse, causale analyse, enzovoort) kunnen worden gekoppeld aan elk verantwoordelijk AI-dashboard. In de volgende afbeelding ziet u de aanpassing van een dashboard en de onderdelen die erin zijn gegenereerd. In elk dashboard kunt u verschillende onderdelen in de gebruikersinterface van het dashboard zelf weergeven of verbergen.

Selecteer de naam van het dashboard om het te openen in een volledige weergave in uw browser. Als u wilt terugkeren naar uw lijst met dashboards, kunt u op elk gewenst moment Terug naar modeldetails selecteren.

Volledige functionaliteit met geïntegreerde rekenresource
Voor sommige functies van het verantwoordelijke AI-dashboard zijn dynamische, on-the-fly- en realtimeberekeningen vereist (bijvoorbeeld wat-als-analyse). Tenzij u een rekenresource verbindt met het dashboard, ontbreekt er mogelijk een aantal functies. Wanneer u verbinding maakt met een rekenresource, schakelt u de volledige functionaliteit van uw Responsible AI-dashboard in voor de volgende onderdelen:
- Foutenanalyse
- Als u uw globale-gegevenshort instelt op een cohort van belang, wordt de foutstructuur bijgewerkt in plaats dat deze wordt uitgeschakeld.
- Het selecteren van andere metrische fout- of prestatiegegevens wordt ondersteund.
- Het selecteren van een subset van functies voor de training van de foutstructuurkaart wordt ondersteund.
- Het wijzigen van het minimale aantal vereiste steekproeven per bladknooppunt en diepte van de foutstructuur wordt ondersteund.
- Dynamisch bijwerken van de heatmap voor maximaal twee functies wordt ondersteund.
- Urgentie van functies
- Een afzonderlijke voorwaardelijke verwachting (ICE) plot op het tabblad met het belang van afzonderlijke functies wordt ondersteund.
- Contrafactuele what-if
- Het genereren van een nieuw what-if contrafactual gegevenspunt om inzicht te krijgen in de minimale wijziging die vereist is voor een gewenst resultaat wordt ondersteund.
- Causale analyse
- Het selecteren van een afzonderlijk gegevenspunt, het verstoren van de behandelingsfuncties en het zien van het verwachte causale resultaat van causaal wat-als wordt ondersteund (alleen voor regressie-machine learning-scenario's).
U kunt deze informatie ook vinden op de pagina Verantwoordelijke AI-dashboard door het pictogram Informatie te selecteren, zoals wordt weergegeven in de volgende afbeelding:

Volledige functionaliteit van het verantwoordelijke AI-dashboard inschakelen
Selecteer een actief rekenproces in de vervolgkeuzelijst Compute boven aan het dashboard. Als u geen actieve berekening hebt, maakt u een nieuw rekenproces door het plusteken (+) naast de vervolgkeuzelijst te selecteren. U kunt ook de knop Rekenproces starten selecteren om een gestopt rekenproces te starten. Het maken of starten van een rekenproces kan enkele minuten duren.

Wanneer een berekening de status Actief heeft, begint uw verantwoordelijke AI-dashboard verbinding te maken met het rekenproces. Hiervoor wordt een terminalproces gemaakt op het geselecteerde rekenproces en wordt er een verantwoordelijk AI-eindpunt gestart in de terminal. Selecteer Terminaluitvoer weergeven om het huidige terminalproces weer te geven.

Wanneer uw verantwoordelijke AI-dashboard is verbonden met het rekenproces, ziet u een groene berichtenbalk en is het dashboard nu volledig functioneel.

Als het proces enige tijd duurt en uw verantwoordelijke AI-dashboard nog steeds niet is verbonden met het rekenproces of als er een rode foutberichtsbalk wordt weergegeven, betekent dit dat er problemen zijn met het starten van uw verantwoordelijke AI-eindpunt. Selecteer Terminal-uitvoer weergeven en schuif omlaag naar beneden om het foutbericht weer te geven.

Als u problemen ondervindt bij het oplossen van het probleem 'Kan geen verbinding maken met rekenproces', selecteert u het pictogram Glimlach rechtsboven. Stuur feedback naar ons over eventuele fouten of problemen die u ondervindt. U kunt een schermopname en uw e-mailadres opnemen in het feedbackformulier.




Overzicht van de gebruikersinterface van het verantwoordelijke AI-dashboard
Het verantwoordelijke AI-dashboard bevat een robuuste, uitgebreide set visualisaties en functionaliteit om u te helpen bij het analyseren van uw machine learning-model of het nemen van zakelijke beslissingen op basis van gegevens:
- Algemene besturingselementen
- Foutenanalyse
- Overzicht van modellen en metrische gegevens voor redelijkheid
- Gegevensanalyse
- Belangrijkheid van functies (modeluitleg)
- Contrafactuele what-if
- Causale analyse
Algemene besturingselementen
Boven aan het dashboard kunt u cohorten maken (subgroepen van gegevenspunten die opgegeven kenmerken delen) om uw analyse van elk onderdeel te concentreren. De naam van het cohort dat momenteel op het dashboard wordt toegepast, wordt altijd linksboven in het dashboard weergegeven. De standaardweergave in uw dashboard is uw hele gegevensset met de titel Alle gegevens (standaard).

- Cohortinstellingen: hiermee kunt u de details van elk cohort in een zijpaneel weergeven en wijzigen.
- Dashboardconfiguratie: Hiermee kunt u de indeling van het algehele dashboard in een zijpaneel weergeven en wijzigen.
- Ander cohort: hiermee kunt u een ander cohort selecteren en de statistieken ervan weergeven in een pop-upvenster.
- Nieuw cohort: hiermee kunt u een nieuw cohort maken en toevoegen aan uw dashboard.
Selecteer Cohortinstellingen om een deelvenster te openen met een lijst met uw cohorten, waar u ze kunt maken, bewerken, dupliceren of verwijderen.

Selecteer Nieuw cohort boven aan het dashboard of in de cohortinstellingen om een nieuw deelvenster te openen met opties om op het volgende te filteren:
- Index: filtert op de positie van het gegevenspunt in de volledige gegevensset.
- Gegevensset: Filtert op de waarde van een bepaalde functie in de gegevensset.
- Voorspelde Y: Filters op basis van de voorspelling van het model.
- True Y: Filtert op de werkelijke waarde van de doelfunctie.
- Fout (regressie): filters op fout (of classificatieresultaat (classificatie): filters op type en nauwkeurigheid van classificatie).
- Categorische waarden: Filter op een lijst met waarden die moeten worden opgenomen.
- Numerieke waarden: Filter op een Booleaanse bewerking boven de waarden (selecteer bijvoorbeeld gegevenspunten waarbij leeftijd 64 is < ).

U kunt het nieuwe cohort van de gegevensset een naam geven, filter toevoegen selecteren om elk filter toe te voegen dat u wilt gebruiken en vervolgens een van de volgende handelingen uitvoeren:
- Selecteer Opslaan om het nieuwe cohort op te slaan in uw cohortlijst.
- Selecteer Opslaan en overschakelen om het globale cohort van het dashboard op te slaan en onmiddellijk over te schakelen naar het zojuist gemaakte cohort.

Selecteer Dashboardconfiguratie om een deelvenster te openen met een lijst met de onderdelen die u hebt geconfigureerd op uw dashboard. U kunt onderdelen op uw dashboard verbergen door het prullenbakpictogram te selecteren, zoals wordt weergegeven in de volgende afbeelding:

U kunt onderdelen weer toevoegen aan uw dashboard via het blauwe cirkelvormige plusteken (+) in de scheidingslijn tussen elk onderdeel, zoals wordt weergegeven in de volgende afbeelding:

Foutenanalyse
In de volgende secties wordt beschreven hoe u foutstructuurkaarten en heatmaps interpreteert en gebruikt.
Structuurkaart van fout
Het eerste deelvenster van het onderdeel voor foutanalyse is een structuurkaart, die laat zien hoe modelfouten worden verdeeld over verschillende cohorten met een structuurvisualisatie. Selecteer een knooppunt om het voorspellingspad op uw functies te zien waar een fout is gevonden.

- Heatmapweergave: Schakelt over naar heatmapvisualisatie van foutdistributie.
- Functielijst: Hiermee kunt u de functies wijzigen die in de heatmap worden gebruikt met behulp van een zijpaneel.
- Foutdekking: geeft het percentage weer van alle fouten in de gegevensset die is geconcentreerd in het geselecteerde knooppunt.
- Fout (regressie) of foutpercentage (classificatie): geeft de fout of het percentage fouten van alle gegevenspunten in het geselecteerde knooppunt weer.
- Knooppunt: Vertegenwoordigt een cohort van de gegevensset, mogelijk met toegepaste filters en het aantal fouten uit het totale aantal gegevenspunten in het cohort.
- Opvullijn: Visualiseert de verdeling van gegevenspunten in onderliggende cohorten op basis van filters, met het aantal gegevenspunten dat wordt weergegeven via lijndikte.
- Selectiegegevens: Bevat informatie over het geselecteerde knooppunt in een zijpaneel.
- Opslaan als een nieuw cohort: hiermee maakt u een nieuw cohort met de opgegeven filters.
- Exemplaren in het basiscohort: geeft het totale aantal punten in de volledige gegevensset weer en het aantal correct en onjuist voorspelde punten.
- Exemplaren in het geselecteerde cohort: geeft het totale aantal punten in het geselecteerde knooppunt weer en het aantal correct en onjuist voorspelde punten.
- Voorspellingspad (filters): geeft een lijst weer van de filters die worden geplaatst over de volledige gegevensset om dit kleinere cohort te maken.
Selecteer de knop Lijst met functies om een zijpaneel te openen, waaruit u de foutstructuur opnieuw kunt trainen voor specifieke functies.

- Zoekfuncties: Hiermee kunt u specifieke functies vinden in de gegevensset.
- Functies: Geeft de naam van de functie in de gegevensset weer.
- Urgenties: Een richtlijn voor de relatie tussen de functie en de fout. Berekend via de score voor wederzijdse informatie tussen de functie en de fout op de labels. U kunt deze score gebruiken om te bepalen welke functies u wilt kiezen in de foutanalyse.
- Vinkje: Hiermee kunt u de functie toevoegen aan of verwijderen uit de structuurkaart.
- Maximale diepte: De maximale diepte van de surrogaatboom die is getraind op fouten.
- Aantal bladeren: het aantal bladeren van de surrogaatboom die is getraind op fouten.
- Minimaal aantal steekproeven in één blad: de minimale hoeveelheid gegevens die nodig is om één blad te maken.
Fout heatmap
Selecteer het tabblad Heatmap om over te schakelen naar een andere weergave van de fout in de gegevensset. U kunt een of meer heatmapcellen selecteren en nieuwe cohorten maken. U kunt maximaal twee functies kiezen om een heatmap te maken.

- Cellen: Geeft het aantal geselecteerde cellen weer.
- Foutdekking: geeft het percentage van alle fouten weer die zijn geconcentreerd in de geselecteerde cel(en).
- Foutpercentage: geeft het percentage fouten van alle gegevenspunten in de geselecteerde cel(en) weer.
- Asfuncties: Hiermee selecteert u het snijpunt van functies die u wilt weergeven in de heatmap.
- Cellen: Vertegenwoordigt een cohort van de gegevensset, waarbij filters zijn toegepast en het percentage fouten uit het totale aantal gegevenspunten in het cohort. Een blauwe omtrek geeft geselecteerde cellen aan en de duisternis van rood vertegenwoordigt de concentratie van storingen.
- Voorspellingspad (filters): geeft een lijst weer van de filters die worden geplaatst over de volledige gegevensset voor elk geselecteerd cohort.
Overzicht van modellen en metrische gegevens voor redelijkheid
Het onderdeel overzicht van het model biedt een uitgebreide set metrische gegevens over prestaties en redelijkheid voor het evalueren van uw model, samen met belangrijke metrische gegevens over de prestaties die verschillen tussen de prestaties en de opgegeven functies en cohorten van gegevenssets.
Cohorten van gegevenssets
In het deelvenster Cohorten van gegevenssets kunt u uw model onderzoeken door de modelprestaties van verschillende door de gebruiker opgegeven cohorten van gegevenssets te vergelijken (toegankelijk via het pictogram Cohortinstellingen in de rechterbovenhoek van het dashboard).

- Help me metrische gegevens te kiezen: selecteer dit pictogram om een deelvenster te openen met meer informatie over welke metrische gegevens voor modelprestaties beschikbaar zijn om in de tabel te worden weergegeven. U kunt eenvoudig aanpassen welke metrische gegevens u wilt weergeven met behulp van de vervolgkeuzelijst met meerdere selecties om metrische prestatiegegevens te selecteren en deselecteren.
- Heatmap weergeven: In- en uitschakelen om heatmapvisualisatie in de tabel weer te geven of te verbergen. De kleurovergang van de heatmap komt overeen met het bereik dat is genormaliseerd tussen de laagste waarde en de hoogste waarde in elke kolom.
- Tabel met metrische gegevens voor elk cohort van de gegevensset: kolommen van gegevenssetcohorten weergeven, de steekproefgrootte van elk cohort en de geselecteerde metrische gegevens over modelprestaties voor elk cohort.
- Staafdiagram waarin afzonderlijke metrische gegevens worden gevisualiseerd: Weergave betekent absolute fout in de cohorten voor eenvoudige vergelijking.
- Kies metrische waarde (x-as):selecteer deze knop om te kiezen welke metrische gegevens u wilt weergeven in het staafdiagram.
- Kies cohorten (y-as): selecteer deze knop om te kiezen welke cohorten u wilt weergeven in het staafdiagram. Functiecohortselectie kan worden uitgeschakeld, tenzij u eerst de gewenste functies opgeeft op het tabblad Functiecohort van het onderdeel.
Selecteer Help bij het kiezen van metrische gegevens om een deelvenster te openen met een lijst met metrische gegevens over modelprestaties en de bijbehorende definities, zodat u de juiste metrische gegevens kunt selecteren om weer te geven.
| Machine learning-scenario | Metrische gegevens voor |
|---|---|
| Regressie | Gemiddelde absolute fout, gemiddelde kwadratische fout, R-kwadraat, gemiddelde voorspelling. |
| Classificatie | Nauwkeurigheid, precisie, relevante overeenkomsten, F1-score, fout-positieve snelheid, fout-negatieve rente, selectiefrequentie. |
Functiecohorten
In het deelvenster Functiecohorten kunt u uw model onderzoeken door modelprestaties te vergelijken met door de gebruiker opgegeven gevoelige en niet-gevoelige functies (bijvoorbeeld prestaties voor verschillende cohorten op geslacht, ras en inkomensniveau).

Help mij metrische gegevens te kiezen: selecteer dit pictogram om een deelvenster te openen met meer informatie over welke metrische gegevens beschikbaar zijn om in de tabel te worden weergegeven. U kunt eenvoudig aanpassen welke metrische gegevens u wilt weergeven met behulp van de vervolgkeuzelijst met meerdere selecties om metrische prestatiegegevens te selecteren en deselecteren.
Help me functies te kiezen: selecteer dit pictogram om een deelvenster te openen met meer informatie over welke functies beschikbaar zijn om te worden weergegeven in de tabel, met descriptors van elke functie en hun binning-mogelijkheid (zie hieronder). U kunt eenvoudig aanpassen welke functies u wilt weergeven met behulp van de vervolgkeuzelijst met meerdere selecties om ze te selecteren en de selectie ervan op te heffen.
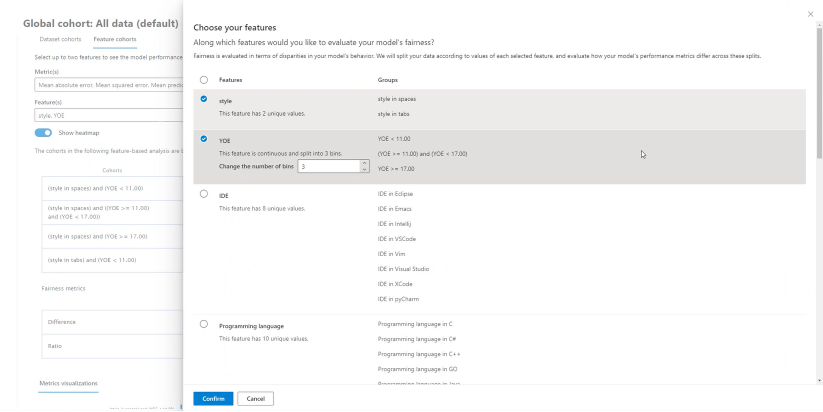
Heatmap weergeven: In- en uitschakelen om een heatmapvisualisatie weer te geven. De kleurovergang van de heatmap komt overeen met het bereik dat is genormaliseerd tussen de laagste waarde en de hoogste waarde in elke kolom.
Tabel met metrische gegevens voor elk functiecohort: een tabel met kolommen voor functiecohorten (subcohort van uw geselecteerde functie), steekproefgrootte van elk cohort en de geselecteerde metrische gegevens voor modelprestaties voor elk functiecohort.
Fairness metrics/disparity metrics: een tabel die overeenkomt met de tabel met metrische gegevens en toont het maximale verschil of de maximale verhouding in prestatiescores tussen twee functiecohorten.
Staafdiagram waarin afzonderlijke metrische gegevens worden gevisualiseerd: Weergave betekent absolute fout in de cohorten voor eenvoudige vergelijking.
Kies cohorten (y-as): selecteer deze knop om te kiezen welke cohorten u wilt weergeven in het staafdiagram.
Als u Cohorten kiezen selecteert, wordt een deelvenster geopend met een optie om een vergelijking weer te geven van geselecteerde gegevensset cohorten of functiecohorten, afhankelijk van wat u selecteert in de vervolgkeuzelijst met meerdere selecties eronder. Selecteer Bevestigen om de wijzigingen op te slaan in de staafdiagramweergave.
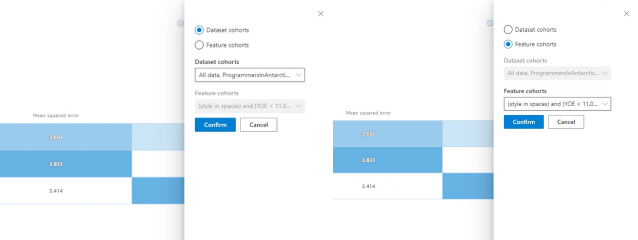
Kies metrische waarde (x-as):selecteer deze knop om te kiezen welke metrische waarde u wilt weergeven in het staafdiagram.


Gegevensanalyse
Met het onderdeel gegevensanalyse ziet u in het deelvenster Tabelweergave een tabelweergave van uw gegevensset voor alle functies en rijen.
In het deelvenster Grafiekweergave ziet u aggregaties en afzonderlijke diagrammen van gegevenspunten. U kunt gegevensstatistieken langs de x-as en y-as analyseren met behulp van filters zoals voorspeld resultaat, gegevenssetfuncties en foutgroepen. Deze weergave helpt u inzicht te hebben in oververtegenwoordigdheid en ondervertegenwoordigdheid in uw gegevensset.

Selecteer een cohort van een gegevensset om te verkennen: geef op voor welke gegevensset u gegevensstatistieken wilt weergeven in de lijst met cohorten waarvoor u gegevensstatistieken wilt weergeven.
X-as: Geeft het type waarde weer dat horizontaal wordt weergegeven. Wijzig de waarden door de knop te selecteren om een zijpaneel te openen.
Y-as: Geeft het type waarde weer dat verticaal wordt weergegeven. Wijzig de waarden door de knop te selecteren om een zijpaneel te openen.
Grafiektype: Hiermee geeft u het grafiektype op. Kies tussen aggregaties (staafdiagrammen) of afzonderlijke gegevenspunten (spreidingsplot).
Door de optie Afzonderlijke gegevenspunten onder Grafiektype te selecteren, kunt u overschakelen naar een niet-samengevoegde weergave van de gegevens met de beschikbaarheid van een kleuras.

Functiebelangen (modeluitleg)
Met behulp van het onderdeel modeluitleg kunt u zien welke functies het belangrijkst waren in de voorspellingen van uw model. U kunt bekijken welke functies van invloed zijn op de voorspelling van uw model in het deelvenster Urgentie van statistische functies of het weergeven van de urgentie van functies voor afzonderlijke gegevenspunten in het deelvenster Prioriteit van afzonderlijke functies.
Belangrijke functies aggregeren (globale uitleg)

Top k-functies: bevat de belangrijkste globale functies voor een voorspelling en stelt u in staat om deze te wijzigen met behulp van een schuifregelaar.
Het belang van een statistische functie: visualiseert het gewicht van elke functie bij het beïnvloeden van modelbeslissingen voor alle voorspellingen.
Sorteren op: Hiermee kunt u selecteren op welk cohort de urgentiegrafiek van de statistische functie moet worden gesorteerd.
Grafiektype: Hiermee kunt u kiezen tussen een staafdiagramweergave van gemiddelde urgenties voor elke functie en een boxplot met urgenties voor alle gegevens.
Wanneer u een van de functies in het staafdiagram selecteert, wordt de afhankelijkheidsplot gevuld, zoals wordt weergegeven in de volgende afbeelding. In het afhankelijkheidsplot ziet u de relatie tussen de waarden van een functie en de bijbehorende waarde voor functiebelang, die van invloed zijn op de voorspelling van het model.
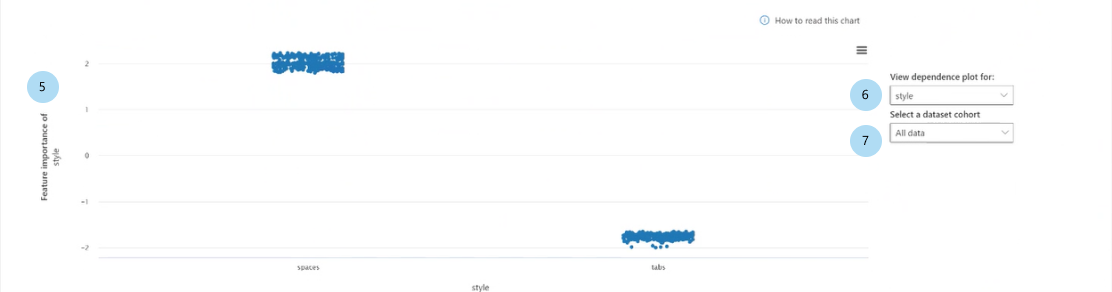
Functiebelang van [functie] (regressie) of functiebelang van [functie] op [voorspelde klasse] (classificatie): hiermee wordt het belang van een bepaalde functie in de voorspellingen uitgezet. Voor regressiescenario's zijn de urgentiewaarden in termen van de uitvoer, dus positief kenmerkbelang betekent dat het positief heeft bijgedragen aan de uitvoer. Het tegenovergestelde is van toepassing op het belang van negatieve functies. Voor classificatiescenario's betekenen positieve functiebelangen dat de functiewaarde bijdraagt aan de voorspelde klasse die wordt aangegeven in de titel van de y-as. Negatieve functiebelang betekent dat deze bijdraagt aan de voorspelde klasse.
Bekijk de afhankelijkheidsplot voor: Selecteert de functie waarvan u de urgenties wilt uitzetten.
Selecteer een cohort van een gegevensset: selecteert het cohort waarvan u de urgenties wilt uitzetten.

Belang van afzonderlijke functies (lokale uitleg)
In de volgende afbeelding ziet u hoe functies van invloed zijn op de voorspellingen die zijn gedaan op specifieke gegevenspunten. U kunt maximaal vijf gegevenspunten kiezen om de urgentie van functies te vergelijken.

Puntselectietabel: bekijk uw gegevenspunten en selecteer maximaal vijf punten om weer te geven in de functiebelangplot of de ICE-plot onder de tabel.

Belangrijke tekenfunctie: een staafdiagram van het belang van elke functie voor de voorspelling van het model op de geselecteerde gegevenspunten.
- Top k-functies: hiermee kunt u het aantal functies opgeven waarvoor u urgenties wilt weergeven met behulp van een schuifregelaar.
- Sorteren op: Hiermee kunt u het punt selecteren (van de punten die hierboven zijn gecontroleerd) waarvan de urgenties van functies in aflopende volgorde worden weergegeven in de grafiek met het belang van de functie.
- Absolute waarden weergeven: schakel deze optie in om het staafdiagram te sorteren op de absolute waarden. Hierdoor kunt u de meest impactvolle functies zien, ongeacht hun positieve of negatieve richting.
- Staafdiagram: Geeft het belang weer van elke functie in de gegevensset voor de modelvoorspelling van de geselecteerde gegevenspunten.
Afzonderlijke voorwaardelijke verwachting (ICE): schakelt over naar de ICE-plot, waarin modelvoorspellingen worden weergegeven voor een bereik van waarden van een bepaalde functie.

- Min (numerieke kenmerken): hiermee geeft u de ondergrens op van het bereik van voorspellingen in de ICE-plot.
- Max (numerieke kenmerken): Hiermee geeft u de bovengrens van het bereik van voorspellingen in de ICE-plot.
- Stappen (numerieke functies): hiermee geeft u het aantal punten op om voorspellingen voor binnen het interval weer te geven.
- Functiewaarden (categorische functies): hiermee geeft u op voor welke categorische functiewaarden voorspellingen moeten worden weergegeven.
- Functie: Hiermee geeft u de functie op waarvoor u voorspellingen moet doen.
Contrafactuele what-if
Contrafactuele analyse biedt een diverse set wat-als-voorbeelden die worden gegenereerd door het wijzigen van de waarden van functies minimaal om de gewenste voorspellingsklasse (classificatie) of het gewenste bereik (regressie) te produceren.

Puntselectie: Hiermee selecteert u het punt om een contrafactueel item te maken en weer te geven in de grafiek met de bovenste classificatiefuncties eronder.
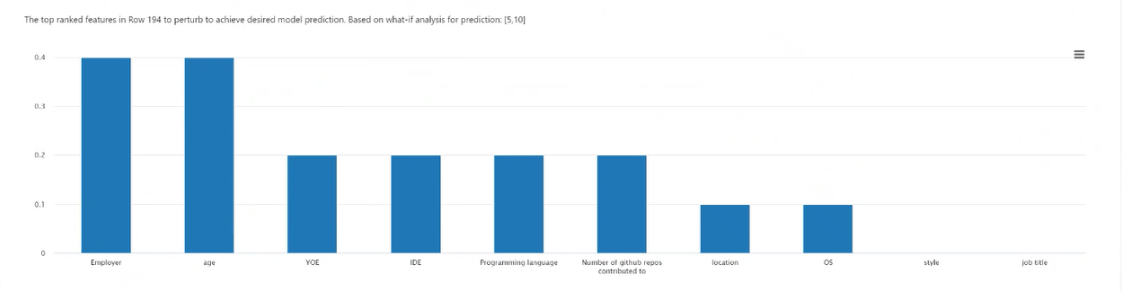
Meest gerangschikte functiesplot: Geeft, in aflopende volgorde van gemiddelde frequentie, de functies te verstoren om een diverse set contrafactuals van de gewenste klasse te maken. U moet ten minste 10 verschillende contrafactuals per gegevenspunt genereren om deze grafiek in te schakelen, omdat er een gebrek aan nauwkeurigheid is met een kleiner aantal contrafactuals.
Geselecteerd gegevenspunt: hiermee wordt dezelfde actie uitgevoerd als de puntselectie in de tabel, behalve in een vervolgkeuzelijst.
Gewenste klasse voor counterfactual(s): hiermee geeft u de klasse of het bereik op waarvoor contrafactuals moeten worden gegenereerd.
What-if contrafactual maken: hiermee opent u een deelvenster voor het maken van een contrafactueel wat-als-gegevenspunt.
Selecteer de knop Wat-als-items maken om een volledig venstervenster te openen.
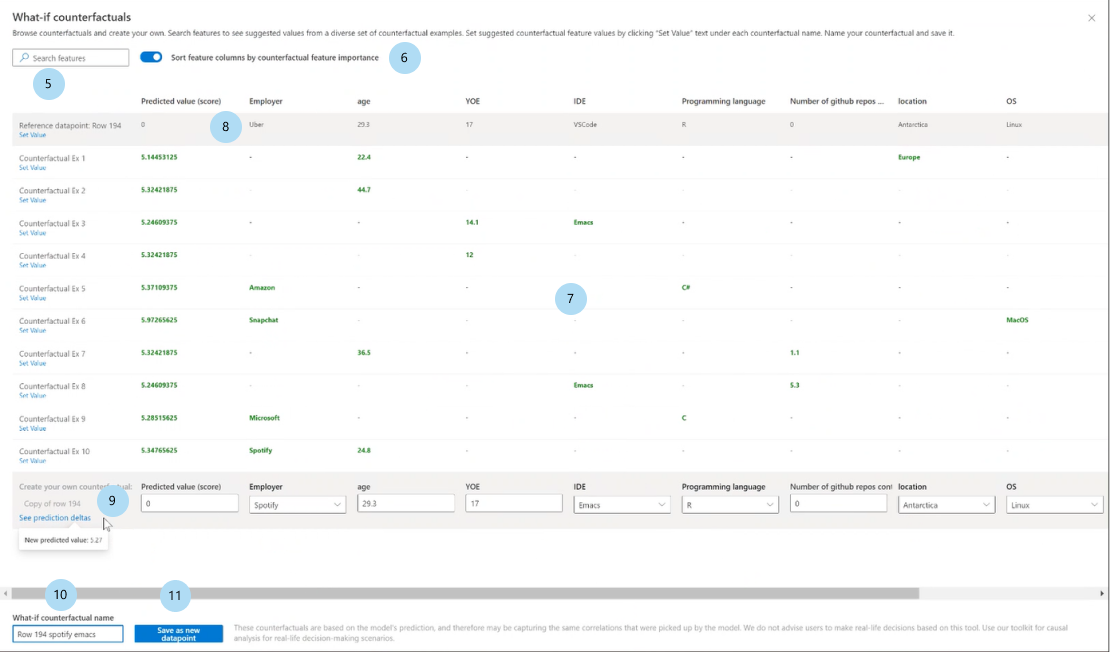
Zoekfuncties: hiermee vindt u functies om waarden te bekijken en te wijzigen.
Sorteer contrafactueel op gerangschikte functies: sorteert contrafactuele voorbeelden in volgorde van verstoringseffect. (Zie ookMeest gerangschikte functies plot, eerder besproken.)
Contrafactuele voorbeelden: een lijst met functiewaarden van voorbeeldtellers met de gewenste klasse of het gewenste bereik. De eerste rij is het oorspronkelijke referentiegegevenspunt. Selecteer Waarde instellen om alle waarden van uw eigen contrafactuele gegevenspunt in de onderste rij in te stellen met de waarden van het vooraf gegenereerde contrafactuele voorbeeld.
Voorspelde waarde of klasse: geeft een lijst weer van de modelvoorspelling van de klasse van een contrafactual op basis van deze gewijzigde functies.
Maak uw eigen contrafactual: hiermee kunt u uw eigen functies verstoren om de contrafactual te wijzigen. Functies die zijn gewijzigd van de oorspronkelijke functiewaarde, worden aangegeven door de titel vetgedrukt (bijvoorbeeld werkgever en programmeertaal). Selecteer Voorspellingsverschillen weergeven om het verschil in de nieuwe voorspellingswaarde van het oorspronkelijke gegevenspunt weer te geven.
Wat-als-contrafactuele naam: Hiermee kunt u de contrafactueel unieke naam geven.
Opslaan als nieuw gegevenspunt: slaat het contrafactueel op dat u hebt gemaakt.


Causale analyse
In de volgende secties wordt beschreven hoe u de causale analyse voor uw gegevensset kunt lezen over bepaalde door de gebruiker opgegeven behandelingen.
Causale effecten aggregeren
Selecteer het tabblad Causale effecten aggregeren van het causale analyseonderdeel om de gemiddelde causale effecten voor vooraf gedefinieerde behandelfuncties weer te geven (de functies die u wilt behandelen om uw resultaat te optimaliseren).
Notitie
Globale cohortfunctionaliteit wordt niet ondersteund voor het causale analyseonderdeel.

Directe tabel met causaal effect: geeft het causale effect weer van elke functie die is samengevoegd op de volledige gegevensset en de bijbehorende betrouwbaarheidsstatistieken.
- Continue behandelingen: Gemiddeld zal het verhogen van deze functie met één eenheid ertoe leiden dat de waarschijnlijkheid van klasse toeneemt met X-eenheden, waarbij X het causale effect is.
- Binaire behandelingen: Gemiddeld in dit voorbeeld zorgt het inschakelen van deze functie ervoor dat de waarschijnlijkheid van klasse toeneemt met X-eenheden, waarbij X het oorzakelijke effect is.
Direct aggregate causal effect whisker plot: visualiseert de causale effecten en betrouwbaarheidsintervallen van de punten in de tabel.
Individuele causale effecten en causale what-if
Als u een gedetailleerd overzicht wilt krijgen van causale effecten op een afzonderlijk gegevenspunt, schakelt u over naar het afzonderlijke causale what-if-tabblad .

- X-as: Hiermee selecteert u de functie die u wilt uitzetten op de x-as.
- Y-as: Hiermee selecteert u de functie die u wilt uitzetten op de y-as.
- Afzonderlijk causaal spreidingsplot: visualiseert punten in de tabel als een spreidingsplot om gegevenspunten te selecteren voor het analyseren van causale wat-als en het bekijken van de afzonderlijke causale effecten eronder.
- Nieuwe behandelingswaarde instellen:
- (numeriek): toont een schuifregelaar om de waarde van de numerieke functie te wijzigen als een echte interventie.
- (categorisch): Toont een vervolgkeuzelijst om de waarde van de categorische functie te selecteren.
Behandelingsbeleid
Selecteer het tabblad Behandelingsbeleid om over te schakelen naar een weergave om te helpen bij het bepalen van echte interventies en het weergeven van behandelingen die moeten worden toegepast om een bepaald resultaat te bereiken.

Behandelfunctie instellen: Selecteert een functie die u wilt wijzigen als een echte interventie.
Aanbevolen globaal behandelingsbeleid: geeft aanbevolen interventies weer voor gegevenscohorten om de doelfunctiewaarde te verbeteren. De tabel kan van links naar rechts worden gelezen, waarbij de segmentatie van de gegevensset eerst in rijen en vervolgens in kolommen staat. Voor bijvoorbeeld 658 personen waarvan de werkgever geen Snapchat is en waarvan de programmeertaal niet JavaScript is, is het aanbevolen behandelbeleid om het aantal GitHub-opslagplaatsen te verhogen waaraan is bijgedragen.
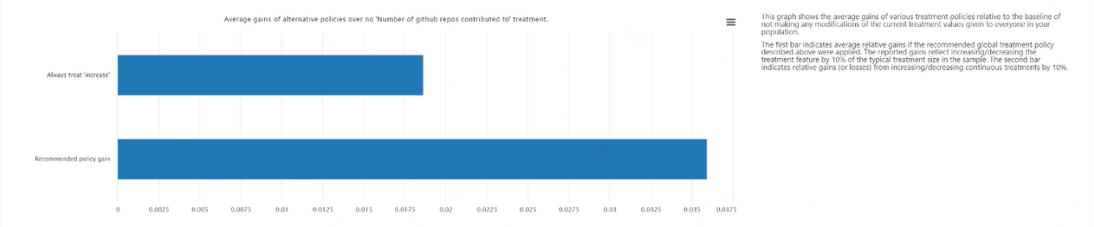
Gemiddelde winsten van alternatief beleid ten opzichte van het altijd toepassen van een behandeling: zet de doelfunctiewaarde in een staafdiagram van de gemiddelde winst in uw resultaat voor het bovenstaande aanbevolen behandelingsbeleid versus het altijd toepassen van een behandeling.
Aanbevolen individueel behandelingsbeleid:
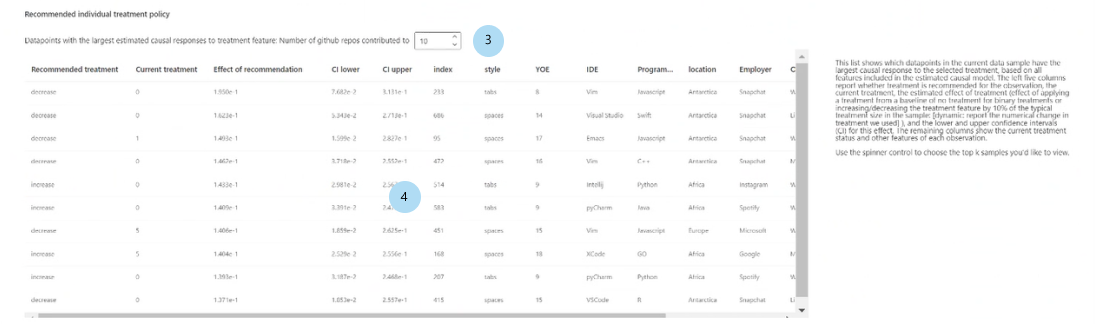
Top k-gegevenspuntmonsters weergeven die zijn gerangschikt op causale effecten voor aanbevolen behandelingsfuncties: Selecteert het aantal gegevenspunten dat in de tabel moet worden weergegeven.
Aanbevolen tabel voor individueel behandelingsbeleid: Lijsten, in aflopende volgorde van causaal effect, de gegevenspunten waarvan de doelfuncties het meest zouden worden verbeterd door een interventie.


Volgende stappen
- Uw verantwoorde AI-inzichten samenvatten en delen met de Responsible AI-scorecard als PDF-export.
- Meer informatie over de concepten en technieken achter het verantwoordelijke AI-dashboard.
- Bekijk voorbeeld-YAML- en Python-notebooks om een verantwoordelijk AI-dashboard te genereren met YAML of Python.
- Verken de functies van het dashboard Responsible AI via deze interactieve AI Lab-webdemo.
- Meer informatie over hoe u het verantwoordelijke AI-dashboard en scorecard kunt gebruiken om fouten in gegevens en modellen op te sporen en betere besluitvorming te informeren in dit blogbericht van de tech community.
- Meer informatie over hoe het verantwoordelijke AI-dashboard en scorecard werden gebruikt door de UK National Health Service (NHS) in een echt klantverhaal.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor