Open Source-basismodellen gebruiken die zijn samengesteld door Azure Machine Learning
In dit artikel leert u hoe u basismodellen in de modelcatalogus nauwkeurig kunt afstemmen, evalueren en implementeren.
U kunt snel elk vooraf getraind model testen met behulp van het formulier Voorbeelddeductie op de modelkaart, met uw eigen voorbeeldinvoer om het resultaat te testen. Daarnaast bevat de modelkaart voor elk model een korte beschrijving van het model en koppelingen naar voorbeelden voor op code gebaseerde deductie, het verfijnen en evalueren van het model.
Basismodellen evalueren met behulp van uw eigen testgegevens
U kunt een Foundation-model evalueren op basis van uw testgegevensset, met behulp van het formulier Ui evalueren of met behulp van de codevoorbeelden, gekoppeld vanaf de modelkaart.
Evalueren met behulp van de studio
U kunt het modelformulier Evalueren aanroepen door de knop Evalueren te selecteren op de modelkaart voor elk basismodel.
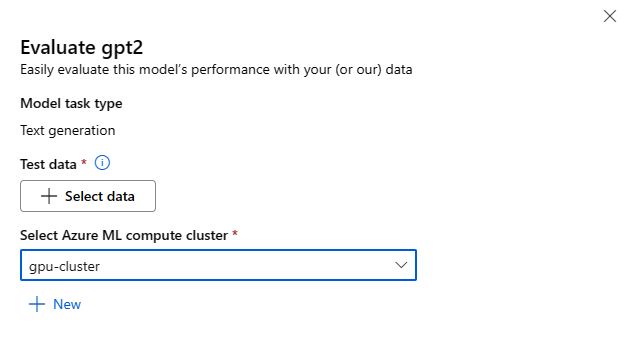
Elk model kan worden geëvalueerd voor de specifieke deductietaak waarvoor het model wordt gebruikt.
Testgegevens:
- Geef de testgegevens door die u wilt gebruiken om uw model te evalueren. U kunt ervoor kiezen om een lokaal bestand (in JSONL-indeling) te uploaden of een bestaande geregistreerde gegevensset in uw werkruimte te selecteren.
- Nadat u de gegevensset hebt geselecteerd, moet u de kolommen uit uw invoergegevens toewijzen op basis van het schema dat nodig is voor de taak. Wijs bijvoorbeeld de kolomnamen toe die overeenkomen met de toetsen 'zin' en 'label' voor tekstclassificatie

Compute:
Geef het Azure Machine Learning Compute-cluster op dat u wilt gebruiken voor het afstemmen van het model. Evaluatie moet worden uitgevoerd op GPU-rekenkracht. Zorg ervoor dat u voldoende rekenquotum hebt voor de reken-SKU's die u wilt gebruiken.
Selecteer Voltooien in het formulier Evalueren om uw evaluatietaak in te dienen. Zodra de taak is voltooid, kunt u metrische evaluatiegegevens voor het model bekijken. Op basis van de metrische evaluatiegegevens kunt u besluiten of u het model wilt verfijnen met behulp van uw eigen trainingsgegevens. Daarnaast kunt u beslissen of u het model wilt registreren en op een eindpunt wilt implementeren.
Evalueren met behulp van voorbeelden op basis van code
Om gebruikers in staat te stellen aan de slag te gaan met modelevaluatie, hebben we voorbeelden (zowel Python-notebooks als CLI-voorbeelden) gepubliceerd in de evaluatievoorbeelden in de Git-opslagplaats azureml-voorbeelden. Elke modelkaart bevat ook koppelingen naar evaluatievoorbeelden voor bijbehorende taken
Basismodellen verfijnen met behulp van uw eigen trainingsgegevens
Als u de modelprestaties in uw workload wilt verbeteren, kunt u een basismodel afstellen met behulp van uw eigen trainingsgegevens. U kunt deze basismodellen eenvoudig verfijnen met behulp van de instellingen in de studio of met behulp van de codegebaseerde voorbeelden die zijn gekoppeld aan de modelkaart.
Verfijnen met behulp van de studio
U kunt het formulier voor het afstemmen van instellingen aanroepen door op de knop Verfijnen te klikken op de modelkaart voor elk basismodel.
Verfijn Instellingen:
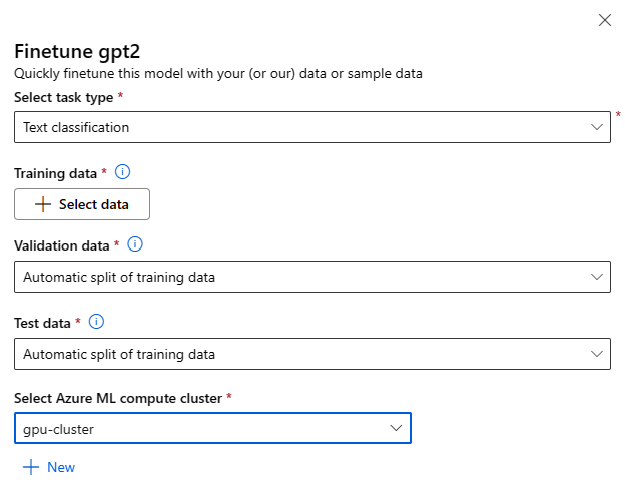
Taaktype verfijnen
- Elk vooraf getraind model uit de modelcatalogus kan worden afgestemd op een specifieke set taken (bijvoorbeeld: tekstclassificatie, tokenclassificatie, vraagantwoording). Selecteer de taak die u wilt gebruiken in de vervolgkeuzelijst.
Trainingsgegevens
Geef de trainingsgegevens door die u wilt gebruiken om uw model af te stemmen. U kunt ervoor kiezen om een lokaal bestand (in JSONL-, CSV- of TSV-indeling) te uploaden of een bestaande geregistreerde gegevensset in uw werkruimte te selecteren.
Nadat u de gegevensset hebt geselecteerd, moet u de kolommen uit uw invoergegevens toewijzen op basis van het schema dat nodig is voor de taak. Bijvoorbeeld: de kolomnamen toewijzen die overeenkomen met de sleutels 'zin' en 'label' voor tekstclassificatie

- Validatiegegevens: geef de gegevens door die u wilt gebruiken om uw model te valideren. Als u Automatisch splitsen selecteert, wordt een automatische splitsing van trainingsgegevens gereserveerd voor validatie. U kunt ook een andere validatiegegevensset opgeven.
- Testgegevens: Geef de testgegevens door die u wilt gebruiken om uw nauwkeurig afgestemde model te evalueren. Als u Automatisch splitsen selecteert, wordt een automatische splitsing van trainingsgegevens voor de test gereserveerd.
- Compute: Geef het Azure Machine Learning Compute-cluster op dat u wilt gebruiken voor het verfijnen van het model. Het afstemmen moet worden uitgevoerd op GPU-rekenkracht. We raden u aan reken-SKU's te gebruiken met A100/V100 GPU's bij het afstemmen. Zorg ervoor dat u voldoende rekenquotum hebt voor de reken-SKU's die u wilt gebruiken.
- Selecteer Voltooien in het formulier afstemmen om uw taak voor het afstemmen te verzenden. Zodra de taak is voltooid, kunt u metrische evaluatiegegevens bekijken voor het nauwkeurig afgestemde model. Vervolgens kunt u de nauwkeurig afgestemde modeluitvoer registreren door de taak voor het afstemmen en dit model implementeren op een eindpunt voor deductie.
Verfijnen met behulp van voorbeelden op basis van code
Op dit moment biedt Azure Machine Learning ondersteuning voor het afstemmen van modellen voor de volgende taaltaken:
- Tekstclassificatie
- Tokenclassificatie
- Vragen beantwoorden
- Samenvatting
- Vertaling
Om gebruikers in staat te stellen snel aan de slag te gaan met het afstemmen, hebben we voorbeelden (zowel Python-notebooks als CLI-voorbeelden) gepubliceerd voor elke taak in de Git-opslagplaats Finetune-voorbeelden van azureml-voorbeelden. Elke modelkaart bevat ook koppelingen naar voorbeelden voor het afstemmen van ondersteunde taken.
Basismodellen implementeren op eindpunten voor deductie
U kunt basismodellen (zowel vooraf getrainde modellen uit de modelcatalogus als nauwkeurig afgestemde modellen implementeren, zodra ze zijn geregistreerd in uw werkruimte) naar een eindpunt dat vervolgens kan worden gebruikt voor deductie. Implementatie naar zowel serverloze API's als beheerde berekeningen wordt ondersteund. U kunt deze modellen implementeren met behulp van de wizard Ui implementeren of met behulp van de codevoorbeelden die zijn gekoppeld aan de modelkaart.
Implementeren met behulp van de studio
U kunt het formulier Ui implementeren aanroepen door de knop Implementeren te selecteren op de modelkaart voor elk basismodel en serverloze API te selecteren met Azure AI Content Safety of Managed Compute zonder Azure AI Content Safety

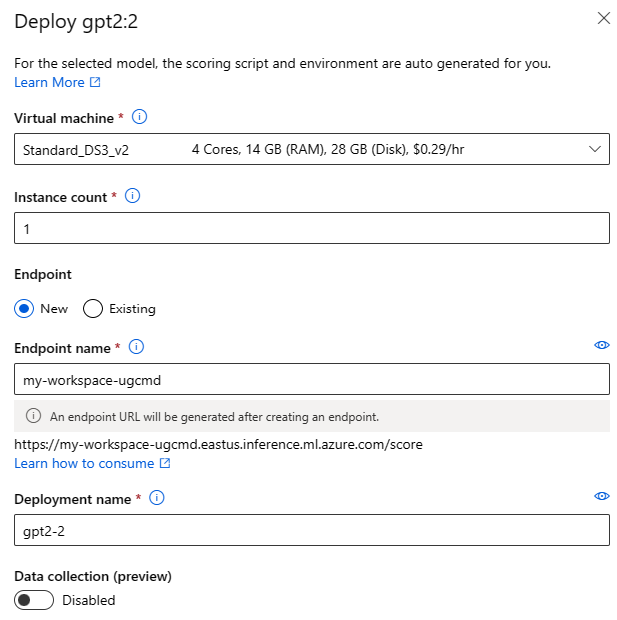
Implementatie-instellingen
Omdat het scorescript en de omgeving automatisch worden opgenomen in het basismodel, hoeft u alleen de SKU van de virtuele machine op te geven die moet worden gebruikt, het aantal exemplaren en de eindpuntnaam die voor de implementatie moet worden gebruikt.
Gedeeld quotum
Als u een Llama-2-model implementeert, Phi, Nemotron, Mistral, Dolly of Deci-DeciLM-model uit de modelcatalogus, maar niet voldoende quotum beschikbaar hebt voor de implementatie, kunt u met Azure Machine Learning een quotum van een gedeelde quotumgroep gedurende een beperkte tijd gebruiken. Zie Gedeeld quotum voor Azure Machine Learning voor meer informatie over gedeelde quota.

Implementeren met behulp van voorbeelden op basis van code
Om gebruikers in staat te stellen snel aan de slag te gaan met implementatie en deductie, hebben we voorbeelden gepubliceerd in de deductievoorbeelden in de Git-opslagplaats azureml-examples. De gepubliceerde voorbeelden bevatten Python-notebooks en CLI-voorbeelden. Elke modelkaart bevat ook koppelingen naar deductievoorbeelden voor realtime en Batch-deductie.
Basismodellen importeren
Als u een opensourcemodel wilt gebruiken dat niet is opgenomen in de modelcatalogus, kunt u het model importeren uit Hugging Face in uw Azure Machine Learning-werkruimte. Hugging Face is een opensource-bibliotheek voor natuurlijke taalverwerking (NLP) die vooraf getrainde modellen biedt voor populaire NLP-taken. Op dit moment biedt het importeren van modellen ondersteuning voor het importeren van modellen voor de volgende taken, zolang het model voldoet aan de vereisten die worden vermeld in het notebook model importeren:
- fill-mask
- tokenclassificatie
- vragen beantwoorden
- samenvatting
- tekstgeneratie
- tekstclassificatie
- vertaling
- afbeeldingsclassificatie
- tekst-naar-afbeelding
Notitie
Modellen van Hugging Face zijn onderhevig aan licentievoorwaarden van derden die beschikbaar zijn op de detailpagina van het Hugging Face-model. Het is uw verantwoordelijkheid om te voldoen aan de licentievoorwaarden van het model.
U kunt de knop Importeren in de rechterbovenhoek van de modelcatalogus selecteren om het notebook model importeren te gebruiken.
Het notebook voor het importeren van modellen is hier ook opgenomen in de git-opslagplaats azureml-examples.
Als u het model wilt importeren, moet u het MODEL_ID model doorgeven dat u wilt importeren uit Hugging Face. Blader door modellen op de Hugging Face-hub en identificeer het model dat u wilt importeren. Zorg ervoor dat het taaktype van het model een van de ondersteunde taaktypen is. Kopieer de model-id, die beschikbaar is in de URI van de pagina of kan worden gekopieerd met behulp van het kopieerpictogram naast de modelnaam. Wijs deze toe aan de variabele 'MODEL_ID' in het notebook modelimport. Voorbeeld:
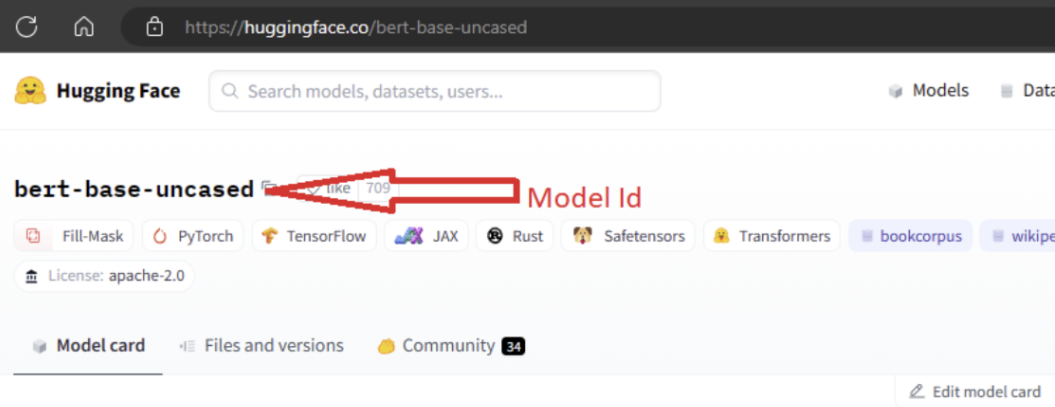
U moet rekenkracht opgeven voor het importeren van het model dat moet worden uitgevoerd. Als u het model importeren uitvoert, wordt het opgegeven model geïmporteerd uit Hugging Face en geregistreerd in uw Azure Machine Learning-werkruimte. U kunt dit model vervolgens verfijnen of implementeren op een eindpunt voor deductie.
Meer informatie
- Verken de modelcatalogus in Azure Machine Learning-studio. U hebt een Azure Machine Learning-werkruimte nodig om de catalogus te verkennen.
- De modelcatalogus en verzamelingen verkennen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor