Apache Spark gebruiken (mogelijk gemaakt door Azure Synapse Analytics) in uw machine learning-pijplijn (afgeschaft)
VAN TOEPASSING OP: Python SDK azureml v1
Python SDK azureml v1
Waarschuwing
De Integratie van Azure Synapse Analytics met Azure Machine Learning, beschikbaar in Python SDK v1, is afgeschaft. Gebruikers kunnen nog steeds Synapse-werkruimte gebruiken, geregistreerd bij Azure Machine Learning, als een gekoppelde service. Een nieuwe Synapse-werkruimte kan echter niet meer worden geregistreerd bij Azure Machine Learning als een gekoppelde service. We raden u aan om serverloze Spark-rekenkracht en gekoppelde Synapse Spark-pools te gebruiken, beschikbaar in CLI v2 en Python SDK v2. U vindt meer informatie op https://aka.ms/aml-spark.
In dit artikel leert u hoe u Apache Spark-pools gebruikt die worden mogelijk gemaakt door Azure Synapse Analytics als rekendoel voor een stap voor het voorbereiden van gegevens in een Azure Machine Learning-pijplijn. U leert hoe één pijplijn rekenresources kan gebruiken die geschikt zijn voor de specifieke stap, bijvoorbeeld gegevensvoorbereiding of training. U leert ook hoe gegevens worden voorbereid voor de Spark-stap en hoe deze worden doorgegeven aan de volgende stap.
Vereisten
Een Azure Machine Learning-werkruimte maken om al uw pijplijnbronnen op te slaan
Configureer uw ontwikkelomgeving om de Azure Machine Learning SDK te installeren of gebruik een Azure Machine Learning-rekenproces met de SDK die al is geïnstalleerd
Maak een Azure Synapse Analytics-werkruimte en Apache Spark-pool. Ga voor meer informatie naar Quickstart: Een serverloze Apache Spark-pool maken met behulp van Synapse Studio
Uw Azure Machine Learning-werkruimte en Azure Synapse Analytics-werkruimte koppelen
U maakt en beheert uw Apache Spark-pools in een Azure Synapse Analytics-werkruimte. Als u een Apache Spark-pool wilt integreren met een Azure Machine Learning-werkruimte, moet u een koppeling maken naar de Azure Synapse Analytics-werkruimte. Zodra u uw Azure Machine Learning-werkruimte en uw Azure Synapse Analytics-werkruimten hebt gekoppeld, kunt u een Apache Spark-pool koppelen aan
Python SDK, zoals later uitgelegd
Arm-sjabloon (Azure Resource Manager). Ga voor meer informatie naar de ARM-voorbeeldsjabloon
- U kunt de opdrachtregel gebruiken om de ARM-sjabloon te volgen, de gekoppelde service toe te voegen en de Apache Spark-pool te koppelen aan dit codevoorbeeld:
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
Belangrijk
Als u een koppeling wilt maken naar de Synapse-werkruimte, moet u de rol Eigenaar van de Synapse-werkruimte krijgen. Controleer uw toegang in de Azure-portal.
De gekoppelde service krijgt tijdens het maken een door het systeem toegewezen beheerde identiteit (SAI). U moet deze koppelingsservice SAI de rol Synapse Apache Spark-beheerder toewijzen vanuit Synapse Studio, zodat deze de Spark-taak kan verzenden (zie Synapse RBAC-roltoewijzingen beheren in Synapse Studio).
U moet de gebruiker van de Azure Machine Learning-werkruimte ook de rol Inzender geven vanuit de Azure-portal voor resourcebeheer.
Haal de koppeling op tussen uw Azure Synapse Analytics-werkruimte en uw Azure Machine Learning-werkruimte
Deze code laat zien hoe u gekoppelde services in uw werkruimte ophaalt:
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
Workspace.from_config() Open eerst uw Azure Machine Learning-werkruimte met de configuratie in het config.json bestand. (Ga voor meer informatie naar Een werkruimteconfiguratiebestand maken). Vervolgens worden met de code alle gekoppelde services afgedrukt die beschikbaar zijn in de werkruimte. LinkedService.get() Haalt ten slotte een gekoppelde service op met de naam 'synapselink1'.
Uw Apache Spark-pool koppelen als rekendoel voor Azure Machine Learning
Als u uw Apache Spark-pool wilt gebruiken om een stap in uw machine learning-pijplijn uit te voeren, moet u deze koppelen als een ComputeTarget voor de pijplijnstap, zoals wordt weergegeven in dit codevoorbeeld:
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
De code configureert eerst de SynapseCompute. Het linked_service argument is het LinkedService object dat u in de vorige stap hebt gemaakt of opgehaald. Het type argument moet zijn SynapseSpark. Het pool_name argument in SynapseCompute.attach_configuration() moet overeenkomen met die van een bestaande pool in uw Azure Synapse Analytics-werkruimte. Ga voor meer informatie over het maken van een Apache Spark-pool in de Azure Synapse Analytics-werkruimte naar Quickstart: Een serverloze Apache Spark-pool maken met behulp van Synapse Studio. Het attach_config type is ComputeTargetAttachConfiguration.
Nadat u de configuratie hebt gemaakt, maakt u een machine learning ComputeTarget door de Workspace waarden door ComputeTargetAttachConfiguration te geven en de naam waarmee u naar de berekening binnen de machine learning-werkruimte wilt verwijzen. De aanroep naar ComputeTarget.attach() is asynchroon, dus het voorbeeld wordt geblokkeerd totdat de aanroep is voltooid.
SynapseSparkStep Een pool maken die gebruikmaakt van de gekoppelde Apache Spark-pool
Met de Spark-voorbeeldtaak in de Apache Spark-pool wordt een eenvoudige machine learning-pijplijn gedefinieerd. Eerst definieert het notebook een stap voor gegevensvoorbereiding, mogelijk gemaakt door de synapse_compute stap die in de vorige stap is gedefinieerd. Vervolgens definieert het notebook een trainingsstap die mogelijk wordt gemaakt door een rekendoel dat geschikter is voor training. Het voorbeeldnotitieblok maakt gebruik van de Survival-database van De Titanic om gegevensinvoer en -uitvoer weer te geven. De gegevens worden niet daadwerkelijk opgeschoond of er wordt een voorspellend model gebruikt. Omdat dit voorbeeld niet echt betrekking heeft op training, maakt de trainingsstap gebruik van een goedkope rekenresource op basis van CPU.
Gegevens stromen naar een machine learning-pijplijn via DatasetConsumptionConfig objecten, die tabelgegevens of sets bestanden kunnen bevatten. De gegevens zijn vaak afkomstig van bestanden in blobopslag in een gegevensarchief van een werkruimte. In dit codevoorbeeld ziet u typische code waarmee invoer wordt gemaakt voor een machine learning-pijplijn:
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
In het codevoorbeeld wordt ervan uitgegaan dat het bestand Titanic.csv zich in blobopslag bevindt. De code laat zien hoe u het bestand zowel als TabularDataset als als als een FileDataset. Deze code is alleen bedoeld voor demonstratiedoeleinden, omdat het verwarrend zou worden om invoer te dupliceren of om één gegevensbron te interpreteren als zowel een tabelresource als een bestand.
Belangrijk
Als u een FileDataset als invoer wilt gebruiken, hebt u ten minste 1.20.0een azureml-core versie van . U kunt dit opgeven met de Environment klas, zoals later besproken. Wanneer een stap is voltooid, kunt u de uitvoergegevens opslaan, zoals wordt weergegeven in dit codevoorbeeld:
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
In dit codevoorbeeld worden de gegevens opgeslagen in een bestand met de datastore naam test. De gegevens zijn beschikbaar in de machine learning-werkruimte als een Dataset, met de naam registered_dataset.
Naast gegevens kan een pijplijnstap python-afhankelijkheden per stap hebben. Daarnaast kunnen afzonderlijke SynapseSparkStep objecten hun exacte Azure Synapse Apache Spark-configuratie opgeven. Om dit weer te geven, geeft het volgende codevoorbeeld aan dat de azureml-core pakketversie ten minste 1.20.0moet zijn. Zoals eerder vermeld, is deze vereiste voor het azureml-core pakket nodig om een FileDataset als invoer te gebruiken.
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
Met deze code wordt één stap in de Azure Machine Learning-pijplijn opgegeven. De environment waarde van deze code stelt een specifieke azureml-core versie in en de code kan indien nodig andere conda- of pip-afhankelijkheden toevoegen.
De SynapseSparkStep zips en uploadt de ./code submap vanaf de lokale computer. Deze map wordt opnieuw gemaakt op de rekenserver en de stap voert het dataprep.py script uit vanuit die map. De inputs en outputs van die stap zijn de step1_input1, step1_input2en step1_output objecten die eerder zijn besproken. De eenvoudigste manier om toegang te krijgen tot deze waarden in het dataprep.py script is door ze te koppelen aan de benoemde argumentswaarden.
De volgende set argumenten voor de SynapseSparkStep constructor bepaalt Apache Spark. Dit compute_target is het 'link1-spark01' doel dat we eerder als rekendoel hebben gekoppeld. De andere parameters geven het geheugen en de kernen op die we willen gebruiken.
In het voorbeeldnotebook wordt deze code gebruikt voor dataprep.py:
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
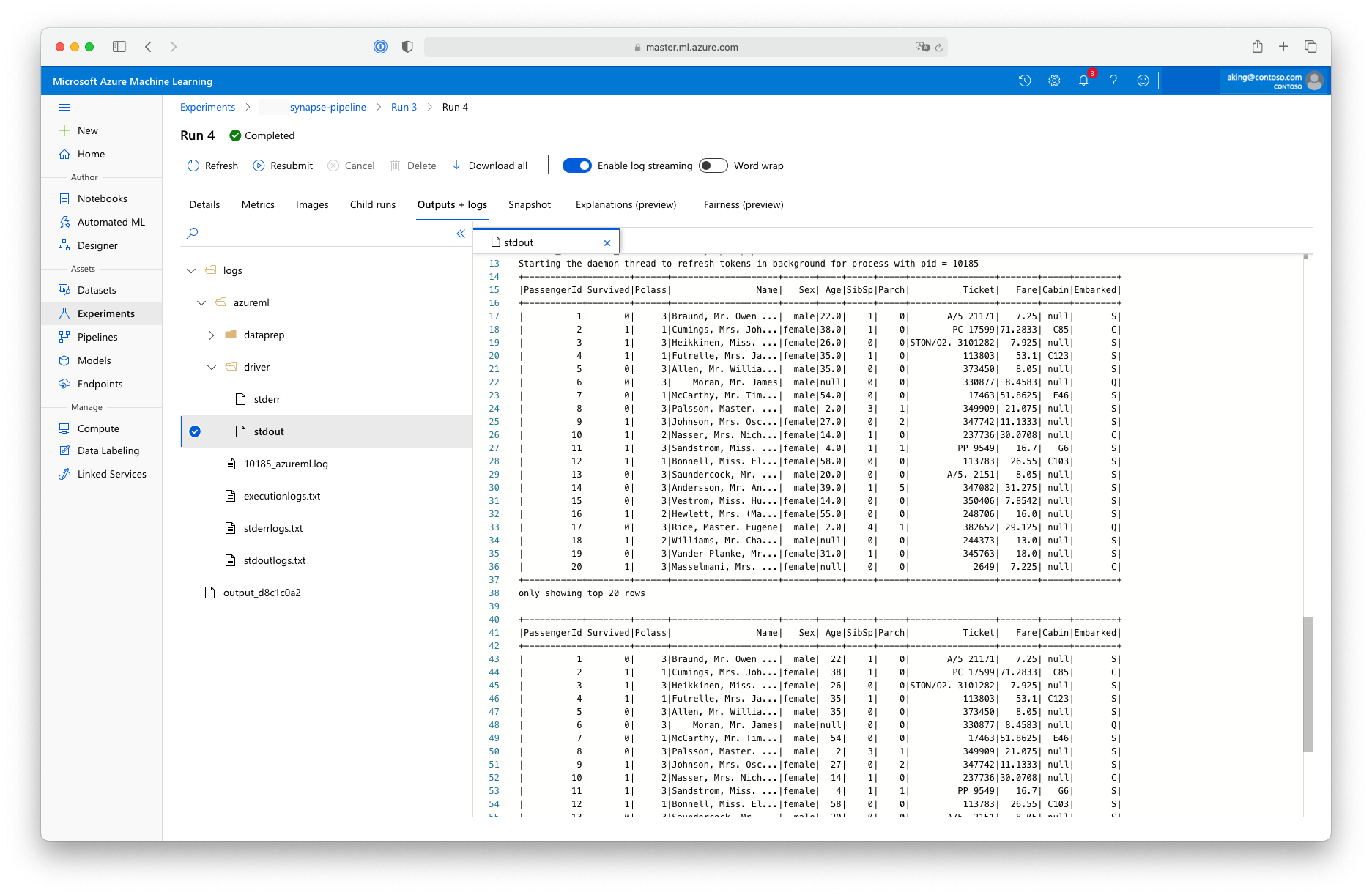
Dit script voor gegevensvoorbereiding voert geen echte gegevenstransformatie uit, maar laat zien hoe u gegevens ophaalt, converteert naar een Spark-dataframe en hoe u enkele eenvoudige Apache Spark-manipulatie uitvoert. Als u de uitvoer in Azure Machine Learning-studio wilt vinden, opent u de onderliggende taak, kiest u het tabblad Uitvoer en logboeken en opent u het logs/azureml/driver/stdout bestand, zoals wordt weergegeven in deze schermopname:
SynapseSparkStep De functie in een pijplijn gebruiken
In het volgende voorbeeld wordt de uitvoer van de SynapseSparkStep gemaakte in de vorige sectie gebruikt. Andere stappen in de pijplijn hebben mogelijk hun eigen unieke omgevingen en kunnen worden uitgevoerd op verschillende rekenresources die geschikt zijn voor de taak. In het voorbeeldnotebook wordt de 'trainingsstap' uitgevoerd op een klein CPU-cluster:
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
Met deze code maakt u indien nodig de nieuwe rekenresource. Vervolgens wordt het step1_output resultaat geconverteerd naar invoer voor de trainingsstap. De as_download() optie betekent dat de gegevens worden verplaatst naar de rekenresource, wat resulteert in snellere toegang. Als de gegevens zo groot zijn dat deze niet op de lokale harde schijf passen, moet u de as_mount() optie gebruiken om de gegevens te streamen met het FUSE bestandssysteem. De compute_target tweede stap is 'cpucluster', niet de 'link1-spark01' resource die u in de stap voor gegevensvoorbereiding hebt gebruikt. In deze stap wordt een eenvoudig train.py script gebruikt in plaats van het dataprep.py script dat u in de vorige stap hebt gebruikt. Het voorbeeldnotebook bevat details van het train.py script.
Nadat u al uw stappen hebt gedefinieerd, kunt u uw pijplijn maken en uitvoeren.
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
Met deze code maakt u een pijplijn die bestaat uit de stap voor gegevensvoorbereiding in Apache Spark-pools, mogelijk gemaakt door Azure Synapse Analytics (step_1) en de trainingsstap (step_2). Azure onderzoekt de gegevensafhankelijkheden tussen de stappen voor het berekenen van de uitvoeringsgrafiek. In dit geval is er slechts één eenvoudige afhankelijkheid. Hier, step2_input noodzakelijkerwijs vereist step1_output.
De pipeline.submit aanroep maakt, indien nodig, een experiment met de naam synapse-pipelineen start asynchroon een taak hierin. Afzonderlijke stappen in de pijplijn worden uitgevoerd als onderliggende taken van deze hoofdtaak en de pagina Experimenten van Studio kan deze stappen controleren en controleren.
Volgende stappen
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor