Een webservice van ML-studio (klassiek) opnieuw ontwerpen in Azure Machine Learning
Belangrijk
Ondersteuning voor Azure Machine Learning Studio (klassiek) eindigt op 31 augustus 2024. U wordt aangeraden op die datum over te stappen naar Azure Machine Learning .
Vanaf 1 december 2021 kunt u geen nieuwe Machine Learning Studio-resources (klassiek) maken (werkruimte- en webserviceplan). Tot en met 31 augustus 2024 kunt u de bestaande Experimenten en webservices van Machine Learning Studio (klassiek) blijven gebruiken. Zie voor meer informatie:
- Migreren naar Azure Machine Learning vanuit Machine Learning Studio (klassiek)
- Wat is Azure Machine Learning?
Machine Learning Studio -documentatie (klassiek) wordt buiten gebruik gesteld en wordt in de toekomst mogelijk niet bijgewerkt.
In dit artikel leert u hoe u een ML Studio-webservice (klassiek) opnieuw bouwt als eindpunt in Azure Machine Learning.
Gebruik Azure Machine Learning-pijplijneindpunten om voorspellingen te doen, modellen opnieuw te trainen of een algemene pijplijn uit te voeren. Met het REST-eindpunt kunt u pijplijnen uitvoeren vanaf elk platform.
Dit artikel maakt deel uit van de migratiereeks Studio (klassiek) naar Azure Machine Learning. Zie het artikel over migratieoverzicht voor meer informatie over migreren naar Azure Machine Learning.
Notitie
Deze migratiereeks is gericht op de ontwerpfunctie voor slepen en neerzetten. Zie Machine Learning-modellen implementeren in Azure voor meer informatie over het programmatisch implementeren van modellen.
Vereisten
- Een Azure-account met een actief abonnement. Gratis een account maken
- Een Azure Machine Learning-werkruimte. Werkruimtebronnen maken.
- Een Azure Machine Learning-trainingspijplijn. Zie Een studioexperiment (klassiek) herbouwen in Azure Machine Learning voor meer informatie.
Realtime-eindpunt versus pijplijneindpunt
Studio-webservices (klassiek) zijn vervangen door eindpunten in Azure Machine Learning. Gebruik de volgende tabel om te kiezen welk eindpunttype u wilt gebruiken:
| Studio-webservice (klassiek) | Azure Machine Learning-vervanging |
|---|---|
| Webservice aanvragen/reageren (realtime voorspelling) | Realtime-eindpunt |
| Batch-webservice (batchvoorspelling) | Pijplijneindpunt |
| Webservice opnieuw trainen (opnieuw trainen) | Pijplijneindpunt |
Een realtime-eindpunt implementeren
In Studio (klassiek) hebt u een REQUEST/RESPOND-webservice gebruikt om een model te implementeren voor realtime voorspellingen. In Azure Machine Learning gebruikt u een realtime-eindpunt.
Er zijn meerdere manieren om een model te implementeren in Azure Machine Learning. Een van de eenvoudigste manieren is om de ontwerpfunctie te gebruiken om het implementatieproces te automatiseren. Gebruik de volgende stappen om een model te implementeren als een realtime-eindpunt:
Voer uw voltooide trainingspijplijn minstens één keer uit.
Nadat de taak is voltooid, selecteert u boven aan het canvas deductiepijplijn>in realtime maken.
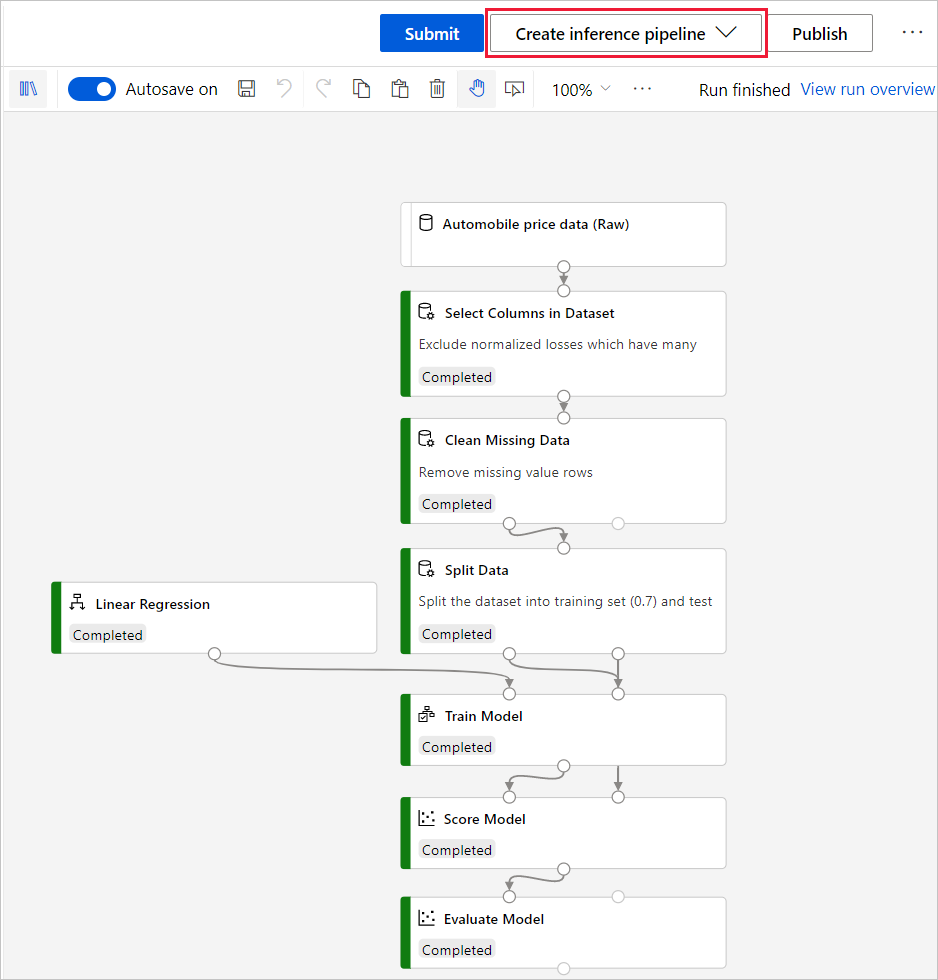
De ontwerpfunctie converteert de trainingspijplijn naar een realtime deductiepijplijn. Een vergelijkbare conversie vindt ook plaats in Studio (klassiek).
In de ontwerpfunctie registreert de conversiestap ook het getrainde model in uw Azure Machine Learning-werkruimte.
Selecteer Verzenden om de realtime deductiepijplijn uit te voeren en controleer of deze correct wordt uitgevoerd.
Nadat u de deductiepijplijn hebt gecontroleerd, selecteert u Implementeren.
Voer een naam in voor uw eindpunt en een rekentype.
In de volgende tabel worden de rekenopties voor de implementatie in de ontwerpfunctie beschreven:
Rekendoel Gebruikt voor Beschrijving Maken Azure Kubernetes Service (AKS) Realtime deductie Grootschalige productie-implementaties. Snelle reactietijd en automatische schaalaanpassing van services. Door de gebruiker gemaakt. Zie Rekendoelen maken voor meer informatie. Azure Container Instances Testen of ontwikkelen Kleinschalige, OP CPU gebaseerde workloads waarvoor minder dan 48 GB RAM nodig is. Automatisch gemaakt door Azure Machine Learning.
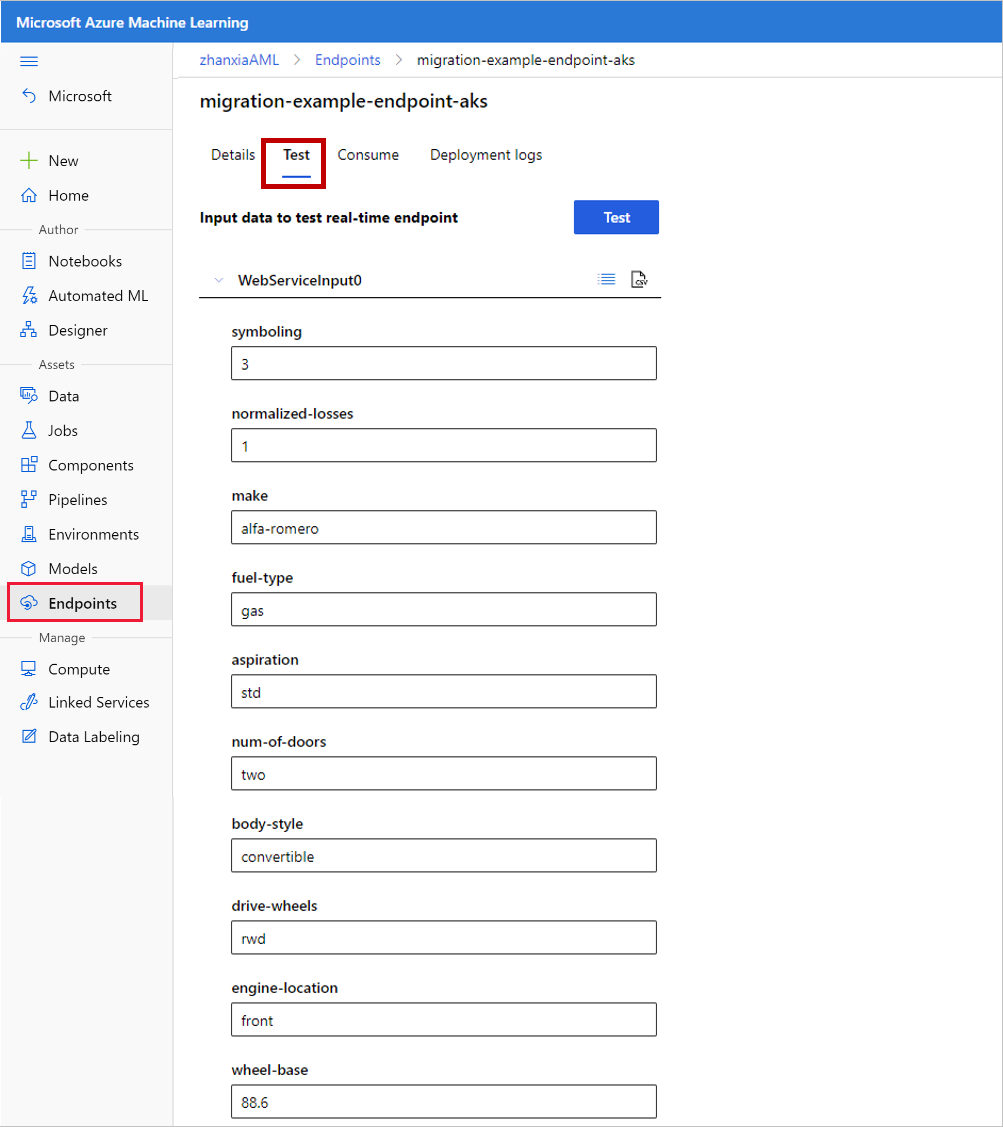
Het realtime-eindpunt testen
Nadat de implementatie is voltooid, kunt u meer details bekijken en uw eindpunt testen:
Ga naar het tabblad Eindpunten .
Selecteer uw eindpunt.
Selecteer het tabblad Testen.
Een pijplijneindpunt publiceren voor batchvoorspelling of opnieuw trainen
U kunt uw trainingspijplijn ook gebruiken om een pijplijneindpunt te maken in plaats van een realtime-eindpunt. Gebruik pijplijneindpunten om batchvoorspelling of hertraining uit te voeren.
Pijplijneindpunten vervangen De eindpunten voor batchuitvoering van Studio (klassiek) en het opnieuw trainen van webservices.
Een pijplijneindpunt publiceren voor batchvoorspelling
Het publiceren van een eindpunt voor batchvoorspelling is vergelijkbaar met het realtime-eindpunt.
Gebruik de volgende stappen om een pijplijneindpunt te publiceren voor batchvoorspelling:
Voer uw voltooide trainingspijplijn minstens één keer uit.
Nadat de taak is voltooid, selecteert u boven aan het canvas Deductiepijplijn batchdeductiepijplijn> maken.
De ontwerpfunctie converteert de trainingspijplijn naar een batchdeductiepijplijn. Een vergelijkbare conversie vindt ook plaats in Studio (klassiek).
In de ontwerpfunctie registreert deze stap ook het getrainde model in uw Azure Machine Learning-werkruimte.
Selecteer Verzenden om de batchdeductiepijplijn uit te voeren en te controleren of deze is voltooid.
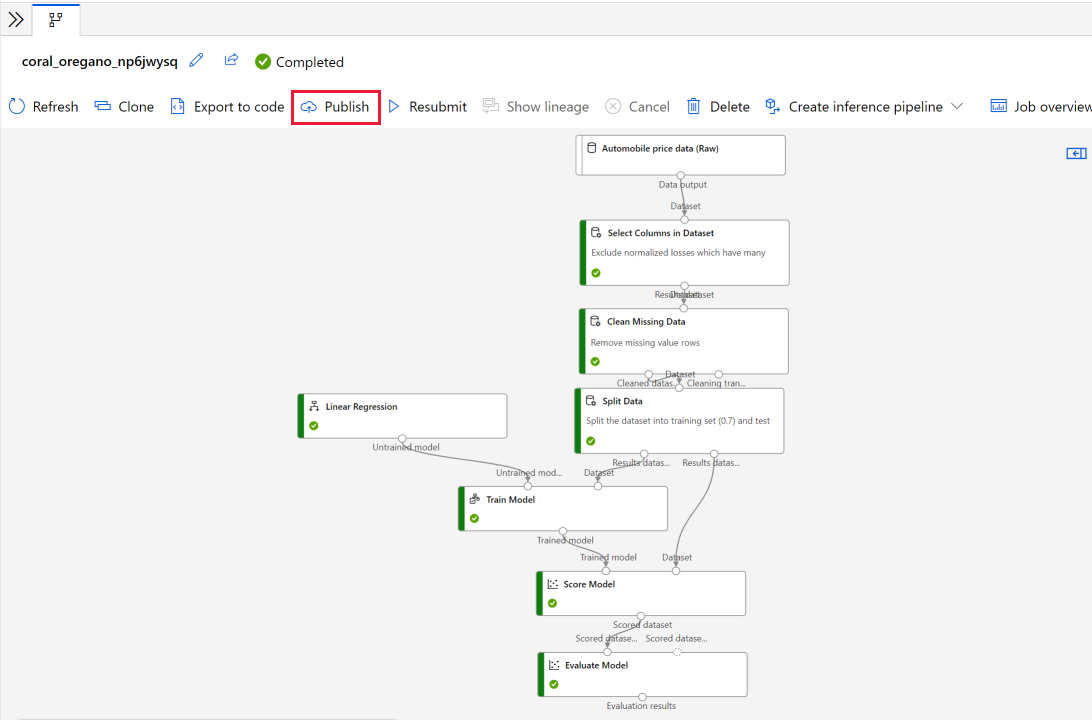
Nadat u de deductiepijplijn hebt gecontroleerd, selecteert u Publiceren.
Maak een nieuw pijplijneindpunt of selecteer een bestaand eindpunt.
Een nieuw pijplijneindpunt maakt een nieuw REST-eindpunt voor uw pijplijn.
Als u een bestaand pijplijneindpunt selecteert, overschrijft u de bestaande pijplijn niet. In plaats daarvan wordt in Azure Machine Learning elke pijplijn in het eindpunt geversied. U kunt opgeven welke versie moet worden uitgevoerd in uw REST-aanroep. U moet ook een standaardpijplijn instellen als de REST-aanroep geen versie opgeeft.
Een pijplijneindpunt publiceren voor opnieuw trainen
Als u een pijplijneindpunt wilt publiceren voor opnieuw trainen, moet u al een pijplijnconcept hebben waarmee een model wordt getraind. Zie Een studioexperiment (klassiek) herbouwen voor meer informatie over het bouwen van een trainingspijplijn.
Als u uw pijplijneindpunt opnieuw wilt gebruiken voor opnieuw trainen, moet u een pijplijnparameter maken voor uw invoergegevensset. Hiermee kunt u uw trainingsgegevensset dynamisch instellen, zodat u uw model opnieuw kunt trainen.
Gebruik de volgende stappen om het eindpunt van de pijplijn voor opnieuw trainen te publiceren:
Voer uw trainingspijplijn minstens één keer uit.
Nadat de uitvoering is voltooid, selecteert u de gegevenssetmodule.
Selecteer In het detailvenster van de module de optie Instellen als pijplijnparameter.
Geef een beschrijvende naam op, zoals InputDataset.
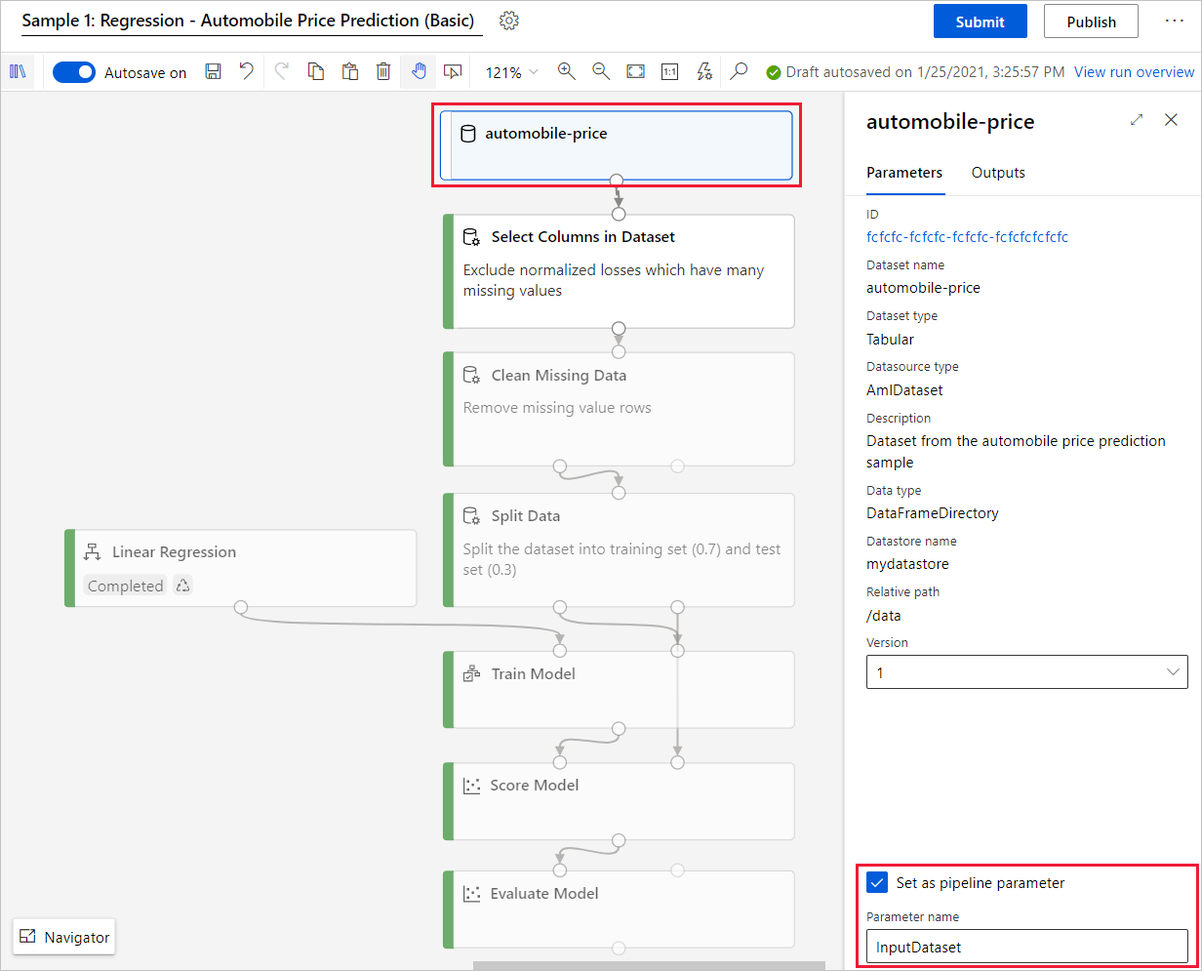
Hiermee maakt u een pijplijnparameter voor uw invoergegevensset. Wanneer u uw pijplijneindpunt aanroept voor training, kunt u een nieuwe gegevensset opgeven om het model opnieuw te trainen.
Selecteer Publiceren.
Uw pijplijneindpunt aanroepen vanuit de studio
Nadat u uw batchdeductie of het opnieuw trainen van het pijplijneindpunt hebt gemaakt, kunt u uw eindpunt rechtstreeks vanuit uw browser aanroepen.
Ga naar het tabblad Pijplijnen en selecteer Pijplijneindpunten.
Selecteer het pijplijneindpunt dat u wilt uitvoeren.
Selecteer Indienen.
U kunt eventuele pijplijnparameters opgeven nadat u Verzenden hebt geselecteerd.
Volgende stappen
In dit artikel hebt u geleerd hoe u een Studio-webservice (klassiek) opnieuw bouwt in Azure Machine Learning. De volgende stap is het integreren van uw webservice met client-apps.
Zie de andere artikelen in de studiomigratiereeks (klassiek):
- Overzicht van migratie.
- Gegevensset migreren.
- Bouw een trainingspijplijn (klassiek) van Studio opnieuw.
- Bouw een Studio-webservice (klassiek) opnieuw op.
- Integreer een Azure Machine Learning-webservice met client-apps.
- R-script uitvoeren migreren.