Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt beschreven hoe u een trainingsscript ontwikkelt met behulp van een notebook op een Azure Machine Learning-cloudwerkstation. In de zelfstudie worden de basisstappen beschreven die u nodig hebt om aan de slag te gaan:
- Het cloudwerkstation instellen en configureren. Uw cloudwerkstation wordt mogelijk gemaakt door een Azure Machine Learning-rekenproces, dat vooraf is geconfigureerd met omgevingen ter ondersteuning van uw modelontwikkelingsbehoeften.
- Ontwikkelomgevingen in de cloud gebruiken.
- Gebruik MLflow om de metrische gegevens van uw model bij te houden.
Vereisten
Als u Azure Machine Learning wilt gebruiken, hebt u een werkruimte nodig. Als u er nog geen hebt, voltooit u Resources maken die u nodig hebt om aan de slag te gaan met het maken van een werkruimte en meer informatie over het gebruik ervan.
Belangrijk
Als uw Azure Machine Learning-werkruimte is geconfigureerd met een beheerd virtueel netwerk, moet u mogelijk uitgaande regels toevoegen om toegang tot de openbare Python-pakketopslagplaatsen toe te staan. Zie Scenario: Toegang tot openbare machine learning-pakketten voor meer informatie.
Berekening maken of starten
U kunt rekenresources maken in de sectie Compute in uw werkruimte. Een rekenproces is een cloudwerkstation dat volledig wordt beheerd door Azure Machine Learning. In deze reeks zelfstudies wordt een rekenproces gebruikt. U kunt deze ook gebruiken om uw eigen code uit te voeren en modellen te ontwikkelen en te testen.
- Meld u aan bij Azure Machine Learning Studio.
- Selecteer uw werkruimte als deze nog niet is geopend.
- Selecteer Compute in het linkerdeelvenster.
- Als u geen rekenproces hebt, ziet u nieuw in het midden van de pagina. Selecteer Nieuw en vul het formulier in. U kunt alle standaardinstellingen gebruiken.
- Als u een rekenproces hebt, selecteert u deze in de lijst. Als deze is gestopt, selecteert u Start.
Visual Studio Code (VS Code) openen
Nadat u een draaiende rekeninstantie hebt, kunt u er op verschillende manieren toegang toe krijgen. In deze zelfstudie wordt beschreven hoe u het rekenproces van Visual Studio Code gebruikt. Visual Studio Code biedt een volledige IDE (Integrated Development Environment) voor het maken van rekeninstanties.
Selecteer in de lijst met rekeninstanties de koppeling VS Code (Web) of VS Code (Desktop) voor het rekenproces dat u wilt gebruiken. Als u VS Code (desktop) kiest, ziet u mogelijk een bericht waarin u wordt gevraagd of u de toepassing wilt openen.

Dit Visual Studio Code-exemplaar is gekoppeld aan uw rekenproces en uw werkruimtebestandssysteem. Zelfs als u het op uw bureaublad opent, zijn de bestanden die u ziet bestanden in uw werkruimte.
Een nieuwe omgeving instellen voor prototypen
Als u uw script wilt uitvoeren, moet u werken in een omgeving die is geconfigureerd met de afhankelijkheden en bibliotheken die de code verwacht. Deze sectie helpt u bij het maken van een omgeving die is afgestemd op uw code. Als u de nieuwe Jupyter-kernel wilt maken waarmee uw notebook verbinding maakt, gebruikt u een YAML-bestand waarmee de afhankelijkheden worden gedefinieerd.
Een bestand uploaden.
Bestanden die u uploadt, worden opgeslagen in een Azure-bestandsshare en deze bestanden worden gekoppeld aan elk rekenproces en gedeeld in de werkruimte.
Ga naar azureml-examples/tutorials/get-started-notebooks/workstation_env.yml.
Download het Conda-omgevingsbestand workstation_env.yml naar uw computer door de knop met het beletselteken (...) in de rechterbovenhoek van de pagina te selecteren en vervolgens Downloaden te selecteren.
Sleep het bestand van uw computer naar het Visual Studio Code-venster. Het bestand wordt geüpload naar uw werkruimte.
Verplaats het bestand naar de map gebruikersnaam.

Selecteer het bestand om een voorbeeld te bekijken. Controleer de afhankelijkheden die worden opgegeven. U zou iets moeten zien dat er ongeveer zo uitziet:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibMaak een kernel.
Gebruik nu de terminal om een nieuwe Jupyter-kernel te maken die is gebaseerd op het workstation_env.yml-bestand .
- Selecteer Terminal > New Terminal in het menu bovenaan Visual Studio Code.
Bekijk uw huidige Conda-omgevingen. De actieve omgeving is gemarkeerd met een sterretje (*).
conda env listHiermee
cdnavigeert u naar de map waarin u het workstation_env.yml-bestand hebt geüpload. Als u deze bijvoorbeeld hebt geüpload naar uw gebruikersmap, gebruikt u deze opdracht:cd Users/myusernameZorg ervoor dat workstation_env.yml zich in de map bevindt.
lsMaak de omgeving op basis van het opgegeven Conda-bestand. Het duurt enkele minuten om de omgeving te bouwen.
conda env create -f workstation_env.ymlActiveer de nieuwe omgeving.
conda activate workstation_envNotitie
Als u CommandNotFoundError ziet, volgt u de instructies om de terminal uit te voeren
conda init bash, sluit u de terminal en opent u een nieuwe. Probeer vervolgens deconda activate workstation_envopdracht opnieuw.Controleer of de juiste omgeving actief is en zoek opnieuw naar de omgeving die is gemarkeerd met een *.
conda env listMaak een nieuwe Jupyter-kernel die is gebaseerd op uw actieve omgeving.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Sluit het terminalvenster.
U hebt nu een nieuwe kernel. Vervolgens opent u een notebook en gebruikt u deze kernel.
Een notebook maken
- Selecteer Bestand > nieuw bestand in het menu bovenaan Visual Studio Code.
- Geef het nieuwe bestand de naam develop-tutorial.ipynb (of gebruik een andere naam). Zorg ervoor dat u de extensie .ipynb gebruikt.
De kernel instellen
- Selecteer Kernel in de rechterbovenhoek van het nieuwe bestand.
- Selecteer een Azure ML-rekenproces (computeinstance-name).
- Selecteer de kernel die u hebt gemaakt: Tutorial Workstation Env. Als u de kernel niet ziet, selecteert u de knop Vernieuwen boven de lijst.
Een trainingsscript ontwikkelen
In deze sectie ontwikkelt u een Python-trainingsscript dat wanbetalingen van creditcards voorspelt met behulp van de voorbereide test- en trainingsdatasets van de UCI-dataset.
Deze code gebruikt sklearn voor training en MLflow voor het vastleggen van metrische gegevens.
Begin met code waarmee de pakketten en bibliotheken worden geïmporteerd die u in het trainingsscript gaat gebruiken.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitVervolgens laadt en verwerkt u de gegevens voor het experiment. In deze zelfstudie leest u de gegevens uit een bestand op internet.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Bereid de gegevens voor op de training.
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesVoeg code toe om autologging met MLflow te starten, zodat u de metrische gegevens en resultaten kunt bijhouden. Met de iteratieve aard van modelontwikkeling helpt MLflow u bij het vastleggen van modelparameters en -resultaten. Raadpleeg verschillende uitvoeringen om te vergelijken en te begrijpen hoe uw model presteert. De logboeken bieden ook context wanneer u klaar bent om over te stappen van de ontwikkelingsfase naar de trainingsfase van uw werkstromen in Azure Machine Learning.
# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Een model trainen.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Notitie
U kunt de MLflow-waarschuwingen negeren. De resultaten die u nodig hebt, worden nog steeds bijgehouden.
Selecteer Alles uitvoeren boven de code.
Herhalen
Nu u modelresultaten hebt, wijzigt u iets en voert u het model opnieuw uit. Probeer bijvoorbeeld een andere classificatietechniek:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Notitie
U kunt de MLflow-waarschuwingen negeren. De resultaten die u nodig hebt, worden nog steeds bijgehouden.
Selecteer Alles uitvoeren om het model uit te voeren.
De resultaten bekijken
Nu u twee verschillende modellen hebt geprobeerd, gebruikt u de resultaten die door MLFfow worden bijgehouden om te bepalen welk model beter is. U kunt verwijzen naar metrische gegevens, zoals nauwkeurigheid of andere indicatoren die het belangrijkst zijn voor uw scenario's. U kunt deze resultaten gedetailleerder bekijken door de taken te bekijken die door MLflow zijn gemaakt.
Ga terug naar uw werkruimte in de Azure Machine Learning-studio.
Selecteer Jobs in het linkerdeelvenster.
Selecteer Ontwikkelen op de cloud handleiding.
Er worden twee taken weergegeven, één voor elk van de modellen die u hebt geprobeerd. De namen worden automatisch gegenereerd. Als u de naam van de taak wilt wijzigen, plaatst u de muisaanwijzer op de naam en selecteert u de potloodknop ernaast.
Selecteer de koppeling voor de eerste taak. De naam wordt boven aan de pagina weergegeven. U kunt de naam hier ook wijzigen met behulp van de potloodknop.
Op de pagina worden taakdetails weergegeven, zoals eigenschappen, uitvoer, tags en parameters. Onder Tags ziet u de estimator_name, waarin het type model wordt beschreven.
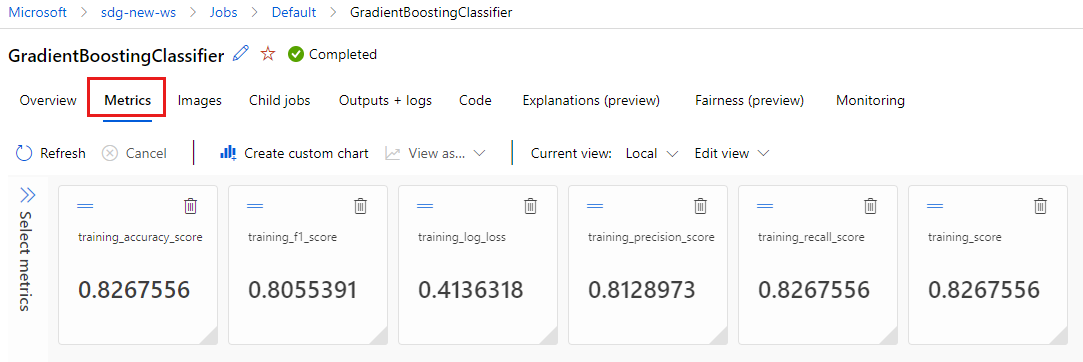
Selecteer het tabblad Metrische gegevens om de metrische gegevens weer te geven die zijn vastgelegd door MLflow. (Uw resultaten zijn anders omdat u een andere trainingsset hebt.)
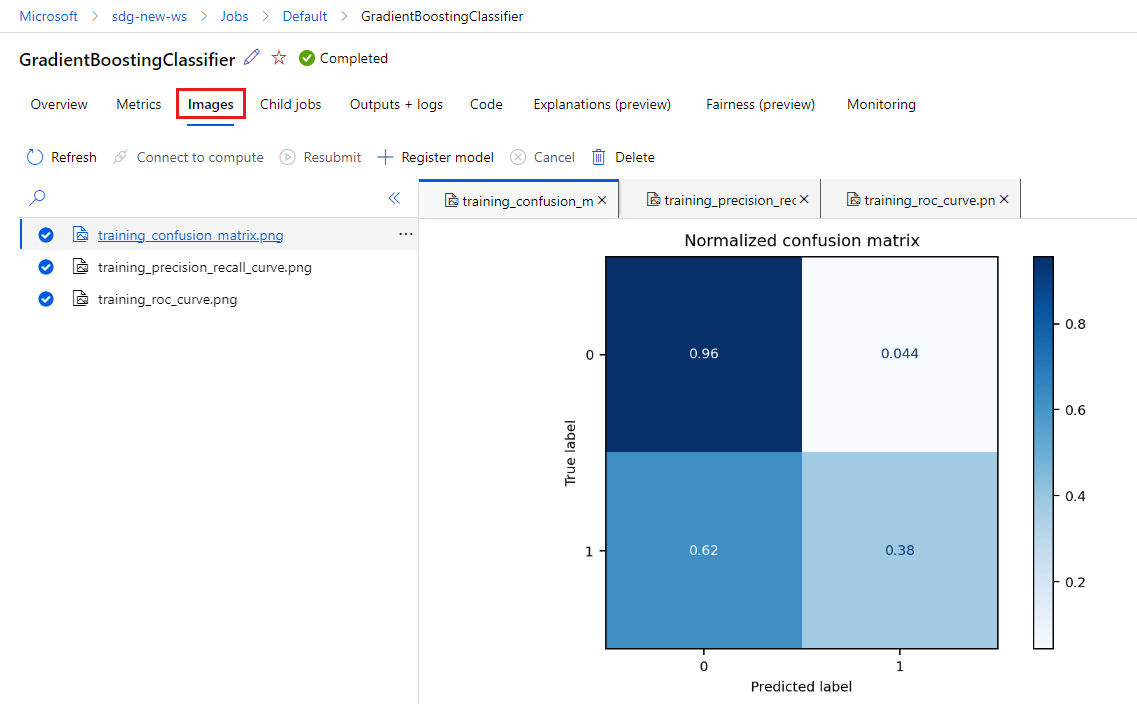
Selecteer het tabblad Afbeeldingen om de afbeeldingen weer te geven die zijn gegenereerd door MLflow.
Ga terug en bekijk de metrische gegevens en afbeeldingen voor het andere model.

Een Python-script maken
U maakt nu een Python-script op basis van uw notebook voor modeltraining.
Klik in Visual Studio Code met de rechtermuisknop op de bestandsnaam van het notitieblok en selecteer Notebook importeren in script.
Selecteer Bestand > opslaan om het nieuwe scriptbestand op te slaan. Noem het train.py.
Bekijk het bestand en verwijder code die u niet wilt in het trainingsscript. Bewaar bijvoorbeeld de code voor het model dat u wilt gebruiken en verwijder code voor het model dat u niet wilt gebruiken.
- Zorg ervoor dat u de code bewaart die het automatisch loggen start (
mlflow.sklearn.autolog()). - Wanneer u het Python-script interactief uitvoert (zoals u hier doet), kunt u de regel behouden waarmee de naam van het experiment (
mlflow.set_experiment("Develop on cloud tutorial")) wordt gedefinieerd. U kunt het ook een andere naam geven zodat het als een andere vermelding wordt weergegeven in de sectie Banen. Maar wanneer u het script voorbereidt voor een trainingstaak, wordt die regel niet toegepast en moet deze worden weggelaten: de taakdefinitie bevat de naam van het experiment. - Wanneer u één model traint, zijn de regels voor het starten en beëindigen van een uitvoering (
mlflow.start_run()enmlflow.end_run()) niet nodig (ze hebben geen effect), maar u kunt ze binnenlaten.
- Zorg ervoor dat u de code bewaart die het automatisch loggen start (
Sla het bestand op wanneer u klaar bent met uw bewerkingen.
U hebt nu een Python-script dat u kunt gebruiken voor het trainen van uw voorkeursmodel.
Het Python-script uitvoeren
Op dit moment voert u deze code uit op uw rekenproces. Dit is uw Azure Machine Learning-ontwikkelomgeving. Zelfstudie: Een model trainen laat zien hoe u een trainingsscript op een schaalbare manier kunt uitvoeren op krachtigere rekenresources.
Selecteer de omgeving die u eerder in deze zelfstudie hebt gemaakt als uw Python-versie (workstations_env). In de rechterbenedenhoek van het notitieblok ziet u de naam van de omgeving. Selecteer het en selecteer vervolgens de omgeving bovenaan in Visual Studio Code.

Voer het Python-script uit door de knop Alles uitvoeren boven de code te selecteren.



Notitie
U kunt de MLflow-waarschuwingen negeren. U krijgt nog steeds alle metrische gegevens en afbeeldingen van automatisch afmelden.
De scriptresultaten bekijken
Ga terug naar Taken in uw werkruimte in Azure Machine Learning-studio om de resultaten van uw trainingsscript weer te geven. Houd er rekening mee dat de trainingsgegevens bij elke splitsing worden gewijzigd, zodat de resultaten verschillen tussen uitvoeringen.
Resources opschonen
Als u van plan bent om door te gaan met andere zelfstudies, gaat u verder met volgende stappen.
Het rekenproces stoppen
Als u deze nu niet gaat gebruiken, stopt u het rekenproces:
- Selecteer Compute in de studio in het linkerdeelvenster.
- Selecteer aan de bovenkant van de pagina Rekeninstanties.
- Selecteer het rekenexemplaar in de lijst.
- Selecteer Stoppen boven aan de pagina.
Alle resources verwijderen
Belangrijk
De resources die u hebt gemaakt, kunnen worden gebruikt als de vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Als u niet van plan bent om een van de resources te gebruiken die u hebt gemaakt, verwijdert u deze zodat er geen kosten in rekening worden gebracht:
Voer in azure Portal in het zoekvak resourcegroepen in en selecteer deze in de resultaten.
Selecteer de resourcegroep die u hebt gemaakt uit de lijst.
Selecteer op de pagina Overzicht de optie Resourcegroep verwijderen.
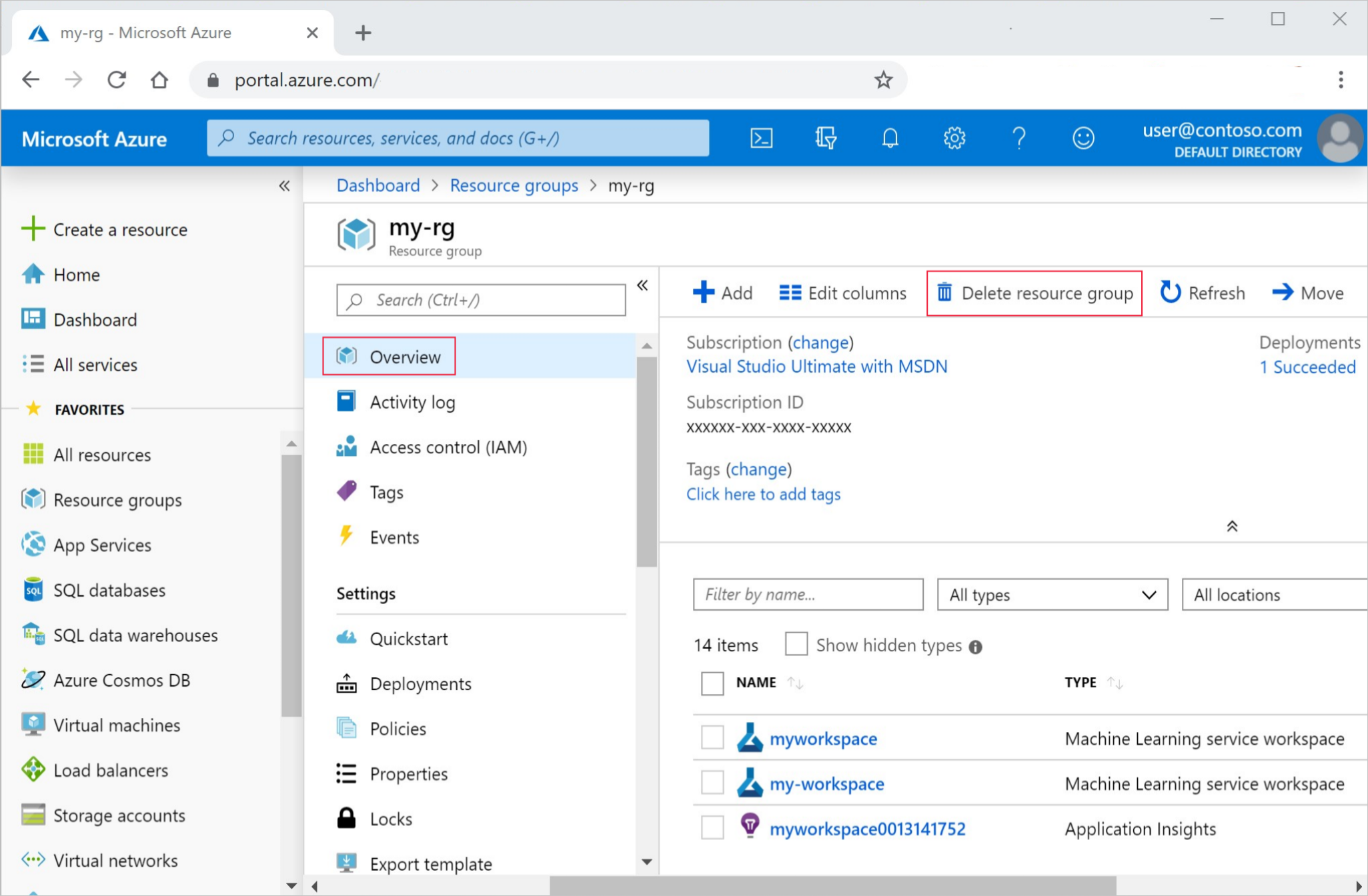
Voer de naam van de resourcegroup in. Selecteer daarna Verwijderen.
Volgende stappen
Zie deze informatiebronnen voor meer informatie:
- Artefacten en modellen in MLflow
- Git gebruiken met Azure Machine Learning
- Jupyter-notebooks uitvoeren in uw werkruimte
- Werken met een rekeninstantieterminal in uw werkruimte
- Notebook- en terminalsessies beheren
In deze zelfstudie ziet u de vroege stappen voor het maken van een model en het maken van prototypen op dezelfde computer waarin de code zich bevindt. Voor uw productietraining leert u hoe u dat trainingsscript kunt gebruiken voor krachtigere externe rekenresources: