Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP: Python SDK azure-ai-ml v2 (actueel)
Python SDK azure-ai-ml v2 (actueel)
In deze zelfstudie worden enkele van de meest gebruikte functies van de Azure Machine Learning-service geïntroduceerd. U maakt, registreert en implementeert een model. Deze zelfstudie helpt u vertrouwd te raken met de belangrijkste concepten van Azure Machine Learning en hun meest voorkomende gebruik.
U leert hoe u een trainingstaak uitvoert op een schaalbare rekenresource, deze vervolgens implementeert en ten slotte de implementatie test.
U maakt een trainingsscript voor het afhandelen van de gegevensvoorbereiding, het trainen en registreren van een model. Nadat u het model hebt getraind, implementeert u het als eindpunt en roept u het eindpunt aan voor deductie.
De stappen die u uitvoert, zijn:
- Een ingang instellen voor uw Azure Machine Learning-werkruimte
- Uw trainingsscript maken
- Een schaalbare rekenresource maken, een rekencluster
- Een opdrachttaak maken en uitvoeren waarmee het trainingsscript op het rekencluster wordt uitgevoerd, geconfigureerd met de juiste taakomgeving
- De uitvoer van uw trainingsscript weergeven
- Het nieuw getrainde model implementeren als eindpunt
- Het Azure Machine Learning-eindpunt aanroepen voor deductie
Bekijk deze video voor een overzicht van de stappen in deze quickstart.
Vereisten
-
Als u Azure Machine Learning wilt gebruiken, hebt u een werkruimte nodig. Als u er nog geen hebt, voltooit u Resources maken die u nodig hebt om aan de slag te gaan met het maken van een werkruimte en meer informatie over het gebruik ervan.
Belangrijk
Als uw Azure Machine Learning-werkruimte is geconfigureerd met een beheerd virtueel netwerk, moet u mogelijk uitgaande regels toevoegen om toegang tot de openbare Python-pakketopslagplaatsen toe te staan. Zie Scenario: Toegang tot openbare machine learning-pakketten voor meer informatie.
-
Meld u aan bij de studio en selecteer uw werkruimte als deze nog niet is geopend.
-
Open of maak een notitieblok in uw werkruimte:
- Als u code in cellen wilt kopiëren en plakken, maakt u een nieuw notitieblok.
- Of open zelfstudies/get-started-notebooks/quickstart.ipynb in de sectie Samples van studio. Selecteer Vervolgens Klonen om het notitieblok toe te voegen aan uw bestanden. Zie Learn from sample notebooks(Learn from sample notebooks) (Learn from sample notebooks) voor meer informatie over voorbeeldnotebooks.
Uw kernel instellen en openen in Visual Studio Code (VS Code)
Maak op de bovenste balk boven het geopende notitieblok een rekenproces als u er nog geen hebt.

Als het rekenproces is gestopt, selecteert u Rekenproces starten en wacht u totdat het wordt uitgevoerd.

Wacht totdat het rekenproces wordt uitgevoerd. Zorg er vervolgens voor dat de kernel, in de rechterbovenhoek, is
Python 3.10 - SDK v2. Als dit niet het probleem is, gebruikt u de vervolgkeuzelijst om deze kernel te selecteren.
Als u deze kernel niet ziet, controleert u of uw rekenproces wordt uitgevoerd. Als dat het is, selecteert u de knop Vernieuwen rechtsboven in het notitieblok.
Als u een banner ziet met de melding dat u moet worden geverifieerd, selecteert u Verifiëren.
U kunt het notebook hier uitvoeren of openen in VS Code voor een volledige IDE (Integrated Development Environment) met de kracht van Azure Machine Learning-resources. Selecteer Openen in VS Code en selecteer vervolgens de optie web of bureaublad. Bij het starten op deze manier wordt VS Code gekoppeld aan uw rekenproces, de kernel en het bestandssysteem van de werkruimte.





Belangrijk
De rest van deze zelfstudie bevat cellen van het zelfstudienotitieblok. Kopieer en plak deze in uw nieuwe notitieblok of ga nu naar het notitieblok als u het hebt gekloond.
Greep maken voor werkruimte
Voordat u de code gaat bekijken, hebt u een manier nodig om naar uw werkruimte te verwijzen. De werkruimte is de resource op het hoogste niveau voor Azure Machine Learning en biedt een gecentraliseerde werkplek met alle artefacten die u maakt in Azure Machine Learning.
Maak ml_client als ingang voor de werkruimte. Gebruik ml_client om middelen en taken te beheren.
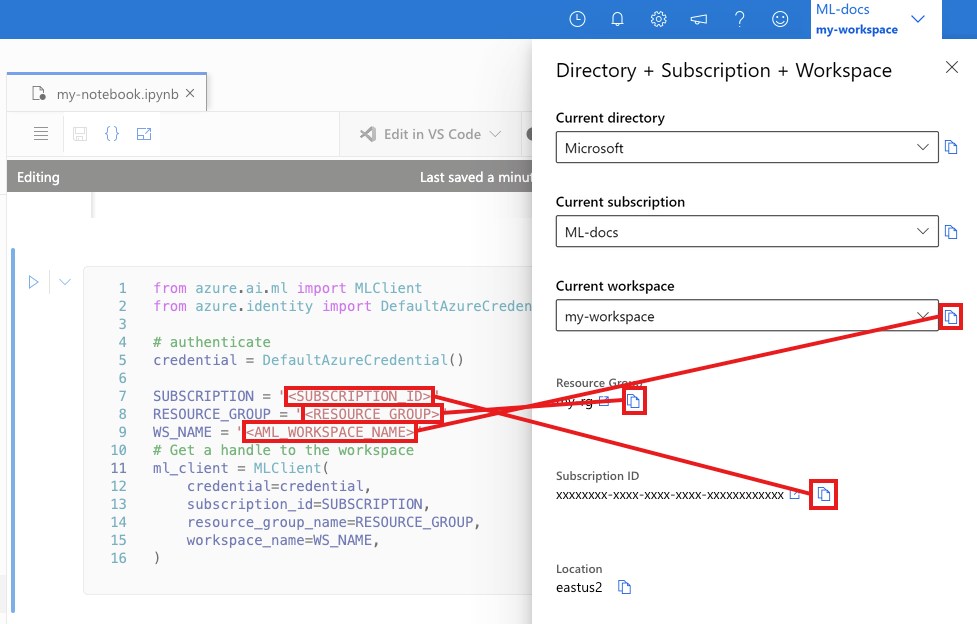
Voer in de volgende cel uw abonnements-id, resourcegroepnaam en werkruimtenaam in. Deze waarden zoeken:
- Selecteer in de rechterbovenhoek Azure Machine Learning-studio werkbalk de naam van uw werkruimte.
- Kopieer de waarde voor werkruimte, resourcegroep en abonnements-id naar de code.
- U moet één waarde kopiëren, het gebied sluiten en plakken. Kom dan terug voor de volgende waarde.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Notitie
Het maken van MLClient maakt geen verbinding met de werkruimte. De initialisatie van de client is lui. Het wacht tot de eerste keer dat het een oproep moet doen. Deze actie vindt plaats in de volgende codecel.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Trainingsscript maken
Maak het trainingsscript, het main.py Python-bestand.
Maak eerst een bronmap voor het script:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Met dit script worden de gegevens vooraf verwerkt en gesplitst in test- en traingegevenssets. Het traint een boomstructuurmodel met behulp van deze data en retourneert het model.
Tijdens de pijplijnuitvoering gebruikt u MLFlow om de parameters en metrische gegevens te registreren.
In de volgende cel wordt IPython magic gebruikt om het trainingsscript te schrijven naar de map die u zojuist hebt gemaakt.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
# pin numpy
conda_env = {
'name': 'mlflow-env',
'channels': ['conda-forge'],
'dependencies': [
'python=3.10.15',
'pip<=21.3.1',
{
'pip': [
'mlflow==2.17.0',
'cloudpickle==2.2.1',
'pandas==1.5.3',
'psutil==5.8.0',
'scikit-learn==1.5.2',
'numpy==1.26.4',
]
}
],
}
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
conda_env=conda_env,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Wanneer het model is getraind, wordt het modelbestand opgeslagen en geregistreerd in de werkruimte. U kunt het geregistreerde model gebruiken bij inferentie-eindpunten.
Mogelijk moet u Vernieuwen selecteren om de nieuwe map en het nieuwe script in uw bestanden weer te geven.
De opdracht configureren
U hebt nu een script dat de gewenste taken kan uitvoeren en een rekencluster om het script uit te voeren. Gebruik een opdracht voor algemeen gebruik waarmee opdrachtregelacties kunnen worden uitgevoerd. Met deze opdrachtregelactie kunt u systeemopdrachten rechtstreeks aanroepen of een script uitvoeren.
Maak invoervariabelen om de invoergegevens, de splitsingsverhouding, de leersnelheid en de geregistreerde modelnaam op te geven. Het opdrachtscript:
- Maakt gebruik van een omgeving die software- en runtimebibliotheken definieert die nodig zijn voor het trainingsscript. Azure Machine Learning biedt veel gecureerde of kant-en-klare omgevingen, die nuttig zijn voor algemene trainings- en deductiescenario's. U gebruikt hier een van deze omgevingen. In de zelfstudie: Een model trainen in Azure Machine Learning leert u hoe u een aangepaste omgeving maakt.
- Configureert de opdrachtregelactie zelf -
python main.pyin dit geval. De invoer en uitvoer zijn toegankelijk in de opdracht via de${{ ... }}notatie. - Hiermee opent u de gegevens uit een bestand op internet.
- Omdat u geen rekenresource hebt opgegeven, wordt het script uitgevoerd op een serverloos rekencluster dat automatisch wordt gemaakt.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="azureml://registries/azureml/environments/sklearn-1.5/labels/latest",
display_name="credit_default_prediction",
)
De taak verzenden
Verzend de taak die moet worden uitgevoerd in Azure Machine Learning. Gebruik deze keer create_or_update op ml_client.
ml_client.create_or_update(job)
Taakuitvoer weergeven en wachten op voltooiing van de taak
Bekijk de taak in Azure Machine Learning-studio door de koppeling te selecteren in de uitvoer van de vorige cel.
De uitvoer van deze taak ziet er als volgt uit in de Azure Machine Learning-studio. Verken de tabbladen voor verschillende details, zoals metrische gegevens, uitvoer en meer. Zodra de taak is voltooid, wordt een model in uw werkruimte geregistreerd als gevolg van de training.
Belangrijk
Wacht totdat de status van de taak is voltooid voordat u teruggaat naar dit notitieblok om door te gaan. Het uitvoeren van de taak duurt twee tot drie minuten. Het kan langer duren (maximaal 10 minuten) als het rekencluster omlaag wordt geschaald naar nul knooppunten en er nog steeds aangepaste omgeving wordt gebouwd.
Het model implementeren als een online-eindpunt
Implementeer uw machine learning-model als een webservice in de Azure-cloud met behulp van een online endpoint.
Als u een machine learning-service wilt implementeren, gebruikt u het model dat u hebt geregistreerd.
Een nieuw online-eindpunt maken
Nu u een model hebt geregistreerd, maakt u uw online-eindpunt. De eindpuntnaam moet uniek zijn in de hele Azure-regio. Maak voor deze zelfstudie een unieke naam met behulp van UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Maak het eindpunt.
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Notitie
Verwacht dat het maken van het eindpunt enkele minuten duurt.
Nadat u het eindpunt hebt gemaakt, haalt u het op zoals wordt weergegeven in de volgende code:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Het model implementeren op het eindpunt
Nadat u het eindpunt hebt gemaakt, implementeert u het model met behulp van het invoerscript. Elk eindpunt kan meerdere implementaties hebben. U kunt regels opgeven om verkeer naar deze implementaties te leiden. In dit voorbeeld maakt u één implementatie die 100% van het binnenkomende verkeer verwerkt. Kies een kleurnaam voor de implementatie, zoals blauw, groen of rood. De keuze is willekeurig.
Als u de nieuwste versie van uw geregistreerde model wilt vinden, raadpleegt u de pagina Modellen in Azure Machine Learning Studio. U kunt ook de volgende code gebruiken om het meest recente versienummer op te halen.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Implementeer de nieuwste versie van het model.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Notitie
Verwacht dat deze implementatie ongeveer 6 tot 8 minuten duurt.
Wanneer de implementatie is voltooid, kunt u deze testen.
Testen met een voorbeeldquery
Nadat u het model op het eindpunt hebt geïmplementeerd, voert u deductie uit met behulp van het model.
Maak een voorbeeldaanvraagbestand dat volgt op het ontwerp dat in de run methode in het scorescript wordt verwacht.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Resources opschonen
Als u het eindpunt niet nodig hebt, verwijdert u het om te stoppen met het gebruik van de resource. Zorg ervoor dat er geen andere implementaties een eindpunt gebruiken voordat u het verwijdert.
Notitie
Verwacht dat de volledige verwijdering ongeveer 20 minuten duurt.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Rekenproces stoppen
Als u dit nu niet nodig hebt, stopt u het rekenproces:
- Selecteer Compute in de studio in het linkerdeelvenster.
- Selecteer Compute-exemplaren op de bovenste tabbladen.
- Selecteer het rekenproces in de lijst.
- Selecteer Stoppen op de bovenste werkbalk.
Alle resources verwijderen
Belangrijk
De resources die u hebt gemaakt, kunnen worden gebruikt als de vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Als u niet van plan bent om een van de resources te gebruiken die u hebt gemaakt, verwijdert u deze zodat er geen kosten in rekening worden gebracht:
Voer in azure Portal in het zoekvak resourcegroepen in en selecteer deze in de resultaten.
Selecteer de resourcegroep die u hebt gemaakt uit de lijst.
Selecteer op de pagina Overzicht de optie Resourcegroep verwijderen.
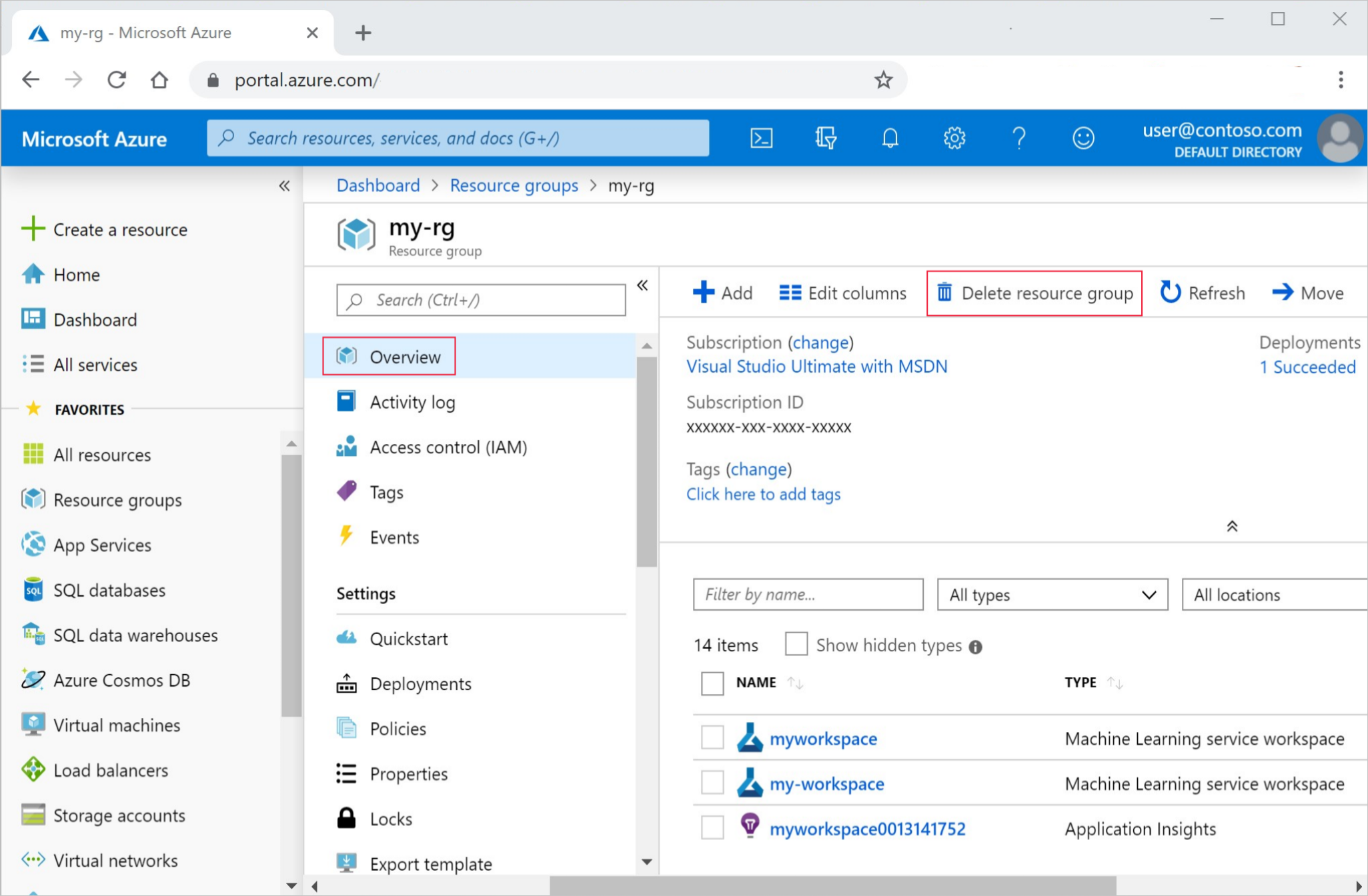
Voer de naam van de resourcegroup in. Selecteer daarna Verwijderen.
Volgende stappen
Nu u een idee hebt van wat betrokken is bij het trainen en implementeren van een model, leert u meer over het proces in deze zelfstudies:
| Zelfstudie | Beschrijving |
|---|---|
| Uw gegevens uploaden, openen en verkennen in Azure Machine Learning | Grote gegevens opslaan in de cloud en deze ophalen uit notebooks en scripts |
| Modelontwikkeling op een cloudwerkstation | Beginnen met het maken van prototypen en het ontwikkelen van machine learning-modellen |
| Een model trainen in Azure Machine Learning | Duik in de details van het trainen van een model |
| Een model implementeren als een online-eindpunt | Duik in de details van het implementeren van een model |
| Machine Learning-pijplijnen voor productie maken | Splits een volledige machine learning-taak in een werkstroom met meerdere stappen. |