Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie leert u hoe u een classificatiemodel traint met geautomatiseerde machine learning (AutoML) zonder code met behulp van Azure Machine Learning in de Azure Machine Learning-studio. Dit classificatiemodel voorspelt of een klant zich abonneert op een vaste termijndeposito bij een financiële instelling.
Met Geautomatiseerde ML kunt u tijdsintensieve taken automatiseren. Geautomatiseerde machine learning doorloopt of itereert snel allerlei combinaties van algoritmen en hyperparameters om het beste model te vinden op basis van uw maatstaaf voor succes.
U schrijft geen code in deze zelfstudie. U gebruikt de studio-interface om training uit te voeren. U leert hoe u de volgende taken uitvoert:
- Een Azure Machine Learning-werkruimte maken
- Een geautomatiseerd machine learning-experiment uitvoeren
- Modeldetails verkennen
- Het aanbevolen model implementeren
Vereisten
Een Azure-abonnement. Als u nog geen Azure-abonnement hebt, maakt u een gratis account.
Download het bank+marketing.zip gegevensbestand. We gebruiken het bestandbank-full.csv . De kolom y geeft aan of een klant een termijnrekening heeft geopend. Verderop in deze zelfstudie wordt deze geïdentificeerd als doelkolom voor voorspellingen.
Notitie
Deze bankmarketinggegevensset wordt beschikbaar gesteld onder de Creative Commons Attribution 4.0 International License. Deze gegevensset is beschikbaar als onderdeel van de UCI Machine Learning-database.
Moro, S., P. Rita en P. Cortez. 2014. Bank Marketing. UCI Machine Learning-opslagplaats. https://doi.org/10.24432/C5K306.
Een werkruimte maken
Een Azure Machine Learning-werkruimte is een basisblok in de cloud dat u gebruikt voor het experimenteren, trainen en implementeren van machine learning-modellen. De klasse bindt uw Azure-abonnement en resourcegroep aan een eenvoudig te verbruiken object in de service.
Voer de volgende stappen uit om een werkruimte te maken en door te gaan met de zelfstudie.
Meld u aan bij Azure Machine Learning Studio.
Selecteer Werkruimte maken.
Geef de volgende gegevens op om uw nieuwe werkruimte te configureren:
Veld Beschrijving Werkruimtenaam Voer een unieke naam in die uw werkruimte aanduidt. Namen moeten uniek zijn binnen de resourcegroep. Gebruik een naam die gemakkelijk te onthouden is en te onderscheiden is van door anderen gemaakte werkruimten. De naam van de werkruimte is niet hoofdlettergevoelig. Abonnement Selecteer het Azure-abonnement dat u wilt gebruiken. Resourcegroep Gebruik een bestaande resourcegroep in uw abonnement of voer een naam in om een nieuwe resourcegroep te maken. Een resourcegroep bevat gerelateerde resources voor een Azure-oplossing. U hebt de rol inzender of eigenaar nodig om een bestaande resourcegroep te kunnen gebruiken. Zie Toegang tot een Azure Machine Learning-werkruimte beheren voor meer informatie. Regio Selecteer de Azure-regio het dichtst bij uw gebruikers en de gegevensbronnen om uw werkruimte te maken. Selecteer Maken om de werkruimte te maken.
Zie De werkruimte maken voor meer informatie over Azure-resources.
Voor andere manieren om een werkruimte te maken in Azure, beheert u Azure Machine Learning-werkruimten in de portal of met de Python SDK (v2).
Een geautomatiseerde Machine Learning-taak maken
Voltooi de volgende stappen voor het instellen en uitvoeren van het experiment met behulp van de Azure Machine Learning-studio op https://ml.azure.com. Machine Learning Studio is een geconsolideerde webinterface met machine learning-hulpprogramma's voor het uitvoeren van data science-scenario's voor gegevenswetenschapsbeoefenaars van alle vaardigheidsniveaus. De studio wordt niet ondersteund in Internet Explorer-browsers.
Selecteer uw abonnement en de werkruimte die u heeft gemaakt.
Selecteer >in het navigatiedeelvenster Geautomatiseerde ML ontwerpen.
Omdat deze zelfstudie uw eerste geautomatiseerde ML-experiment is, ziet u een lege lijst en koppelingen naar documentatie.
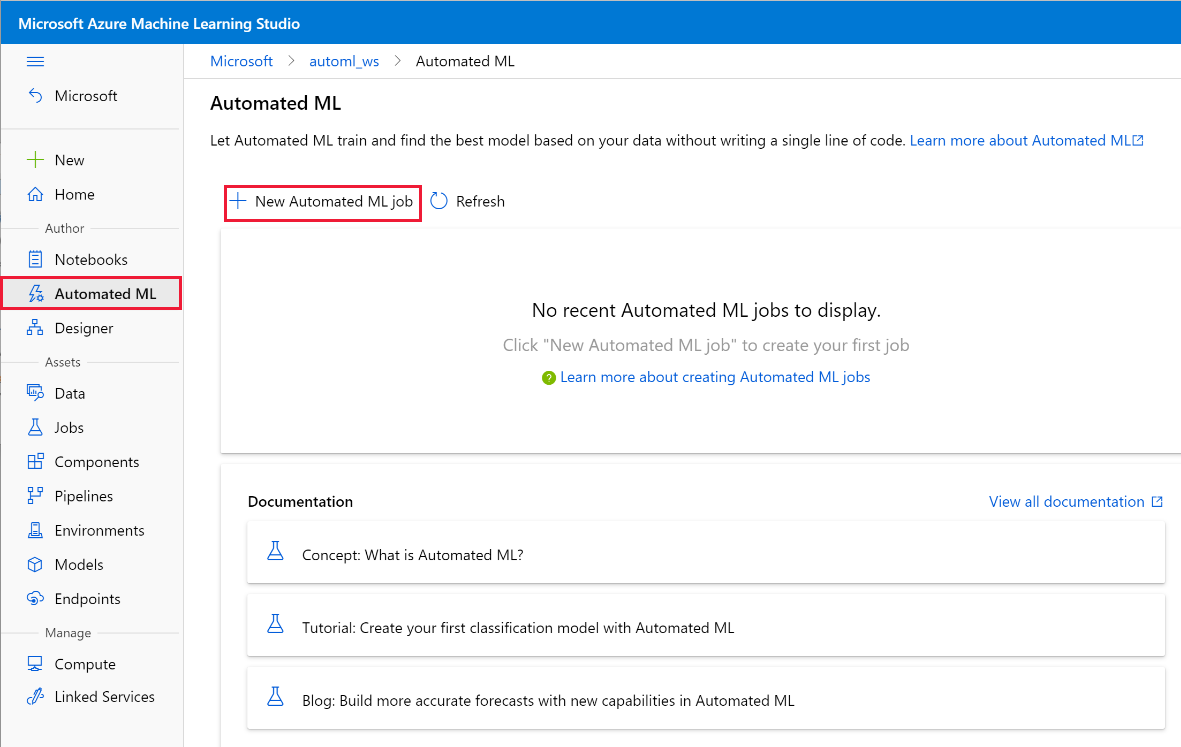
Selecteer nieuwe geautomatiseerde ML-taak.
Selecteer automatisch trainen in de trainingsmethode en selecteer vervolgens De configuratietaak starten.
Selecteer in De basisinstellingen Nieuwe maken en voer vervolgens voor De naam van het experiment mijn-1e-automl-experiment in.
Selecteer Volgende om uw gegevensset te laden.

Een gegevensset maken en laden als gegevensasset
Voordat u uw experiment configureert, uploadt u het gegevensbestand naar uw werkruimte in de vorm van een Azure Machine Learning-gegevensasset. Voor deze zelfstudie kunt u een gegevensasset beschouwen als uw gegevensset voor de geautomatiseerde ML-taak. Hierdoor kunt u ervoor zorgen dat uw gegevens op de juiste wijze zijn opgemaakt voor uw experiment.
Kies Classificatie in taaktype & gegevens voor Taaktype selecteren.
Kies Onder Gegevens selecteren de optie Maken.
Geef in het formulier Gegevenstype een naam op voor uw gegevensasset en geef een optionele beschrijving op.
Voor Type selecteert u Tabellair. De geautomatiseerde ML-interface ondersteunt momenteel alleen TabularDatasets.
Selecteer Volgende.
Selecteer in het formulier Gegevensbron de optie Uit lokale bestanden. Selecteer Volgende.
Selecteer in doelopslagtype het standaardgegevensarchief dat automatisch is ingesteld tijdens het maken van uw werkruimte: workspaceblobstore. U uploadt uw gegevensbestand naar deze locatie om het beschikbaar te maken voor uw werkruimte.
Selecteer Volgende.
Selecteer bestanden of mappen uploaden in de selectie Van bestanden of mappen>uploaden.
Kies het bestand bankmarketing_train.csv op uw lokale computer. U hebt dit bestand gedownload als een vereiste.
Selecteer Volgende.
Wanneer het uploaden is voltooid, wordt het gebied Gegevensvoorbeeld ingevuld op basis van het bestandstype.
Controleer in het formulier Instellingen de waarden voor uw gegevens. Selecteer Volgende.
Veld Beschrijving Waarde voor zelfstudie Bestandsformaat Definieert de indeling en het type gegevens dat is opgeslagen in een bestand. Met scheidingstekens Scheidingsteken Een of meer tekens die de grens aangeven tussen afzonderlijke, onafhankelijke regio's in tekst zonder opmaak of andere gegevensstromen. Puntkomma Codering Identificeert welke bit-naar-tekenschematabel er moet gebruikt worden om uw gegevensset te lezen. UTF-8 Kolomkoppen Geeft aan hoe de headers van de gegevensset, indien aanwezig, worden behandeld. Alle bestanden hebben dezelfde koppen Rijen overslaan Geeft aan hoeveel rijen er eventueel worden overgeslagen in de gegevensset. Geen Met het formulier Schema kunt u uw gegevens verder configureren voor dit experiment. Voor dit voorbeeld selecteert u de wisselknop voor de day_of_week, zodat u deze niet wilt opnemen. Selecteer Volgende.
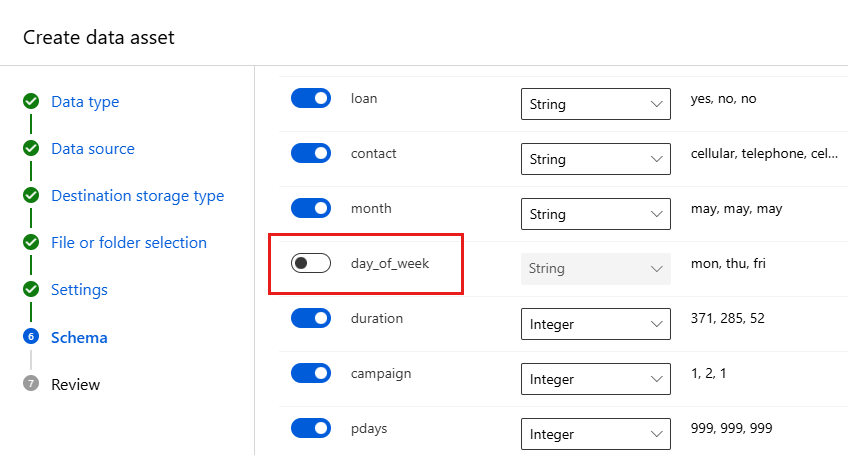
Controleer uw gegevens in het formulier Controleren en selecteer vervolgens Maken.
Selecteer uw gegevensset in de lijst.
Controleer de gegevens door de gegevensasset te selecteren en naar het tabblad Voorbeeld te kijken. Zorg ervoor dat deze geen day_of_week bevat en selecteer Sluiten.
Selecteer Volgende om door te gaan met taakinstellingen.
Taak configureren
Nadat u uw gegevens hebt geladen en geconfigureerd, kunt u uw experiment instellen. Dit installatieprogramma bevat ontwerptaken voor het experiment, zoals, het selecteren van de grootte van uw rekenomgeving en het opgeven van de kolom die u wilt voorspellen.
Vul het formulier Taakinstellingen als volgt in:
Selecteer y (tekenreeks) als doelkolom. Dit is wat u wilt voorspellen. Deze kolom geeft aan of de klant een termijnrekening heeft geopend of niet.
Selecteer Aanvullende configuratie-instellingen weergeven en vul de velden als volgt in. Dankzij deze instellingen kunt u de trainingstaak beter controleren. Anders worden de standaardinstellingen toegepast op basis van de selectie en gegevens van het experiment.
Aanvullende configuraties Beschrijving Waarde voor zelfstudie Primaire metrische gegevens Metrische evaluatiegegevens die worden gebruikt om het machine learning-algoritme te meten. AUCWeighted Uitleg geven over het beste model Hiermee wordt automatisch uitleg gegeven over het beste model dat is gemaakt met geautomatiseerde ML. Inschakelen Geblokkeerde modellen Algoritmen die u niet wilt opnemen in de trainingstaak Geen Selecteer Opslaan.
Onder Valideren en testen:
- Selecteer voor validatietype k-vouwen kruisvalidatie.
- Selecteer 2 voor het aantal kruisvalidaties.
Selecteer Volgende.
Selecteer het rekencluster als rekentype.
Een rekendoel is een resource-omgeving, lokaal of in de cloud, die gebruikt wordt om uw trainingsscript uit te voeren of uw service-implementatie te hosten. Voor dit experiment kunt u een serverloze berekening in de cloud (preview) uitproberen of uw eigen cloudgebaseerde rekenkracht maken.
Notitie
Als u serverloze berekeningen wilt gebruiken, schakelt u de preview-functie in, selecteert u Serverloos en slaat u deze procedure over.
Als u uw eigen rekendoel wilt maken, selecteert u in Rekentype Selecteren het rekencluster om uw rekendoel te configureren.
Vul het formulier Virtuele machine in om de berekening in te stellen. Selecteer Nieuw.
Veld Beschrijving Waarde voor zelfstudie Locatie Uw regio van waaruit u de machine wilt uitvoeren VS - west 2 Virtuele-machinelaag Selecteer de prioriteit die het experiment moet krijgen Toegewezen VM-type Selecteer het type van de virtuele machine voor uw berekening. CPU (Central Processing Unit, centrale verwerkingseenheid) Grootte van de virtuele machine Selecteer de grootte van de virtuele machine voor uw berekening. Er wordt een lijst met aanbevolen grootten geboden, op basis van uw gegevens en het type experiment. Standard_DS12_V2 Selecteer Volgende om naar het formulier Geavanceerde instellingen te gaan.
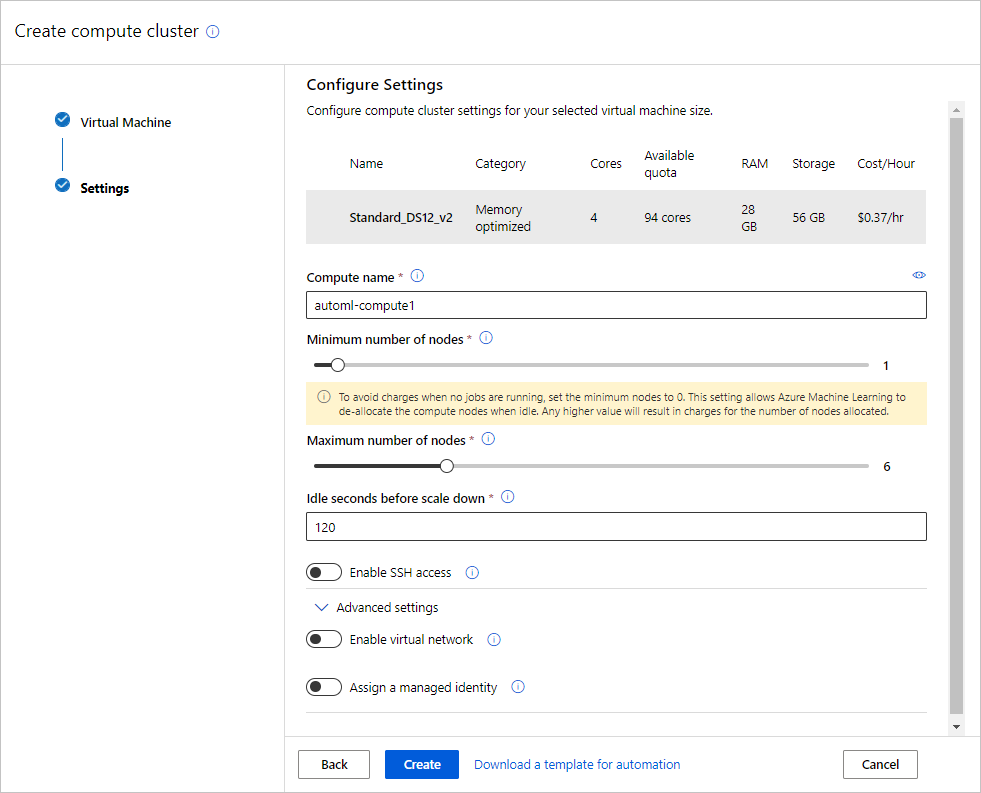
Veld Beschrijving Waarde voor zelfstudie Naam berekening Een unieke naam die de context van uw berekening identificeert. automl-compute Min / Max knooppunten U moet u één of meer knooppunten opgeven om gegevens te profileren. Min. knooppunten: 1
Max. knooppunten: 6Seconden wachten voor omlaag schalen Niet-actieve tijd voordat het cluster automatisch omlaag wordt geschaald naar het minimum aantal knooppunten. 120 (standaardinstelling) Geavanceerde instellingen Instellingen voor het configureren en autoriseren van een virtueel netwerk voor uw experiment. Geen Selecteer Maken.
Het maken van een berekening kan enkele minuten duren.
Nadat u het hebt gemaakt, selecteert u uw nieuwe rekendoel in de lijst. Selecteer Volgende.
Selecteer Trainingstaak verzenden om het experiment uit te voeren. Het scherm Overzicht wordt geopend met de status bovenaan wanneer de voorbereiding van het experiment begint. Deze status wordt bijgewerkt wanneer het experiment wordt uitgevoerd. Meldingen worden ook weergegeven in de studio om u te informeren over de status van uw experiment.

Belangrijk
Het duurt 10-15 minuten om de experimentele uitvoerbewerking voor te bereiden. Zodra de uitvoering is gestart duurt het 2-3 minuten langer per iteratie.
Bij een productie zou u waarschijnlijk even weggaan. Voor deze zelfstudie kunt u echter beginnen met het verkennen van de geteste algoritmen op het tabblad Modellen terwijl ze zijn voltooid terwijl de anderen doorgaan met uitvoeren.
Modellen bekijken
Navigeer naar het tabblad Modellen en onderliggende taken om de geteste algoritmen (modellen) te bekijken. De taak bestelt standaard de modellen op metrische score zodra ze zijn voltooid. Voor deze zelfstudie staat het model dat het hoogste scoren op basis van de gekozen metriek AUCWeighted boven aan de lijst.
Terwijl u wacht tot alle experimentmodellen zijn voltooid, kunt u de Algoritmenaam van een volledig model selecteren om de prestatiedetails te bekijken. Selecteer het tabblad Overzicht en de tabbladen Metrische gegevens voor informatie over de taak.
In de volgende animatie worden de eigenschappen, metrische gegevens en prestatiegrafieken van het geselecteerde model weergegeven.

Modeluitleg weergeven
Terwijl u wacht tot de modellen zijn voltooid, kunt u ook modeluitleg bekijken en zien welke gegevensfuncties (onbewerkt of ontworpen) de voorspellingen van een bepaald model hebben beïnvloed.
Deze modeluitleg kan op aanvraag worden gegenereerd. Het dashboard voor modeluitleg dat deel uitmaakt van het tabblad Uitleg (preview) bevat een overzicht van deze uitleg.
Modeluitleg genereren:
Selecteer in de navigatiekoppelingen boven aan de pagina de taaknaam om terug te gaan naar het scherm Modellen .
Selecteer het tabblad Modellen en onderliggende taken .
Voor deze zelfstudie selecteert u het eerste Model MaxAbsScaler, LightGBM .
Selecteer Model uitleggen. Aan de rechterkant wordt het deelvenster Model uitleggen weergegeven.
Selecteer uw rekentype en selecteer vervolgens het exemplaar of cluster: automl-compute die u eerder hebt gemaakt. Met deze berekening wordt een onderliggende taak gestart om de modeluitleg te genereren.
Selecteer Maken. Er wordt een groen succesbericht weergegeven.
Notitie
Het duurt ongeveer 2-5 minuten om de uitlegtaak te voltooien.
Selecteer Uitleg (preview). Dit tabblad wordt ingevuld nadat de uitvoering van de uitleg is voltooid.
Vouw het deelvenster aan de linkerkant uit. Selecteer onder Functies de rij met onbewerkte tekst.
Selecteer het tabblad Urgentie van statistische functies. In deze grafiek ziet u welke gegevensfuncties invloed hebben gehad op de voorspellingen van het geselecteerde model.

In dit voorbeeld lijkt de duur de meeste invloed te hebben op de voorspellingen van dit model.

Het beste model implementeren
Met de geautomatiseerde machine learning-interface kunt u het beste model implementeren als een webservice. Implementatie is de integratie van het model, zodat het nieuwe gegevens kan voorspellen en potentiële kansengebieden kan identificeren. Voor dit experiment betekent de implementatie naar een webservice dat de financiële instelling nu een iteratieve en schaalbare weboplossing heeft om potentiële klanten voor termijnrekeningen te identificeren.
Controleer of de uitvoering van het experiment is voltooid. Hiervoor gaat u terug naar de bovenliggende taakpagina door de taaknaam boven aan het scherm te selecteren. In de linkerbovenhoek van het scherm wordt de status Voltooid weergegeven.
Nadat de uitvoering van het experiment is voltooid, wordt de pagina Details gevuld met een overzichtssectie van het beste model . In deze experimentcontext wordt VotingEnsemble beschouwd als het beste model, op basis van de metrische waarde AUCWeighted .
Implementeer dit model. De implementatie duurt ongeveer 20 minuten. Het implementatieproces omvat verschillende stappen, waaronder het model registreren, resources genereren en ze configureren voor de webservice.
Selecteer VotingEnsemble om de model-specifieke pagina te openen.
Selecteer .
Vul het deelvenster Een model implementeren als volgt in:
Veld Weergegeven als Naam my-automl-deploy Beschrijving Implementatie van mijn eerste geautomatiseerde machine learning-experiment Rekentype Azure Container Instance selecteren Verificatie inschakelen Uitgeschakeld. Aangepaste implementatie-assets gebruiken Uitgeschakeld. Staat toe dat het standaard stuurprogrammabestand (scorescript) en het omgevingsbestand automatisch gegenereerd worden. Gebruik voor dit voorbeeld de standaardwaarden in het menu Geavanceerd .
Selecteer Implementeren.
Bovenaan het scherm Taak wordt een groen bericht weergegeven. In het deelvenster Modelsamenvatting wordt een statusbericht weergegeven onder Implementatiestatus. Selecteer regelmatig Vernieuwen om de implementatiestatus te controleren.
U hebt een operationele webservice voor het genereren van voorspellingen.
Ga verder met de gerelateerde inhoud voor meer informatie over het gebruik van uw nieuwe webservice en test uw voorspellingen met behulp van ingebouwde Ondersteuning voor Azure Machine Learning van Power BI.
Resources opschonen
Implementatiebestanden zijn groter dan gegevens- en experimentbestanden. Daarom kost het meer om ze op te slaan. Als u uw werkruimte- en experimentbestanden wilt behouden, verwijdert u alleen de implementatiebestanden om de kosten voor uw account te minimaliseren. Als u niet van plan bent een van de bestanden te gebruiken, verwijdert u de hele resourcegroep.
Het implementatie-exemplaar verwijderen
Alleen het implementatie-exemplaar verwijderen uit Azure Machine Learning op https://ml.azure.com/.
Ga naar Azure Machine Learning. Navigeer naar uw werkruimte en selecteer onder het deelvenster Assets eindpunten.
Selecteer de implementatie die u wilt verwijderen en vervolgens Verwijderen.
Selecteer Doorgaan.
De resourcegroep verwijderen
Belangrijk
De resources die u hebt gemaakt, kunnen worden gebruikt als de vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Als u niet van plan bent om een van de resources te gebruiken die u hebt gemaakt, verwijdert u deze zodat er geen kosten in rekening worden gebracht:
Voer in azure Portal in het zoekvak resourcegroepen in en selecteer deze in de resultaten.
Selecteer de resourcegroep die u hebt gemaakt uit de lijst.
Selecteer op de pagina Overzicht de optie Resourcegroep verwijderen.
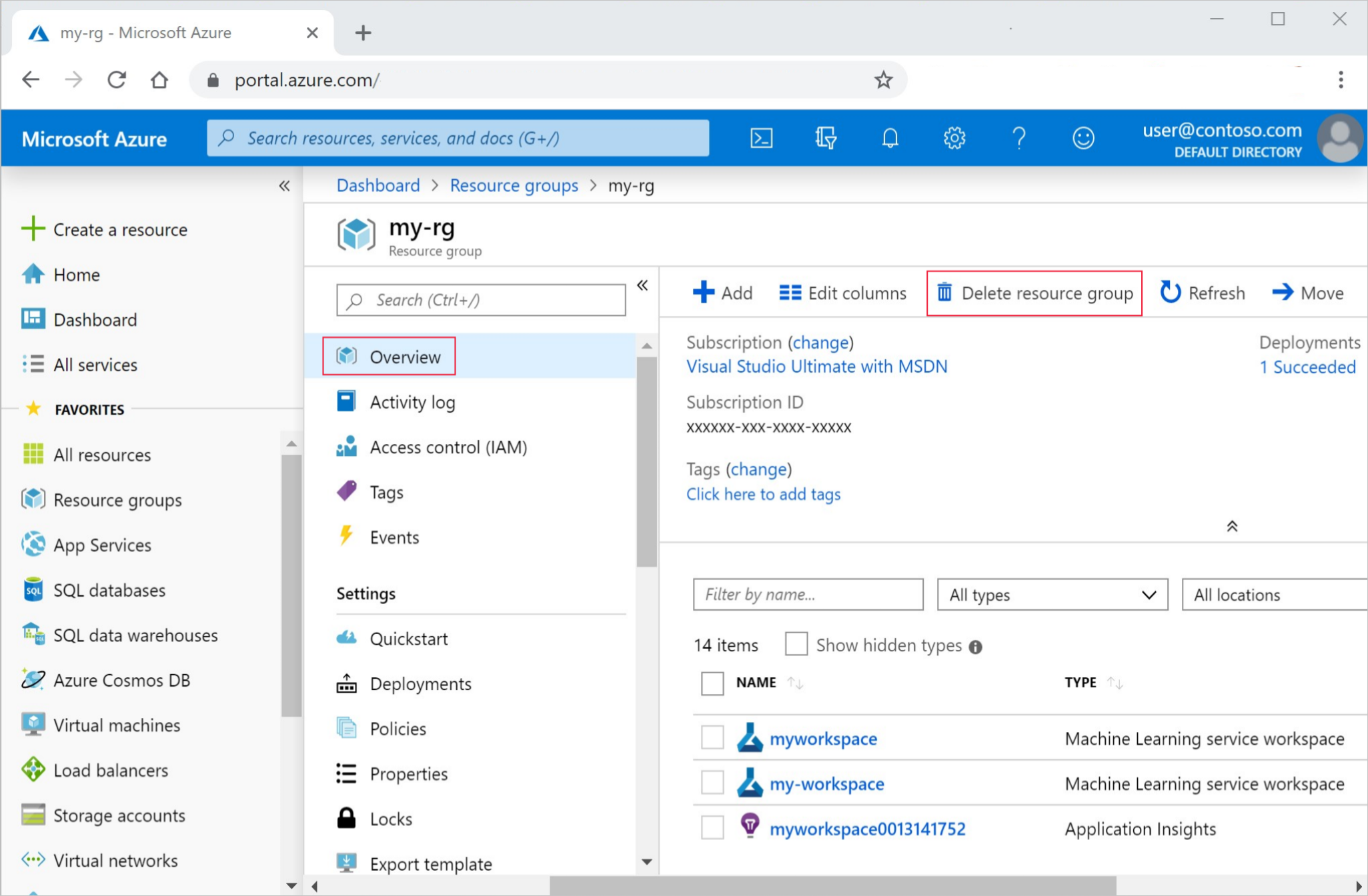
Voer de naam van de resourcegroup in. Selecteer daarna Verwijderen.
Gerelateerde inhoud
In deze zelfstudie over geautomatiseerde machine learning heeft u de geautomatiseerde ML-interface van Azure Machine Learning gebruikt om een classificatiemodel te maken en implementeren. Zie de volgende bronnen voor meer informatie en volgende stappen:
- Meer informatie over geautomatiseerde machine learning.
- Meer informatie over metrische gegevens en grafieken voor classificatie: artikel met resultaten van geautomatiseerde machine learning-experimenten evalueren.
- Meer informatie over het instellen van AutoML voor NLP.
Probeer ook geautomatiseerde machine learning voor deze andere modeltypen:
- Zie Zelfstudie: Vraag voorspellen met geautomatiseerde machine learning zonder code in de Azure Machine Learning-studio voor een voorbeeld van prognose.
- Zie de zelfstudie: Een objectdetectiemodel trainen met AutoML en Python voor een codevoorbeeld van een objectdetectiemodel.