Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
VAN TOEPASSING OP: Python SDK azure-ai-ml v2 (actueel)
Python SDK azure-ai-ml v2 (actueel)
Notitie
Zie Zelfstudie: Een Azure Machine Learning-pijplijn bouwen voor afbeeldingsclassificatie voor een zelfstudie waarin SDK v1 wordt gebruikt om een pijplijn te bouwen.
Een machine learning-pijplijn splitst een volledige machine learning-taak in een werkstroom met meerdere stappen. Elke stap is een beheerbaar onderdeel dat u afzonderlijk kunt ontwikkelen, optimaliseren, configureren en automatiseren. Goed gedefinieerde interfaces verbinden stappen. De Azure Machine Learning-pijplijnservice organiseert alle afhankelijkheden tussen de pijplijnstappen.
De voordelen van het gebruik van een pijplijn zijn gestandaardiseerde MLOps-praktijken, schaalbare teamsamenwerking, trainingsefficiëntie en kostenreductie. Zie Wat zijn Azure Machine Learning-pijplijnen voor meer informatie over de voordelen van pijplijnen.
In deze zelfstudie gebruikt u Azure Machine Learning om een machine learning-project voor productie te maken met behulp van Azure Machine Learning Python SDK v2. Na deze zelfstudie kunt u de Azure Machine Learning Python SDK gebruiken voor het volgende:
- Een ingang krijgen voor uw Azure Machine Learning-werkruimte
- Azure Machine Learning-gegevensassets maken
- Herbruikbare Azure Machine Learning-onderdelen maken
- Azure Machine Learning-pijplijnen maken, valideren en uitvoeren
Tijdens deze zelfstudie maakt u een Azure Machine Learning-pijplijn om een model te trainen voor standaardvoorspelling voor tegoed. De pijplijn verwerkt twee stappen:
- Gegevensvoorbereiding
- Het getrainde model trainen en registreren
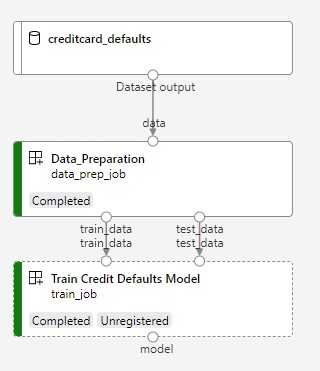
In de volgende afbeelding ziet u een eenvoudige pijplijn zoals u deze ziet in Azure Studio nadat u deze hebt verzonden.
De twee stappen zijn gegevensvoorbereiding en training.
In deze video ziet u hoe u aan de slag gaat in Azure Machine Learning-studio, zodat u de stappen in de zelfstudie kunt volgen. In de video ziet u hoe u een notebook maakt, een rekenproces maakt en het notebook kloont. In de volgende secties worden deze stappen ook beschreven.
Vereisten
-
Als u Azure Machine Learning wilt gebruiken, hebt u een werkruimte nodig. Als u er nog geen hebt, voltooit u Resources maken die u nodig hebt om aan de slag te gaan met het maken van een werkruimte en meer informatie over het gebruik ervan.
Belangrijk
Als uw Azure Machine Learning-werkruimte is geconfigureerd met een beheerd virtueel netwerk, moet u mogelijk uitgaande regels toevoegen om toegang tot de openbare Python-pakketopslagplaatsen toe te staan. Zie Scenario: Toegang tot openbare machine learning-pakketten voor meer informatie.
-
Meld u aan bij de studio en selecteer uw werkruimte als deze nog niet is geopend.
Voltooi de zelfstudie Upload, open en verken uw gegevens om de gegevensasset te maken die u nodig hebt in deze zelfstudie. Zorg ervoor dat u alle code uitvoert om de eerste gegevensasset te maken. U kunt de gegevens verkennen en desgewenst herzien, maar u hebt alleen de initiële gegevens voor deze zelfstudie nodig.
-
Open of maak een notitieblok in uw werkruimte:
- Als u code in cellen wilt kopiëren en plakken, maakt u een nieuw notitieblok.
- U kunt ook zelfstudies/get-started-notebooks/pipeline.ipynb openen vanuit de sectie Voorbeelden van studio. Selecteer Vervolgens Klonen om het notitieblok toe te voegen aan uw bestanden. Zie Learn from sample notebooks(Learn from sample notebooks) (Learn from sample notebooks) voor meer informatie over voorbeeldnotebooks.
Uw kernel instellen en openen in Visual Studio Code (VS Code)
Maak op de bovenste balk boven het geopende notitieblok een rekenproces als u er nog geen hebt.

Als het rekenproces is gestopt, selecteert u Rekenproces starten en wacht u totdat het wordt uitgevoerd.

Wacht totdat het rekenproces wordt uitgevoerd. Zorg er vervolgens voor dat de kernel, in de rechterbovenhoek, is
Python 3.10 - SDK v2. Als dit niet het probleem is, gebruikt u de vervolgkeuzelijst om deze kernel te selecteren.
Als u deze kernel niet ziet, controleert u of uw rekenproces wordt uitgevoerd. Als dat het is, selecteert u de knop Vernieuwen rechtsboven in het notitieblok.
Als u een banner ziet met de melding dat u moet worden geverifieerd, selecteert u Verifiëren.
U kunt het notebook hier uitvoeren of openen in VS Code voor een volledige IDE (Integrated Development Environment) met de kracht van Azure Machine Learning-resources. Selecteer Openen in VS Code en selecteer vervolgens de optie web of bureaublad. Bij het starten op deze manier wordt VS Code gekoppeld aan uw rekenproces, de kernel en het bestandssysteem van de werkruimte.





Belangrijk
De rest van deze zelfstudie bevat cellen van het zelfstudienotitieblok. Kopieer en plak deze in uw nieuwe notitieblok of ga nu naar het notitieblok als u het hebt gekloond.
De pijplijnbronnen instellen
U kunt het Azure Machine Learning framework gebruiken vanuit de Azure CLI, de Python SDK of de Studio-interface. In dit voorbeeld gebruikt u de Azure Machine Learning Python SDK v2 om een pijplijn te maken.
Voordat u de pijplijn maakt, hebt u deze resources nodig:
- De gegevensasset voor training
- De softwareomgeving voor het uitvoeren van de pijplijn
- Een rekenresource waarin de taak wordt uitgevoerd
Greep maken voor werkruimte
Voordat u de code gebruikt, hebt u een manier nodig om naar uw werkruimte te verwijzen. Maak ml_client als ingang voor de werkruimte. U gebruikt vervolgens ml_client om resources en taken te beheren.
Voer in de volgende cel uw abonnements-id, resourcegroepnaam en werkruimtenaam in. Deze waarden zoeken:
- Selecteer in de rechterbovenhoek Azure Machine Learning-studio werkbalk de naam van uw werkruimte.
- Kopieer de waarde voor werkruimte, resourcegroep en abonnements-id naar de code. U moet één waarde kopiëren, het gebied sluiten en plakken en vervolgens teruggaan naar de volgende waarde.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
SDK-documentatie:
Notitie
Het maken van MLClient maakt geen verbinding met de werkruimte. De initialisatie van de client is lui. Hij wacht tot de eerste keer dat het een oproep moet doen. Initialisatie vindt plaats in de volgende codecel.
Controleer de verbinding door een aanroep naar ml_client. Omdat deze aanroep de eerste keer is dat u de werkruimte aanroept, wordt u mogelijk gevraagd om te verifiëren.
# Verify that the handle works correctly.
# If you get an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
SDK-documentatie:
Toegang tot de geregistreerde gegevensasset
Begin met het ophalen van de gegevens die u eerder hebt geregistreerd in zelfstudie: Uw gegevens uploaden, openen en verkennen in Azure Machine Learning.
Notitie
Azure Machine Learning maakt gebruik van een Data object om een herbruikbare definitie van gegevens te registreren en gegevens in een pijplijn te gebruiken.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
SDK-documentatie:
Een taakomgeving maken voor pijplijnstappen
Tot nu toe hebt u een ontwikkelomgeving gemaakt op het rekenproces, uw ontwikkelcomputer. U hebt ook een omgeving nodig die moet worden gebruikt voor elke stap van de pijplijn. Elke stap kan een eigen omgeving hebben of u kunt enkele algemene omgevingen gebruiken voor meerdere stappen.
In dit voorbeeld maakt u een conda-omgeving voor uw taken met behulp van een conda yaml-bestand. Maak eerst een map waarin het bestand moet worden opgeslagen.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Maak nu het bestand in de map afhankelijkheden.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.10
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
De specificatie bevat enkele gebruikelijke pakketten die u in uw pijplijn (numpy, pip) gebruikt, samen met enkele azure Machine Learning-specifieke pakketten (azureml-mlflow).
De Azure Machine Learning-pakketten zijn niet vereist om Azure Machine Learning-taken uit te voeren. Door deze pakketten toe te voegen, kunt u communiceren met Azure Machine Learning voor het vastleggen van metrische gegevens en het registreren van modellen, allemaal binnen de Azure Machine Learning-taak. U gebruikt ze in het trainingsscript verderop in deze zelfstudie.
Gebruik het YAML-bestand om deze aangepaste omgeving in uw werkruimte te maken en te registreren:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
SDK-documentatie:
De trainingspijplijn bouwen
Nu u alle assets hebt die nodig zijn om uw pijplijn uit te voeren, is het tijd om de pijplijn zelf te bouwen.
Azure Machine Learning-pijplijnen zijn herbruikbare ML-werkstromen die meestal bestaan uit verschillende onderdelen. De typische levenscyclus van een onderdeel is:
- Schrijf de YAML-specificatie van het onderdeel of maak het programmatisch met behulp van
ComponentMethod. - Registreer het onderdeel eventueel met een naam en versie in uw werkruimte om het herbruikbaar en deelbaar te maken.
- Laad dat onderdeel vanuit de pijplijncode.
- Implementeer de pijplijn met behulp van de invoer, uitvoer en parameters van het onderdeel.
- Verzend de pijplijn.
U kunt een onderdeel op twee manieren maken: programmatische definitie en YAML-definitie. In de volgende twee secties leert u hoe u een onderdeel op beide manieren maakt. U kunt de twee onderdelen maken door beide opties uit te proberen of de gewenste methode te kiezen.
Notitie
In deze zelfstudie gebruikt u voor het gemak dezelfde rekenkracht voor alle onderdelen. U kunt echter verschillende berekeningen instellen voor elk onderdeel. U kunt bijvoorbeeld een regel toevoegen zoals train_step.compute = "cpu-cluster". Als u een voorbeeld wilt bekijken van het bouwen van een pijplijn met verschillende berekeningen voor elk onderdeel, raadpleegt u de sectie Basispijplijntaak in de zelfstudie cifar-10-pijplijn.
Onderdeel 1 maken: gegevensvoorbereiding (met behulp van programmatische definitie)
Begin met het maken van het eerste onderdeel. Dit onderdeel verwerkt het voorverwerken van de gegevens. De voorverwerkingstaak wordt uitgevoerd in het data_prep.py Python-bestand.
Maak eerst een bronmap voor het data_prep-onderdeel:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Met dit script wordt de eenvoudige taak uitgevoerd voor het splitsen van de gegevens in gegevenssets voor het trainen en testen van gegevenssets. Azure Machine Learning koppelt gegevenssets als mappen aan de berekeningen. U hebt een hulpfunctie select_first_file gemaakt voor toegang tot het gegevensbestand in de gekoppelde invoermap.
MLFlow wordt gebruikt om de parameters en metrische gegevens te registreren tijdens de pijplijnuitvoering.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Nu u een script hebt dat de gewenste taak kan uitvoeren, maakt u er een Azure Machine Learning-onderdeel van.
Gebruik het algemene doel CommandComponent waarmee opdrachtregelacties kunnen worden uitgevoerd. Met deze opdrachtregelactie kunt u systeemopdrachten rechtstreeks aanroepen of een script uitvoeren. De invoer en uitvoer worden opgegeven op de opdrachtregel met behulp van de ${{ ... }} notatie.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
SDK-documentatie:
Registreer eventueel het onderdeel in de werkruimte voor toekomstig hergebruik.
# Now register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create and register the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
SDK-documentatie:
Onderdeel 2 maken: training (met yaml-definitie)
Het tweede onderdeel dat u maakt, verbruikt de trainings- en testgegevens, traint een model op basis van een structuur en retourneert het uitvoermodel. Gebruik de mogelijkheden voor logboekregistratie van Azure Machine Learning om de voortgang van het leren vast te leggen en te visualiseren.
U hebt de CommandComponent klasse gebruikt om uw eerste onderdeel te maken. Deze keer gebruikt u de yaml-definitie om het tweede onderdeel te definiëren. Elke methode heeft zijn eigen voordelen. Een YAML-definitie kan samen met de code worden ingecheckt en zorgt voor een leesbare geschiedenisregistratie. De programmatische methode die wordt gebruikt CommandComponent , kan eenvoudiger zijn met ingebouwde klassedocumentatie en het voltooien van code.
Maak de map voor dit onderdeel:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Maak het trainingsscript in de map:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Zoals u in dit trainingsscript kunt zien, wordt het modelbestand opgeslagen en geregistreerd bij de werkruimte nadat het model is getraind. U kunt nu het geregistreerde model gebruiken in deductie-eindpunten.
Voor de omgeving van deze stap gebruikt u een van de ingebouwde (gecureerde) Azure Machine Learning-omgevingen. De tag azureml vertelt het systeem om te zoeken naar de naam in gecureerde omgevingen.
Maak eerst het YAML-bestand met een beschrijving van het onderdeel:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Maak en registreer nu het onderdeel. Als u deze registreert, kunt u deze opnieuw gebruiken in andere pijplijnen. Iedereen met toegang tot uw werkruimte kan ook het geregistreerde onderdeel gebruiken.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create and register the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
SDK-documentatie:
De pijplijn maken op basis van onderdelen
Nadat u de onderdelen hebt gedefinieerd en geregistreerd, begint u met het implementeren van de pijplijn.
De Python-functies die load_component() retourneren, werken net als elke reguliere Python-functie. Gebruik deze in een pijplijn om elke stap aan te roepen.
Als u de pijplijn wilt coderen, gebruikt u een specifieke @dsl.pipeline decorator waarmee de Azure Machine Learning-pijplijnen worden geïdentificeerd. Geef in de decorator de beschrijving van de pijplijn en de standaardresources op, zoals compute en opslag. Net als bij een Python-functie kunnen pijplijnen invoer hebben. U kunt meerdere exemplaren van één pijplijn met verschillende invoerwaarden maken.
Gebruik in het volgende voorbeeld invoergegevens, split ratio en geregistreerde modelnaam als invoervariabelen. Roep vervolgens de onderdelen aan en verbind ze met behulp van hun invoer- en uitvoer-id's. Open de uitvoer van elke stap met behulp van de .outputs eigenschap.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
SDK-documentatie:
Gebruik nu uw pijplijndefinitie om een pijplijn te instantiëren met uw gegevensset, splitssnelheid naar keuze en de naam die u voor uw model hebt gekozen.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
SDK-documentatie:
De taak verzenden
Verzend nu de taak die moet worden uitgevoerd in Azure Machine Learning. Gebruik deze keer create_or_update op ml_client.jobs.
Geef een experimentnaam door. Een experiment is een container voor alle iteraties die één voor een bepaald project uitvoert. Alle taken die onder dezelfde experimentnaam zijn ingediend, worden naast elkaar weergegeven in Azure Machine Learning Studio.
Nadat dit is voltooid, registreert de pijplijn een model in uw werkruimte als resultaat van de training.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
SDK-documentatie:
U kunt de voortgang van uw pijplijn bijhouden met behulp van de koppeling die in de vorige cel is gegenereerd. Wanneer u deze link voor het eerst selecteert, ziet u mogelijk dat de pijplijn nog steeds actief is. Wanneer dit is voltooid, kunt u de resultaten van elk onderdeel bekijken.
Dubbelklik op het onderdeel Standaardmodel train credit.
Twee belangrijke resultaten die u wilt zien over training:
Uw logboeken weergeven:
- Selecteer het tabblad Uitvoer+logboeken .
- Open de mappen in
user_logs>std_log.txtdeze sectie met de scriptuitvoering stdout.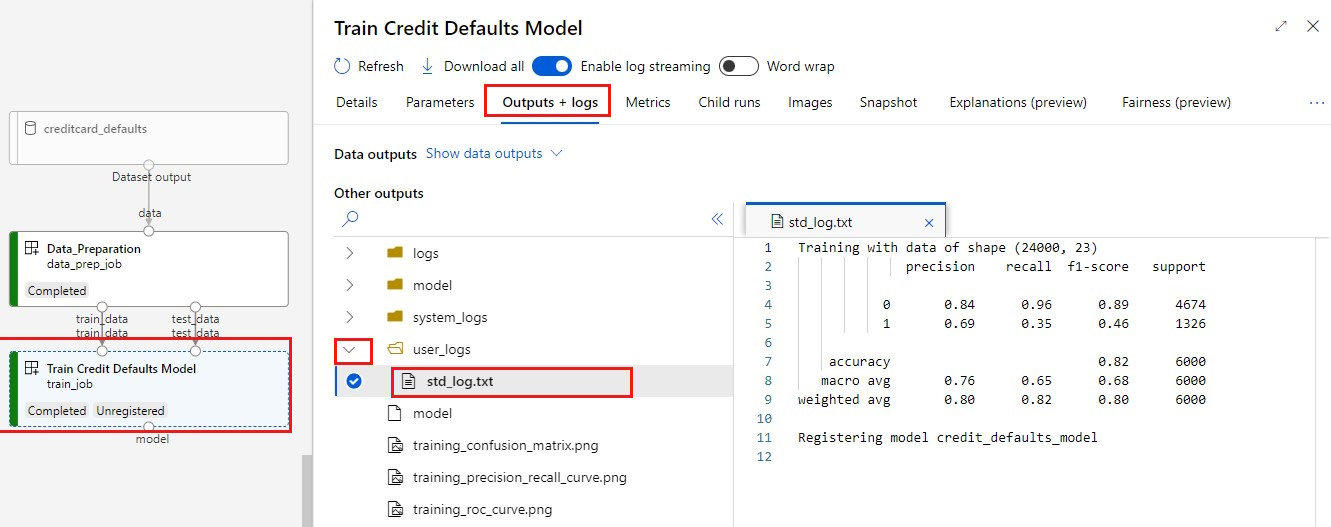
Uw metrische gegevens weergeven: selecteer het tabblad Metrische gegevens . In deze sectie worden verschillende vastgelegde metrische gegevens weergegeven. In dit voorbeeld registreert mlflow
autologgingautomatisch de metrische trainingsgegevens.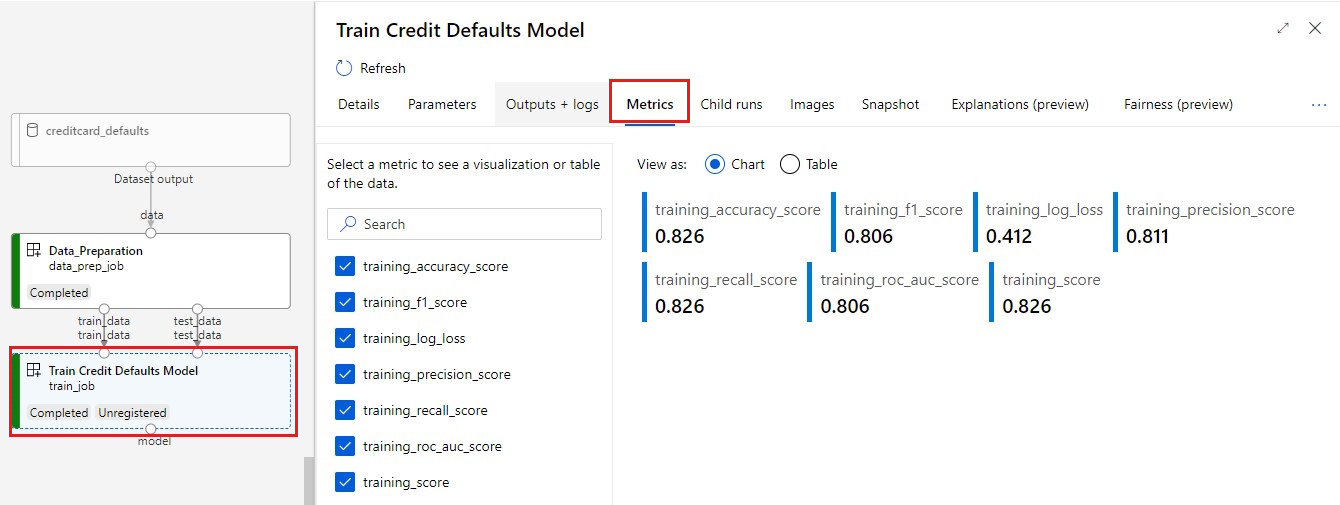


Het model implementeren als een online-eindpunt
Zie voor meer informatie over het implementeren van uw model naar een online-eindpunt de zelfstudie Een model implementeren als online-eindpunt.
Resources opschonen
Als u van plan bent om andere tutorials te volgen, sla dan over naar de volgende stap.
Rekenproces stoppen
Als u de rekeninstantie nu niet gaat gebruiken, stop deze dan.
- Selecteer Compute in de studio in het linkerdeelvenster.
- Selecteer Compute-exemplaren op de bovenste tabbladen.
- Selecteer het rekenproces in de lijst.
- Selecteer Stoppen op de bovenste werkbalk.
Alle resources verwijderen
Belangrijk
De resources die u hebt gemaakt, kunnen worden gebruikt als de vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Als u niet van plan bent om een van de resources te gebruiken die u hebt gemaakt, verwijdert u deze zodat er geen kosten in rekening worden gebracht:
Voer in azure Portal in het zoekvak resourcegroepen in en selecteer deze in de resultaten.
Selecteer de resourcegroep die u hebt gemaakt uit de lijst.
Selecteer op de pagina Overzicht de optie Resourcegroep verwijderen.
Voer de naam van de resourcegroup in. Selecteer daarna Verwijderen.