Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
AI-agents transformeren de interactie van toepassingen met gegevens door grote taalmodellen (LLM's) te combineren met externe hulpprogramma's en databases. Agents maken het mogelijk om complexe werkstromen te automatiseren, de nauwkeurigheid van het ophalen van gegevens te verbeteren en interfaces in natuurlijke taal naar databases te vergemakkelijken.
In dit artikel wordt beschreven hoe u intelligente AI-agents kunt maken die uw gegevens kunnen doorzoeken en analyseren in Azure Database for PostgreSQL. Het begeleidt bij het instellen, implementeren en testen met behulp van een juridische onderzoeksassistent als voorbeeld.
Wat zijn AI-agents?
AI-agents gaan verder dan eenvoudige chatbots door LLM's te combineren met externe hulpprogramma's en databases. In tegenstelling tot zelfstandige LLM's of standaard retrieval-augmented generation (RAG) systemen, kunnen AI agents:
- Plan: complexe taken opsplitsen in kleinere, opeenvolgende stappen.
- Hulpprogramma's gebruiken: API's, codeuitvoering en zoeksystemen gebruiken om informatie te verzamelen of acties uit te voeren.
- Begrijpen: Begrijpen en verwerken van inputs uit verschillende gegevensbronnen.
- Vergeet niet: Sla eerdere interacties op en herinner ze eraan voor betere besluitvorming.
Door AI-agents te verbinden met databases zoals Azure Database for PostgreSQL, kunnen agents nauwkeurigere, contextbewuste antwoorden leveren op basis van uw gegevens. AI-agents gaan verder dan eenvoudige menselijke gesprekken om taken uit te voeren op basis van natuurlijke taal. Deze taken vereist traditioneel gecodeerde logica. Agents kunnen echter de taken plannen die nodig zijn om uit te voeren op basis van door de gebruiker verstrekte context.
Implementatie van AI-agents
Het implementeren van AI-agents met Azure Database for PostgreSQL omvat het integreren van geavanceerde AI-mogelijkheden met robuuste databasefunctionaliteiten om intelligente, contextbewuste systemen te maken. Met behulp van hulpprogramma's zoals vectorzoekopdrachten, insluitingen en Foundry Agent Service kunnen ontwikkelaars agents bouwen die query's in natuurlijke taal begrijpen, relevante gegevens ophalen en bruikbare inzichten bieden.
In de volgende secties wordt het stapsgewijze proces beschreven voor het instellen, configureren en implementeren van AI-agents. Dit proces maakt naadloze interactie mogelijk tussen AI-modellen en uw PostgreSQL-database.
Raamwerken
Verschillende frameworks en hulpprogramma's kunnen de ontwikkeling en implementatie van AI-agents vergemakkelijken. Al deze frameworks ondersteunen het gebruik van Azure Database for PostgreSQL als hulpprogramma:
Voorbeeld van implementatie
In dit artikel wordt gebruikgemaakt van agentservice voor het plannen, gebruiken van hulpprogramma's en perceptie van agents. Azure Database for PostgreSQL wordt gebruikt als hulpprogramma voor vectordatabases en semantische zoekmogelijkheden.
In de volgende secties wordt u begeleid bij het bouwen van een AI-agent waarmee juridische teams relevante cases kunnen onderzoeken om hun klanten in Washington State te ondersteunen. De agent:
- Accepteert query's in natuurlijke taal over juridische situaties.
- Gebruikt vectorzoekopdrachten in Azure Database for PostgreSQL om relevante jurisprudentie te vinden.
- Analyseert en vat de bevindingen samen in een nuttige indeling voor juridische professionals.
Vereiste voorwaarden
Installeer Visual Studio Code.
Installeer de Python-extensie .
Installeer Python 3.11.x.
Installeer de Azure CLI (nieuwste versie).
Opmerking
U hebt de sleutel en het eindpunt nodig van de geïmplementeerde modellen die u voor de agent hebt gemaakt.
Aan de slag
Alle code- en voorbeeldgegevenssets zijn beschikbaar in deze GitHub-opslagplaats.
Stap 1: Vector Search instellen in Azure Database for PostgreSQL
Bereid eerst uw database voor om juridische casegegevens op te slaan en te doorzoeken met behulp van vector-insluitingen.
De omgeving instellen
Als u macOS en Bash gebruikt, voert u deze opdrachten uit:
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
Als u Windows en PowerShell gebruikt, voert u deze opdrachten uit:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
Als u Windows gebruikt en cmd.exevoert u de volgende opdrachten uit:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
Omgevingsvariabelen configureren
Maak een .env bestand met uw referenties:
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
Laden van documenten en vectoren
Het Python-bestand load_data/main.py fungeert als het centrale toegangspunt voor het laden van gegevens in Azure Database for PostgreSQL. De code verwerkt de gegevens voor voorbeeldcases, inclusief informatie over zaken in Washington.
Het bestand main.py:
- Hiermee maakt u de benodigde extensies, stelt u OpenAI API-instellingen in en beheert u databasetabellen door bestaande tabellen te verwijderen en nieuwe te maken voor het opslaan van casegegevens.
- Leest gegevens uit een CSV-bestand en voegt deze in een tijdelijke tabel in en verwerkt en draagt deze vervolgens over in de hoofdcasetabel.
- Voegt een nieuwe kolom toe voor insluitingen in de casetabel en genereert insluitingen voor caseadviezen met behulp van de API van OpenAI. De embeddings worden opgeslagen in de nieuwe kolom. Het insluitproces duurt ongeveer 3 tot 5 minuten.
Voer de volgende opdracht uit vanuit de load_data map om het proces voor het laden van gegevens te starten:
python main.py
Hier volgt de uitvoer van main.py:
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
Stap 2: Een Postgres-hulpprogramma voor de agent maken
Configureer vervolgens ai-agenthulpprogramma's om gegevens op te halen uit Postgres. Gebruik vervolgens de Agent Service SDK om uw AI-agent te verbinden met de Postgres-database.
Een functie definiëren die door uw agent moet worden aangeroepen
Begin met het definiëren van een functie die uw agent moet aanroepen door de structuur en de vereiste parameters in een docstring te beschrijven. Neem al uw functiedefinities op in één bestand legal_agent_tools.py. Vervolgens kunt u het bestand importeren in het hoofdscript.
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch case information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
Stap 3: De AI-agent maken en configureren met Postgres
Stel nu de AI-agent in en integreer deze met het Postgres-hulpprogramma. Het Python-bestand src/simple_postgres_and_ai_agent.py fungeert als het centrale toegangspunt voor het maken en gebruiken van uw agent.
Het bestand simple_postgres_and_ai_agent.py:
- Initialiseert de agent in uw Foundry-project door gebruik te maken van een specifiek model.
- Hiermee voegt u het Postgres-hulpprogramma voor vectorzoekopdrachten in uw database toe tijdens de initialisatie van de agent.
- Hiermee configureert u een communicatiethread. Deze thread wordt gebruikt om berichten naar de agent te verzenden voor verwerking.
- Verwerkt de query van de gebruiker met behulp van de agent en hulpprogramma's. De agent kan plannen met hulpprogramma's om het juiste antwoord te krijgen. In dit gebruiksscenario roept de agent het Hulpprogramma Postgres aan op basis van de functiehandtekening en docstring om een vectorzoekopdracht uit te voeren en de relevante gegevens op te halen om de vraag te beantwoorden.
- Geeft het antwoord van de agent op de query van de gebruiker weer.
De projectverbindingsreeks zoeken in Foundry
In uw Foundry-project vindt u de verbindingsreeks van uw project op de overzichtspagina van het project. U gebruikt deze tekenreeks om het project te verbinden met de Agent Service SDK. Voeg deze tekenreeks toe aan het .env bestand.
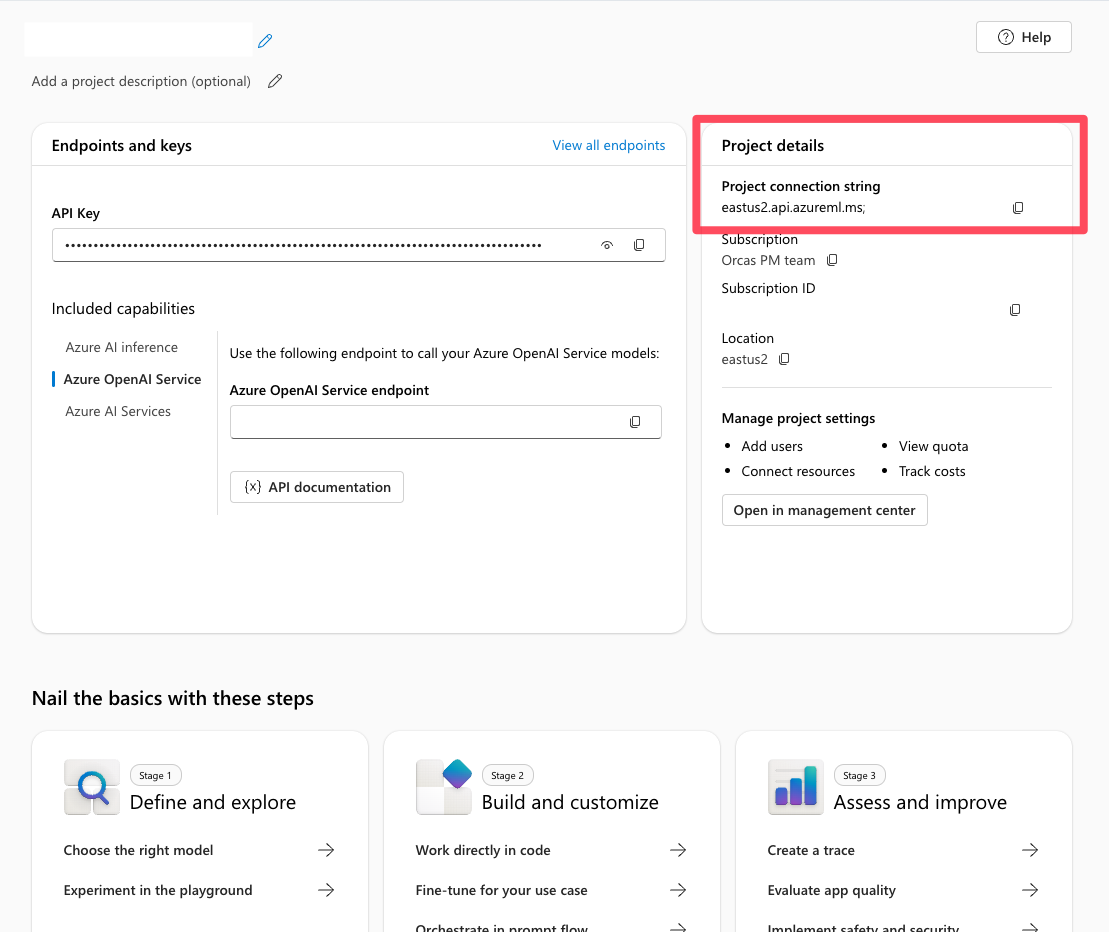
De verbinding instellen
Voeg deze variabelen toe aan uw .env bestand in de hoofdmap:
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the agent with tool access
We created the agent in the Foundry project and added the Postgres tools needed to query the database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/azure-ai-agent-service/src/simple_postgres_and_ai_agent.py).
# Create a Foundry client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize the agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
Een communicatiethread maken
Dit codefragment laat zien hoe u een agentthread en -bericht maakt, die door de agent in een uitvoering wordt verwerkt:
# Create a thread for communication
thread = project_client.agents.create_thread()
# Create a message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
De aanvraag verwerken
Met het volgende codefragment wordt een uitvoering voor de agent gemaakt om het bericht te verwerken en de juiste hulpprogramma's te gebruiken om het beste resultaat te bieden.
Met behulp van de hulpprogramma's kan de agent Postgres en de vectorzoekopdracht aanroepen op de query 'Water die uit de verdieping erboven naar het appartement lekt' om de gegevens op te halen die nodig zijn om de vraag het beste te beantwoorden.
from pprint import pprint
# Create and process an agent run in the thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
De agent uitvoeren
Voer de volgende opdracht uit vanuit de src map om de agent uit te voeren:
python simple_postgres_and_ai_agent.py
De agent produceert een vergelijkbaar resultaat met behulp van het hulpprogramma Azure Database for PostgreSQL voor toegang tot casegegevens die zijn opgeslagen in de Postgres-database.
Hier volgt een uitvoerfragment van de agent:
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
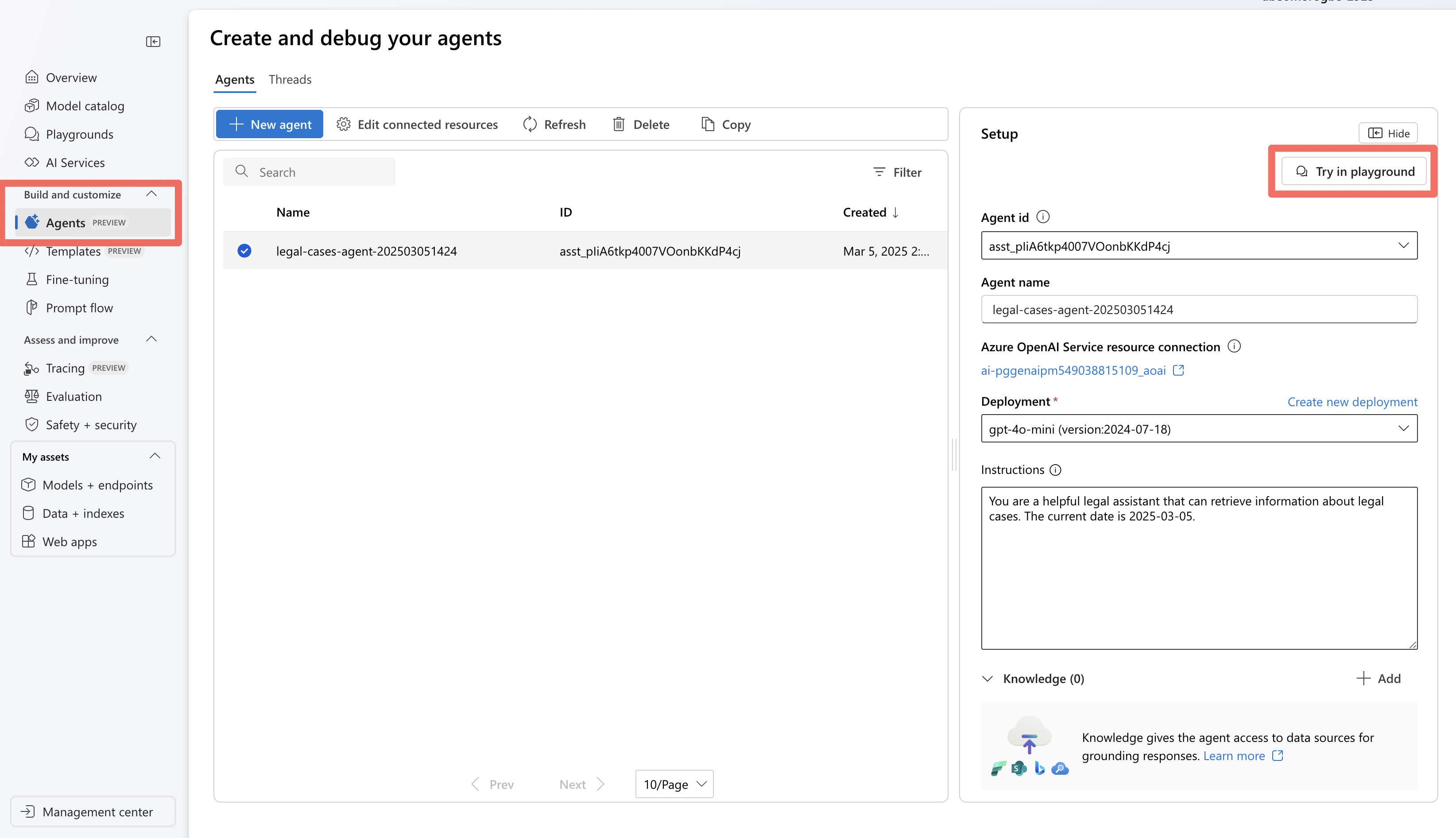
Stap 4: Testen en fouten opsporen met de agent-speeltuin
Nadat u de agent hebt uitgevoerd met behulp van de Agent Service SDK, wordt de agent opgeslagen in uw project. U kunt experimenteren met de agent in de agentspeelplaats:
Ga in Foundry naar de sectie Agents .
Zoek uw agent in de lijst en selecteer deze om deze te openen.
Gebruik de speeltuininterface om verschillende juridische query's te testen.
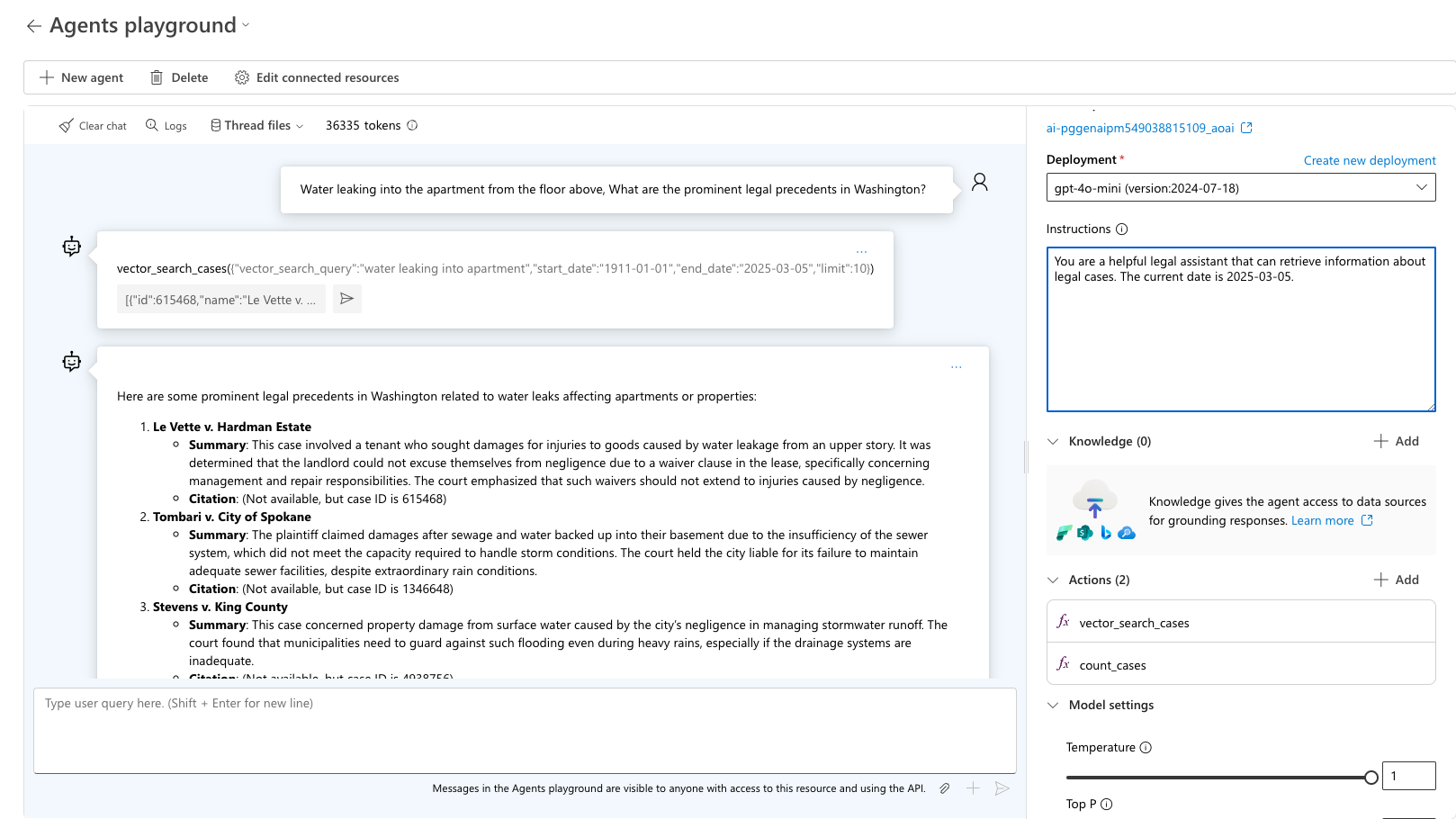
Test de query 'Water die uit de bovenstaande verdieping naar het appartement lekt, Wat zijn de prominente juridische precedenten in Washington?' De agent kiest het juiste hulpprogramma dat u wilt gebruiken en vraagt om de verwachte uitvoer voor die query. Gebruik sample_vector_search_cases_output.json als voorbeelduitvoer.
Stap 5: Fouten opsporen met Foundry-tracering
Wanneer u de agent ontwikkelt met behulp van de Agent Service SDK, kunt u fouten opsporen in de agent met tracering. Met tracering kunt u fouten opsporen in de aanroepen naar hulpprogramma's zoals Postgres en zien hoe de agent elke taak organiseert.
Ga in Foundry naar Tracering.
Als u een nieuwe Application Insights-resource wilt maken, selecteert u Nieuwe maken. Als u verbinding wilt maken met een bestaande resource, selecteert u een resource in het vak Naam van de Application Insights-resource en selecteert u Vervolgens Verbinding maken.
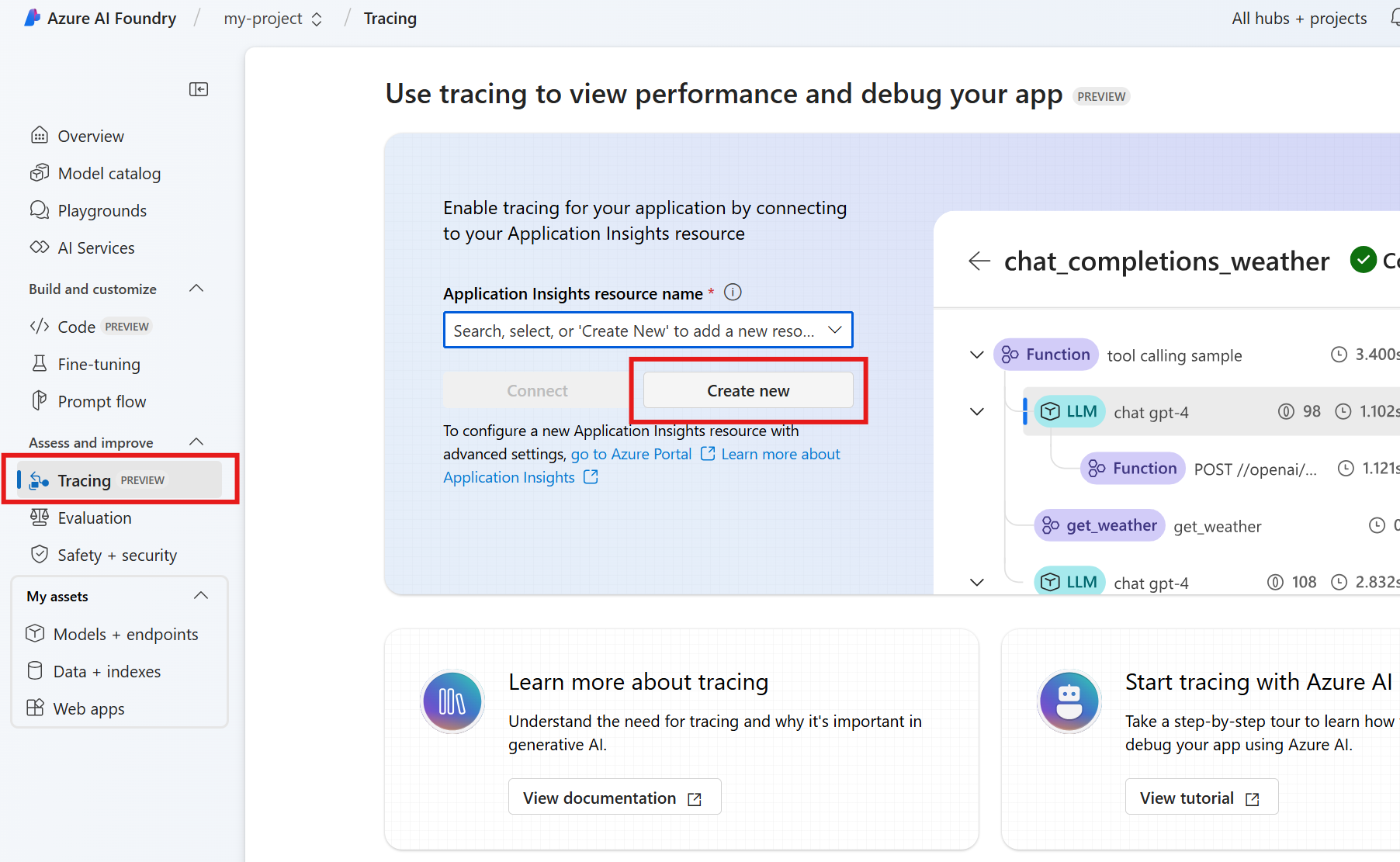
Bekijk gedetailleerde traceringen van de bewerkingen van uw agent.
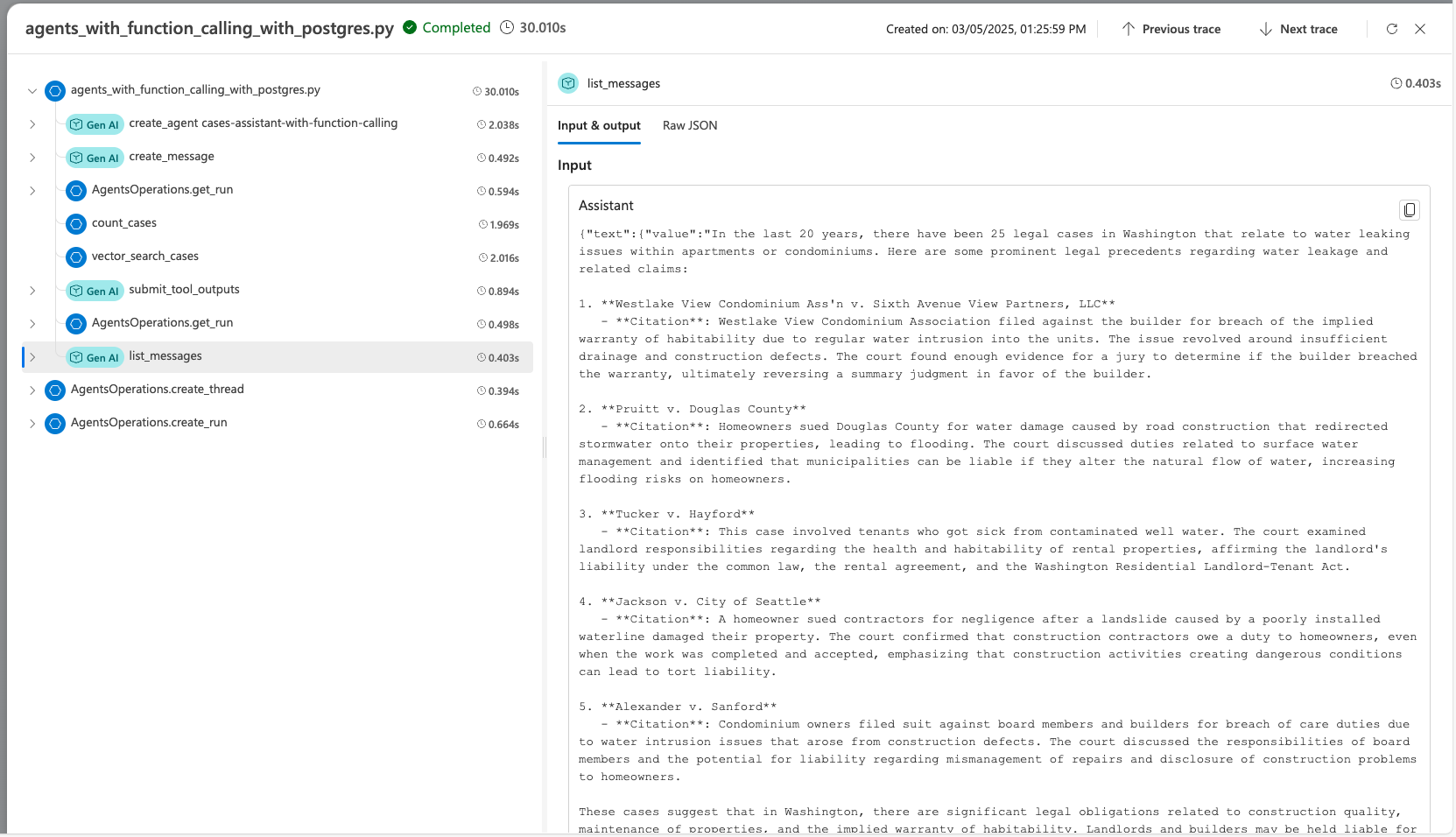
Meer informatie over het instellen van tracering met de AI-agent en Postgres in het advanced_postgres_and_ai_agent_with_tracing.py-bestand op GitHub.
Verwante inhoud
- Azure Database for PostgreSQL - integraties voor AI-toepassingen
- LangChain gebruiken met Azure Database for PostgreSQL
- Vector embeddings genereren met Azure OpenAI in Azure Database for PostgreSQL
- Azure AI-extensie in Azure Database for PostgreSQL
- Een semantische zoekopdracht maken met Azure Database for PostgreSQL en Azure OpenAI
- Pgvector inschakelen en gebruiken in Azure Database for PostgreSQL