Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Azure Database for PostgreSQL ondersteunt hoge beschikbaarheid door fysiek gescheiden primaire en stand-byreplica's in te richten. Dit model voor hoge beschikbaarheid zorgt ervoor dat vastgelegde gegevens nooit verloren gaan tijdens fouten. In een configuratie met hoge beschikbaarheid (HA) schrijft het systeem gegevens synchroon weg naar zowel de primaire server als de stand-byserver. Het model is zo ontworpen dat de database geen single point of failure is in uw softwarearchitectuur.
In de meeste regio's plaatst de service standaard uw standbyreplica in een andere beschikbaarheidszone dan uw primaire replica (zone-redundant). U kunt ook de primaire en standby-replica's implementeren binnen dezelfde beschikbaarheidszone (zonal).
Functies voor hoge beschikbaarheid
De primaire server en de stand-byreplica maken gebruik van dezelfde configuratie van virtuele machines, zoals vCores, opslag en netwerkinstellingen.
U kunt ondersteuning voor beschikbaarheidszones toevoegen aan een bestaande databaseserver.
Naast de standbyserver omvat de architectuur ook een WAL-replicaserver om quorum-commit te handhaven. In scenario's waarin de stand-byserver tijdelijk niet beschikbaar is, worden transacties doorgevoerd op de primaire server en de WAL-replicaserver om duurzaamheid te garanderen. Wanneer de standbyserver weer beschikbaar is, loopt deze automatisch weer gelijk met de primaire server. Deze architectuur helpt ervoor te zorgen dat vastgelegde records permanent worden bewaard.
Als er een failover optreedt, maakt het proces alleen de standbyserver tot de nieuwe primaire server. De WAL-replicaserver wordt niet gepromoveerd en wordt uitsluitend gebruikt om het commitquorum te handhaven.
U kunt de hogere beschikbaarheidsinstelling uitschakelen, waardoor de stand-by replica wordt verwijderd.
U kunt beschikbaarheidszones kiezen voor uw primaire en standby-databaseservers voor hoge beschikbaarheid met zone-redundantie.
U voert bewerkingen uit, zoals stoppen, starten en opnieuw opstarten op zowel primaire als stand-bydatabaseservers tegelijk.
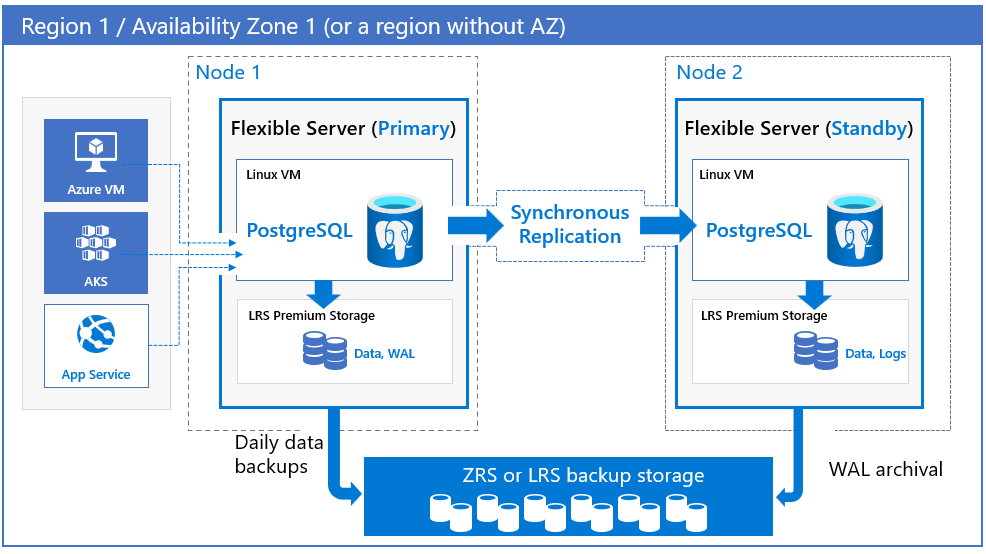
De primaire databaseserver voert periodiek automatische back-ups uit. Tegelijkertijd archiveert de stand-byreplica continu de transactielogboeken in de back-up opslag. Voor zone-redundante servers worden back-upgegevens opgeslagen in zone-redundante opslag (ZRS). Voor servers die zijn geconfigureerd zonder zoneredundantie, zonegebonden servers (één zone) en in regio's die geen ondersteuning bieden voor beschikbaarheidszones, worden back-upgegevens opgeslagen op lokaal redundante opslag (LRS).
Clients maken altijd verbinding met de hostnaam van de primaire databaseserver.
Wijzigingen aan de parameters worden ook toegepast op de standbyreplica.
U kunt de server opnieuw opstarten om eventuele wijzigingen in statische parameters op te halen.
Periodieke onderhoudsactiviteiten zoals secundaire versie-upgrades worden eerst uitgevoerd op de stand-by. Om downtime te verminderen, bevordert het proces de stand-by naar primaire, zodat workloads kunnen blijven terwijl de onderhoudstaken worden toegepast op het resterende knooppunt.
Opmerking
Configureer de max_replication_slots waarden en max_wal_senders parameterwaarden om ervoor te zorgen dat hoge beschikbaarheid goed functioneert. Hoge beschikbaarheid vereist vier van elk om failovers en naadloze upgrades te verwerken. Stel voor een configuratie met hoge beschikbaarheid met vijf leesreplica's en 12 logische replicatieslots zowel max_replication_slots als max_wal_senders parameterwaarden in op 21. Deze configuratie is nodig omdat voor elke leesreplica en logische replicatieslot een van elk nodig is, plus de vier die nodig zijn voor het functioneren van hoge beschikbaarheid. Zie de max_replication_slots voor meer informatie over max_wal_senders en parameters.
Ondersteuningstypen voor beschikbaarheidszones
Azure Database for PostgreSQL ondersteunt zowel zone-redundante als zonegebonden modellen voor configuraties met hoge beschikbaarheid. Beide configuraties met hoge beschikbaarheid maken automatische failover mogelijk met geen gegevensverlies tijdens geplande en ongeplande gebeurtenissen.
Zone-redundant. Zoneredundante hoge beschikbaarheid zorgt voor de inzet van een stand-byreplica in een andere zone met automatische failovercapaciteit. Zoneredundantie biedt het hoogste beschikbaarheidsniveau, maar u moet toepassingsredundantie tussen zones configureren. Kies daarom zoneredundantie wanneer u bescherming wilt tegen storingen op beschikbaarheidszoneniveau en wanneer latentie in de beschikbaarheidszones acceptabel is. Hoewel er enige latentie van invloed kan zijn op schrijf- en doorvoerbewerkingen vanwege synchrone replicatie, heeft dit geen invloed op leesquery's. Deze impact is specifiek voor uw workloads, het SKU-type dat u selecteert en de regio.
U kunt de regio en de beschikbaarheidszones kiezen voor zowel primaire als stand-byservers. De stand-byreplicaserver wordt ingericht in de gekozen beschikbaarheidszone in dezelfde regio met een vergelijkbare reken-, opslag- en netwerkconfiguratie als de primaire server. Gegevensbestanden en transactielogboekbestanden (write-ahead-logboeken, ook wel wal genoemd) worden opgeslagen in lokaal redundante opslag (LRS) binnen elke beschikbaarheidszone, en slaan automatisch drie gegevenskopieën op. Een zone-redundante configuratie biedt fysieke isolatie van de hele stack tussen primaire en stand-byservers.

De zone-redundante optie is alleen beschikbaar in regio's die ondersteuning hebben voor beschikbaarheidszones.
Zone-redundant wordt niet ondersteund voor:
- Burstable berekeningslaag
- Regio's met beschikbaarheid in één zone
Dezelfde zone (zonegebonden). Kies een zonegebonden implementatie wanneer u het hoogste beschikbaarheidsniveau binnen één beschikbaarheidszone wilt bereiken, maar met de laagste netwerklatentie. U kunt de regio en de beschikbaarheidszone kiezen om zowel uw primaire databaseserver te implementeren. Een stand-byreplicaserver wordt automatisch ingericht en beheerd in dezelfde beschikbaarheidszone, met vergelijkbare reken-, opslag- en netwerkconfiguratie, als de primaire server. Een zonegebonden configuratie beschermt uw databases tegen storingen op knooppuntniveau en helpt ook bij het verminderen van de downtime van toepassingen tijdens geplande en ongeplande downtimegebeurtenissen. Gegevens van de primaire server worden gerepliceerd naar de stand-byreplica in de synchrone modus. als er onderbrekingen zijn op de primaire server, voert de server automatisch een failover uit naar de stand-byreplica.
De zonal uitroloptie is beschikbaar in alle Azure-regio's waar u een flexibele server kunt implementeren.


Opmerking
Zowel zonale als zone-redundante deployatiemodellen gedragen zich architecturaal hetzelfde. Verschillende discussies in de volgende secties zijn van toepassing op beide, tenzij anders wordt beschreven.
Herstel van fouten in zones
Zone-redundant: Azure Database for PostgreSQL voert binnen 60-120 seconden automatisch een failover uit naar de stand-byserver met nul gegevensverlies.
Zonegebonden: Als een zone uitvalt, zijn zowel de primaire als de standby-servers niet beschikbaar. Om te herstellen van een fout op zoneniveau, kunt u met behulp van de back-up een point-in-time herstel uitvoeren. U kunt een aangepast herstelpunt kiezen met de laatste tijd om de meest recente gegevens te herstellen. Er wordt een nieuwe flexibele server geïmplementeerd in een andere niet-betrokken zone. De tijd die nodig is om te herstellen, is afhankelijk van de vorige back-up en het volume van transactielogboeken dat moet worden hersteld.
Zie Backup and restore in Azure Database for PostgreSQL-Flexible Server voor meer informatie over herstel op een specifiek moment.
Dienstverleningsovereenkomst (SLA)
Het zoneredundantiemodel biedt een uptime voor een SLA voor ongeveer 99,99%. Het zonegebonden model biedt een uptime voor een SLA voor ongeveer 99,95%.
Azure Database for PostgreSQL zonder hoge beschikbaarheid
Hoewel dit niet wordt aanbevolen, kunt u uw flexibele server configureren zonder hoge beschikbaarheid ingeschakeld. Voor flexibele servers die zijn geconfigureerd zonder hoge beschikbaarheid, biedt de service lokaal redundante opslag met drie kopieën van gegevens en ingebouwde servertolerantie om automatisch een vastgelopen server opnieuw op te starten en de server te verplaatsen naar een ander fysiek knooppunt. Deze configuratie biedt een lagere uptime SLA dan servers met hoge beschikbaarheid. Tijdens geplande of niet-geplande failovergebeurtenissen, als de server uitvalt, behoudt de service de beschikbaarheid van de servers met behulp van de volgende geautomatiseerde procedure:
- Er wordt een nieuwe compute Linux-virtuele machine ingericht.
- De opslag met gegevensbestanden wordt toegewezen aan de nieuwe virtuele machine.
- PostgreSQL-database-engine wordt online gebracht op de nieuwe virtuele machine.
In de volgende afbeelding ziet u de overgang tussen vm en opslagfout.

Opties voor bedrijfskritiek (hoge beschikbaarheid) configureren
U kunt hoge beschikbaarheid (HA) op twee manieren configureren: zone-redundante ha, die de stand-byserver in een andere beschikbaarheidszone plaatst voor maximale zonetolerantie of hoge beschikbaarheid van dezelfde zone, waarmee de stand-byserver in dezelfde zone als de primaire server wordt geïmplementeerd om de latentie te minimaliseren.
De sectie Bedrijfskritiek (hoge beschikbaarheid) biedt een optie voor het maken van een stand-by-HA-server met een zone-redundante configuratie. Om de configuratie te vereenvoudigen en de zonetolerantie te waarborgen, biedt de portal een optie voor zonetolerantie met twee keuzerondjes: Ingeschakeld en Uitgeschakeld. Als u Ingeschakeld selecteert, wordt geprobeerd de stand-byserver te maken in een andere beschikbaarheidszone (zone-redundante HA-modus). Als de regio geen zone-redundante HA ondersteunt, kunt u in plaats daarvan het selectievakje voor terugval aanvinken om dezelfde-zone (zongebonden) Hoge Beschikbaarheid in te schakelen.

Wanneer u het selectievakje voor terugval inschakelt, maakt het systeem de stand-byserver in dezelfde zone. Als er later zonale capaciteit beschikbaar komt, migreert Azure uw workloads automatisch van single-zone HA naar zone-redundante HA. Als u het selectievakje niet inschakelt en zonegebonden capaciteit niet beschikbaar is, mislukt het inschakelen van hoge beschikbaarheid. Dit ontwerp dwingt zone-redundante hoge beschikbaarheid af als standaardinstelling, terwijl er een gecontroleerde terugval wordt geboden voor hoge beschikbaarheid binnen dezelfde zone, zodat workloads uiteindelijk volledig zonebestendig worden.
Een Azure Database for PostgreSQL maken waarvoor beschikbaarheidszone is ingeschakeld
Zie Quickstart: Een Azure Database for PostgreSQL maken in de Azure portal voor meer informatie over het maken van een Azure Database for PostgreSQL voor hoge beschikbaarheid met beschikbaarheidszones.
Opnieuw implementeren en migreren van beschikbaarheidszone
Zie Hoge beschikbaarheid beheren in Flexibele server voor meer informatie over het in- of uitschakelen van configuratie met hoge beschikbaarheid op uw flexibele server in zowel zone-redundante als zonegebonden implementatiemodellen.
De gezondheid van hoge beschikbaarheid monitoren
Statuscontrole met hoge beschikbaarheid (HA) in Azure Database for PostgreSQL biedt een doorlopend overzicht van de status en gereedheid van instanties met hoge beschikbaarheid. Deze bewakingsfunctie past Azure's Resource Health Check (RHC) framework toe om problemen te detecteren en te waarschuwen die van invloed kunnen zijn op de failovergereedheid of de algehele beschikbaarheid van uw database. Het bewaken van de gezondheid van de HA-status maakt het mogelijk om belangrijke metrische gegevens zoals verbindingsstatus, failoverstatus en status van gegevensreplicatie te beoordelen, waardoor u proactief problemen kunt oplossen en de uptime en prestatie van uw database kunt waarborgen.
Gebruik gezondheidsstatusmonitoring met hoge beschikbaarheid om:
- Krijg realtime inzicht in de status van zowel primaire als stand-byreplica's, met statusindicatoren die potentiële problemen blootleggen, zoals verminderde prestaties of netwerkblokkering.
- Stel waarschuwingen in voor tijdige meldingen over wijzigingen in de hoge beschikbaarheidsstatus, zodat u onmiddellijk actie kunt ondernemen om potentiële onderbrekingen aan te pakken.
- Optimaliseer de failovergereedheid door problemen te identificeren en op te lossen voordat ze van invloed zijn op databasebewerkingen.
Voor een gedetailleerde gids over het configureren en interpreteren van gezondheidsstatussen voor hoge beschikbaarheid, zie Gezondheidsstatusbewaking voor High Availability (HA) van Azure Database for PostgreSQL.
Beperkingen van hoge beschikbaarheid
Replicatie tussen de primaire en stand-by-server is synchroon.
U kunt de stand-by-HA-server niet gebruiken voor leesquery's.
Afhankelijk van de workload en activiteit op de primaire server kan het failoverproces langer duren dan 120 seconden, omdat de stand-byreplica moet worden hersteld voordat deze kan worden gepromoveerd.
De stand-byserver herstelt doorgaans WAL-bestanden op 40 MB/s. Voor grotere versies kan dit tarief oplopen tot maximaal 200 MB/s. Als uw werkbelasting deze limiet overschrijdt, kunt u een langere tijd nodig hebben om het herstelproces te voltooien tijdens de failover of nadat u een nieuwe standby hebt ingesteld.
Als u de primaire databaseserver opnieuw opstart, wordt ook de stand-byreplica opnieuw opgestart.
U kunt geen extra stand-by configureren.
U kunt door de klant geïnitieerde beheertaken niet plannen tijdens het venster beheerd onderhoud.
Geplande gebeurtenissen, zoals het schalen van computing en schaalopslag, vinden eerst plaats op de stand-by en vervolgens op de primaire server. Op dit moment voert de server geen failover uit voor deze geplande bewerkingen.
Het configureren van beschikbaarheidszones tussen privé (virtueel netwerk) en openbare toegang met privé-eindpunten wordt niet ondersteund. U moet beschikbaarheidszones in een virtueel netwerk configureren (verspreid over beschikbaarheidszones binnen een regio) of openbare toegang met privé-eindpunten.
U kunt alleen beschikbaarheidszones binnen één regio configureren. U kunt geen beschikbaarheidszones configureren tussen regio's.
Onderdelen en werkstroom voor hoge beschikbaarheid
Transactievoltooiing
Een toepassingstransactie triggert een schrijf- en commitoperatie die eerst naar de WAL wordt gelogd op de primaire server. De primaire server streamt deze logboeken naar de stand-byserver met behulp van het Postgres-streamingprotocol. Wanneer de opslag van de stand-byserver de logboeken persistent maakt, bevestigt de primaire server dat de schrijfbewerking is voltooid. De toepassing voert de transactie pas na deze bevestiging door. Deze extra rondreis voegt latentie toe aan uw toepassing. Het impactpercentage is afhankelijk van de toepassing. Dit bevestigingsproces wacht niet totdat de logbestanden zijn toegepast op de standby-server. De stand-byserver blijft in de herstelmodus totdat deze wordt gepromoveerd.
Gezondheidscontrole
De statuscontrole van flexibele servers controleert periodiek de status van zowel de primaire als de stand-byserver. Als na meerdere pings gezondheidsbewaking detecteert dat een primaire server niet bereikbaar is, start de service een automatische failover naar de standby-server. Het algoritme voor statuscontrole gebruikt meerdere gegevenspunten om fout-positieve situaties te voorkomen.
Failovermodussen
Flexibele server ondersteunt twee failovermodi, geplande failover en niet-geplande failover. In beide modi, zodra de replicatie is verbroken, voert de standby-server herstel uit voordat hij als primaire server wordt gepromoveerd en opent voor lezen en schrijven. Wanneer automatische DNS-vermeldingen zijn bijgewerkt met het nieuwe eindpunt van de primaire server, kunnen toepassingen verbinding maken met de server met hetzelfde eindpunt. Er wordt een nieuwe stand-byserver op de achtergrond tot stand gebracht, zodat uw toepassing verbinding kan onderhouden.
Status van hoge beschikbaarheid
Het systeem bewaakt continu de status van primaire en stand-byservers. Het neemt de juiste acties om problemen op te lossen, waaronder het activeren van een failover naar de stand-byserver. De volgende tabel bevat de mogelijke statussen voor hoge beschikbaarheid:
| Status | Beschrijving |
|---|---|
| Initialiseren | Tijdens het maken van een nieuwe stand-byserver. |
| Gegevens repliceren | Nadat de stand-by is gemaakt, haalt het de primaire in. |
| Gezond | Replicatie verkeert in een stabiele en gezonde toestand. |
| Overdragen bij Falen | De databaseserver is bezig met het uitvoeren van een failover naar de stand-by. |
| Stand-by verwijderen | Tijdens het verwijderen van de stand-byserver. |
| Niet ingeschakeld | Hoge beschikbaarheid is niet ingeschakeld. |
Opmerking
U kunt hoge beschikbaarheid inschakelen tijdens het maken van de server of op een later tijdstip. Als u hoge beschikbaarheid inschakelt of uitschakelt tijdens de fase na het maken, doet u dit wanneer de primaire serveractiviteit laag is.
Onverander gebleven bewerkingen
PostgreSQL-clienttoepassingen maken verbinding met de primaire server met behulp van de databaseservernaam. De primaire server verwerkt rechtstreeks applicatie-lezingen. Tegelijkertijd ontvangt de toepassing alleen bevestiging van doorvoeringen en schrijfbewerkingen nadat de logboekgegevens zich op zowel de primaire server als de stand-byreplica bevinden. Door deze extra retourbezoek kunnen toepassingen verhoogde latentie verwachten bij schrijf- en commitbewerkingen. U kunt de status van de hoge beschikbaarheid in de portal bewaken.
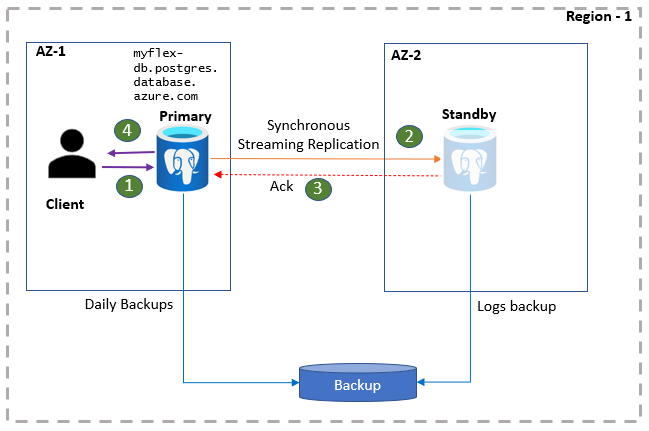
- Clients maken verbinding met de flexibele server en voeren schrijfbewerkingen uit.
- Wijzigingen worden gerepliceerd naar de standbysite.
- Primair ontvangt een bevestiging.
- Schrijf- en doorvoerbewerkingen worden bevestigd.
Herstel van servers met hoge beschikbaarheid naar een specifiek tijdstip
Voor flexibele servers die zijn geconfigureerd met hoge beschikbaarheid, repliceert het systeem logboekgegevens in realtime naar de stand-byserver. Gebruikersfouten op de primaire server, zoals een onbedoelde daling van een tabel of onjuiste gegevensupdates, worden gerepliceerd naar de stand-byreplica. U kunt de stand-by dus niet gebruiken om dergelijke logische fouten te herstellen. Als u dergelijke fouten wilt herstellen, moet u een herstel op een bepaald tijdstip uitvoeren vanuit de back-up. Door de functie voor herstel naar een bepaald tijdstip van een flexibele server te gebruiken, kunt u herstellen naar het tijdstip voordat de fout is opgetreden. Een nieuwe databaseserver wordt hersteld als een zonegebonden flexibele server met een nieuwe door de gebruiker verstrekte servernaam voor databases die zijn geconfigureerd met hoge beschikbaarheid. U kunt de herstelde server gebruiken voor verschillende gebruiksvoorbeelden:
Gebruik de herstelde server voor productie en schakel indien gewenst hoge beschikbaarheid in met een stand-byreplica in dezelfde zone of een andere zone binnen dezelfde regio.
Als u een object wilt herstellen, exporteert u het van de herstelde databaseserver en importeert u het naar de productiedatabaseserver.
Als u uw databaseserver wilt klonen voor test- en ontwikkelingsdoeleinden of voor andere doeleinden wilt herstellen, kunt u het herstel naar een bepaald tijdstip uitvoeren.
Als u wilt weten hoe u een flexibele server naar een bepaald tijdstip kunt herstellen, zie Herstel naar een bepaald tijdstip van een flexibele server.
Failover-ondersteuning
Geplande overdracht
Geplande downtime-gebeurtenissen omvatten Azure geplande periodieke software-updates en secundaire versie-upgrades. U kunt ook een geplande failover gebruiken om de primaire server te retourneren naar een beschikbaarheidszone van voorkeur. Wanneer u hoge beschikbaarheid configureert, zijn deze bewerkingen eerst van toepassing op de stand-byreplica terwijl toepassingen toegang blijven krijgen tot de primaire server. Zodra het proces de stand-byreplica bijwerkt, wordt de primaire serververbindingen verwijderd en wordt een failover geactiveerd die de stand-byreplica activeert als de primaire server met dezelfde databaseservernaam. Clienttoepassingen maken opnieuw verbinding met dezelfde databaseservernaam op de nieuwe primaire server en kunnen hun bewerkingen hervatten. Met het proces wordt een nieuwe stand-byserver in dezelfde zone als de oude primaire server tot stand gebracht.
Aanbeveling
Wanneer u een zone-redundante flexibele server hebt, kunt u ook een geplande failover gebruiken om de primaire server te retourneren naar een beschikbaarheidszone van voorkeur met minder downtime. Uw primaire server kan zich bijvoorbeeld in een andere beschikbaarheidszone bevinden dan de toepassing na een niet-geplande failover. Het geplande failoverproces verplaatst de primaire terug naar de oorspronkelijke zone en stelt een nieuwe stand-byserver in dezelfde zone als de oude primaire server in.
Voor andere door de gebruiker geïnitieerde bewerkingen, zoals scale-compute of scale-storage, past het proces eerst wijzigingen toe op de stand-by en vervolgens de primaire bewerking. Op dit moment voert de service geen failover uit naar de stand-by. Dus terwijl de schaalbewerking wordt uitgevoerd op de primaire server, hebben toepassingen korte downtime.
U kunt deze functie ook gebruiken om een failover uit te voeren naar de stand-byserver met verminderde downtime. Uw primaire server kan zich bijvoorbeeld in een andere beschikbaarheidszone bevinden dan de toepassing na een niet-geplande failover. U wilt de primaire server terugplaatsen naar de vorige zone zodat deze samen met uw toepassing wordt geplaatst.
Wanneer u deze functie uitvoert, bereidt het proces eerst de stand-byserver voor om ervoor te zorgen dat deze bij recente transacties wordt ingehaald, zodat de applicatie kan blijven lezen en schrijven. Het proces bevordert de stand-by en breekt de verbindingen met de primaire. Uw toepassing kan blijven schrijven naar de primaire server terwijl het proces een nieuwe stand-byserver op de achtergrond tot stand brengt. In de volgende tabel worden de stappen beschreven die betrekking hebben op geplande failover:
| Step | Beschrijving | Verwachte downtime van de app? |
|---|---|---|
| 1 | Wacht tot de standby-server is gesynchroniseerd met de primaire server. | No |
| 2 | Het interne bewakingssysteem initieert de failoverwerkstroom. | No |
| 3 | Schrijfbewerkingen van toepassingen worden geblokkeerd wanneer de stand-byserver zich dicht bij het primaire logboekreeksnummer (LSN) bevindt. | Ja |
| 4 | Stand-byserver wordt gepromoveerd tot een onafhankelijke server. | Ja |
| 5 | DNS-record wordt bijgewerkt met het IP-adres van de nieuwe stand-byserver. | Ja |
| 6 | De toepassing maakt opnieuw verbinding en hervat de lees-/schrijfbewerking met de nieuwe primaire. | No |
| 7 | Er wordt een nieuwe stand-byserver tot stand gebracht. Voor zone-redundante servers bevindt de nieuwe server zich in een andere zone. | No |
| 8 | De standbyserver begint logboeken te herstellen die hij heeft gemist vanuit Azure Blob tijdens de oprichting. | No |
| 9 | Er wordt een stabiele toestand tussen de primaire en de standbyserver tot stand gebracht. | No |
| 10 | Het geplande failoverproces is voltooid. | No |
Downtime van toepassingen begint bij stap 3 en kan na stap 5 de bewerking hervatten. De rest van de stappen worden op de achtergrond uitgevoerd zonder dat dit van invloed is op schrijf- en doorvoerbewerkingen van toepassingen.
Aanbeveling
Met flexibele server kunt u eventueel Azure geïnitieerde onderhoudsactiviteiten plannen door een venster van 60 minuten te kiezen op een dag van uw voorkeur wanneer activiteiten op de databases naar verwachting laag zijn. Azure onderhoudstaken zoals patching of secundaire versie-upgrades worden uitgevoerd tijdens dat venster. Als u geen aangepast venster kiest, wijst het systeem een periode van één uur toe tussen 11:00 en 7:00 uur lokale tijd voor uw server. Deze Azure geïnitieerde onderhoudsactiviteiten worden ook uitgevoerd op de stand-byreplica voor flexibele servers die zijn geconfigureerd met beschikbaarheidszones.
Zie Geplande downtime-gebeurtenissen voor een lijst met mogelijke geplande downtime-gebeurtenissen.
Niet-geplande failover
Ongeplande downtime kan optreden vanwege onvoorziene onderbrekingen, zoals onderliggende hardwarefouten, netwerkproblemen en softwarefouten. Als de databaseserver die u hebt geconfigureerd met hoge beschikbaarheid onverwacht uitvalt, activeert het proces de stand-byreplica en kunnen clients hun bewerkingen hervatten. Als u hoge beschikbaarheid (HA) niet configureert en de poging tot opnieuw opstarten mislukt, wordt automatisch een nieuwe databaseserver ingericht. Hoewel u niet-geplande downtime niet kunt voorkomen, helpt flexibele server de downtime te beperken door automatisch herstelbewerkingen uit te voeren zonder menselijke tussenkomst.
Zie Niet-geplande downtime beperking voor informatie over niet-geplande failovers en downtime, inclusief mogelijke scenario's.
Geforceerde failover
Gebruik een geforceerde failover voor failovertests om een scenario van een ongeplande storing te simuleren terwijl uw productieworkload wordt uitgevoerd. U kunt de downtime van uw toepassing observeren. U kunt ook een geforceerde failover gebruiken wanneer uw primaire server niet meer reageert.
Een geforceerde failover legt de primaire server plat en initieert de failoverwerkstroom waarin de standby-promotiebewerking wordt uitgevoerd. Zodra de standby-server het herstelproces heeft voltooid tot de laatste vastgelegde gegevens, wordt deze gepromoveerd tot de primaire server. DNS-records worden bijgewerkt en uw toepassing kan verbinding maken met de gepromoveerde primaire server. Uw toepassing kan blijven schrijven naar de primaire server terwijl er een nieuwe stand-byserver op de achtergrond wordt ingesteld, wat geen invloed heeft op de uptime.
In de volgende tabel worden de stappen beschreven tijdens geforceerde failover:
| Step | Beschrijving | Verwachte downtime van de app? |
|---|---|---|
| 1 | De primaire server stopt kort na ontvangst van de failoveraanvraag. | Ja |
| 2 | De toepassing ondervindt downtime omdat de primaire server niet beschikbaar is. | Ja |
| 3 | Intern bewakingssysteem detecteert de fout en initieert een failover naar de stand-byserver. | Ja |
| 4 | Stand-byserver gaat in de herstelmodus voordat deze volledig wordt gepromoveerd als een onafhankelijke server. | Ja |
| 5 | Het failoverproces wacht tot het standbyherstel voltooid is. | Ja |
| 6 | Zodra de server klaar is, werkt het proces de DNS-record bij met dezelfde hostnaam, maar gebruikt het IP-adres van de stand-by. | Ja |
| 7 | De toepassing kan opnieuw verbinding maken met de nieuwe primaire server en de bewerking hervatten. | No |
| 8 | Er wordt een stand-byserver in de voorkeurszone tot stand gebracht. | No |
| 9 | De standbyserver begint logboeken te herstellen die hij heeft gemist vanuit Azure Blob tijdens de oprichting. | No |
| 10 | Er wordt een stabiele toestand tussen de primaire en de standbyserver tot stand gebracht. | No |
| 11 | Het geforceerde failoverproces is voltooid. | No |
Downtime van toepassingen wordt gestart na stap 1 en gaat door totdat stap 6 is voltooid. Resterende stappen worden op de achtergrond uitgevoerd, zonder dat dit van invloed is op schrijfbewerkingen en doorvoeringen van toepassingen.
Belangrijk
Het end-to-end-failoverproces omvat (a) een failover naar de stand-byserver na het uitvallen van de primaire server en (b) het tot stand brengen van een nieuwe stand-byserver in een stabiele toestand. Wanneer uw toepassing uitvaltijd in beslag neemt totdat de failover naar de stand-by is voltooid, meet u de downtime vanuit het perspectief van uw toepassing/client in plaats van het algehele end-to-endfailoverproces.
Overwegingen bij het uitvoeren van geforceerde failovers
De totale end-to-end-bewerkingstijd kan langer zijn dan de werkelijke downtime die de toepassing ondervindt.
Belangrijk
Bekijk altijd de downtime vanuit het perspectief van de toepassing.
Voer geen directe back-to-back-failovers uit. Wacht ten minste 15-20 minuten tussen failovers, zodat de nieuwe stand-byserver volledig tot stand kan worden gebracht.
Voer een geforceerde failover uit tijdens een periode met weinig activiteit om de downtime te verminderen.
Best practices voor PostgreSQL-statistieken na een failover
Na een PostgreSQL-failover is het van belang voor het behoud van optimale databaseprestaties dat u inzicht heeft in de verschillende rollen van pg_statistic en de pg_stat_* weergaven. In pg_statistic de tabel worden optimalisatiestatistieken opgeslagen, die cruciaal zijn voor de queryplanner. Deze statistieken omvatten gegevensdistributies in tabellen en blijven intact na een failover, zodat de queryplanner de uitvoering van query's effectief kan blijven optimaliseren op basis van nauwkeurige, historische gegevensdistributiegegevens.
Daarentegen bieden de weergaven pg_stat_* runtime-activiteitsstatistieken, zoals het aantal scans, gelezen tuples en updates. Deze gegevens worden in het geheugen opgeslagen en bij een failover opnieuw ingesteld. Een voorbeeld hiervan is pg_stat_user_tables, waarmee activiteiten voor door de gebruiker gedefinieerde tabellen worden bijgehouden. Deze reset weerspiegelt nauwkeurig de operationele status van de nieuwe primaire, maar betekent ook het verlies van historische activiteitsgegevens die het autovacuumproces en andere operationele efficiëntie kunnen informeren.
Gezien dit onderscheid moet u overwegen ANALYZE uit te voeren na een PostgreSQL-failover. Met deze actie worden de gegevens van pg_stat_* (bijvoorbeeld pg_stat_user_tables) bijgewerkt met nieuwe statistieken over vacuumactiviteit, wat het autovacuumproces helpt en er op zijn beurt voor zorgt dat de databaseprestaties optimaal blijven in zijn nieuwe rol. Deze proactieve stap overbrugt de kloof tussen het behouden van essentiële optimizer-statistieken en het vernieuwen van metrische gegevens over activiteit, zodat deze overeenkomt met de huidige status van de database.
Ondersteuning voor logische replicatie met hoge beschikbaarheid
Wanneer u logische replicatie of logische decodering met hoge beschikbaarheid (HA) in Azure Database for PostgreSQL Flexibele server gebruikt, is het belangrijk om te begrijpen hoe replicatiesites zich gedragen tijdens een failover en hoe u de continuïteit van de replicatie kunt garanderen.
PostgreSQL 16 en eerder
In PostgreSQL 16 en eerder worden logische replicatieslots na een failover niet automatisch behouden op de standby-server. Als u logische replicatie tussen failovers wilt onderhouden, moet u het volgende doen:
- De
pg_failover_slotsextensie inschakelen - Vereiste instellingen configureren, zoals:
hot_standby_feedback = on
Zonder deze configuraties werkt logische replicatie mogelijk niet meer na een failover omdat replicatieslots niet beschikbaar zijn op de nieuwe primaire server.
PostgreSQL 17 en hoger
Vanaf PostgreSQL 17 wordt synchronisatie van logische replicatieslots native ondersteund. Wanneer u deze functie correct configureert, synchroniseert het systeem automatisch replicatieslots naar de standbyserver.
Ga als volgt te werk om dit gedrag in te schakelen:
- Stel
sync_replication_slotsin opon. - Stel
hot_standby_feedbackin opon.
Met deze instellingen behoudt het systeem logische replicatieslots bij failover en kan de replicatie worden voortgezet zonder dat extensies vereist zijn. Zie de PG_Failover_Slots-extensiedocumentatie voor meer informatie.
Belangrijke overwegingen
- U beheert logische replicatieslots op de primaire server, maar de standbyserver moet deze slots ook hebben om ervoor te zorgen dat logische replicatie na HA-failover doorgaat.
- Systeemweergaven (bijvoorbeeld het opvragen van
pg_replication_slots) geven alleen de status op de primaire weer en bevestigen niet of slots worden gesynchroniseerd met de stand-by. Een systeem kan gezond lijken op de primaire server, maar toch niet klaar zijn voor failover om logische replicatieslots op de stand-by te behouden.
Failovergereedheid van logische replicatie bewaken
Gebruik de metriek logical_replication_slot_sync_status in Azure Monitor (Preview) om failovergereedheid te helpen valideren.
Belangrijk
Als u deze metrische waarde wilt verzenden, moet u ervoor zorgen dat de parameter metrics.collector_database_activity is ingesteld op on.
Deze metriek geeft aan of logische replicatieslots zijn gesynchroniseerd tussen de HA-primary en de standby.
-
1geeft aan dat slots worden gesynchroniseerd tussen de primaire en de stand-by. -
0geeft aan dat slots niet zijn gesynchroniseerd in de stand-bymodus.
Als de metrische waarde 0 is, blijft logische replicatie mogelijk functioneren op de huidige primaire, maar wordt deze mogelijk niet voortgezet na een failover. Zie Bewaking van logische replicatie voor een volledige lijst met metrische gegevens voor logische replicatie.
Opmerking
Deze synchronisatiestatus weerspiegelt de status van alle HA-knooppunten en kan niet worden geverifieerd via systeemweergaven alleen op het primaire knooppunt. Overweeg deze metrische gegevens te gebruiken met waarschuwingen om te detecteren wanneer logische replicatie niet gereed is voor failover, met name vóór gepland onderhoud of failovergebeurtenissen. Overweeg waarschuwingen te configureren wanneer deze metrische waarde gedurende een langere periode 0 blijft.