DBMS-implementatie van SQL Server Azure Virtual Machines voor SAP NetWeaver
In dit document worden verschillende gebieden behandeld waarmee u rekening moet houden bij het implementeren van SQL Server voor SAP-werkbelasting in Azure IaaS. Lees als voorwaarde voor dit document de overwegingen voor dbms-implementatie van Azure Virtual Machines voor SAP-werkbelasting en andere handleidingen in de SAP-workload in Azure-documentatie.
Belangrijk
Het bereik van dit document is de Windows-versie op SQL Server. SAP biedt geen ondersteuning voor de Linux-versie van SQL Server met een van de SAP-software. Het document bespreekt Microsoft Azure SQL Database niet. Dit is een Platform as a Service-aanbieding van het Microsoft Azure Platform. De discussie in dit artikel gaat over het uitvoeren van het SQL Server-product, omdat het bekend staat om on-premises implementaties in Azure Virtual Machines, waarbij gebruik wordt gemaakt van de infrastructuur als een service-functie van Azure. Databasemogelijkheden en -functionaliteit tussen deze twee aanbiedingen zijn verschillend en mogen niet met elkaar worden gecombineerd. Zie Azure SQL Database voor meer informatie.
Over het algemeen moet u overwegen om de meest recente SQL Server-releases te gebruiken om SAP-workload uit te voeren in Azure IaaS. De nieuwste VERSIES van SQL Server bieden een betere integratie in een aantal Azure-services en -functionaliteit. U kunt ook wijzigingen aanbrengen die bewerkingen in een Azure IaaS-infrastructuur optimaliseren.
Algemene documentatie over SQL Server die wordt uitgevoerd in Azure Virtual Machines (VM) vindt u in deze artikelen:
- SQL Server op virtuele Azure-machines (Windows)
- Beheer automatiseren met de IaaS Agent-extensie van Windows SQL Server
- Azure Key Vault-integratie configureren voor SQL Server op Azure-VM's (Resource Manager)
- Controlelijst: best practices voor prestaties voor SQL Server op Azure-VM's
- Opslag: Best practices voor prestaties voor SQL Server op Azure-VM's
- Aanbevolen procedures voor HADR-configuratie (SQL Server op virtuele machines van Azure)
Niet alle inhoud en instructies in de algemene DOCUMENTATIE van SQL Server in Azure VM zijn van toepassing op SAP-werkbelasting. Maar de documentatie geeft een goede indruk van de principes. Een voorbeeld voor functionaliteit die niet wordt ondersteund voor SAP-werkbelasting is het gebruik van FCI-clustering.
Er zijn enkele specifieke SQL Server-informatie in IaaS die u moet weten voordat u doorgaat:
- Ondersteuning voor SQL-versie: Zelfs met SAP-opmerking #1928533 wordt aangegeven dat de minimaal ondersteunde SQL Server-release SQL Server 2008 R2 is, wordt het venster met ondersteunde SQL Server-versies in Azure ook bepaald door de levenscyclus van SQL Server. Het uitgebreide onderhoud van SQL Server 2012 is halverwege 2022 beëindigd. Als gevolg hiervan moet de huidige minimale release voor nieuw geïmplementeerde systemen SQL Server 2014 zijn. Hoe recenter, hoe beter. De nieuwste VERSIES van SQL Server bieden een betere integratie in een aantal Azure-services en -functionaliteit. U kunt ook wijzigingen aanbrengen die bewerkingen in een Azure IaaS-infrastructuur optimaliseren.
- Installatiekopieën uit Azure Marketplace gebruiken: de snelste manier om een nieuwe Microsoft Azure-VM te implementeren, is door een installatiekopieën uit Azure Marketplace te gebruiken. Er zijn installatiekopieën in Azure Marketplace, die de meest recente SQL Server-releases bevatten. De installatiekopieën waarop SQL Server al is geïnstalleerd, kunnen niet onmiddellijk worden gebruikt voor SAP NetWeaver-toepassingen. De reden hiervoor is dat de standaard-SQL Server-sortering wordt geïnstalleerd binnen deze installatiekopieën en niet de sortering die is vereist voor SAP NetWeaver-systemen. Als u dergelijke installatiekopieën wilt gebruiken, raadpleegt u de stappen in hoofdstuk Een SQL Server-installatiekopieën uit de Microsoft Azure Marketplace gebruiken.
- Ondersteuning voor meerdere exemplaren van SQL Server binnen één Virtuele Azure-machine: deze implementatiemethode wordt ondersteund. Houd echter rekening met resourcebeperkingen, met name met betrekking tot netwerk- en opslagbandbreedte van het VM-type dat u gebruikt. Gedetailleerde informatie is beschikbaar in artikelGrootten voor virtuele machines in Azure. Deze quotumbeperkingen kunnen verhinderen dat u dezelfde architectuur met meerdere exemplaren implementeert als on-premises. Vanaf de configuratie en interferentie van het delen van de resources die beschikbaar zijn binnen één VIRTUELE machine, moeten dezelfde overwegingen als on-premises in aanmerking worden genomen.
- Meerdere SAP-databases in één SQL Server-exemplaar in één VM: configuraties zoals deze worden ondersteund. Overwegingen voor meerdere SAP-databases die de gedeelde resources van één SQL Server-exemplaar delen, zijn hetzelfde als voor on-premises implementaties. Houd andere limieten, zoals het aantal schijven dat kan worden gekoppeld aan een specifiek VM-type in gedachten. Of netwerk- en opslagquotalimieten van specifieke VM-typen als gedetailleerde grootten voor virtuele machines in Azure.
Nieuwe VM's uit de M-serie en SQL Server
Azure heeft een aantal nieuwe families van M-serie-SKU's uitgebracht onder de familie Mv3. Sommige VM-typen in deze familie mogen niet worden gebruikt voor SQL Server, waaronder SQL Server 2022 zonder SMT (Hyperthreading) uit te schakelen in het gastbesturingssysteem van Windows Server. Reden is het aantal NUMA-knooppunten dat wordt gepresenteerd in het gastbesturingssystemen van Windows Server, dat groter is dan 64 vCPU's, te groot is voor SQL Server. Door SMT uit te schakelen in het gastbesturingssysteem van Windows Server, wordt het aantal vCPU's verminderd. Dus, dat het aantal vCPU's kleiner is dan 64 in elk NUMA-knooppunt. De manier waarop SMT kan worden uitgeschakeld, wordt hier beschreven. De specifieke VM-typen zijn:
- M176(d)s_3_v3 - SCHAKEL SMT uit of gebruik M176bds_4_v3 of M176bds_4_v3 als alternatief
- M176(d)s_4_v3 - SMT uitschakelen of M176bds_4_v3 als alternatief gebruiken
- M624(d)s_12_v3 - SMT uitschakelen of als alternatief M416ms_v2 gebruiken
- M832(d)s_12_v3 - SMT uitschakelen of M416ms_v2 als alternatief gebruiken
- M832i(d)s_16_v3 - SMT uitschakelen of M416ms_v2 als alternatief gebruiken
Notitie
Met sommige van de nieuwe VM-typen M(b)v3 kan het gebruik van Premium SSD v1-opslag in de cache leiden tot lagere IOPS-snelheid en -schrijfsnelheid en -doorvoer dan u krijgt als u geen leescache gebruikt.
Aanbevelingen voor VM-/VHD-structuur voor SAP-gerelateerde SQL Server-implementaties
In overeenstemming met de algemene beschrijving, besturingssysteem, UITVOERbare SQL Server-bestanden, moeten de UITVOERbare SAP-bestanden zich bevinden of afzonderlijke Azure-schijven installeren. Normaal gesproken worden de meeste SQL Server-systeemdatabases niet op hoog niveau gebruikt met de SAP NetWeaver-workload. De systeemdatabases van SQL Server moeten echter samen met de andere SQL Server-directory's op een afzonderlijke Azure-schijf zijn. SQL Server tempdb moet zich bevinden op het niet-ervaren D:\-station of op een afzonderlijke schijf.
- Met alle sap-gecertificeerde VM-typen (zie SAP-opmerking #1928533), kunnen tempdb-gegevens en logboekbestanden worden geplaatst op het niet-gepersiste D:\-station.
- Met SQL Server-releases, waarbij SQL Server tempdb met slechts één gegevensbestand installeert, is het raadzaam om meerdere tempdb-gegevensbestanden te gebruiken. Houd er rekening mee dat D:\-stationsvolumes verschillen in grootte en mogelijkheden op basis van het VM-type. Raadpleeg het artikel Grootten voor virtuele Windows-machines in Azure voor exacte grootten van het station D:\ van de verschillende VM's.
Met deze configuraties kan tempdb meer ruimte verbruiken en belangrijkere I/O-bewerkingen per seconde (IOPS) en opslagbandbreedte dan het systeemstation kan bieden. Het niet-persistente D:\-station biedt ook betere I/O-latentie en doorvoer. Als u de juiste tempdb-grootte wilt bepalen, kunt u de tempdb-grootten op bestaande systemen controleren.
Notitie
Als u tempdb-gegevensbestanden en logboekbestand in een map op het D:\-station plaatst dat u hebt gemaakt, moet u ervoor zorgen dat de map bestaat nadat een VM opnieuw is opgestart. Omdat het station D:\ vers kan worden geïnitialiseerd nadat een VIRTUELE machine alle bestanden opnieuw heeft opgestart en mapstructuren kunnen worden gewist. Een mogelijkheid om uiteindelijke mapstructuren opnieuw te maken op D:\-station voordat de SQL Server-service wordt gestart, wordt beschreven in dit artikel.
Een VM-configuratie, waarop SQL Server wordt uitgevoerd met een SAP-database en waar tempdb-gegevens en tempdb-logboekbestand worden geplaatst op het station D:\ en Azure Premium Storage v1 of v2, ziet er als volgt uit:
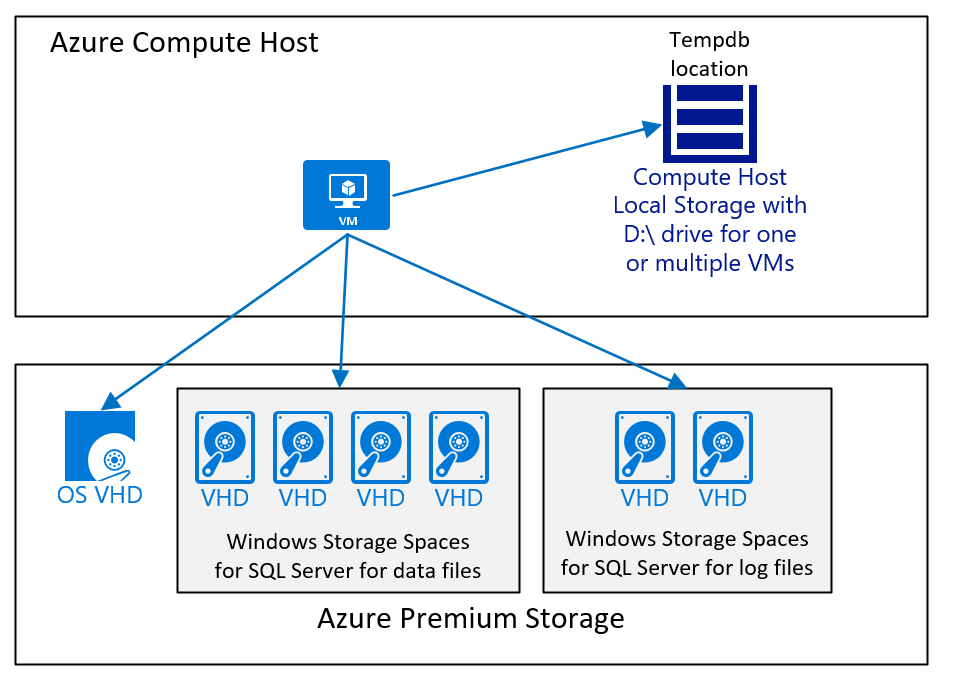
In het diagram wordt een eenvoudig hoofdlettergebruik weergegeven. Zoals beschreven in het artikel Overwegingen voor DBMS-implementatie van Virtuele Azure-machines voor SAP-werkbelasting, azure-opslagtype, -nummer en -grootte is afhankelijk van verschillende factoren. Maar over het algemeen raden we het volgende aan:
- Voor kleinere en middelgrote implementaties gebruikt u één groot volume, dat de SQL Server-gegevensbestanden bevat. Reden achter deze configuratie is dat het eenvoudiger is om verschillende I/O-workloads af te handelen voor het geval de SQL Server-gegevensbestanden niet dezelfde vrije ruimte hebben. In grote implementaties, met name implementaties waarbij de klant is verplaatst met een heterogene databasemigratie naar SQL Server in Azure, hebben we afzonderlijke schijven gebruikt en vervolgens de gegevensbestanden over deze schijven gedistribueerd. Een dergelijke architectuur is alleen geslaagd wanneer elke schijf hetzelfde aantal gegevensbestanden heeft, alle gegevensbestanden dezelfde grootte hebben en ongeveer dezelfde vrije ruimte hebben.
- Gebruik de D:\drive voor tempdb zolang de prestaties goed genoeg zijn. Als de totale werkbelasting beperkt is in de prestaties van tempdb op het station D:\ moet u tempdb verplaatsen naar Azure Premium Storage v1 of v2 of Ultra Disk, zoals aanbevolen in dit artikel.
Het mechanisme voor proportionele opvulling van SQL Server distribueert lees- en schrijfbewerkingen naar alle gegevensbestanden gelijkmatig, mits alle SQL Server-gegevensbestanden dezelfde grootte hebben en hetzelfde vrije tempo hebben. SAP op SQL Server levert de beste prestaties wanneer lees- en schrijfbewerkingen gelijkmatig worden verdeeld over alle beschikbare gegevensbestanden. Als een database te weinig gegevensbestanden heeft of als de bestaande gegevensbestanden zeer onevenwichtig zijn, is de beste methode om te corrigeren een R3load-export en -import. Een R3load-export en -import omvat downtime en moet alleen worden uitgevoerd als er een duidelijk prestatieprobleem is dat moet worden opgelost. Als de gegevensbestanden slechts matig verschillende grootten hebben, verhoogt u alle gegevensbestanden tot dezelfde grootte en verdeelt SQL Server gegevens in de loop van de tijd opnieuw. SQL Server groeit automatisch gegevensbestanden gelijkmatig als traceringsvlag 1117 is ingesteld of als SQL Server 2016 of hoger wordt gebruikt zonder traceringsvlag.
Speciaal voor VM's uit de M-serie
Voor vm uit de Azure M-serie kan de latentie die in het transactielogboek wordt geschreven, worden verminderd, vergeleken met de prestaties van Azure Premium Storage v1, wanneer u Azure Write Accelerator gebruikt. Als de opgegeven latentie voor Premium Storage v1 de schaalbaarheid van de SAP-workload beperkt, kan de schijf waarin het SQL Server-transactielogboekbestand wordt opgeslagen, worden ingeschakeld voor Write Accelerator. Details kunnen worden gelezen in het document Write Accelerator. Azure Write Accelerator werkt niet met Azure Premium Storage v2 en Ultra Disk. In beide gevallen is de latentie beter dan wat Azure Premium Storage v1 levert. Write Accelerator biedt geen ondersteuning voor Premium SSD v2.
Notitie
Met sommige van de nieuwe VM-typen M(b)v3 kan het gebruik van Premium SSD v1-opslag in de cache leiden tot lagere IOPS-snelheid en -schrijfsnelheid en -doorvoer dan u krijgt als u geen leescache gebruikt.
De schijven opmaken
Voor SQL Server moet de NTFS-blokgrootte voor schijven met SQL Server-gegevens en logboekbestanden 64 kB zijn. U hoeft het D:\-station niet te formatteren. Dit station is vooraf opgemaakt.
Om te voorkomen dat het herstellen of maken van databases de gegevensbestanden initialiseert door de inhoud van de bestanden te nulen, moet u ervoor zorgen dat de gebruikerscontext waarin de SQL Server-service wordt uitgevoerd, beschikt over de gebruikersrechten volumeonderhoudstaken uitvoeren. Zie Initialisatie van direct databasebestand voor meer informatie.
SQL Server 2014 en recentere SQL Server-versies: databasebestanden rechtstreeks opslaan in Azure Blob Storage
SQL Server 2014 en latere releases openen de mogelijkheid om databasebestanden rechtstreeks in Azure Blob Store op te slaan zonder de 'wrapper' van een VHD eromheen. Deze functionaliteit is bedoeld om tekortkomingen van Azure-blokopslag jaren terug te verhelpen. Tegenwoordig wordt het niet aanbevolen om deze implementatiemethode te gebruiken en in plaats daarvan Azure Premium Storage v1, Premium Storage v2 of Ultra Disk te kiezen. Afhankelijk van de vereisten.
Overwegingen voor back-up/herstel voor SQL Server
Als u SQL Server implementeert in Azure, moet u uw back-uparchitectuur controleren. Zelfs als het systeem geen productiesysteem is, moet er periodiek een back-up van de SQL Server SAP-database worden gemaakt. Omdat Azure Storage drie installatiekopieën bewaart, is een back-up nu minder belangrijk met betrekking tot het compenseren van een opslagcrash. De prioriteitsreden voor het onderhouden van een correct back-up- en herstelplan is belangrijk voor herstel naar een bepaald tijdstip om logische/handmatige fouten te compenseren. Het doel is om back-ups te gebruiken om de database terug te zetten naar een bepaald tijdstip. Of als u de back-ups in Azure wilt gebruiken om een ander systeem te seeden met het kopiëren van de bestaande databaseback-up.
Er zijn verschillende manieren om een back-up te maken van SQL Server-databases en deze te herstellen in Azure. Lees het document Back-up en herstel voor SQL Server op Azure-VM's voor het beste overzicht en de beste details. In het artikel worden verschillende mogelijkheden behandeld.
Een SQL Server-installatiekopieën gebruiken uit De Microsoft Azure Marketplace
Microsoft biedt VM's in Azure Marketplace, die al versies van SQL Server bevat. Voor SAP-klanten die licenties nodig hebben voor SQL Server en Windows, kan het gebruik van deze installatiekopieën een mogelijkheid zijn om de noodzaak van licenties te dekken door VM's te maken waarop SQL Server al is geïnstalleerd. Als u dergelijke installatiekopieën voor SAP wilt gebruiken, moeten de volgende overwegingen worden gemaakt:
- De niet-evaluatieversies van SQL Server krijgen hogere kosten dan een vm met alleen Windows die is geïmplementeerd vanuit Azure Marketplace. Als u prijzen wilt vergelijken, raadpleegt u prijzen voor Virtuele Windows-machines en prijzen voor VIRTUELE MACHINES van SQL Server Enterprise.
- U kunt alleen SQL Server-releases gebruiken, die worden ondersteund door SAP voor hun software.
- De sortering van het SQL Server-exemplaar, dat is geïnstalleerd in de VM's die worden aangeboden in Azure Marketplace, is niet de sortering van SAP NetWeaver vereist dat het SQL Server-exemplaar wordt uitgevoerd. U kunt de sortering echter wijzigen met de aanwijzingen in de volgende sectie.
De SQL Server-sortering van een Microsoft Windows/SQL Server-VM wijzigen
Omdat de SQL Server-installatiekopieën in Azure Marketplace niet zijn ingesteld voor het gebruik van de sortering, die vereist is voor SAP NetWeaver-toepassingen, moet deze onmiddellijk na de implementatie worden gewijzigd. Voor SQL Server kan deze wijziging van sortering worden uitgevoerd met de volgende stappen zodra de VIRTUELE machine is geïmplementeerd en een beheerder zich kan aanmelden bij de geïmplementeerde VM:
- Open een Windows-opdrachtvenster als beheerder.
- Wijzig de map in C:\Program Files\Microsoft SQL Server\110\Setup Bootstrap\SQLServer2012.
- Voer de opdracht uit: Setup.exe /QUIET /ACTION=REBUILDDATABASE /INSTANCENAME=MSSQLSERVER /SQLSYSADMINACCOUNTS=
<local_admin_account_name> /SQLCOLLATION=SQL_Latin1_General_Cp850_BIN2-
<local_admin_account_name> is het account, dat is gedefinieerd als het beheerdersaccount bij het voor het eerst implementeren van de VIRTUELE machine via de galerie.
-
Het proces duurt slechts een paar minuten. Voer de volgende stappen uit om te controleren of de stap uiteindelijk het juiste resultaat heeft:
- Start SQL Server Management Studio.
- Open een queryvenster.
- Voer de opdracht uit sp_helpsort in de SQL Server-hoofddatabase.
Het gewenste resultaat moet er als volgt uitzien:
Latin1-General, binary code point comparison sort for Unicode Data, SQL Server Sort Order 40 on Code Page 850 for non-Unicode Data
Als het resultaat anders is, stopt u een implementatie en onderzoekt u waarom de installatieopdracht niet werkt zoals verwacht. Implementatie van SAP NetWeaver-toepassingen op SQL Server-exemplaar met verschillende SQL Server-codepagina's dan de vermelde codepagina's wordt niet ondersteund voor NetWeaver-implementaties.
Hoge beschikbaarheid van SQL Server voor SAP in Azure
Met BEHULP van SQL Server in Azure IaaS-implementaties voor SAP hebt u verschillende mogelijkheden om de databaselaag maximaal beschikbaar te implementeren. Azure biedt verschillende up-time SLA's voor één VM met behulp van verschillende Azure-blokopslag, een paar virtuele machines die zijn geïmplementeerd in een Azure-beschikbaarheidsset of een paar virtuele machines die zijn geïmplementeerd in Azure Beschikbaarheidszones. Voor productiesystemen verwachten we dat u een paar VM's in een virtuele-machineschaalset implementeert met flexibele indeling in twee beschikbaarheidszones. Bekijk de vergelijking van verschillende implementatietypen voor SAP-werkbelasting voor meer informatie. Op één VM wordt het actieve SQL Server-exemplaar uitgevoerd. De andere VM voert het passieve exemplaar uit
SQL Server-clustering met windows scale-out bestandsserver of gedeelde Azure-schijf
Met Windows Server 2016 heeft Microsoft Opslagruimten Direct geïntroduceerd. Op basis van Opslagruimten wordt directe implementatie, SQL Server FCI-clustering in het algemeen ondersteund. Azure biedt ook gedeelde Azure-schijven die kunnen worden gebruikt voor Windows-clustering. Voor SAP-werkbelasting bieden we geen ondersteuning voor deze ha-opties.
Sql Server-logboekverzending
Een functionaliteit voor hoge beschikbaarheid is verzending van SQL Server-logboeken. Als de VM's die deelnemen aan de ha-configuratie een werkende naamomzetting hebben, is er geen probleem. De installatie in Azure verschilt niet van een installatie die on-premises wordt uitgevoerd met betrekking tot het instellen van logboekverzending en de principes voor het verzenden van logboeken. Details van sql Server-logboekverzending vindt u in het artikel Over logboekverzending (SQL Server).
De functionaliteit voor het verzenden van SQL Server-logboeken is nauwelijks gebruikt in Azure om hoge beschikbaarheid binnen één Azure-regio te bereiken. In de volgende scenario's gebruiken SAP-klanten echter logboekverzending met Azure:
- Scenario's voor herstel na noodgevallen van de ene Azure-regio naar een andere Azure-regio
- Configuratie voor herstel na noodgevallen van on-premises naar een Azure-regio
- Cut-over-scenario's van on-premises naar Azure. In dergelijke gevallen wordt logboekverzending gebruikt om de nieuwe database-implementatie in Azure te synchroniseren met het doorlopende on-premises productiesysteem. Op het moment dat de productie is afgekapt, wordt de productie afgesloten en wordt ervoor gezorgd dat de laatste en meest recente back-ups van transactielogboeken zijn overgedragen naar de Implementatie van de Azure-database. Vervolgens wordt de implementatie van de Azure-database geopend voor productie.
SQL Server AlwaysOn
Omdat Always On wordt ondersteund voor SAP on-premises (zie SAP Note #1772688), wordt dit ondersteund in combinatie met SAP in Azure. Er zijn enkele speciale overwegingen voor het implementeren van de listener voor sql Server-beschikbaarheidsgroepen (niet te verwarren met de Azure-beschikbaarheidsset). Daarom zijn er enkele verschillende installatiestappen nodig.
Enkele overwegingen bij het gebruik van een listener voor beschikbaarheidsgroepen zijn:
- Het gebruik van een listener voor beschikbaarheidsgroepen is alleen mogelijk met Windows Server 2012 of hoger als gastbesturingssystemen van de virtuele machine. Voor Windows Server 2012 moet u ervoor zorgen dat de update voor het inschakelen van listeners voor SQL Server-beschikbaarheidsgroepen op Windows Server 2008 R2 en Windows Server 2012 op virtuele Microsoft Azure-machines is toegepast.
- Voor Windows Server 2008 R2 bestaat deze patch niet. In dit geval moet AlwaysOn op dezelfde manier worden gebruikt als databasespiegeling. Door een failoverpartner op te geven in de verbindingsreeks (uitgevoerd via de parameter dbs/mss/server van SAP default.opgegeven- zie SAP Note #965908).
- Met behulp van een listener voor beschikbaarheidsgroepen moet u de database-VM's verbinden met een toegewezen load balancer. U moet statische IP-adressen toewijzen aan de netwerkinterfaces van deze VM's in de AlwaysOn-configuratie (het definiëren van een statisch IP-adres wordt beschreven in dit artikel). Statische IP-adressen vergeleken met DHCP verhinderen de toewijzing van nieuwe IP-adressen in gevallen waarin beide VM's mogelijk worden gestopt.
- Er zijn speciale stappen vereist bij het bouwen van de WSFC-clusterconfiguratie waar het cluster een speciaal IP-adres nodig heeft dat is toegewezen, omdat Azure met de huidige functionaliteit de clusternaam hetzelfde IP-adres toewijst als het knooppunt waarop het cluster wordt gemaakt. Dit gedrag betekent dat een handmatige stap moet worden uitgevoerd om een ander IP-adres toe te wijzen aan het cluster.
- De listener voor beschikbaarheidsgroepen wordt gemaakt in Azure met TCP/IP-eindpunten, die zijn toegewezen aan de VM's waarop de primaire en secundaire replica's van de beschikbaarheidsgroep worden uitgevoerd.
- Mogelijk moet u deze eindpunten beveiligen met ACL's.
Gedetailleerde documentatie over het implementeren van AlwaysOn met SQL Server in Azure-VM's, zoals:
- Introductie van SQL Server AlwaysOn-beschikbaarheidsgroepen op virtuele Azure-machines.
- Configureer een AlwaysOn-beschikbaarheidsgroep op virtuele Azure-machines in verschillende regio's.
- Configureer een load balancer voor een AlwaysOn-beschikbaarheidsgroep in Azure.
- Aanbevolen procedures voor HADR-configuratie (SQL Server op virtuele machines van Azure)
Notitie
Lees Inleiding tot ALWAYSOn-beschikbaarheidsgroepen van SQL Server op virtuele Azure-machines. U leest meer over de DNN-listener (Direct Network Name) van SQL Server. Deze nieuwe functionaliteit is geïntroduceerd met SQL Server 2019 CU8. Deze nieuwe functionaliteit maakt het gebruik van een Azure Load Balancer die het virtuele IP-adres van de listener voor beschikbaarheidsgroepen verouderd verwerkt.
SQL Server AlwaysOn is de meest gebruikte functionaliteit voor hoge beschikbaarheid en herstel na noodgevallen die wordt gebruikt in Azure voor SAP-workloadimplementaties. De meeste klanten gebruiken AlwaysOn voor hoge beschikbaarheid binnen één Azure-regio. Als de implementatie beperkt is tot slechts twee knooppunten, hebt u twee opties voor connectiviteit:
- De listener voor beschikbaarheidsgroepen gebruiken. Met de listener voor beschikbaarheidsgroepen moet u een Azure-load balancer implementeren.
- Met SQL Server 2016 SP3, SQL Server 2017 CU 25 of SQL Server 2019 CU8 of recentere SQL Server-releases op Windows Server 2016 of hoger kunt u de DNN-listener (Direct Network Name) gebruiken in plaats van een Azure-load balancer. DNN elimineert de vereiste voor een Azure load balancer.
Het gebruik van de connectiviteitsparameters van SQL Server Database Mirroring mag alleen worden overwogen voor een ronde van het onderzoeken van problemen met de andere twee methoden. In dit geval moet u de connectiviteit van de SAP-toepassingen configureren op een manier waarop beide knooppuntnamen een naam hebben. Exacte details van een dergelijke SAP-zijdeconfiguratie worden beschreven in SAP Note #965908. Als u deze optie gebruikt, hoeft u geen listener voor een beschikbaarheidsgroep te configureren. En met dat geen Azure load balancer en daarmee kunnen problemen van deze onderdelen worden onderzocht. Deze optie werkt echter alleen als u uw beschikbaarheidsgroep beperkt tot twee exemplaren.
De meeste klanten gebruiken de SQL Server AlwaysOn-functionaliteit voor herstel na noodgevallen tussen Azure-regio's. Verschillende klanten gebruiken ook de mogelijkheid om back-ups uit te voeren vanaf een secundaire replica.
Transparante gegevensversleuteling van SQL Server
Veel klanten gebruiken TDE (Transparent Data Encryption) van SQL Server bij het implementeren van hun SAP SQL Server-databases in Azure. De TDE-functionaliteit van SQL Server wordt volledig ondersteund door SAP (zie SAP Note #1380493).
SQL Server TDE toepassen
In gevallen waarin u een heterogene migratie uitvoert vanuit een andere database, die on-premises wordt uitgevoerd, naar Windows/SQL Server die wordt uitgevoerd in Azure, moet u uw lege doeldatabase in SQL Server van tevoren maken. Als volgende stap past u de TDE-functionaliteit van SQL Server toe op deze lege database. Reden waarom u in deze volgorde wilt uitvoeren, is dat het versleutelen van de lege database enige tijd kan duren. De SAP-importprocessen importeren vervolgens de gegevens in de versleutelde database tijdens de downtimefase. De overhead van het importeren in een versleutelde database heeft een veel lagere tijdsimpact dan het versleutelen van de database na de exportfase in de down time-fase. Er zijn negatieve ervaringen gemaakt bij het toepassen van TDE met SAP-werkbelasting die wordt uitgevoerd boven op de database. Daarom wordt de implementatie van TDE behandeld als een activiteit die moet worden uitgevoerd zonder of weinig SAP-werkbelasting op de specifieke database. Vanaf SQL Server 2016 kunt u de TDE-scan stoppen en hervatten waarmee de eerste versleuteling wordt uitgevoerd. In het document Transparent Data Encryption (TDE) worden de opdracht en details beschreven.
In gevallen waarin u SAP SQL Server-databases van on-premises naar Azure verplaatst, raden we u aan te testen op welke infrastructuur u de versleuteling het snelst kunt toepassen. Houd voor dit geval rekening met deze feiten:
- U kunt niet definiëren hoeveel threads worden gebruikt om gegevensversleuteling toe te passen op de database. Het aantal threads is sterk afhankelijk van het aantal schijfvolumes waarover de SQL Server-gegevens en logboekbestanden worden verdeeld. Betekent hoe meer afzonderlijke volumes (stationsletters), hoe meer threads parallel worden gebruikt om de versleuteling uit te voeren. Een dergelijke configuratie is een beetje in strijd met eerdere suggesties voor schijfconfiguratie bij het bouwen van een of een kleiner aantal opslagruimten voor de SQL Server-databasebestanden in Virtuele Azure-machines. Een configuratie met een paar volumes zou leiden tot een paar threads die de versleuteling uitvoeren. Een enkele thread versleuteling is het lezen van 64 kB-gebieden, versleutelt het en schrijft vervolgens een record in het transactielogboekbestand, waarbij wordt aangegeven dat de omvang is versleuteld. Als gevolg hiervan is de belasting van het transactielogboek gemiddeld.
- In oudere VERSIES van SQL Server werd back-upcompressie niet meer efficiënt wanneer u uw SQL Server-database hebt versleuteld. Dit gedrag kan zich ontwikkelen tot een probleem wanneer uw plan was om uw SQL Server-database on-premises te versleutelen en vervolgens een back-up naar Azure te kopiëren om de database in Azure te herstellen. Back-upcompressie van SQL Server kan een compressieverhouding van factor 4 bereiken.
- Met SQL Server 2016 heeft SQL Server nieuwe functionaliteit geïntroduceerd waarmee back-ups van versleutelde databases op een efficiënte manier kunnen worden gecomprimeerd. Zie deze blog voor meer informatie.
Azure Key Vault gebruiken
Azure biedt de service van een Key Vault voor het opslaan van versleutelingssleutels. SQL Server aan de andere kant biedt een connector voor het gebruik van Azure Key Vault als archief voor de TDE-certificaten.
Meer informatie over het gebruik van Azure Key Vault voor SQL Server TDE-lijsten, zoals:
- Azure Key Vault-integratie configureren voor SQL Server op Azure-VM's (Resource Manager).
- Meer vragen van klanten over transparante gegevensversleuteling van SQL Server : TDE + Azure Key Vault.
Belangrijk
Het is raadzaam om de nieuwste patches van SQL Server 2014, SQL Server 2016 en SQL Server 2017 te gebruiken, met name met Azure Key Vault. Reden hiervoor is dat op basis van feedback, optimalisaties en oplossingen van klanten op de code zijn toegepast. Controleer bijvoorbeeld KBA #4058175.
Minimale implementatieconfiguraties
In deze sectie wordt een set minimale configuraties voorgesteld voor verschillende grootten van databases onder SAP-werkbelasting. Het is te moeilijk om te beoordelen of deze grootten passen bij uw specifieke workload. In sommige gevallen kunnen we vrijgevig geheugen gebruiken in vergelijking met de grootte van de database. Aan de andere kant kan de grootte van de schijf te laag zijn voor sommige werkbelastingen. Daarom moeten deze configuraties worden behandeld als wat ze zijn. Het zijn configuraties waarmee u een beginpunt krijgt. Configuraties om uw specifieke vereisten voor workload en kostenefficiëntie af te stemmen.
Een voorbeeld van een configuratie voor een klein SQL Server-exemplaar met een databasegrootte tussen 50 GB en 250 GB kan er als volgt uitzien
| Configuratie | Database-VM | Opmerkingen |
|---|---|---|
| VM-type | E4s_v3/v4/v5 (4 vCPU/32 GiB RAM) | |
| Versneld netwerken | Inschakelen | |
| SQL Server-versie | SQL Server 2019 of recenter | |
| Aantal gegevensbestanden | 4 | |
| Aantal logboekbestanden | 1 | |
| Aantal tijdelijke gegevensbestanden | 4 of standaard sinds SQL Server 2016 | |
| Besturingssysteem | Windows Server 2019 of recenter | |
| Schijfaggregatie | Opslagruimten indien gewenst | |
| Bestandssysteem | NTFS | |
| Blokgrootte opmaken | 64 kB | |
| # en het type gegevensschijven | Premium Storage v1: 2 x P10 (RAID0) Premium Storage v2: 2 x 150 GiB (RAID0) - standaard IOPS en doorvoer of equivalente Premium SSD v2 |
Cache = Alleen-lezen voor Premium Storage v1 |
| # en type logboekschijven | Premium storage v1: 1 x P20 Premium Storage v2: 1 x 128 GiB - standaard-IOPS en doorvoer of equivalente Premium SSD v2 |
Cache = NONE |
| SQL Server: maximale geheugenparameter | 90% van het fysieke RAM-geheugen | Ervan uitgaande dat één exemplaar |
Een voorbeeld van een configuratie of een klein SQL Server-exemplaar met een databasegrootte tussen 250 GB – 750 GB, zoals een kleiner SAP Business Suite-systeem, kan er als volgt uitzien
| Configuratie | Database-VM | Opmerkingen |
|---|---|---|
| VM-type | E16s_v3/v4/v5 (16 vCPU/128 GiB RAM) | |
| Versneld netwerken | Inschakelen | |
| SQL Server-versie | SQL Server 2019 of recenter | |
| Aantal gegevensbestanden | 8 | |
| Aantal logboekbestanden | 1 | |
| Aantal tijdelijke gegevensbestanden | 8 of standaard sinds SQL Server 2016 | |
| Besturingssysteem | Windows Server 2019 of recenter | |
| Schijfaggregatie | Opslagruimten indien gewenst | |
| Bestandssysteem | NTFS | |
| Blokgrootte opmaken | 64 kB | |
| # en het type gegevensschijven | Premium Storage v1: 4 x P20 (RAID0) Premium Storage v2: 4 x 100 GiB - 200 GiB (RAID0) - standaard IOPS en 25 MB/seconde extra doorvoer per schijf of equivalente Premium SSD v2 |
Cache = Alleen-lezen voor Premium Storage v1 |
| # en type logboekschijven | Premium storage v1: 1 x P20 Premium Storage v2: 1 x 200 GiB - standaard-IOPS en doorvoer of equivalente Premium SSD v2 |
Cache = NONE |
| SQL Server: maximale geheugenparameter | 90% van het fysieke RAM-geheugen | Ervan uitgaande dat één exemplaar |
Een voorbeeld van een configuratie voor een gemiddeld SQL Server-exemplaar met een databasegrootte tussen 750 GB en 2000 GB, zoals een gemiddeld SAP Business Suite-systeem, kan er als volgt uitzien
| Configuratie | Database-VM | Opmerkingen |
|---|---|---|
| VM-type | E64s_v3/v4/v5 (64 vCPU/432 GiB RAM) | |
| Versneld netwerken | Inschakelen | |
| SQL Server-versie | SQL Server 2019 of recenter | |
| Aantal gegevensapparaten | 16 | |
| Aantal logboekapparaten | 1 | |
| Aantal tijdelijke gegevensbestanden | 8 of standaard sinds SQL Server 2016 | |
| Besturingssysteem | Windows Server 2019 of recenter | |
| Schijfaggregatie | Opslagruimten indien gewenst | |
| Bestandssysteem | NTFS | |
| Blokgrootte opmaken | 64 kB | |
| # en het type gegevensschijven | Premium Storage v1: 4 x P30 (RAID0) Premium storage v2: 4 x 250 GiB - 500 GiB - plus 2000 IOPS en 75 MB/sec doorvoer per schijf of equivalente Premium SSD v2 |
Cache = Alleen-lezen voor Premium Storage v1 |
| # en type logboekschijven | Premium storage v1: 1 x P20 Premium Storage v2: 1 x 400 GiB - standaard IOPS en 75 MB/sec extra doorvoer of equivalente Premium SSD v2 |
Cache = NONE |
| SQL Server: maximale geheugenparameter | 90% van het fysieke RAM-geheugen | Ervan uitgaande dat één exemplaar |
Een voorbeeld van een configuratie voor een groter SQL Server-exemplaar met een databasegrootte tussen 2000 GB en 4000 GB, zoals een groter SAP Business Suite-systeem, kan er als volgt uitzien
| Configuratie | Database-VM | Opmerkingen |
|---|---|---|
| VM-type | E96(d)s_v5 (96 vCPU/672 GiB RAM) | |
| Versneld netwerken | Inschakelen | |
| SQL Server-versie | SQL Server 2019 of recenter | |
| Aantal gegevensapparaten | 24 | |
| Aantal logboekapparaten | 1 | |
| Aantal tijdelijke gegevensbestanden | 8 of standaard sinds SQL Server 2016 | |
| Besturingssysteem | Windows Server 2019 of recenter | |
| Schijfaggregatie | Opslagruimten indien gewenst | |
| Bestandssysteem | NTFS | |
| Blokgrootte opmaken | 64 kB | |
| # en het type gegevensschijven | Premium Storage v1: 4 x P30 (RAID0) Premium Storage v2: 4 x 500 GiB - 800 GiB - plus 2500 IOPS en 100 MB/sec doorvoer per schijf of equivalente Premium SSD v2 |
Cache = Alleen-lezen voor Premium Storage v1 |
| # en type logboekschijven | Premium storage v1: 1 x P20 Premium Storage v2: 1 x 400 GiB - plus 1.000 IOPS en 75 MB per seconde extra doorvoer of equivalente Premium SSD v2 |
Cache = NONE |
| SQL Server: maximale geheugenparameter | 90% van het fysieke RAM-geheugen | Ervan uitgaande dat één exemplaar |
Een voorbeeld van een configuratie voor een groot SQL Server-exemplaar met een databasegrootte van 4 TB+, zoals een groot, wereldwijd gebruikt SAP Business Suite-systeem, kan er als volgt uitzien
| Configuratie | Database-VM | Opmerkingen |
|---|---|---|
| VM-type | M-serie (1,0 tot 4,0 TB RAM) | |
| Versneld netwerken | Inschakelen | |
| SQL Server-versie | SQL Server 2019 of recenter | |
| Aantal gegevensapparaten | 32 | |
| Aantal logboekapparaten | 1 | |
| Aantal tijdelijke gegevensbestanden | 8 of standaard sinds SQL Server 2016 | |
| Besturingssysteem | Windows Server 2019 of recenter | |
| Schijfaggregatie | Opslagruimten indien gewenst | |
| Bestandssysteem | NTFS | |
| Blokgrootte opmaken | 64 kB | |
| # en het type gegevensschijven | Premium Storage v1: 4+ x P40 (RAID0) Premium Storage v2: 4+ x 1.000 GiB - 4.000 GiB - plus 4.500 IOPS en doorvoer van 125 MB per seconde per schijf of equivalente Premium SSD v2 |
Cache = Alleen-lezen voor Premium Storage v1 |
| # en type logboekschijven | Premium storage v1: 1 x P30 Premium Storage v2: 1 x 500 GiB - plus 2.000 IOPS en 125 MB per seconde doorvoer of equivalente Premium SSD v2 |
Cache = NONE |
| SQL Server: maximale geheugenparameter | 95% van het fysieke RAM-geheugen | Ervan uitgaande dat één exemplaar |
Deze configuratie is bijvoorbeeld de database-VM-configuratie van een SAP Business Suite op SQL Server. Deze VM host de database van 30 TB van de individuele globale SAP Business Suite-instantie van een wereldwijd bedrijf met meer dan $ 200B jaarlijkse omzet en meer dan 200K fulltime werknemers. Het systeem voert alle financiële verwerking, verkoop- en distributieverwerking uit en nog veel meer bedrijfsprocessen uit verschillende gebieden, waaronder Noord-Amerika n salarisadministratie. Het systeem wordt uitgevoerd in Azure sinds begin 2018 met vm's uit de Azure M-serie als database-VM's. Als hoge beschikbaarheid gebruikt het systeem AlwaysOn met één synchrone replica in een andere beschikbaarheidszone van dezelfde Azure-regio. En een andere asynchrone replica in een andere Azure-regio. De NetWeaver-toepassingslaag wordt geïmplementeerd op de nieuwste D(a)/E(a) VM-families.
| Configuratie | Database-VM | Opmerkingen |
|---|---|---|
| VM-type | M192dms_v2 (192 vCPU/4.196 GiB RAM) | |
| Versneld netwerken | Ingeschakeld | |
| SQL Server-versie | SQL Server 2019 | |
| Aantal gegevensbestanden | 32 | |
| Aantal logboekbestanden | 1 | |
| Aantal tijdelijke gegevensbestanden | 8 | |
| Besturingssysteem | Windows Server 2019 | |
| Schijfaggregatie | Opslagruimten | |
| Bestandssysteem | NTFS | |
| Blokgrootte opmaken | 64 kB | |
| # en het type gegevensschijven | Premium Storage v1: 16 x P40 of equivalente Premium SSD v2 | Cache = Alleen-lezen |
| # en type logboekschijven | Premium Storage v1: 1 x P60 of equivalente Premium SSD v2 | Schrijfversneller gebruiken |
| # en type tempdb-schijven | Premium Storage v1: 1 x P30 of equivalente Premium SSD v2 | Geen caching |
| SQL Server: maximale geheugenparameter | 95% van het fysieke RAM-geheugen |
Algemene SQL Server voor SAP in Azure-samenvatting
Deze handleiding bevat veel aanbevelingen en we raden u aan deze meer dan één keer te lezen voordat u uw Azure-implementatie plant. Over het algemeen moet u echter de belangrijkste aanbevelingen voor SQL Server in Azure volgen:
- Gebruik de nieuwste SQLServer-release, zoals SQL Server 2022, die de meeste voordelen heeft in Azure.
- Plan uw SAP-systeemlandschap in Azure zorgvuldig om de indeling van het gegevensbestand en de Azure-beperkingen te verdelen:
- U hebt niet te veel schijven, maar u hebt voldoende om ervoor te zorgen dat u uw vereiste IOPS kunt bereiken.
- Alleen stripe over schijven als u een hogere doorvoer wilt bereiken.
- U hebt niet te veel schijven, maar u hebt voldoende om ervoor te zorgen dat u uw vereiste IOPS kunt bereiken.
- Installeer nooit software of plaats bestanden die persistentie vereisen op het station D:\ omdat het niet-permanent is. Alles op dit station kan verloren gaan bij het opnieuw opstarten van Windows of het opnieuw opstarten van de VIRTUELE machine.
- Gebruik uw SQL Server AlwaysOn-oplossing om databasegegevens te repliceren.
- Gebruik altijd naamomzetting, vertrouw niet op IP-adressen.
- Pas met BEHULP van SQL Server TDE de meest recente SQL Server-patches toe.
- Wees voorzichtig met het gebruik van SQL Server-installatiekopieën uit Azure Marketplace. Als u de SQL Server gebruikt, moet u de sortering van het exemplaar wijzigen voordat u een SAP NetWeaver-systeem erop installeert.
- Installeer en configureer de SAP Host Monitoring voor Azure, zoals beschreven in de implementatiehandleiding.
Volgende stappen
Het artikel lezen