Hoge beschikbaarheid van SAP HANA omhoog SCHALEN met Azure NetApp Files op RHEL
In dit artikel wordt beschreven hoe u SAP HANA-systeemreplicatie configureert in de opschaalimplementatie, wanneer de HANA-bestandssystemen worden gekoppeld via NFS, met behulp van Azure NetApp Files. In de voorbeeldconfiguraties en installatieopdrachten worden exemplaarnummer 03 en HANA-systeem-id HN1 gebruikt. SAP HANA-systeemreplicatie bestaat uit één primair knooppunt en ten minste één secundair knooppunt.
Wanneer stappen in dit document zijn gemarkeerd met de volgende voorvoegsels, is de betekenis als volgt:
- [A]: De stap is van toepassing op alle knooppunten
- [1]: De stap is alleen van toepassing op knooppunt1
- [2]: De stap is alleen van toepassing op node2
Vereisten
Lees eerst de volgende SAP-notities en -documenten:
- SAP-notitie 1928533, met:
- De lijst met vm-grootten (virtuele Azure-machines) die worden ondersteund voor de implementatie van SAP-software.
- Belangrijke capaciteitsinformatie voor Azure VM-grootten.
- De ondersteunde combinaties van SAP-software en -besturingssystemen en -databases.
- De vereiste SAP-kernelversie voor Windows en Linux in Microsoft Azure.
- SAP Note 2015553 bevat vereisten voor SAP-ondersteunde SAP-software-implementaties in Azure.
- SAP Note 405827 bevat aanbevolen bestandssystemen voor HANA-omgevingen.
- SAP Note 2002167 heeft aanbevolen besturingssysteeminstellingen voor Red Hat Enterprise Linux.
- SAP Note 2009879 heeft SAP HANA-richtlijnen voor Red Hat Enterprise Linux.
- SAP Note 3108302 heeft SAP HANA-richtlijnen voor Red Hat Enterprise Linux 9.x.
- SAP Note 2178632 bevat gedetailleerde informatie over alle metrische bewakingsgegevens die zijn gerapporteerd voor SAP in Azure.
- SAP-opmerking 2191498 beschikt over de vereiste VERSIE van de SAP Host Agent voor Linux in Azure.
- SAP Note 2243692 informatie heeft over SAP-licenties in Linux in Azure.
- SAP-opmerking 1999351 meer informatie over het oplossen van problemen heeft voor de Uitgebreide Bewakingsextensie van Azure voor SAP.
- Sap Community Wiki bevat alle vereiste SAP-notities voor Linux.
- Azure Virtual Machines plannen en implementeren voor SAP in Linux
- Azure Virtual Machines-implementatie voor SAP in Linux
- DBMS-implementatie van Azure Virtual Machines voor SAP in Linux
- SAP HANA-systeemreplicatie in Pacemaker-cluster
- Algemene documentatie voor Red Hat Enterprise Linux (RHEL):
- Overzicht van invoegtoepassingen voor hoge beschikbaarheid
- Beheer van invoegtoepassingen met hoge beschikbaarheid
- Naslaginformatie over invoegtoepassingen met hoge beschikbaarheid
- SAP HANA-systeemreplicatie configureren in opschalen in een Pacemaker-cluster wanneer de HANA-bestandssystemen zich op NFS-shares bevinden
- Azure-specifieke RHEL-documentatie:
- Ondersteuningsbeleid voor RHEL-clusters met hoge beschikbaarheid - Microsoft Azure Virtual Machines als clusterleden
- Een Red Hat Enterprise Linux 7.4 -cluster (en hoger) met hoge beschikbaarheid installeren en configureren in Microsoft Azure
- SAP HANA-systeemreplicatie configureren in een Pacemaker-cluster wanneer de HANA-bestandssystemen zich op NFS-shares bevinden
- NFS v4.1-volumes in Azure NetApp Files voor SAP HANA
Overzicht
Traditioneel in een opschaalomgeving worden alle bestandssystemen voor SAP HANA gekoppeld vanuit lokale opslag. Het instellen van hoge beschikbaarheid (HA) van SAP HANA-systeemreplicatie in Red Hat Enterprise Linux wordt gepubliceerd in SAP HANA-systeemreplicatie instellen op RHEL.
Om SAP HANA HA van een scale-upsysteem op Azure NetApp Files NFS-shares te bereiken, hebben we wat meer resourceconfiguratie in het cluster nodig, zodat HANA-resources kunnen worden hersteld wanneer één knooppunt geen toegang meer heeft tot de NFS-shares in Azure NetApp Files. Het cluster beheert de NFS-koppelingen, zodat deze de status van de resources kan bewaken. De afhankelijkheden tussen de bestandssysteemkoppelingen en de SAP HANA-resources worden afgedwongen.
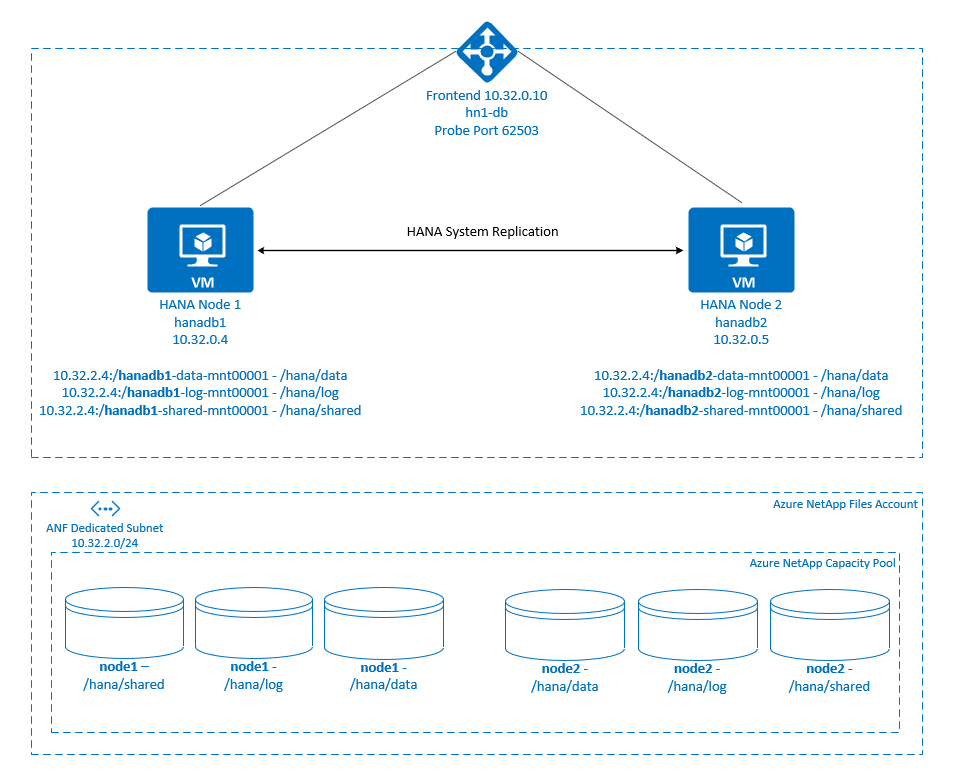 .
.
SAP HANA-bestandssystemen worden gekoppeld aan NFS-shares met behulp van Azure NetApp Files op elk knooppunt. Bestandssystemen /hana/dataen /hana/log/hana/shared zijn uniek voor elk knooppunt.
Gekoppeld op knooppunt1 (hanadb1):
- 10.32.2.4:/hanadb1-data-mnt00001 op /hana/data
- 10.32.2.4:/hanadb1-log-mnt00001 op /hana/log
- 10.32.2.4:/hanadb1-shared-mnt00001 op /hana/shared
Gekoppeld op node2 (hanadb2):
- 10.32.2.4:/hanadb2-data-mnt00001 op /hana/data
- 10.32.2.4:/hanadb2-log-mnt00001 op /hana/log
- 10.32.2.4:/hanadb2-shared-mnt00001 op /hana/shared
Notitie
Bestandssystemen /hana/shareden /hana/data/hana/log worden niet gedeeld tussen de twee knooppunten. Elk clusterknooppunt heeft zijn eigen afzonderlijke bestandssystemen.
De SAP HANA-systeemreplicatieconfiguratie maakt gebruik van een toegewezen virtuele hostnaam en virtuele IP-adressen. In Azure is een load balancer vereist voor het gebruik van een virtueel IP-adres. De configuratie die hier wordt weergegeven, heeft een load balancer met:
- Front-end-IP-adres: 10.32.0.10 voor hn1-db
- Testpoort: 62503
De Azure NetApp Files-infrastructuur instellen
Voordat u verdergaat met de installatie van de Infrastructuur van Azure NetApp Files, moet u vertrouwd raken met de documentatie van Azure NetApp Files.
Azure NetApp Files is beschikbaar in verschillende Azure-regio's. Controleer of uw geselecteerde Azure-regio Azure NetApp Files biedt.
Zie de beschikbaarheid van Azure NetApp Files per Azure-regio voor informatie over de beschikbaarheid van Azure NetApp Files per Azure-regio.
Belangrijke aandachtspunten
Wanneer u uw Azure NetApp Files-volumes voor SAP HANA-schaalsystemen maakt, moet u rekening houden met de belangrijke overwegingen die worden beschreven in NFS v4.1-volumes in Azure NetApp Files voor SAP HANA.
Grootte van HANA-database wijzigen in Azure NetApp Files
De doorvoer van een Azure NetApp Files-volume is een functie van de volumegrootte en het serviceniveau, zoals beschreven in Serviceniveau voor Azure NetApp Files.
Terwijl u de infrastructuur voor SAP HANA in Azure ontwerpt met Azure NetApp Files, moet u rekening houden met de aanbevelingen in NFS v4.1-volumes in Azure NetApp Files voor SAP HANA.
De configuratie in dit artikel bevat eenvoudige Azure NetApp Files-volumes.
Belangrijk
Voor productiesystemen, waarbij de prestaties een sleutel zijn, raden we u aan om Azure NetApp Files-toepassingsvolumegroep voor SAP HANA te evalueren en te gebruiken.
Azure NetApp Files-resources implementeren
In de volgende instructies wordt ervan uitgegaan dat u uw virtuele Azure-netwerk al hebt geïmplementeerd. De Azure NetApp Files-resources en -VM's, waarbij de Azure NetApp Files-resources worden gekoppeld, moeten worden geïmplementeerd in hetzelfde virtuele Azure-netwerk of in gekoppelde virtuele Azure-netwerken.
Maak een NetApp-account in uw geselecteerde Azure-regio door de instructies in Een NetApp-account maken te volgen.
Stel een Azure NetApp Files-capaciteitsgroep in door de instructies te volgen in Een Azure NetApp Files-capaciteitspool instellen.
De HANA-architectuur die in dit artikel wordt weergegeven, maakt gebruik van één Azure NetApp Files-capaciteitspool op ultraserviceniveau. Voor HANA-workloads in Azure raden we u aan een Azure NetApp Files Ultra- of Premium-serviceniveau te gebruiken.
Een subnet delegeren naar Azure NetApp Files, zoals beschreven in de instructies in Een subnet delegeren aan Azure NetApp Files.
Implementeer Azure NetApp Files-volumes door de instructies te volgen in Een NFS-volume maken voor Azure NetApp Files.
Wanneer u de volumes implementeert, moet u de versie NFSv4.1 selecteren. Implementeer de volumes in het aangewezen Azure NetApp Files-subnet. De IP-adressen van de Azure NetApp-volumes worden automatisch toegewezen.
Houd er rekening mee dat de Azure NetApp Files-resources en de Azure-VM's zich in hetzelfde virtuele Azure-netwerk of in gekoppelde virtuele Azure-netwerken moeten bevinden. Dit zijn bijvoorbeeld
hanadb1-data-mnt00001hanadb1-log-mnt00001de volumenamen ennfs://10.32.2.4/hanadb1-data-mnt00001nfs://10.32.2.4/hanadb1-log-mnt00001zijn de bestandspaden voor de Azure NetApp Files-volumes.Op hanadb1:
- Volume hanadb1-data-mnt00001 (nfs://10.32.2.4:/hanadb1-data-mnt00001)
- Volume hanadb1-log-mnt00001 (nfs://10.32.2.4:/hanadb1-log-mnt00001)
- Volume hanadb1-shared-mnt00001 (nfs://10.32.2.4:/hanadb1-shared-mnt00001)
Op hanadb2:
- Volume hanadb2-data-mnt00001 (nfs://10.32.2.4:/hanadb2-data-mnt00001)
- Volume hanadb2-log-mnt00001 (nfs://10.32.2.4:/hanadb2-log-mnt00001)
- Volume hanadb2-shared-mnt00001 (nfs://10.32.2.4:/hanadb2-shared-mnt00001)
Notitie
Alle opdrachten die u in dit artikel wilt koppelen /hana/shared , worden weergegeven voor NFSv4.1-volumes /hana/shared .
Als u de /hana/shared volumes als NFSv3-volumes hebt geïmplementeerd, vergeet dan niet om de koppelingsopdrachten voor /hana/shared NFSv3 aan te passen.
De infrastructuur voorbereiden
Azure Marketplace bevat installatiekopieën die zijn gekwalificeerd voor SAP HANA met de invoegtoepassing Hoge beschikbaarheid, die u kunt gebruiken om nieuwe VM's te implementeren met behulp van verschillende versies van Red Hat.
Virtuele Linux-machines handmatig implementeren via Azure Portal
In dit document wordt ervan uitgegaan dat u al een resourcegroep, een virtueel Azure-netwerk en een subnet hebt geïmplementeerd.
Vm's implementeren voor SAP HANA. Kies een geschikte RHEL-installatiekopieën die worden ondersteund voor het HANA-systeem. U kunt een VIRTUELE machine implementeren in een van de beschikbaarheidsopties: virtuele-machineschaalset, beschikbaarheidszone of beschikbaarheidsset.
Belangrijk
Zorg ervoor dat het besturingssysteem dat u selecteert SAP is gecertificeerd voor SAP HANA op de specifieke VM-typen die u in uw implementatie wilt gebruiken. U kunt sap HANA-gecertificeerde VM-typen en hun besturingssysteemreleases opzoeken in GECERTIFICEERDE IAAS-platformen van SAP HANA. Zorg ervoor dat u de details van het VM-type bekijkt om de volledige lijst met door SAP HANA ondersteunde besturingssysteemreleases voor het specifieke VM-type op te halen.
Azure Load Balancer configureren
Tijdens de VM-configuratie hebt u de mogelijkheid om een load balancer te maken of te selecteren in de sectie Netwerken. Volg de onderstaande stappen om de standaard load balancer in te stellen voor het instellen van hoge beschikbaarheid van de HANA-database.
Volg de stappen in Load Balancer maken om een standaard load balancer in te stellen voor een SAP-systeem met hoge beschikbaarheid met behulp van Azure Portal. Houd rekening met de volgende punten tijdens de installatie van de load balancer:
- Front-end-IP-configuratie: maak een front-end-IP-adres. Selecteer dezelfde virtuele netwerk- en subnetnaam als uw virtuele databasemachines.
- Back-endpool: maak een back-endpool en voeg database-VM's toe.
- Regels voor inkomend verkeer: maak een taakverdelingsregel. Volg dezelfde stappen voor beide taakverdelingsregels.
- Front-end-IP-adres: Selecteer een front-end-IP-adres.
- Back-endpool: Selecteer een back-endpool.
- Poorten voor hoge beschikbaarheid: selecteer deze optie.
- Protocol: selecteer TCP.
- Statustest: maak een statustest met de volgende details:
- Protocol: selecteer TCP.
- Poort: bijvoorbeeld 625<instance-no.>.
- Interval: Voer 5 in.
- Testdrempel: voer 2 in.
- Time-out voor inactiviteit (minuten): voer 30 in.
- Zwevend IP-adres inschakelen: selecteer deze optie.
Notitie
De configuratie-eigenschap numberOfProbesvan de statustest, ook wel bekend als drempelwaarde voor beschadigde status in de portal, wordt niet gerespecteerd. Als u het aantal geslaagde of mislukte opeenvolgende tests wilt bepalen, stelt u de eigenschap probeThreshold in op 2. Het is momenteel niet mogelijk om deze eigenschap in te stellen met behulp van Azure Portal, dus gebruik de Azure CLI of de PowerShell-opdracht.
Lees voor meer informatie over de vereiste poorten voor SAP HANA het hoofdstuk Verbindingen met tenantdatabases in de handleiding sap HANA-tenantdatabases of SAP Note 2388694.
Notitie
Wanneer VM's zonder openbare IP-adressen worden geplaatst in de back-endpool van een intern (geen openbaar IP-adres) exemplaar van Standard Azure Load Balancer, is er geen uitgaande internetverbinding, tenzij er meer configuratie wordt uitgevoerd om routering naar openbare eindpunten toe te staan. Zie Openbare eindpuntconnectiviteit voor virtuele machines met standard Azure Load Balancer in scenario's met hoge beschikbaarheid van SAP voor meer informatie over het bereiken van uitgaande connectiviteit.
Belangrijk
Schakel TCP-tijdstempels niet in op Azure-VM's die achter Azure Load Balancer worden geplaatst. Als u TCP-tijdstempels inschakelt, kunnen de statustests mislukken. Stel de parameter net.ipv4.tcp_timestamps in op 0. Zie Statustests van Load Balancer en SAP Note 2382421 voor meer informatie.
Het Azure NetApp Files-volume koppelen
[A] Koppelpunten maken voor de HANA-databasevolumes.
sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared[A] Controleer de NFS-domeininstelling. Zorg ervoor dat het domein is geconfigureerd als het standaarddomein van Azure NetApp Files, dat wil weten defaultv4iddomain.com en dat de toewijzing is ingesteld op niemand.
sudo cat /etc/idmapd.confVoorbeelduitvoer:
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyBelangrijk
Zorg ervoor dat u het NFS-domein op
/etc/idmapd.confde virtuele machine instelt op de standaarddomeinconfiguratie in Azure NetApp Files: defaultv4iddomain.com. Als de domeinconfiguratie op de NFS-client (dat wil gezegd de VM) en de NFS-server (dat wil gezegd de Configuratie van Azure NetApp Files) niet overeenkomen, worden de machtigingen voor bestanden op Azure NetApp Files-volumes weergegeven alsnobody.[1] Koppel de knooppuntspecifieke volumes op node1 (hanadb1).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-data-mnt00001 /hana/data[2] Koppel de knooppuntspecifieke volumes op node2 (hanadb2).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-data-mnt00001 /hana/data[A] Controleer of alle HANA-volumes zijn gekoppeld aan NFS-protocolversie NFSv4.
sudo nfsstat -mControleer of de vlag
versis ingesteld op 4.1. Voorbeeld van hanadb1:/hana/log from 10.32.2.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/data from 10.32.2.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/shared from 10.32.2.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4[A] Controleer nfs4_disable_idmapping. Deze moet worden ingesteld op Y. Voer de koppelingsopdracht uit om de mapstructuur te maken waarin nfs4_disable_idmapping zich bevindt. U kunt de map
/sys/modulesniet handmatig maken omdat de toegang is gereserveerd voor de kernel en stuurprogramma's.Controleer
nfs4_disable_idmapping.sudo cat /sys/module/nfs/parameters/nfs4_disable_idmappingAls u het volgende wilt instellen
nfs4_disable_idmapping:sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmappingDe configuratie permanent maken.
sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confZie de Red Hat Knowledge Base voor meer informatie over het wijzigen van de
nfs_disable_idmappingparameter.
SAP HANA-installatie
[A] Hostnaamomzetting instellen voor alle hosts.
U kunt een DNS-server gebruiken of het
/etc/hostsbestand op alle knooppunten wijzigen. In dit voorbeeld ziet u hoe u het/etc/hostsbestand gebruikt. Vervang het IP-adres en de hostnaam in de volgende opdrachten:sudo vi /etc/hostsVoeg de volgende regels in het
/etc/hostsbestand in. Wijzig het IP-adres en de hostnaam zodat deze overeenkomen met uw omgeving.10.32.0.4 hanadb1 10.32.0.5 hanadb2[A] Bereid het besturingssysteem voor op het uitvoeren van SAP HANA in Azure NetApp met NFS, zoals beschreven in SAP Note 3024346 - Linux-kernelinstellingen voor NetApp NFS. Maak een configuratiebestand
/etc/sysctl.d/91-NetApp-HANA.confvoor de NetApp-configuratie-instellingen.sudo vi /etc/sysctl.d/91-NetApp-HANA.confVoeg de volgende vermeldingen toe in het configuratiebestand.
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Maak het configuratiebestand
/etc/sysctl.d/ms-az.confmet meer optimalisatie-instellingen.sudo vi /etc/sysctl.d/ms-az.confVoeg de volgende vermeldingen toe in het configuratiebestand.
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Tip
Vermijd het instellen
net.ipv4.ip_local_port_rangeennet.ipv4.ip_local_reserved_portsexpliciet in desysctlconfiguratiebestanden, zodat de SAP Host Agent de poortbereiken kan beheren. Zie SAP Note 2382421 voor meer informatie.[A] Pas de
sunrpcinstellingen aan, zoals aanbevolen in SAP Note 3024346 - Linux-kernelinstellingen voor NetApp NFS.sudo vi /etc/modprobe.d/sunrpc.confVoeg de volgende regel in:
options sunrpc tcp_max_slot_table_entries=128[A] Voer de RHEL-besturingssysteemconfiguratie voor HANA uit.
Configureer het besturingssysteem zoals beschreven in de volgende SAP-notities op basis van uw RHEL-versie:
- 2292690 - SAP HANA DB: Aanbevolen besturingssysteeminstellingen voor RHEL 7
- 2777782 - SAP HANA DB: Aanbevolen besturingssysteeminstellingen voor RHEL 8
- 2455582 - Linux: SAP-toepassingen uitvoeren die zijn gecompileerd met GCC 6.x
- 2593824 - Linux: SAP-toepassingen uitvoeren die zijn gecompileerd met GCC 7.x
- 2886607 - Linux: SAP-toepassingen uitvoeren die zijn gecompileerd met GCC 9.x
[A] Installeer sap HANA.
Vanaf HANA 2.0 SPS 01 is MDC de standaardoptie. Wanneer u het HANA-systeem installeert, worden SYSTEMDB en een tenant met dezelfde SID samen gemaakt. In sommige gevallen wilt u de standaardtenant niet. Als u geen eerste tenant samen met de installatie wilt maken, kunt u SAP Note volgen 2629711.
Voer het hdblcm-programma uit vanaf de HANA-dvd. Voer de volgende waarden in bij de prompt:
- Kies installatie: Voer 1 in (voor installatie).
- Selecteer meer onderdelen voor installatie: Voer 1 in.
- Voer het installatiepad [/hana/shared] in: selecteer Enter om de standaardwaarde te accepteren.
- Voer de lokale hostnaam [..]: selecteer Enter om de standaardwaarde te accepteren. Wilt u extra hosts toevoegen aan het systeem? (y/n) [n]: n.
- Voer de SAP HANA-systeem-id in: Voer HN1 in.
- Voer exemplaarnummer [00] in: Voer 03 in.
- Databasemodus selecteren /Index invoeren [1]: selecteer Enter om de standaardwaarde te accepteren.
- Systeemgebruik selecteren/Index invoeren [4]: Voer 4 in (voor aangepast).
- Locatie van gegevensvolumes invoeren [/hana/data]: selecteer Enter om de standaardwaarde te accepteren.
- Locatie van logboekvolumes [/hana/log] invoeren: selecteer Enter om de standaardwaarde te accepteren.
- Maximale geheugentoewijzing beperken? [n]: Selecteer Enter om de standaardwaarde te accepteren.
- Voer de naam van de certificaathost in voor de host ...' [...]: selecteer Enter om de standaardwaarde te accepteren.
- Voer het wachtwoord van de SAP Host Agent-gebruiker (sapadm) in: voer het gebruikerswachtwoord van de hostagent in.
- Bevestig het wachtwoord van de SAP Host Agent-gebruiker (sapadm): voer het gebruikerswachtwoord van de hostagent opnieuw in om te bevestigen.
- Voer het wachtwoord van de systeembeheerder (hn1adm) in: voer het wachtwoord van de systeembeheerder in.
- Bevestig het wachtwoord van de systeembeheerder (hn1adm): voer het wachtwoord van de systeembeheerder opnieuw in om dit te bevestigen.
- Voer De basismap van de systeembeheerder [/usr/sap/HN1/home] in: selecteer Enter om de standaardinstelling te accepteren.
- Voer De aanmeldingsshell van de systeembeheerder [/bin/sh] in: selecteer Enter om de standaardwaarde te accepteren.
- Voer de gebruikers-id van de systeembeheerder in [1001]: selecteer Enter om de standaardwaarde te accepteren.
- Voer de id in van de gebruikersgroep (sapsys) [79]: selecteer Enter om de standaardwaarde te accepteren.
- Voer het wachtwoord van de databasegebruiker (SYSTEM) in: voer het wachtwoord van de databasegebruiker in.
- Bevestig het wachtwoord van databasegebruiker (SYSTEM): voer het wachtwoord van de databasegebruiker opnieuw in om dit te bevestigen.
- Systeem opnieuw opstarten nadat de computer opnieuw is opgestart? [n]: Selecteer Enter om de standaardwaarde te accepteren.
- Wilt u doorgaan? (y/n): Valideer de samenvatting. Voer y in om door te gaan.
[A] Werk de SAP-hostagent bij.
Download het meest recente SAP Host Agent-archief vanuit het SAP Software Center en voer de volgende opdracht uit om de agent bij te werken. Vervang het pad naar het archief om te verwijzen naar het bestand dat u hebt gedownload:
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>[A] Een firewall configureren.
Maak de firewallregel voor de testpoort van Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp –permanent
SAP HANA-systeemreplicatie configureren
Volg de stappen in SAP HANA-systeemreplicatie instellen om SAP HANA-systeemreplicatie te configureren.
Clusterconfiguratie
In deze sectie worden de stappen beschreven die nodig zijn om een cluster naadloos te laten werken wanneer SAP HANA is geïnstalleerd op NFS-shares met behulp van Azure NetApp Files.
Een Pacemaker-cluster maken
Volg de stappen in Pacemaker instellen in Red Hat Enterprise Linux in Azure om een eenvoudig Pacemaker-cluster voor deze HANA-server te maken.
Belangrijk
Met het systeemgebaseerde SAP Startup Framework kunnen SAP HANA-exemplaren nu worden beheerd door een systeem. De minimaal vereiste Red Hat Enterprise Linux-versie (RHEL) is RHEL 8 voor SAP. Zoals beschreven in SAP Note 3189534, worden nieuwe installaties van SAP HANA SPS07 revisie 70 of hoger of updates van HANA-systemen naar HANA 2.0 SPS07 revisie 70 of hoger automatisch geregistreerd bij systemd.
Wanneer u HA-oplossingen gebruikt voor het beheren van SAP HANA-systeemreplicatie in combinatie met SAP HANA-exemplaren met systeemfunctionaliteit (raadpleeg SAP Note 3189534), zijn er aanvullende stappen nodig om ervoor te zorgen dat het HA-cluster het SAP-exemplaar zonder systeeminterferentie kan beheren. Voor het SAP HANA-systeem dat is geïntegreerd met systemd, moeten extra stappen die worden beschreven in Red Hat KBA 7029705 worden gevolgd op alle clusterknooppunten.
De Python-systeemreplicatiehook implementeren SAPHanaSR
Deze stap is een belangrijk onderdeel om de integratie met het cluster te optimaliseren en de detectie te verbeteren wanneer een clusterfailover nodig is. U wordt ten zeerste aangeraden de SAPHanaSR Python-hook te configureren. Volg de stappen in De Python-systeemreplicatiehook IMPLEMENTEREN SAPHanaSR.
Bestandssysteembronnen configureren
In dit voorbeeld heeft elk clusterknooppunt een eigen HANA NFS-bestandssystemen /hana/shared, /hana/dataen /hana/log.
[1] Plaats het cluster in de onderhoudsmodus.
sudo pcs property set maintenance-mode=true[1] Maak de bestandssysteembronnen voor de hanadb1-koppelingen .
sudo pcs resource create hana_data1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_log1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_shared1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs[2] Maak de bestandssysteembronnen voor de hanadb2-koppelingen .
sudo pcs resource create hana_data2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_log2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_shared2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfsHet
OCF_CHECK_LEVEL=20kenmerk wordt toegevoegd aan de bewakingsbewerking, zodat elke monitor een lees-/schrijftest uitvoert op het bestandssysteem. Zonder dit kenmerk controleert de bewakingsbewerking alleen of het bestandssysteem is gekoppeld. Dit kan een probleem zijn omdat wanneer de verbinding is verbroken, het bestandssysteem mogelijk gekoppeld blijft, ondanks dat het niet toegankelijk is.Het
on-fail=fencekenmerk wordt ook toegevoegd aan de bewakingsbewerking. Als met deze optie de monitorbewerking op een knooppunt mislukt, wordt dat knooppunt onmiddellijk omheining geplaatst. Zonder deze optie is het standaardgedrag om alle resources te stoppen die afhankelijk zijn van de mislukte resource, de mislukte resource opnieuw te starten en vervolgens alle resources te starten die afhankelijk zijn van de mislukte resource.Dit gedrag kan niet alleen lang duren wanneer een SAPHana-resource afhankelijk is van de mislukte resource, maar het kan ook helemaal mislukken. De SAPHana-resource kan niet stoppen als de NFS-server met de uitvoerbare HANA-bestanden niet toegankelijk is.
Met de voorgestelde time-outwaarden kunnen de clusterresources bestand zijn tegen protocolspecifieke onderbreking, gerelateerd aan NFSv4.1-leaseverlengingen. Zie NFS in De best practice van NetApp voor meer informatie. De time-outs in de voorgaande configuratie moeten mogelijk worden aangepast aan de specifieke SAP-installatie.
Voor workloads waarvoor een hogere doorvoer is vereist, kunt u overwegen de
nconnectkoppelingsoptie te gebruiken, zoals beschreven in NFS v4.1-volumes in Azure NetApp Files voor SAP HANA. Controleer ofnconnectdit wordt ondersteund door Azure NetApp Files in uw Linux-release.[1] Configureer locatiebeperkingen.
Configureer locatiebeperkingen om ervoor te zorgen dat de resources die unieke hanadb1-koppelingen beheren, nooit kunnen worden uitgevoerd op hanadb2 en omgekeerd.
sudo pcs constraint location hanadb1_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb2 sudo pcs constraint location hanadb2_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb1De
resource-discovery=neveroptie wordt ingesteld omdat de unieke koppelingen voor elk knooppunt hetzelfde koppelpunt delen. Gebruikt bijvoorbeeldhana_data1koppelpunt/hana/dataenhana_data2maakt ook gebruik van koppelpunt/hana/data. Het delen van hetzelfde koppelpunt kan een fout-positief veroorzaken voor een testbewerking, wanneer de resourcestatus wordt gecontroleerd bij het opstarten van het cluster en het op zijn beurt onnodig herstelgedrag kan veroorzaken. Om dit scenario te voorkomen, stelt u hetresource-discovery=neverin.[1] Kenmerkbronnen configureren.
Kenmerkbronnen configureren. Deze kenmerken worden ingesteld op true als alle NFS-koppelingen van een knooppunt (
/hana/data,/hana/logen/hana/data) zijn gekoppeld. Anders worden ze ingesteld op false.sudo pcs resource create hana_nfs1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs1_active sudo pcs resource create hana_nfs2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs2_active[1] Configureer locatiebeperkingen.
Configureer locatiebeperkingen om ervoor te zorgen dat de kenmerkresource van hanadb1 nooit wordt uitgevoerd op hanadb2 en omgekeerd.
sudo pcs constraint location hana_nfs1_active avoids hanadb2 sudo pcs constraint location hana_nfs2_active avoids hanadb1[1] Bestelbeperkingen maken.
Configureer bestelbeperkingen zodat de kenmerkbronnen van een knooppunt pas worden gestart nadat alle NFS-koppelingen van het knooppunt zijn gekoppeld.
sudo pcs constraint order hanadb1_nfs then hana_nfs1_active sudo pcs constraint order hanadb2_nfs then hana_nfs2_activeTip
Als uw configuratie bestandssystemen bevat, buiten de groep
hanadb1_nfsofhanadb2_nfs, neemt u desequential=falseoptie op, zodat er geen volgordeafhankelijkheden zijn tussen de bestandssystemen. Alle bestandssystemen moeten eerderhana_nfs1_activeworden gestart, maar ze hoeven niet te beginnen in volgorde ten opzichte van elkaar. Zie voor meer informatie Hoe kan ik SAP HANA-systeemreplicatie configureren in scale-up in een Pacemaker-cluster wanneer de HANA-bestandssystemen zich op NFS-shares bevinden
SAP HANA-clusterbronnen configureren
Volg de stappen in SAP HANA-clusterbronnen maken om de SAP HANA-resources in het cluster te maken. Nadat SAP HANA-resources zijn gemaakt, moet u een locatieregelbeperking maken tussen SAP HANA-resources en bestandssystemen (NFS-koppelingen).
[1] Configureer beperkingen tussen de SAP HANA-resources en de NFS-koppelingen.
Locatieregelbeperkingen worden ingesteld, zodat de SAP HANA-resources alleen op een knooppunt kunnen worden uitgevoerd als alle NFS-koppelingen van het knooppunt zijn gekoppeld.
sudo pcs constraint location SAPHanaTopology_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueOp RHEL 7.x:
sudo pcs constraint location SAPHana_HN1_03-master rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueOp RHEL 8.x/9.x:
sudo pcs constraint location SAPHana_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne true[1] Configureer bestelbeperkingen zodat de SAP-resources op een knooppunt voor een stop stoppen voor een van de NFS-koppelingen.
pcs constraint order stop SAPHanaTopology_HN1_03-clone then stop hanadb1_nfs pcs constraint order stop SAPHanaTopology_HN1_03-clone then stop hanadb2_nfsOp RHEL 7.x:
pcs constraint order stop SAPHana_HN1_03-master then stop hanadb1_nfs pcs constraint order stop SAPHana_HN1_03-master then stop hanadb2_nfsOp RHEL 8.x/9.x:
pcs constraint order stop SAPHana_HN1_03-clone then stop hanadb1_nfs pcs constraint order stop SAPHana_HN1_03-clone then stop hanadb2_nfsHaal het cluster uit de onderhoudsmodus.
sudo pcs property set maintenance-mode=falseControleer de status van het cluster en alle resources.
Notitie
Dit artikel bevat verwijzingen naar een term die microsoft niet meer gebruikt. Zodra de term uit de software wordt verwijderd, verwijderen we deze uit dit artikel.
sudo pcs statusVoorbeelduitvoer:
Online: [ hanadb1 hanadb2 ] Full list of resources: rsc_hdb_azr_agt(stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem):Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1
HANA-systeemreplicatie met actief/gelezen-ingeschakeld configureren in Pacemaker-cluster
Vanaf SAP HANA 2.0 SPS 01 biedt SAP actieve/leesfuncties voor SAP HANA-systeemreplicatie, waarbij de secundaire systemen van SAP HANA-systeemreplicatie actief kunnen worden gebruikt voor leesintensieve werkbelastingen. Ter ondersteuning van een dergelijke installatie in een cluster is een tweede virtueel IP-adres vereist, waardoor clients toegang hebben tot de secundaire SAP HANA-database met leestoegang.
Om ervoor te zorgen dat de secundaire replicatiesite nog steeds toegankelijk is nadat een overname is uitgevoerd, moet het cluster het virtuele IP-adres verplaatsen met de secundaire van de SAPHana-resource.
De extra configuratie, die vereist is voor het beheren van HANA active/read-enabled systeemreplicatie in een Red Hat HA-cluster met een tweede virtueel IP-adres, wordt beschreven in HANA Active/Read-Enabled System Replication configureren in Pacemaker-cluster.
Voordat u verdergaat, moet u ervoor zorgen dat u het Red Hat High Availability-cluster voor het beheren van de SAP HANA-database volledig hebt geconfigureerd, zoals beschreven in de voorgaande secties van de documentatie.
De clusterinstallatie testen
In deze sectie wordt beschreven hoe u uw installatie kunt testen.
Voordat u een test start, moet u ervoor zorgen dat Pacemaker geen mislukte actie heeft (via pcs-status), er geen onverwachte locatiebeperkingen zijn (bijvoorbeeld resten van een migratietest) en dat HANA-systeemreplicatie de synchronisatiestatus heeft, bijvoorbeeld met
systemReplicationStatus:sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Controleer de clusterconfiguratie voor een foutscenario wanneer een knooppunt geen toegang meer heeft tot de NFS-share (
/hana/shared).De SAP HANA-resourceagents zijn afhankelijk van binaire bestanden die zijn opgeslagen
/hana/sharedom bewerkingen uit te voeren tijdens een failover./hana/sharedBestandssysteem wordt in het gepresenteerde scenario gekoppeld aan NFS.Het is moeilijk om een fout te simuleren waarbij een van de servers geen toegang meer heeft tot de NFS-share. Als test kunt u het bestandssysteem opnieuw koppelen als alleen-lezen. Met deze methode wordt gevalideerd dat het cluster een failover kan uitvoeren als de toegang tot
/hana/sharedhet actieve knooppunt verloren gaat.Verwacht resultaat: Bij het maken
/hana/sharedals een alleen-lezen bestandssysteem mislukt hetOCF_CHECK_LEVELkenmerk van de resourcehana_shared1, waarmee lees-/schrijfbewerkingen op bestandssystemen worden uitgevoerd. Het kan niets schrijven op het bestandssysteem en voert failover van HANA-resources uit. Hetzelfde resultaat wordt verwacht wanneer uw HANA-knooppunt geen toegang meer heeft tot de NFS-shares.Resourcestatus voordat u de test start:
sudo pcs statusVoorbeelduitvoer:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem): Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1U kunt met deze opdracht in de modus Alleen-lezen op het actieve clusterknooppunt plaatsen
/hana/shared:sudo mount -o ro 10.32.2.4:/hanadb1-shared-mnt00001 /hana/sharedhanadbwordt opnieuw opgestart of uitgeschakeld op basis van de actie die is ingesteld opstonith(pcs property show stonith-action). Zodra de server (hanadb1) is uitgeschakeld, wordt de HANA-resource verplaatst naarhanadb2. U kunt de status van het cluster controleren vanuithanadb2.sudo pcs statusVoorbeelduitvoer:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb2 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Stopped hana_log1 (ocf::heartbeat:Filesystem): Stopped hana_shared1 (ocf::heartbeat:Filesystem): Stopped Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Stopped hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb2 ] Stopped: [ hanadb1 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb2 ] Stopped: [ hanadb1 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb2 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb2We raden u aan om de configuratie van het SAP HANA-cluster grondig te testen door ook de tests uit te voeren die worden beschreven in SAP HANA-systeemreplicatie instellen op RHEL.