Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel wordt beschreven hoe u een eenvoudig Pacemaker-cluster configureert op Red Hat Enterprise Server (RHEL). De instructies hebben betrekking op RHEL 7, RHEL 8 en RHEL 9.
Voorwaarden
Lees eerst de volgende SAP-notities en artikelen:
RHEL High Availability (HA) documentatie
- Clusters met hoge beschikbaarheid configureren en beheren.
- Ondersteuningsbeleid voor RHEL-clusters met hoge beschikbaarheid: sbd en fence_sbd.
- Ondersteuningsbeleid voor RHEL-clusters met hoge beschikbaarheid- fence_azure_arm.
- Bekende beperkingen van software-geëmuleerde waakhond.
- Het verkennen van de componenten van RHEL High Availability - sbd en fence_sbd
- Ontwerprichtlijnen voor RHEL-clusters met hoge beschikbaarheid- overwegingen.
- Overwegingen bij de overstap naar RHEL 8 - Hoge beschikbaarheid en clusters
Azure-specifieke RHEL-documentatie
RHEL-documentatie voor SAP-aanbiedingen
- Ondersteuningsbeleid voor RHEL-clusters met hoge beschikbaarheid : beheer van SAP S/4HANA in een cluster.
- SAP S/4HANA ASCS/ERS configureren met standalone Enqueue Server 2 (ENSA2) in Pacemaker.
- Sap HANA-systeemreplicatie configureren in Pacemaker-cluster.
- Red Hat Enterprise Linux HA-oplossing voor SAP HANA Scale-Out en systeemreplicatie.
Overzicht
Belangrijk
Pacemaker-clusters die meerdere virtuele netwerken (VNets)/subnetten omvatten, vallen niet onder standaardondersteuningsbeleid.
Er zijn twee opties beschikbaar in Azure voor het configureren van de fencing in een pacemakercluster voor RHEL: Azure Fence Agent, waarmee een mislukt knooppunt opnieuw wordt opgestart via de Azure-API's, of u kunt het SBD-apparaat gebruiken.
Belangrijk
In Azure maakt een RHEL-cluster met hoge beschikbaarheid gebruik van op opslag gebaseerde fencing (fence_sbd), dat software-geëmuleerde watchdog gebruikt. Het is belangrijk om de bekende beperkingen van Software-Emulated Watchdog en de ondersteuningsbeleid voor RHEL High Availability Clusters - sbd en fence_sbd te controleren bij het selecteren van SBD als de fencing-methode.
Een SBD-apparaat gebruiken
Notitie
Het hekmechanisme met SBD wordt ondersteund op RHEL 8.8 en hoger en RHEL 9.0 en hoger.
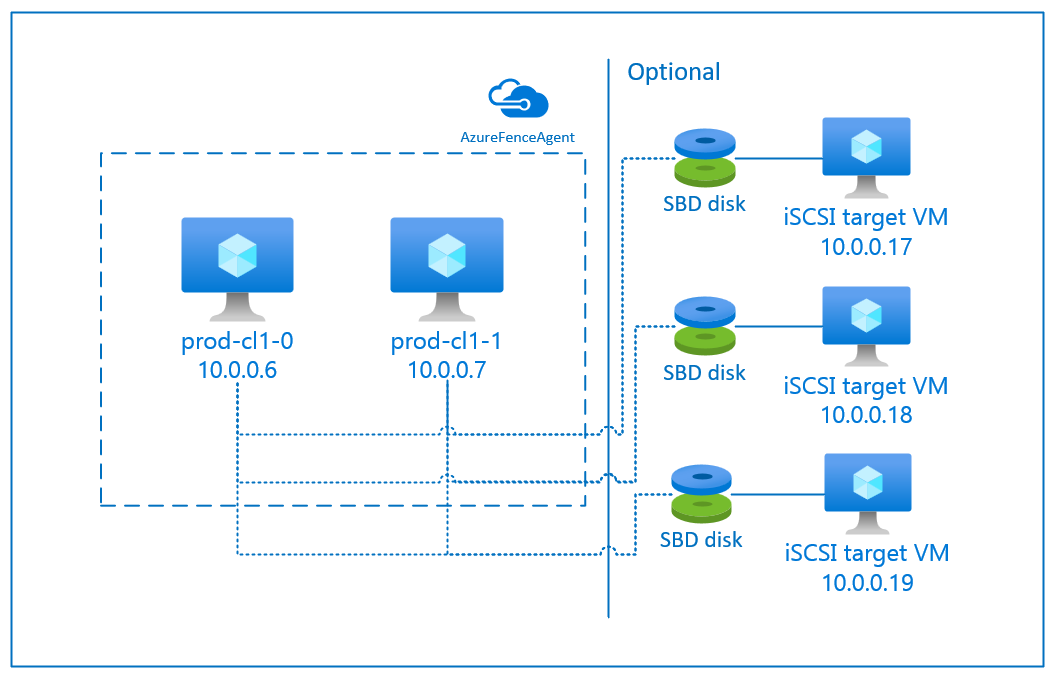
U kunt het SBD-apparaat configureren met behulp van een van de volgende twee opties:
SBD met iSCSI-doelserver
Voor het SBD-apparaat is ten minste één extra virtuele machine (VM) vereist die fungeert als een iSCSI-doelserver (Internet Small Compute System Interface) en een SBD-apparaat biedt. Deze iSCSI-doelservers kunnen echter worden gedeeld met andere pacemakerclusters. Het voordeel van het gebruik van een SBD-apparaat is dat als u al on-premises SBD-apparaten gebruikt, er geen wijzigingen nodig zijn in de manier waarop u het pacemaker-cluster gebruikt.
U kunt maximaal drie SBD-apparaten voor een pacemakercluster gebruiken om een SBD-apparaat niet meer beschikbaar te maken (bijvoorbeeld tijdens het patchen van het besturingssysteem van de iSCSI-doelserver). Als u meer dan één SBD-apparaat per pacemaker wilt gebruiken, moet u meerdere iSCSI-doelservers implementeren en één SBD verbinden vanaf elke iSCSI-doelserver. U wordt aangeraden een of drie SBD-apparaten te gebruiken. Pacemaker kan een clusterknooppunt niet automatisch omheinen als er slechts twee SBD-apparaten zijn geconfigureerd en één ervan niet beschikbaar is. Als u wilt kunnen omheinen wanneer één iSCSI-doelserver offline is, moet u drie SBD-apparaten en dus drie iSCSI-doelservers gebruiken. Dat is de meest flexibele configuratie wanneer u SBD's gebruikt.
Belangrijk
Wanneer u van plan bent om Linux pacemaker-clusterknooppunten en SBD-apparaten te implementeren en te configureren, staat u niet toe dat de routering tussen uw virtuele machines en de VM's die als host fungeren voor de SBD-apparaten, worden doorgegeven door andere apparaten, zoals een virtueel netwerkapparaat (NVA).
Onderhoudsgebeurtenissen en andere problemen met de NVA kunnen een negatieve invloed hebben op de stabiliteit en betrouwbaarheid van de algehele clusterconfiguratie. Zie door de gebruiker gedefinieerde routeringsregels voor meer informatie.
SBD met gedeelde Azure-schijf
Als u een SBD-apparaat wilt configureren, moet u ten minste één gedeelde Azure-schijf koppelen aan alle virtuele machines die deel uitmaken van het pacemaker-cluster. Het voordeel van een SBD-apparaat met behulp van een gedeelde Azure-schijf is dat u geen extra virtuele machines hoeft te implementeren en configureren.
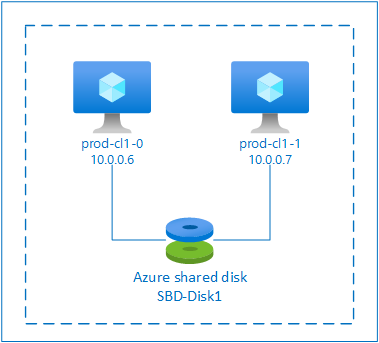
Hier volgen enkele belangrijke overwegingen over SBD-apparaten bij het configureren van een gedeelde Azure-schijf:
- Een gedeelde Azure-schijf met Premium SSD wordt ondersteund als een SBD-apparaat.
- SBD-apparaten die gebruikmaken van een gedeelde Azure-schijf worden ondersteund op RHEL 8.8 en hoger.
- SBD-apparaten die gebruikmaken van een Azure Premium Share-schijf worden ondersteund op lokaal redundante opslag (LRS) en zone-redundante opslag (ZRS).
- Afhankelijk van het type implementatie, kiest u de juiste redundante opslag voor een gedeelde Azure-schijf als uw SBD-apparaat.
- Een SBD-apparaat dat gebruikmaakt van LRS voor een Azure Premium gedeelde schijf (skuName - Premium_LRS) wordt alleen ondersteund bij regionale uitrol, zoals bij een beschikbaarheidsset.
- Een SBD-apparaat dat gebruikmaakt van ZRS voor een gedeelde Azure Premium-schijf (skuName - Premium_ZRS) wordt aanbevolen met zonegebonden implementatie, zoals beschikbaarheidszone of schaalset met FD=1.
- Een ZRS voor beheerde schijf is momenteel beschikbaar in de regio's die worden vermeld in het document voor regionale beschikbaarheid .
- De gedeelde Azure-schijf die u voor SBD-apparaten gebruikt, hoeft niet groot te zijn. De waarde maxShares bepaalt hoeveel clusterknooppunten de gedeelde schijf kunnen gebruiken. U kunt bijvoorbeeld P1- of P2-schijfgroottes gebruiken voor uw SBD-apparaat in een tweeknooppuntencluster, zoals SAP ASCS/ERS of SAP HANA uitbreiden.
- Voor uitschalen van HANA met HANA-systeemreplicatie (HSR) en pacemaker kunt u een gedeelde Azure-schijf gebruiken voor SBD-apparaten in clusters met maximaal vijf knooppunten per replicatiesite vanwege de huidige limiet van maxShares.
- Het is niet raadzaam om een SBD-apparaat met een gedeelde Azure-schijf te koppelen aan pacemakerclusters.
- Als u meerdere gedeelde Azure-schijf-SBD-apparaten gebruikt, controleert u de limiet voor een maximum aantal gegevensschijven dat kan worden gekoppeld aan een virtuele machine.
- Raadpleeg de sectie Beperkingen van de documentatie over gedeelde Azure-schijven voor meer informatie over beperkingen voor gedeelde Azure-schijven.
Een Azure Fence-agent gebruiken
U kunt fencing instellen met behulp van een Azure Fence-agent. Voor de Azure Fence-agent zijn beheerde identiteiten vereist voor de cluster-VM's of een service-principal of een beheerde systeemidentiteit (MSI) die mislukte knooppunten via Azure-API's opnieuw kan opstarten. Voor de Azure Fence-agent is de implementatie van extra virtuele machines niet vereist.
SBD met een iSCSI-doelserver
Als u een SBD-apparaat wilt gebruiken dat gebruikmaakt van een iSCSI-doelserver voor fencing, volgt u de instructies in de volgende secties.
Installeer de iSCSI-doelserver
U moet eerst de virtuele iSCSI-doelmachines maken. U kunt iSCSI-taakservers delen met meerdere pacemakerclusters.
Implementeer virtuele machines die worden uitgevoerd op de ondersteunde RHEL-besturingssysteemversie en maak er verbinding mee via SSH. De VM's hoeven niet van grote grootte te zijn. VM-grootten zoals Standard_E2s_v3 of Standard_D2s_v3 zijn voldoende. Zorg ervoor dat u Premium-opslag gebruikt voor de besturingssysteemschijf.
Het is niet nodig om RHEL te gebruiken voor SAP met HA en Update Services, of RHEL voor SAP Apps OS-installatiekopieën voor de iSCSI-doelserver. In plaats daarvan kan een standaard RHEL-OS-afbeelding worden gebruikt. Houd er echter rekening mee dat de levenscyclus van de ondersteuning varieert tussen verschillende productversies van het besturingssysteem.
Voer de volgende opdrachten uit op alle virtuele iSCSI-doelmachines.
RHEL bijwerken.
sudo yum -y updateNotitie
Mogelijk moet u het knooppunt opnieuw opstarten nadat u het besturingssysteem hebt geüpgraded of bijgewerkt.
Installeer het iSCSI-doelpakket.
sudo yum install targetcliStart en configureer het doel om te beginnen bij het opstarten.
sudo systemctl start target sudo systemctl enable target3260Poort openen in de firewallsudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
Een iSCSI-apparaat maken op de iSCSI-doelserver
Als u de iSCSI-schijven voor uw SAP-systeemclusters wilt maken, voert u de volgende opdrachten uit op elke virtuele iSCSI-doelmachine. Het voorbeeld illustreert het maken van SBD-apparaten voor verschillende clusters, waarmee het gebruik van één iSCSI-doelserver voor meerdere clusters wordt gedemonstreerd. Het SBD-apparaat is geconfigureerd op de besturingssysteemschijf, dus zorg ervoor dat er voldoende ruimte is.
- ascsnw1: vertegenwoordigt het ASCS/ERS-cluster van NW1.
- dbhn1: Vertegenwoordigt het databasecluster van HN1.
- sap-cl1 en sap-cl2: Hostnamen van de NW1 ASCS/ERS-clusterknooppunten.
- hn1-db-0 en hn1-db-1: Hostnamen van de databaseclusterknooppunten.
Wijzig in de volgende instructies de opdracht met uw specifieke hostnamen en SID's, indien nodig.
Maak de hoofdmap voor alle SBD-apparaten.
sudo mkdir /sbdMaak het SBD-apparaat voor de ASCS/ERS-servers van het systeem NW1.
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2Maak het SBD-apparaat voor het databasecluster van het systeem HN1.
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1Sla de targetcli-configuratie op.
sudo targetcli saveconfigControleer of alles juist is ingesteld
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
Het SBD-apparaat van de iSCSI-doelserver instellen
[A]: van toepassing op alle knooppunten. [1]: Alleen van toepassing op knooppunt 1. [2]: Alleen van toepassing op knooppunt 2.
Maak op de clusterknooppunten verbinding met en ontdek het iSCSI-apparaat dat in de vorige sectie is gemaakt. Voer de volgende opdrachten uit op de knooppunten van het nieuwe cluster dat u wilt maken.
[A] ISCSI-initiatorhulpmiddelen installeren of bijwerken op alle clusterknooppunten.
sudo yum install -y iscsi-initiator-utils[A] Installeer cluster- en SBD-pakketten op alle clusterknooppunten.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Schakel iSCSI-service in.
sudo systemctl enable iscsid iscsi[1] Wijzig de naam van de initiator op het eerste knooppunt van het cluster.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] Wijzig de naam van de initiator op het tweede knooppunt van het cluster.
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] Start de iSCSI-service opnieuw op om de wijzigingen toe te passen.
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] Verbind de iSCSI-apparaten. In het volgende voorbeeld is 10.0.0.17 het IP-adres van de iSCSI-doelserver en is 3260 de standaardpoort. De doelnaam
iqn.2006-04.ascsnw1.local:ascsnw1wordt vermeld wanneer u de eerste opdrachtiscsiadm -m discoveryuitvoert.sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Als u meerdere SBD-apparaten gebruikt, maakt u ook verbinding met de tweede iSCSI-doelserver.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Als u meerdere SBD-apparaten gebruikt, maakt u ook verbinding met de derde iSCSI-doelserver.
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] Zorg ervoor dat de iSCSI-apparaten beschikbaar zijn en noteer de apparaatnaam. In het volgende voorbeeld worden drie iSCSI-apparaten gedetecteerd door het knooppunt te verbinden met drie iSCSI-doelservers.
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] Haal de id's van de iSCSI-apparaten op.
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgDe opdracht bevat drie apparaat-id's voor elk SBD-apparaat. U wordt aangeraden de id te gebruiken die begint met scsi-3. In het voorgaande voorbeeld zijn de id's:
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] Maak het SBD-apparaat.
Gebruik de apparaat-id van de iSCSI-apparaten om de nieuwe SBD-apparaten op het eerste clusterknooppunt te maken.
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 createMaak ook de tweede en derde SBD-apparaten als u meer dan één wilt gebruiken.
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] De SBD-configuratie aanpassen
Open het SBD-configuratiebestand.
sudo vi /etc/sysconfig/sbdWijzig de eigenschap van het SBD-apparaat, schakel de pacemaker-integratie in en wijzig de startmodus van SBD.
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Voer de volgende opdracht uit om de
softdogmodule te laden.modprobe softdog[A] Voer de volgende opdracht uit om ervoor te zorgen dat
softdoghet knooppunt automatisch wordt geladen nadat het knooppunt opnieuw is opgestart.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] De time-outwaarde van de SBD-service is standaard ingesteld op 90 s. Als de
SBD_DELAY_STARTwaarde echter is ingesteldyesop, vertraagt de SBD-service de start tot na demsgwaittime-out. Daarom moet de time-outwaarde van de SBD-service demsgwaittime-out overschrijden wanneerSBD_DELAY_STARTdeze is ingeschakeld.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
SBD met een gedeelde Azure-schijf
Deze sectie is alleen van toepassing als u een SBD-apparaat wilt gebruiken met een gedeelde Azure-schijf.
Gedeelde Azure-schijf configureren met PowerShell
Voer de volgende instructies uit om een gedeelde Azure-schijf te maken en te koppelen met PowerShell. Als u resources wilt implementeren met behulp van de Azure CLI of Azure Portal, kunt u ook verwijzen naar Een ZRS-schijf implementeren.
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Een gedeeld Azure-schijf-SBD-apparaat instellen
[A] Installeer cluster- en SBD-pakketten op alle clusterknooppunten.
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] Controleer of de gekoppelde schijf beschikbaar is.
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] Haal de apparaat-id van de gekoppelde gedeelde schijf op.
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaDe apparaat-id van de opdrachtlijst voor de gekoppelde gedeelde schijf. U wordt aangeraden de id te gebruiken die begint met scsi-3. In dit voorbeeld is de id /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107.
[1] Het SBD-apparaat maken
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] De SBD-configuratie aanpassen
Open het SBD-configuratiebestand.
sudo vi /etc/sysconfig/sbdWijzig de eigenschap van het SBD-apparaat, schakel de pacemaker-integratie in en wijzig de startmodus van SBD
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] Voer de volgende opdracht uit om de
softdogmodule te laden.modprobe softdog[A] Voer de volgende opdracht uit om ervoor te zorgen dat
softdoghet knooppunt automatisch wordt geladen nadat het knooppunt opnieuw is opgestart.echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] De time-outwaarde van de SBD-service is standaard ingesteld op 90 seconden. Als de
SBD_DELAY_STARTwaarde echter is ingesteldyesop, vertraagt de SBD-service de start tot na demsgwaittime-out. Daarom moet de time-outwaarde van de SBD-service demsgwaittime-out overschrijden wanneerSBD_DELAY_STARTdeze is ingeschakeld.sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
Configuratie van Azure Fence-agent
Het fencing-apparaat gebruikt een beheerde identiteit voor Azure-resources of een service-principal voor autorisatie bij Azure. Afhankelijk van de methode voor identiteitsbeheer volgt u de juiste procedures -
Identiteitsbeheer configureren
Gebruik een beheerde identiteit of een service-principal.
Als u een beheerde identiteit (MSI) wilt maken, maakt u een door het systeem toegewezen beheerde identiteit voor elke VIRTUELE machine in het cluster. Als er al een door het systeem toegewezen beheerde identiteit bestaat, wordt deze gebruikt. Gebruik momenteel geen door de gebruiker toegewezen beheerde identiteiten met Pacemaker. Een omheiningsapparaat, op basis van beheerde identiteit, wordt ondersteund op RHEL 7.9 en RHEL 8.x/RHEL 9.x.
Een aangepaste rol maken voor de fence agent
Zowel de beheerde identiteit als de service-principal hebben standaard geen machtigingen voor toegang tot uw Azure-resources. U moet de beheerde identiteit of service-principal machtigingen geven om alle VM's van het cluster te starten en stoppen (uit te schakelen). Als u de aangepaste rol nog niet hebt gemaakt, kunt u deze maken met behulp van PowerShell of de Azure CLI.
Gebruik de volgende inhoud voor het invoerbestand. U moet de inhoud aanpassen aan uw abonnementen, dat wil gezegd, vervangen
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxenyyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyydoor de id's van uw abonnement. Als u slechts één abonnement hebt, verwijdert u de tweede vermelding inAssignableScopes.{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }De aangepaste rol toewijzen
Gebruik een beheerde identiteit of een service-principal.
Wijs de aangepaste rol
Linux Fence Agent Roletoe die in de laatste sectie is gemaakt aan elke beheerde identiteit van de cluster-VM's. Aan elke door het VM-systeem toegekende beheerde identiteit moet de rol worden toegewezen voor de resource van elke cluster-VM. Zie Een beheerde identiteit toegang tot een resource toewijzen met behulp van Azure Portal voor meer informatie. Controleer of de roltoewijzing van de beheerde identiteit van elke VIRTUELE machine alle cluster-VM's bevat.Belangrijk
Houd er rekening mee dat het toewijzen en verwijderen van autorisatie met beheerde identiteiten kan worden uitgesteld totdat deze effectief is.
Clusterinstallatie
Verschillen in de opdrachten of de configuratie tussen RHEL 7 en RHEL 8/RHEL 9 worden gemarkeerd in het document.
[A] Installeer de RHEL HA-invoegtoepassing.
sudo yum install -y pcs pacemaker nmap-ncat[A] Installeer op RHEL 9.x de resourceagents voor cloudimplementatie.
sudo yum install -y resource-agents-cloud[A] Installeer het fence-agents-pakket als u een fencing-apparaat gebruikt op basis van de Azure Fence-agent.
sudo yum install -y fence-agents-azure-armBelangrijk
We raden de volgende versies van de Azure Fence-agent (of hoger) aan voor klanten die beheerde identiteiten willen gebruiken voor Azure-resources in plaats van service-principalnamen voor de omheiningsagent:
- RHEL 8.4: fence-agents-4.2.1-54.el8.
- RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9: hek-agents-4.2.1-41.el7_9.4.
Belangrijk
Op RHEL 9 raden we de volgende pakketversies (of hoger) aan om problemen met de Azure Fence-agent te voorkomen:
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Controleer de versie van de Azure Fence-agent. Werk deze indien nodig bij naar de minimaal vereiste versie of hoger.
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-armBelangrijk
Als u de Azure Fence-agent moet bijwerken en als u een aangepaste rol gebruikt, moet u de aangepaste rol bijwerken om de actie powerOff op te nemen. Zie Een aangepaste rol maken voor de omheiningsagent voor meer informatie.
[A] Configureer hostnaam-omzetting.
U kunt een DNS-server gebruiken of het
/etc/hostsbestand op alle knooppunten wijzigen. In dit voorbeeld ziet u hoe u het/etc/hostsbestand gebruikt. Vervang het IP-adres en de hostnaam in de volgende opdrachten.Belangrijk
Als u hostnamen gebruikt in de clusterconfiguratie, is het essentieel dat de hostnaamomzetting betrouwbaar is. De clustercommunicatie mislukt als de namen niet beschikbaar zijn, wat kan leiden tot vertragingen in de clusterfailover.
Het voordeel van het gebruik van
/etc/hostsis dat uw cluster onafhankelijk wordt van DNS, wat ook een single point of failure kan zijn.sudo vi /etc/hostsVoeg de volgende regels in op
/etc/hosts. Wijzig het IP-adres en de hostnaam zodat deze overeenkomen met uw omgeving.# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] Wijzig het
haclusterwachtwoord in hetzelfde wachtwoord.sudo passwd hacluster[A] Voeg firewallregels toe voor Pacemaker.
Voeg de volgende firewallregels toe aan alle clustercommunicatie tussen de clusterknooppunten.
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] Schakel basiscluster diensten in.
Voer de volgende opdrachten uit om de Pacemaker-service in te schakelen en te starten.
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Maak een Pacemaker-cluster.
Voer de volgende opdrachten uit om de knooppunten te verifiëren en het cluster te maken. Stel het token in op 30000 om onderhoud met geheugenbehoud mogelijk te maken. Zie dit artikel voor Linux voor meer informatie.
Als u een cluster bouwt op RHEL 7.x, gebruikt u de volgende opdrachten:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allAls u een cluster bouwt op RHEL 8.x/RHEL 9.x, gebruikt u de volgende opdrachten:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --allControleer de clusterstatus door de volgende opdracht uit te voeren:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] Stel verwachte stemmen in.
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2Aanbeveling
Als u een cluster met meerdere knooppunten bouwt, dus een cluster met meer dan twee knooppunten, stelt u de stemmen niet in op 2.
[1] Gelijktijdige omheiningsacties toestaan.
sudo pcs property set concurrent-fencing=true
Een fencingapparaat voor het Pacemaker-cluster maken
Aanbeveling
- Als u omheiningsraces binnen een pacemakercluster met twee knooppunten wilt voorkomen, kunt u de
priority-fencing-delayclustereigenschap configureren. Deze eigenschap introduceert extra vertraging bij het afschermen van een knooppunt met een hogere totale resourceprioriteit wanneer er een split-brain-scenario optreedt. Zie Kan Pacemaker het clusterknooppunt omheinen met de minste actieve resources? voor meer informatie. - De eigenschap
priority-fencing-delayis van toepassing op Pacemaker versie 2.0.4-6.el8 of hoger en op een cluster met twee knooppunten. Als u depriority-fencing-delayclustereigenschap configureert, hoeft u depcmk_delay_maxeigenschap niet in te stellen. Maar als de Pacemaker-versie kleiner is dan 2.0.4-6.el8, moet u depcmk_delay_maxeigenschap instellen. - Zie de respectieve SAP ASCS/ERS- en SAP HANA scale-up HA-documenten voor instructies over het instellen van de
priority-fencing-delayclustereigenschap.
Volg op basis van het geselecteerde fencingmechanisme slechts één sectie voor relevante instructies: SBD als fencing-apparaat of Azure Fence-agent als fencing-apparaat.
SBD als afschermingsapparaat
[A] SBD-service inschakelen
sudo systemctl enable sbd[1] Voer de volgende opdrachten uit voor het SBD-apparaat dat is geconfigureerd met iSCSI-doelservers of een gedeelde Azure-schijf.
sudo pcs property set stonith-timeout=144 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] Start het cluster opnieuw op
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allNotitie
Als er een volgende fout optreedt tijdens het starten van het pacemaker-cluster, kunt u het bericht negeren. U kunt het cluster ook starten met behulp van de opdracht
pcs cluster start --all --request-timeout 140.Fout: kan niet alle knooppunten knooppunt1/knooppunt2 starten: Kan geen verbinding maken met node1/node2, controleer of pcsd daar wordt uitgevoerd of probeer een hogere time-out in te stellen met
--request-timeoutde optie (Er is een time-out opgetreden na 60000 milliseconden met 0 bytes ontvangen)
Azure Fence-agent als fencing-apparaat
[1] Nadat u rollen hebt toegewezen aan beide clusterknooppunten, kunt u de fencingapparaten in het cluster configureren.
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] Voer de juiste opdracht uit, afhankelijk van of u een beheerde identiteit of een service-principal voor de Azure Fence-agent gebruikt.
Notitie
Wanneer u Azure Government Cloud gebruikt, moet u de optie opgeven
cloud=bij het configureren van de omheiningsagent. Bijvoorbeeldcloud=usgovvoor de Azure US Government-cloud. Zie Ondersteuningsbeleid voor RHEL-clusters met hoge beschikbaarheid - Microsoft Azure Virtual Machines als clusterleden voor meer informatie over RedHat-ondersteuning in de Azure Government-cloud.Aanbeveling
De optie
pcmk_host_mapis alleen vereist in de opdracht als de RHEL-hostnamen en de azure-VM-namen niet identiek zijn. Geef de toewijzing op in het formaat hostnaam:vm-name. Zie voor meer informatie welke indeling moet ik gebruiken om knooppunttoewijzingen op te geven voor fencing-apparaten in pcmk_host_map?.Gebruik voor RHEL 7.x de volgende opdracht om het hekapparaat te configureren:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600Voor RHEL 8.x/9.x gebruikt u de volgende opdracht om het hekapparaat te configureren:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600
Als u een fencing-apparaat gebruikt op basis van de configuratie van de service-principal, leest u Change from SPN to MSI for Pacemaker clusters by using Azure fencing en leert u hoe u kunt overzetten naar een managed identity-configuratie.
De bewakings- en afschermingsbewerkingen worden gedeserialiseerd. Als er dus een langduriger actieve bewakingsbewerking en een gelijktijdige fencing-gebeurtenis is, is er geen vertraging voor de cluster-overgang omdat de bewakingsbewerking al wordt uitgevoerd.
Aanbeveling
De Azure Fence-agent vereist uitgaande connectiviteit met openbare eindpunten. Zie Openbare eindpuntconnectiviteit voor VM's met behulp van standaard-ILB voor meer informatie en mogelijke oplossingen.
Pacemaker configureren voor geplande Azure-gebeurtenissen
Azure biedt geplande gebeurtenissen. Geplande gebeurtenissen worden aangeboden via de metagegevensservice en bieden de toepassing de tijd om deze gebeurtenissen voor te bereiden.
Resource agent azure-events-az monitort voor geplande Azure-gebeurtenissen. Als er gebeurtenissen worden gedetecteerd en de resourceagent bepaalt dat er een ander clusterknooppunt beschikbaar is, wordt een statuskenmerk #health-azure-1000000op knooppuntniveau ingesteld op .
Wanneer dit speciale clusterstatuskenmerk is ingesteld voor een knooppunt, wordt het knooppunt als beschadigd beschouwd door het cluster en worden alle resources verwijderd van het betrokken knooppunt. De locatiebeperking zorgt ervoor dat resources waarvan de naam met 'health-' begint worden uitgesloten, omdat de agent moet werken in deze ongezonde toestand. Zodra het getroffen clusterknooppunt geen clusterbronnen meer uitvoert, kan de geplande gebeurtenis zijn actie uitvoeren, zoals opnieuw opstarten, zonder risico voor de actieve resources.
Het #heath-azure kenmerk wordt bij het opstarten van de pacemaker weer ingesteld op 0 zodra alle gebeurtenissen zijn verwerkt, waardoor het knooppunt weer als in orde wordt gemarkeerd.
[A] Zorg ervoor dat het pakket voor de
azure-events-azagent al is geïnstalleerd en up-to-date is.RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloudMinimale versievereisten:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 en hoger:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Configureer de middelen in Pacemaker.
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Stel de strategie en beperking voor het gezondheidsknooppunt van het Pacemaker-cluster in.
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'Belangrijk
Definieer geen andere resources in het cluster die beginnen met
health-, behalve de resources die in de volgende stappen worden beschreven.[1] Stel de initiële waarde van de clusterkenmerken in. Uitvoeren voor elk clusterknooppunt en voor uitschaalomgevingen, inclusief de majority-maker VM.
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Configureer de middelen in Pacemaker. Zorg ervoor dat de resources beginnen met
health-azure.sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ meta failure-timeout=120s \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=trueHaal het Pacemaker-cluster uit de onderhoudsmodus.
sudo pcs property set maintenance-mode=falseWis eventuele fouten tijdens het inschakelingsproces en controleer of de
health-azure-eventsresources succesvol zijn gestart op alle clusterknooppunten.sudo pcs resource cleanupHet uitvoeren van de eerste query voor geplande gebeurtenissen kan maximaal twee minuten duren. Pacemakertests met geplande taken kunnen gebruikmaken van acties zoals herstarten of opnieuw implementeren voor de cluster-VM's. Zie Geplande gebeurtenissen voor meer informatie.
Optionele configuratie voor fencing
Aanbeveling
Deze sectie is alleen van toepassing als u het speciale afschermingsapparaat fence_kdumpwilt configureren.
Als u diagnostische gegevens binnen de VIRTUELE machine moet verzamelen, kan het handig zijn om een ander fencing-apparaat te configureren op basis van de omheiningsagent fence_kdump. De fence_kdump agent kan detecteren dat een knooppunt kdump crash recovery heeft ingevoerd en kan de crash recovery-service voltooien voordat andere fencing-methoden worden aangeroepen. Houd er rekening mee dat fence_kdump dit geen vervanging is voor traditionele omheiningsmechanismen, zoals de SBD- of Azure Fence-agent, wanneer u Azure-VM's gebruikt.
Belangrijk
Houd er rekening mee dat wanneer fence_kdump deze is geconfigureerd als een afschermingsapparaat op het eerste niveau, vertragingen in de afschermingsbewerkingen introduceert en, respectievelijk, vertragingen in de failover van toepassingsresources.
Als er een crashdump is gedetecteerd, wordt de fencing vertraagd totdat de crashherstelservice is afgerond. Als het mislukte knooppunt onbereikbaar is of als het niet reageert, wordt de fencing vertraagd op basis van de tijd die is bepaald, het geconfigureerde aantal iteraties en de fence_kdump time-out. Zie Hoe kan ik fence_kdump configureren in een Red Hat Pacemaker-cluster? voor meer informatie.
De voorgestelde fence_kdump time-out moet mogelijk worden aangepast aan de specifieke omgeving.
We raden u aan om fencing alleen te configureren fence_kdump wanneer dat nodig is om diagnostische gegevens binnen de VM te verzamelen en altijd in combinatie met traditionele omheiningsmethoden, zoals SBD of Azure Fence Agent.
De volgende Red Hat KB-artikelen bevatten belangrijke informatie over het configureren van fence_kdump fencing:
- Zie Hoe kan ik fence_kdump configureren in een Red Hat Pacemaker-cluster?.
- Zie Hoe u fencingniveaus in een RHEL-cluster configureert/beheert met Pacemaker.
- Zie fence_kdump mislukt met 'time-out na X seconden' in een RHEL 6- of 7 HA-cluster met kexec-tools ouder dan 2.0.14.
- Zie Hoe kan ik kdump configureren voor gebruik met de invoegtoepassing RHEL 6, 7, 8 HA voor meer informatie over het wijzigen van de standaardtime-out.
- Voor informatie over hoe u de vertraging van failover kunt verminderen wanneer u
fence_kdumpgebruikt, zie Kan ik de verwachte vertraging van failover verminderen bij het toevoegen van fence_kdump configuratie?.
Voer de volgende optionele stappen uit om fence_kdump toe te voegen als een configuratie op het eerste niveau van fencing, naast de configuratie van de Azure Fence-agent.
[A] Controleer of dit
kdumpactief en geconfigureerd is.systemctl is-active kdump # Expected result # active[A] Installeer de
fence_kdumpfence-agent.yum install fence-agents-kdump[1] Maak een
fence_kdumpfencing-systeem in het cluster.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] Configureer afschermingsniveaus zodat het
fence_kdumpafschermingsmechanisme eerst wordt ingeschakeld.pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] Sta de vereiste poorten in de firewall toe voor
fence_kdump.firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] Voer de
fence_kdump_nodesconfiguratie uit/etc/kdump.confom te voorkomen datfence_kdumpmislukt met een time-out voor sommigekexec-toolsversies. Zie fence_kdump time-out wanneer fence_kdump_nodes niet is opgegeven met kexec-tools versie 2.0.15 of hoger en fence_kdump mislukt met time-out na X seconden in een RHEL 6- of 7 high availability-cluster met kexec-tools versies ouder dan 2.0.14. De voorbeeldconfiguratie voor een cluster met twee knooppunten wordt hier weergegeven. Nadat u een wijziging in/etc/kdump.confhebt aangebracht, moet het kdump-image opnieuw worden gegenereerd. Begin dekdump-service opnieuw om deze te regenereren.vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] Zorg ervoor dat het
initramfsafbeeldingsbestand defence_kdumpenhostsbestanden bevat. Zie Hoe kan ik fence_kdump configureren in een Red Hat Pacemaker-cluster? voor meer informatie.lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendTest de configuratie door een knooppunt te crashen. Zie Hoe kan ik fence_kdump configureren in een Red Hat Pacemaker-cluster? voor meer informatie.
Belangrijk
Als het cluster al productief is, plant u de test dienovereenkomstig omdat het vastlopen van een knooppunt gevolgen heeft voor de toepassing.
echo c > /proc/sysrq-trigger
Volgende stappen
- Zie Planning en implementatie van Azure Virtual Machines voor SAP.
- Zie de implementatie van Azure Virtual Machines voor SAP.
- Zie de DBMS-implementatie van Azure Virtual Machines voor SAP.
- Zie Hoge beschikbaarheid van SAP HANA op virtuele Azure-machines voor meer informatie over het instellen van hoge beschikbaarheid van SAP HANA en het plannen van herstel na noodgevallen van SAP HANA op virtuele Azure-machines.