Indexeerfuncties, vaardigheden of documenten uitvoeren of opnieuw instellen
In Azure AI Search zijn er verschillende manieren om een indexeerfunctie uit te voeren:
- Direct uitvoeren bij het maken van de indexeerfunctie, ervan uitgaande dat deze niet is gemaakt in de modus Uitgeschakeld.
- Voer volgens een schema uit om de uitvoering regelmatig aan te roepen.
- Voer op aanvraag uit, met of zonder 'reset'.
In dit artikel wordt uitgelegd hoe u indexeerfuncties op aanvraag uitvoert, met en zonder opnieuw instellen. Ook worden de uitvoering, duur en gelijktijdigheid van de indexeerfunctie beschreven.
Hoe indexeerfuncties verbinding maken met Azure-resources
Indexeerfuncties zijn een van de weinige subsystemen die uitgaande aanroepen naar andere Azure-resources maken. In termen van Azure-rollen hebben indexeerfuncties geen afzonderlijke identiteiten: een verbinding van de zoekmachine naar een andere Azure-resource wordt gemaakt met behulp van de door het systeem of door de gebruiker toegewezen beheerde identiteit van een zoekservice. Als de indexeerfunctie verbinding maakt met een Azure-resource in een virtueel netwerk, moet u een gedeelde privékoppeling voor die verbinding maken. Zie de beveiliging in Azure AI Search voor meer informatie over beveiligde verbindingen.
Uitvoering van indexeerfunctie
Een zoekservice voert één indexeertaak per zoekeenheid uit. Elke zoekservice begint met één zoekeenheid, maar elke nieuwe partitie of replica verhoogt de zoekeenheden van uw service. U kunt het aantal zoekeenheden controleren in de sectie Essential van de portal van de overzichtspagina . Als u gelijktijdige verwerking nodig hebt, moet u ervoor zorgen dat u voldoende replica's hebt. Indexeerfuncties worden niet op de achtergrond uitgevoerd, dus u kunt meer querybeperking detecteren dan normaal als de service onder druk staat.
In de volgende schermopname ziet u het aantal zoekeenheden, waarmee wordt bepaald hoeveel indexeerfuncties tegelijk kunnen worden uitgevoerd.

Zodra de uitvoering van de indexeerfunctie is gestart, kunt u deze niet onderbreken of stoppen. De uitvoering van de indexeerfunctie stopt wanneer er geen documenten meer zijn om te laden of te vernieuwen, of wanneer de maximale uitvoeringstijdslimiet is bereikt.
U kunt meerdere indexeerfuncties tegelijk uitvoeren, ervan uitgaande dat er voldoende capaciteit is, maar elke indexeerfunctie zelf is één exemplaar. Als u een nieuw exemplaar start terwijl de indexeerfunctie al in uitvoering is, wordt deze fout gegenereerd: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
Een indexeertaak wordt uitgevoerd in een beheerde uitvoeringsomgeving. Er zijn momenteel twee omgevingen. U kunt niet bepalen of configureren welke omgeving wordt gebruikt. Azure AI Search bepaalt de omgeving op basis van taaksamenstelling en de mogelijkheid van de service om een indexeertaak te verplaatsen naar een inhoudsprocessor (sommige beveiligingsfuncties blokkeren de omgeving met meerdere tenants).
De uitvoeringsomgevingen van de indexeerfunctie zijn onder andere:
Een privé-uitvoeringsomgeving die wordt uitgevoerd op zoekknooppunten, specifiek voor uw zoekservice.
Een omgeving met meerdere tenants met inhoudsprocessors, beheerd en beveiligd door Microsoft, zonder extra kosten. Deze omgeving wordt gebruikt voor het offloaden van rekenintensieve verwerking, waardoor servicespecifieke resources beschikbaar blijven voor routinebewerkingen. Indien mogelijk worden de meeste indexeerfuncties uitgevoerd in de omgeving met meerdere tenants.
De limieten voor indexeerfuncties variëren voor elke omgeving:
| Workload | Maximale duur | Maximum aantal taken | Uitvoeringsomgeving |
|---|---|---|---|
| Privé-uitvoering | 24 uur | Eén indexeertaak per zoekeenheid 1. | Indexering wordt niet op de achtergrond uitgevoerd. In plaats daarvan zorgt de zoekservice ervoor dat alle indexeringstaken worden afgeslagen op lopende query's en objectbeheeracties (zoals het maken of bijwerken van indexen). Bij het uitvoeren van indexeerfuncties zou u een querylatentie moeten zien als het indexeren van volumes groot is. |
| Multitenant | 2 uur 2 | Onbepaald 3 | Omdat het cluster voor inhoudsverwerking meerdere tenants is, worden knooppunten toegevoegd om aan de vraag te voldoen. Als u een vertraging ondervindt in on-demand of geplande uitvoering, komt dit waarschijnlijk doordat het systeem knooppunten toevoegt of wacht tot er een beschikbaar is. |
1 Zoekeenheden kunnen flexibele combinaties van partities en replica's zijn, maar indexeertaken zijn niet gekoppeld aan een of meer. Met andere woorden, als u 12 eenheden hebt, kunt u 12 indexeerfuncties tegelijk uitvoeren in privé-uitvoering, ongeacht hoe de zoekeenheden worden geïmplementeerd.
2 Als er meer dan twee uur nodig zijn om alle gegevens te verwerken, schakelt u wijzigingsdetectie in en plant u dat de indexeerfunctie met intervallen van twee uur wordt uitgevoerd. Zie Indexering van een grote gegevensset voor meer strategieën.
3 "Onbepaald" betekent dat de limiet niet wordt gekwantificeerd door het aantal taken. Sommige werkbelastingen, zoals het verwerken van vaardighedensets, kunnen parallel worden uitgevoerd, wat kan leiden tot veel taken, ook al is er slechts één indexeerfunctie betrokken. Hoewel de omgeving geen beperkingen oplegt, zijn er nog steeds indexeerlimieten voor uw zoekservice van toepassing.
Uitvoeren zonder opnieuw instellen
Een Run Indexer-bewerking detecteert en verwerkt alleen wat nodig is om de zoekindex te synchroniseren met wijzigingen in de onderliggende gegevensbron. Incrementele indexering begint met het zoeken naar een interne hoogwatermarkering om het laatst bijgewerkte zoekdocument te vinden. Dit wordt het startpunt voor het uitvoeren van de indexeerfunctie voor nieuwe en bijgewerkte documenten in de gegevensbron.
Wijzigingsdetectie is essentieel voor het bepalen wat er nieuw of bijgewerkt is in de gegevensbron. Indexeerfuncties gebruiken de mogelijkheden voor wijzigingsdetectie van de onderliggende gegevensbron om te bepalen wat er nieuw of bijgewerkt is in de gegevensbron.
Azure Storage heeft ingebouwde wijzigingsdetectie via de eigenschap LastModified.
Andere gegevensbronnen, zoals Azure SQL of Azure Cosmos DB, moeten worden geconfigureerd voor wijzigingsdetectie voordat de indexeerfunctie nieuwe en bijgewerkte rijen kan lezen.
Als de onderliggende inhoud ongewijzigd is, heeft een uitvoeringsbewerking geen effect. In dit geval geeft de uitvoeringsgeschiedenis van de indexeerfunctie aan welke 0\0 documenten zijn verwerkt.
U moet de indexeerfunctie opnieuw instellen, zoals wordt uitgelegd in de volgende sectie, om deze volledig opnieuw te verwerken.
Indexeerfuncties opnieuw instellen
Na de eerste uitvoering houdt een indexeerfunctie bij welke zoekdocumenten zijn geïndexeerd via een interne hoogwatermarkering. De markering wordt nooit weergegeven, maar intern weet de indexeerfunctie waar deze voor het laatst is gestopt.
Als u een index geheel of gedeeltelijk opnieuw moet opbouwen, kunt u de hoge watermarkeringen van de indexeerfunctie wissen via een reset. Reset-API's zijn beschikbaar op afnemende niveaus in de objecthiërarchie:
- Indexeerfuncties wissen de hoge watermarkering en voert een volledige herindex van alle documenten uit
- Documenten opnieuw instellen (preview) indexeert een specifiek document of een specifieke lijst met documenten opnieuw
- Vaardigheden opnieuw instellen (preview) roept vaardigheidsverwerking aan voor een specifieke vaardigheid
Volg na het opnieuw instellen de opdracht Uitvoeren om nieuwe en bestaande documenten opnieuw te verwerken. Zwevende zoekdocumenten zonder tegenhanger in de gegevensbron kunnen niet worden verwijderd via opnieuw instellen/uitvoeren. Als u documenten wilt verwijderen, raadpleegt u in plaats daarvan Documenten - Index .
Indexeerfuncties opnieuw instellen en uitvoeren
Opnieuw instellen wist de hoge watermarkering. Alle documenten in de zoekindex worden gemarkeerd voor volledig overschrijven, zonder inline-updates of samenvoeging in bestaande inhoud. Voor indexeerfuncties met een vaardighedenset en verrijkingscaching wordt de vaardighedenset ook impliciet opnieuw ingesteld door de index opnieuw in te stellen.
De werkelijke hoeveelheid werk vindt plaats wanneer u een reset volgt met de opdracht Uitvoeren:
- Alle nieuwe documenten die de onderliggende bron hebben gevonden, worden toegevoegd aan de zoekindex.
- Alle documenten in zowel de gegevensbron als de zoekindex worden overschreven in de zoekindex.
- Alle verrijkte inhoud die is gemaakt op basis van vaardighedensets, wordt opnieuw opgebouwd. De verrijkingscache, als deze is ingeschakeld, wordt vernieuwd.
Zoals eerder vermeld, is het opnieuw instellen een passieve bewerking: u moet een Run-aanvraag opvolgen om de index opnieuw te bouwen.
Reset-/uitvoeringsbewerkingen zijn van toepassing op een zoekindex of een kennisarchief, op specifieke documenten of projecties en op verrijkingen in de cache als een reset expliciet of impliciet vaardigheden bevat.
Opnieuw instellen is ook van toepassing op het maken en bijwerken van bewerkingen. Hiermee wordt het verwijderen of opschonen van zwevende documenten in de zoekindex niet geactiveerd. Zie Documenten - Index voor meer informatie over het verwijderen van documenten.
Nadat u een indexeerfunctie opnieuw hebt ingesteld, kunt u de actie niet ongedaan maken.
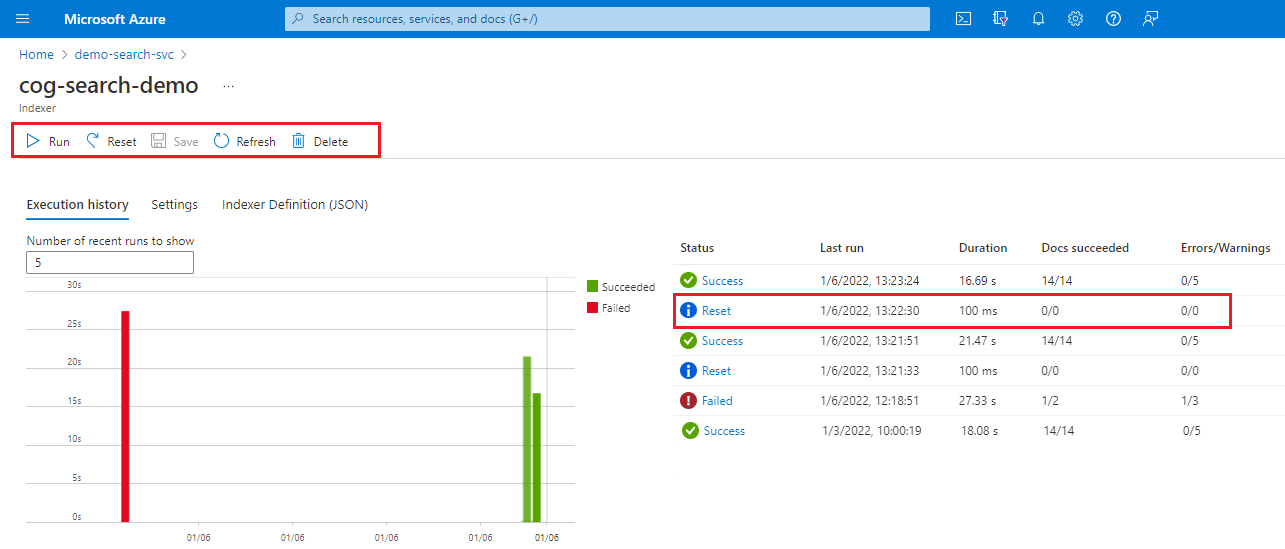
Meld u aan bij Azure Portal en open de zoekservicepagina.
Selecteer op de pagina Overzicht het tabblad Indexeerfuncties .
Selecteer een indexeerfunctie.
Selecteer de opdracht Opnieuw instellen en selecteer vervolgens Ja om de actie te bevestigen.
Vernieuw de pagina om de status weer te geven. U kunt het item selecteren om de details ervan weer te geven.
Selecteer Uitvoeren om de verwerking van de indexeerfunctie te starten of wacht op de volgende geplande uitvoering.
Vaardigheden opnieuw instellen (preview)
Voor indexeerfuncties met vaardighedensets kunt u afzonderlijke vaardigheden opnieuw instellen om alleen die vaardigheid en eventuele downstreamvaardigheden af te dwingen die afhankelijk zijn van de uitvoer. De verrijkingscache, als u deze hebt ingeschakeld, wordt ook vernieuwd.
Reset skills is momenteel alleen-rest, beschikbaar via 2020-06-30-preview of hoger. We raden de nieuwste preview-API aan.
POST /skillsets/[skillset name]/resetskills?api-version=2024-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
U kunt afzonderlijke vaardigheden opgeven, zoals aangegeven in het bovenstaande voorbeeld, maar als een van deze vaardigheden uitvoer vereist van niet-vermelde vaardigheden (#2 tot en met #4), worden niet-vermelde vaardigheden uitgevoerd, tenzij de cache de benodigde informatie kan verstrekken. Om dit waar te maken, mogen verrijkingen in de cache voor vaardigheden #2 tot en met #4 niet afhankelijk zijn van #1 (vermeld voor opnieuw instellen).
Als er geen vaardigheden zijn opgegeven, wordt de volledige vaardighedenset uitgevoerd en als caching is ingeschakeld, wordt de cache ook vernieuwd.
Vergeet niet om op te volgen met Run Indexer om de werkelijke verwerking aan te roepen.
Documenten opnieuw instellen (preview)
De indexeerfuncties - Docs opnieuw instellen accepteert een lijst met documentsleutels , zodat u specifieke documenten kunt vernieuwen. Indien opgegeven, worden de parameters voor opnieuw instellen de enige determinant van wat wordt verwerkt, ongeacht andere wijzigingen in de onderliggende gegevens. Als er bijvoorbeeld 20 blobs zijn toegevoegd of bijgewerkt sinds de laatste indexeerfunctie, maar u slechts één document opnieuw instelt, wordt alleen dat document verwerkt.
Op documentbasis worden alle velden in dat zoekdocument vernieuwd met waarden uit de gegevensbron. U kunt niet kiezen welke velden u wilt vernieuwen.
Als het document is verrijkt via een vaardighedenset en gegevens in de cache heeft, wordt de vaardighedenset alleen aangeroepen voor alleen de opgegeven documenten en wordt de cache bijgewerkt voor de opnieuw verwerkte documenten.
Wanneer u deze API voor het eerst test, kunnen de volgende API's u helpen het gedrag te valideren en te testen. U kunt preview-API-versie 2020-06-30-preview en hoger gebruiken. We raden de nieuwste preview-API aan.
Indexeerfuncties aanroepen : status ophalen met een preview-API-versie om de status van opnieuw instellen en de uitvoeringsstatus te controleren. U vindt informatie over de aanvraag voor opnieuw instellen aan het einde van het statusantwoord.
Indexeerfuncties aanroepen : stel Docs opnieuw in met een preview-API-versie om op te geven welke documenten moeten worden verwerkt.
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2024-05-01-preview { "documentKeys" : [ "1001", "4452" ] }De documentsleutels in de aanvraag zijn waarden uit de zoekindex. Deze kunnen afwijken van de bijbehorende velden in de gegevensbron. Als u niet zeker weet wat de sleutelwaarde is, stuurt u een query om de waarde te retourneren. U kunt alleen
selecthet documentsleutelveld retourneren.Voor blobs die worden geparseerd in meerdere zoekdocumenten (waarbij parsingMode is ingesteld op jsonLines of jsonArrays of delimitedText), wordt de documentsleutel gegenereerd door de indexeerfunctie en is deze mogelijk onbekend voor u. In dit scenario retourneert een query voor de documentsleutel de juiste waarde.
Roep Run Indexer (elke API-versie) aan om de documenten te verwerken die u hebt opgegeven. Alleen die specifieke documenten worden geïndexeerd.
Roep Run Indexer een tweede keer aan om te verwerken vanaf de laatste bovengrens.
Roep Zoekdocumenten aan om te controleren op bijgewerkte waarden en om documentsleutels te retourneren als u niet zeker weet wat de waarde is. Gebruik
"select": "<field names>"deze optie als u wilt beperken welke velden in het antwoord worden weergegeven.
De lijst met documentsleutels overschrijven
Als u de API documenten opnieuw instellen aanroept, worden de nieuwe sleutels toegevoegd aan de lijst met documentsleutels die opnieuw worden ingesteld. Als u de API aanroept met de overwrite parameter die is ingesteld op true, wordt de huidige lijst overschreven met de nieuwe:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Status 'currentState' opnieuw instellen controleren
Volg deze stappen om de status van het opnieuw instellen te controleren en te zien welke documentsleutels in de wachtrij staan voor verwerking.
Indexeerstatus ophalen aanroepen met een preview-API.
De preview-API retourneert de
currentStatesectie aan het einde van het antwoord."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Controleer de 'modus':
Voor Het opnieuw instellen van vaardigheden moet de modus 'modus' worden ingesteld
indexingAllDocsop (omdat mogelijk alle documenten worden beïnvloed, wat betreft de velden die zijn ingevuld via AI-verrijking).Als u documenten opnieuw wilt instellen, moet de modus worden ingesteld op
indexingResetDocs. De indexeerfunctie behoudt deze status totdat alle documentsleutels die zijn opgegeven in de aanroep documenten opnieuw instellen, worden verwerkt. Gedurende welke tijd geen andere indexeerfuncties worden uitgevoerd terwijl de bewerking wordt uitgevoerd. Als u alle documenten in de lijst met documentsleutels zoekt, moet elk document worden gebarsten om deze op de sleutel te zoeken en overeen te komen. Dit kan even duren als de gegevensset groot is. Als een blobcontainer honderden blobs bevat en de documenten die u opnieuw wilt instellen zich aan het einde bevinden, vindt de indexeerfunctie de overeenkomende blobs pas nadat alle andere blobs zijn gecontroleerd.Nadat de documenten opnieuw zijn verwerkt, voert u de status Van de indexeerfunctie ophalen opnieuw uit. De indexeerfunctie keert terug naar de
indexingAllDocsmodus en verwerkt nieuwe of bijgewerkte documenten tijdens de volgende uitvoering.
Volgende stappen
Reset-API's worden gebruikt om het bereik van de volgende uitvoering van de indexeerfunctie te informeren. Voor de werkelijke verwerking moet u een indexeerfunctie op aanvraag aanroepen of een geplande taak toestaan om het werk te voltooien. Nadat de uitvoering is voltooid, keert de indexeerfunctie terug naar de normale verwerking, ongeacht of dat volgens een planning of verwerking op aanvraag is.
Nadat u indexeertaken opnieuw hebt ingesteld en opnieuw hebt uitgevoerd, kunt u de status van de zoekservice controleren of gedetailleerde informatie verkrijgen via resourcelogboekregistratie.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor