Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Zoeken in volledige tekst is een benadering bij het ophalen van informatie die overeenkomt met tekst zonder opmaak die is opgeslagen in een index. Als u bijvoorbeeld een querytekenreeks 'hotels in San Diego op het strand' opgeeft, zoekt de zoekmachine naar tokenized tekenreeksen op basis van deze termen. Om scans efficiënter te maken, ondergaan queryreeksen lexicale analyses: alle termen in kleine letters, het verwijderen van stopwoorden zoals 'de' en het verminderen van termen tot primitieve hoofdformulieren. Wanneer overeenkomende termen worden gevonden, haalt de zoekmachine documenten op, rangschikt deze in volgorde van relevantie en worden de belangrijkste resultaten geretourneerd.
Het uitvoeren van query's kan complex zijn. Dit artikel is bedoeld voor ontwikkelaars die meer inzicht nodig hebben in hoe zoeken in volledige tekst werkt in Azure AI Search. Voor tekstquery's levert Azure AI Search naadloos verwachte resultaten in de meeste scenario's, maar soms krijgt u mogelijk een resultaat dat 'uit' lijkt. In deze situaties kunt u met een achtergrond in de vier fasen van lucene-queryuitvoering (queryparsering, lexicale analyse, documentkoppeling, scoren) specifieke wijzigingen in queryparameters of indexconfiguratie identificeren die het gewenste resultaat opleveren.
Notitie
Azure AI Search maakt gebruik van Apache Lucene voor zoeken in volledige tekst, maar Lucene-integratie is niet volledig. We stellen Lucene-functionaliteit selectief beschikbaar en uitbreiden om de scenario's mogelijk te maken die belangrijk zijn voor Azure AI Search.
Overzicht en diagram van architectuur
De uitvoering van query's heeft vier fasen:
- Queryparsering
- Lexicale analyse
- Document ophalen
- Scoren
Een zoekquery voor volledige tekst begint met het parseren van de querytekst om zoektermen en operatoren te extraheren. Er zijn twee parsers, zodat u kunt kiezen tussen snelheid en complexiteit. Een analysefase is de volgende, waarbij afzonderlijke querytermen soms worden opgesplitst en opnieuw worden samengesteld in nieuwe formulieren. Deze stap helpt bij het casten van een breder net over wat als een mogelijke overeenkomst kan worden beschouwd. De zoekmachine scant vervolgens de index om documenten te zoeken met overeenkomende termen en scores voor elke overeenkomst. Vervolgens wordt een resultatenset gesorteerd op een relevantiescore die aan elk afzonderlijk overeenkomend document is toegewezen. Deze boven aan de gerangschikte lijst worden geretourneerd naar de aanroepende toepassing.
In het onderstaande diagram ziet u de onderdelen die worden gebruikt om een zoekaanvraag te verwerken.
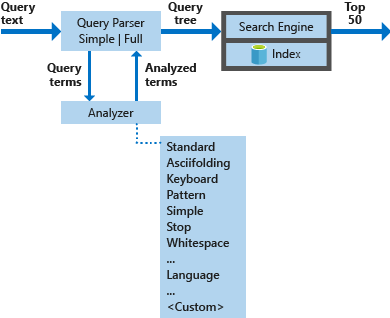
| Belangrijke onderdelen | Functionele beschrijving |
|---|---|
| Queryparsers | Scheid querytermen van queryoperators en maak de querystructuur (een querystructuur) die naar de zoekmachine moet worden verzonden. |
| Analyzers | Lexicale analyse uitvoeren op querytermen. Dit proces kan betrekking hebben op het transformeren, verwijderen of uitbreiden van querytermen. |
| Index | Een efficiënte gegevensstructuur die wordt gebruikt voor het opslaan en organiseren van doorzoekbare termen die zijn geëxtraheerd uit geïndexeerde documenten. |
| Zoekmachine | Hiermee worden overeenkomende documenten opgehaald en scores opgehaald op basis van de inhoud van de omgekeerde index. |
Anatomie van een zoekaanvraag
Een zoekaanvraag is een volledige specificatie van wat moet worden geretourneerd in een resultatenset. In de eenvoudigste vorm is het een lege query zonder criteria van welke aard dan ook. Een realistischer voorbeeld bevat parameters, verschillende querytermen, mogelijk gericht op bepaalde velden, met mogelijk een filterexpressie en ordenenregels.
Het volgende voorbeeld is een zoekaanvraag die u kunt verzenden naar Azure AI Search met behulp van de REST API.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Voor deze aanvraag voert de zoekmachine de volgende bewerkingen uit:
Hiermee vindt u documenten waar de prijs ten minste $ 60 en minder dan $ 300 is.
Hiermee wordt de query uitgevoerd. In dit voorbeeld bestaat de zoekquery uit woordgroepen en termen:
"Spacious, air-condition* +\"Ocean view\""(gebruikers voeren meestal geen interpunctie in, maar kunnen we in het voorbeeld uitleggen hoe analyses deze verwerken).Voor deze query scant de zoekmachine de beschrijvings- en titelvelden die zijn opgegeven in 'searchFields' op documenten die
"Ocean view", en ook op de term"spacious", of op termen die beginnen met het voorvoegsel"air-condition". De parameter searchMode wordt gebruikt om overeen te komen met elke term (standaard) of allemaal, voor gevallen waarin een term niet expliciet vereist is (+).Hiermee wordt de resulterende set hotels gesorteerd op nabijheid van een bepaalde geografische locatie en worden de resultaten vervolgens geretourneerd naar de aanroepende toepassing.
Het meeste in dit artikel gaat over het verwerken van de zoekquery: "Spacious, air-condition* +\"Ocean view\"". Filteren en ordenen valt buiten het bereik. Zie de naslagdocumentatie voor de Zoek-API voor meer informatie.
Fase 1: Queryparsering
Zoals vermeld, is de queryreeks de eerste regel van de aanvraag:
"search": "Spacious, air-condition* +\"Ocean view\"",
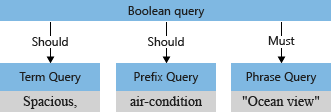
Met de queryparser worden operators (zoals * en + in het voorbeeld) gescheiden van zoektermen en wordt de zoekquery gedeconstrueerd in subquery's van een ondersteund type:
- termquery voor zelfstandige termen (zoals ruim)
- woordgroepsquery voor termen tussen aanhaalt (zoals oceaanweergave)
-
voorvoegselquery voor termen gevolgd door een voorvoegseloperator
*(zoals air-condition)
Zie Lucene-querysyntaxis voor een volledige lijst met ondersteunde querytypen
Operators die zijn gekoppeld aan een subquery bepalen of de query 'moet zijn' of 'moet' worden voldaan om een document als een overeenkomst te laten beschouwen. Is bijvoorbeeld +"Ocean view" 'must' vanwege de + operator.
De queryparser herstructureert de subquery's in een querystructuur (een interne structuur die de query vertegenwoordigt) die wordt doorgegeven aan de zoekmachine. In de eerste fase van het parseren van query's ziet de querystructuur er als volgt uit.
Ondersteunde parsers: Simple en Full Lucene
Azure AI Search maakt twee verschillende querytalen beschikbaar, simple (standaard) en full. Door de queryType parameter in te stellen met uw zoekaanvraag, geeft u de queryparser aan welke querytaal u kiest, zodat deze weet hoe de operators en syntaxis moeten worden geïnterpreteerd.
De eenvoudige querytaal is intuïtief en robuust, vaak geschikt om gebruikersinvoer als zodanig te interpreteren zonder verwerking aan de clientzijde. Het ondersteunt queryoperators die bekend zijn van webzoekprogramma's.
De volledige Lucene-querytaal, die u krijgt door het instellen
queryType=full, breidt de standaardtaal simple query uit door ondersteuning toe te voegen voor meer operators en querytypen, zoals jokertekens, fuzzy, regex en query's met veldbereik. Een reguliere expressie die wordt verzonden in eenvoudige querysyntaxis, wordt bijvoorbeeld geïnterpreteerd als een querytekenreeks en niet als een expressie. De voorbeeldaanvraag in dit artikel maakt gebruik van de volledige Lucene-querytaal.
Impact van searchMode op de parser
Een andere zoekaanvraagparameter die van invloed is op parseren, is de parameter searchMode. Het bepaalt de standaardoperator voor Boole-query's: elke (standaard) of alle.
Wanneer "searchMode=any", wat de standaardinstelling is, is het spatiescheidingsteken tussen ruim en luchtvoorwaarde OR (||), waardoor de voorbeeldquerytekst gelijk is aan:
Spacious,||air-condition*+"Ocean view"
Expliciete operators, zoals + in +"Ocean view", zijn ondubbelzinnig in booleaanse queryconstructie (de term moet overeenkomen). Minder duidelijk is hoe de resterende termen worden geïnterpreteerd: ruim en luchtconditie. Moet de zoekmachine overeenkomsten vinden op het uitzicht op de oceaan en ruime en airconditioning? Of moet het uitzicht op de oceaan plus een van de resterende voorwaarden vinden?
Standaard ("searchMode=any"), gaat de zoekmachine uit van de bredere interpretatie. Een veld moet overeenkomen met de semantiek 'or'. In de eerste querystructuur die eerder is geïllustreerd, met de twee 'should'-bewerkingen, wordt de standaardwaarde weergegeven.
Stel dat we nu searchMode=all instellen. In dit geval wordt de ruimte geïnterpreteerd als een 'and'-bewerking. Elk van de resterende voorwaarden moet beide aanwezig zijn in het document om als overeenkomst in aanmerking te komen. De resulterende voorbeeldquery wordt als volgt geïnterpreteerd:
+Spacious,+air-condition*+"Ocean view"
Een gewijzigde querystructuur voor deze query is als volgt, waarbij een overeenkomend document het snijpunt is van alle drie de subquery's:

Notitie
Het kiezen van "searchMode=any" over "searchMode=all" is een beslissing die het beste is aangekomen door representatieve query's uit te voeren. Gebruikers die waarschijnlijk operatoren bevatten (gebruikelijk bij het zoeken in documentarchieven) kunnen intuïtiever resultaten vinden als 'searchMode=all' booleaanse queryconstructies informeert. Zie de syntaxis van eenvoudige query's voor meer informatie over de interactie tussen searchMode en operators.
Fase 2: Lexicale analyse
Lexical analyzers verwerken termenquery's en woordgroepquery's nadat de querystructuur is gestructureerd. Een analyse accepteert de tekstinvoer die eraan is gegeven door de parser, verwerkt de tekst en stuurt vervolgens tokenized termen terug die in de querystructuur moeten worden opgenomen.
De meest voorkomende vorm van lexicale analyse is *taalkundige analyse waarmee querytermen worden getransformeerd op basis van regels die specifiek zijn voor een bepaalde taal:
- Een queryterm beperken tot de hoofdvorm van een woord
- Niet-essentiële woorden verwijderen (stopwoorden, zoals "the" of "and" in het Engels)
- Een samengesteld woord opsplitsen in onderdelen
- Kleine hoofdletters
Al deze bewerkingen wissen meestal verschillen tussen de tekstinvoer van de gebruiker en de termen die zijn opgeslagen in de index. Dergelijke bewerkingen gaan verder dan tekstverwerking en vereisen diepgaande kennis van de taal zelf. Azure AI Search biedt ondersteuning voor een lange lijst met taalanalyses van Lucene en Microsoft om deze taalbewustzijn toe te voegen.
Notitie
Analysevereisten kunnen variëren van minimaal tot uitgebreid, afhankelijk van uw scenario. U kunt de complexiteit van lexicale analyse beheren door een van de vooraf gedefinieerde analyses te selecteren of door uw eigen aangepaste analyse te maken. Analyzers zijn gericht op doorzoekbare velden en worden opgegeven als onderdeel van een velddefinitie. Hierdoor kunt u lexicale analyses per veld variëren. Niet opgegeven, de standaard Lucene Analyzer wordt gebruikt.
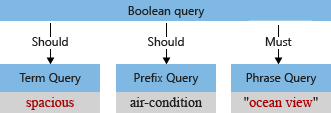
In ons voorbeeld heeft de eerste querystructuur vóór de analyse de term 'Ruim', met een hoofdletter 'S' en een komma die de queryparser interpreteert als onderdeel van de queryterm (een komma wordt niet beschouwd als een querytaaloperator).
Wanneer de standaardanalyse de term verwerkt, wordt de term 'oceaanweergave' en 'ruim' in kleine letters weergegeven en wordt het kommateken verwijderd. De gewijzigde querystructuur ziet er als volgt uit:
Analysegedrag testen
Het gedrag van een analyse kan worden getest met behulp van de Analyse-API. Geef de tekst op die u wilt analyseren om te zien welke termen in de analyse worden gegenereerd. Als u bijvoorbeeld wilt zien hoe de standaardanalyse de tekst 'air-condition' verwerkt, kunt u de volgende aanvraag uitgeven:
{
"text": "air-condition",
"analyzer": "standard"
}
De standaardanalyse breekt de invoertekst op in de volgende twee tokens, waarbij er aantekeningen worden toegevoegd aan kenmerken zoals begin- en eind offsets (gebruikt voor het markeren van treffers) en hun positie (gebruikt voor woordgroepkoppeling):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Uitzonderingen op lexicale analyse
Lexicale analyse is alleen van toepassing op querytypen waarvoor volledige termen zijn vereist: een termquery of een woordgroepsquery. Deze is niet van toepassing op querytypen met onvolledige termen , voorvoegselquery, jokertekenquery, regex-query of op een fuzzy query. Deze querytypen, inclusief de voorvoegselquery met de term air-condition* in ons voorbeeld, worden rechtstreeks toegevoegd aan de querystructuur, waardoor de analysefase wordt overgeslagen. De enige transformatie die wordt uitgevoerd op querytermen van deze typen is lager.
Fase 3: Ophalen van documenten
Bij het ophalen van documenten wordt verwezen naar het zoeken naar documenten met overeenkomende termen in de index. Deze fase wordt het beste begrepen door een voorbeeld. Laten we beginnen met een hotelsindex met het volgende eenvoudige schema:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Ga er verder van uit dat deze index de volgende vier documenten bevat:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Hoe termen worden geïndexeerd
Om inzicht te hebben in het ophalen, is het handig om enkele basisprincipes van indexering te kennen. De opslageenheid is een omgekeerde index, één voor elk doorzoekbaar veld. Binnen een omgekeerde index is een gesorteerde lijst met alle termen uit alle documenten. Elke term wordt toegewezen aan de lijst met documenten waarin deze voorkomt, zoals wordt weergegeven in het onderstaande voorbeeld.
Om de termen in een omgekeerde index te produceren, voert de zoekmachine lexicale analyse uit op de inhoud van documenten, vergelijkbaar met wat er gebeurt tijdens het verwerken van query's:
- Tekstinvoer wordt doorgegeven aan een analyse, kleine letters, ontdaan van interpunctie, enzovoort, afhankelijk van de analyseconfiguratie.
- Tokens zijn de uitvoer van lexicale analyse.
- Termen worden toegevoegd aan de index.
Het is gebruikelijk, maar niet vereist, om dezelfde analysefuncties te gebruiken voor zoek- en indexeringsbewerkingen, zodat querytermen er meer uitzien als termen in de index.
Notitie
Met Azure AI Search kunt u verschillende analysefuncties opgeven voor indexering en zoekopdrachten via aanvullende indexAnalyzer en searchAnalyzer veldparameters. Indien niet opgegeven, wordt de analyseset met de analyzer eigenschap gebruikt voor zowel indexeren als zoeken.
Omgekeerde index voor voorbeelddocumenten
Terug naar ons voorbeeld ziet de omgekeerde index er als volgt uit voor het titelveld :
| Term | Documentlijst |
|---|---|
| Atman | 1 |
| strand | 2 |
| hotel | 1, 3 |
| oceaan | 4 |
| Playa | 3 |
| toevlucht | 3 |
| zich terugtrekken | 4 |
In het titelveld wordt alleen het hotel weergegeven in twee documenten: 1, 3.
Voor het beschrijvingsveld is de index als volgt:
| Term | Documentlijst |
|---|---|
| lucht | 3 |
| en | 4 |
| strand | 1 |
| geconditioneerd | 3 |
| comfortabel | 3 |
| afstand | 1 |
| eiland | 2 |
| kauaʻi | 2 |
| Gelegen | 2 |
| noord | 2 |
| oceaan | 1, 2, 3 |
| van de | 2 |
| op | 2 |
| stille | 4 |
| kamers | 1, 3 |
| alleenstaand | 4 |
| kust | 2 |
| ruim | 1 |
| het | 1, 2 |
| to | 1 |
| weergeven | 1, 2, 3 |
| wandelen | 1 |
| wordt uitgevoerd met | 3 |
Overeenkomende querytermen op basis van geïndexeerde termen
Gezien de omgekeerde indexen hierboven, gaan we terug naar de voorbeeldquery en kijken we hoe overeenkomende documenten worden gevonden voor onze voorbeeldquery. Zoals u weet ziet de uiteindelijke querystructuur er als volgt uit:
Tijdens het uitvoeren van query's worden afzonderlijke query's onafhankelijk uitgevoerd op de doorzoekbare velden.
De TermQuery, "ruim", komt overeen met document 1 (Hotel Atman).
De prefixQuery, 'air-condition*', komt niet overeen met documenten.
Dit is een gedrag dat ontwikkelaars soms verwarren. Hoewel de term airconditioner in het document bestaat, wordt deze gesplitst in twee termen door de standaardanalyse. Zoals u weet, worden voorvoegselquery's, die gedeeltelijke termen bevatten, niet geanalyseerd. Daarom worden termen met voorvoegsel 'air-condition' opgezoekd in de omgekeerde index en niet gevonden.
De PhraseQuery, 'oceaanweergave', zoekt de termen 'oceaan' en 'weergave' op en controleert de nabijheid van termen in het oorspronkelijke document. Documenten 1, 2 en 3 komen overeen met deze query in het beschrijvingsveld. Let op: document 4 bevat de term oceaan in de titel, maar wordt niet beschouwd als een overeenkomst, omdat we op zoek zijn naar de woordgroep 'oceaanweergave' in plaats van afzonderlijke woorden.
Notitie
Een zoekquery wordt onafhankelijk uitgevoerd voor alle doorzoekbare velden in de Azure AI Search-index, tenzij u de velden beperkt die zijn ingesteld met de searchFields parameter, zoals geïllustreerd in de voorbeeldzoekaanvraag. Documenten die overeenkomen in een van de geselecteerde velden, worden geretourneerd.
Voor de betreffende query zijn de documenten die overeenkomen 1, 2, 3.
Fase 4: Scoren
Aan elk document in een zoekresultaatset wordt een relevantiescore toegewezen. De functie van de relevantiescore is het rangschikken van de documenten die het beste een gebruikersvraag beantwoorden, zoals uitgedrukt in de zoekquery. De score wordt berekend op basis van statistische eigenschappen van termen die overeenkomen. De kern van de scoreformule is TF/IDF (term frequency-inverse documentfrequentie). In query's met zeldzame en algemene termen bevordert TF/IDF resultaten die de zeldzame term bevatten. Bijvoorbeeld, in een hypothetische index met alle Wikipedia-artikelen, uit documenten die overeenkomen met de query de president, documenten die op president overeenkomen, worden documenten die overeenkomen met president beschouwd als relevanter dan documenten die overeenkomen met de documenten die op de lijst staan.
Voorbeeld van scoren
U herinnert zich de drie documenten die overeenkomen met onze voorbeeldquery:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Document 1 komt het beste overeen met de query omdat zowel de term ruim als de vereiste zinszeeweergave in het beschrijvingsveld voorkomen. De volgende twee documenten komen alleen overeen met het uitzicht op de oceaan. Het kan verrassend zijn dat de relevantiescore voor document 2 en 3 anders is, ook al hebben ze de query op dezelfde manier gevonden. Dit komt doordat de scoreformule meer onderdelen heeft dan alleen TF/IDF. In dit geval is aan document 3 een iets hogere score toegewezen omdat de beschrijving korter is. Meer informatie over de praktische scoreformule van Lucene om te begrijpen hoe veldlengte en andere factoren van invloed kunnen zijn op de relevantiescore.
Sommige querytypen (jokerteken, voorvoegsel, regex) dragen altijd een constante score bij aan de algehele documentscore. Hierdoor kunnen overeenkomsten die via query-uitbreiding worden gevonden, worden opgenomen in de resultaten, maar zonder dat dit van invloed is op de classificatie.
Een voorbeeld laat zien waarom dit belangrijk is. Zoekopdrachten met jokertekens, waaronder zoekopdrachten met voorvoegsels, zijn per definitie dubbelzinnig omdat de invoer een gedeeltelijke tekenreeks is met mogelijke overeenkomsten op een zeer groot aantal verschillende termen (overweeg een invoer van 'tour*', met overeenkomsten die zijn gevonden op 'tours', 'tourettes' en 'tourmaline'). Gezien de aard van deze resultaten, is er geen manier om redelijk te afleiden welke termen waardevoller zijn dan andere. Daarom negeren we termfrequenties bij het scoren van query's van typen jokertekens, voorvoegsel en regex. In een zoekaanvraag met meerdere onderdelen die gedeeltelijke en volledige termen bevat, worden resultaten van de gedeeltelijke invoer opgenomen met een constante score om vooroordelen bij mogelijk onverwachte overeenkomsten te voorkomen.
Relevantie afstemmen
Er zijn twee manieren om relevantiescores af te stemmen in Azure AI Search:
Scoreprofielen promoten documenten in de gerangschikte lijst met resultaten op basis van een set regels. In ons voorbeeld kunnen we documenten overwegen die overeenkomen met het titelveld die relevanter zijn dan documenten die overeenkomen in het beschrijvingsveld. Als onze index bovendien een prijsveld voor elk hotel had, konden we documenten promoveren met een lagere prijs. Meer informatie over het toevoegen van scoreprofielen aan een zoekindex.
Termverbetering (alleen beschikbaar in de volledige Lucene-querysyntaxis) biedt een stimulerende operator
^die kan worden toegepast op elk deel van de querystructuur. In ons voorbeeld, in plaats van te zoeken op het voorvoegsel air-condition*, kan men zoeken naar de exacte term air-condition of het voorvoegsel, maar documenten die overeenkomen op de exacte term zijn gerangschikt hoger door boost toe te passen op de termquery: air-condition^2||air-condition*. Meer informatie over het stimuleren van termen in een query.
Scoren in een gedistribueerde index
Alle indexen in Azure AI Search worden automatisch gesplitst in meerdere shards, zodat we de index snel kunnen distribueren tussen meerdere knooppunten tijdens het omhoog of omlaag schalen van de service. Wanneer een zoekaanvraag wordt uitgegeven, wordt deze onafhankelijk van elke shard uitgegeven. De resultaten van elke shard worden vervolgens samengevoegd en gerangschikt op score (als er geen andere volgorde is gedefinieerd). Het is belangrijk om te weten dat de scorefunctie de frequentie van querytermen aflegt op basis van de inverse documentfrequentie in alle documenten in de shard, niet voor alle shards.
Dit betekent dat een relevantiescore voor identieke documenten kan verschillen als ze zich op verschillende shards bevinden. Gelukkig verdwijnen dergelijke verschillen meestal naarmate het aantal documenten in de index toeneemt vanwege een meer gelijkmatige verdeling van de term. Het is niet mogelijk om aan te nemen op welke shard een bepaald document wordt geplaatst. Als een documentsleutel echter niet wordt gewijzigd, wordt deze altijd toegewezen aan dezelfde shard.
Over het algemeen is de documentscore niet het beste kenmerk voor het ordenen van documenten als ordestabiliteit belangrijk is. Als u bijvoorbeeld twee documenten met een identieke score hebt, is er geen garantie dat er eerst een wordt weergegeven in volgende uitvoeringen van dezelfde query. De documentscore mag alleen een algemeen beeld geven van de relevantie van documenten ten opzichte van andere documenten in de resultatenset.
Conclusie
Het succes van commerciële zoekmachines heeft de verwachtingen voor zoeken in volledige tekst verhoogd ten opzichte van privégegevens. Voor vrijwel elk soort zoekervaring verwachten we dat de engine onze intentie begrijpt, zelfs wanneer termen onjuist of onvolledig zijn. We kunnen zelfs overeenkomsten verwachten op basis van bijna gelijkwaardige termen of synoniemen die we nooit hebben opgegeven.
Vanuit technisch oogpunt is zoeken in volledige tekst zeer complex, waarbij geavanceerde taalkundige analyse en een systematische benadering van verwerking nodig zijn op manieren waarop querytermen worden gedestilleerd, uitgebreid en getransformeerd om een relevant resultaat te leveren. Gezien de inherente complexiteit zijn er veel factoren die van invloed kunnen zijn op het resultaat van een query. Daarom is het investeren van de tijd om inzicht te krijgen in de mechanismen van zoeken in volledige tekst tastbare voordelen wanneer u onverwachte resultaten probeert te doorlopen.
In dit artikel is het zoeken in volledige tekst verkend in de context van Azure AI Search. We hopen dat u voldoende achtergrond krijgt om mogelijke oorzaken en oplossingen te herkennen voor het oplossen van veelvoorkomende queryproblemen.
Volgende stappen
Bouw de voorbeeldindex, probeer verschillende query's uit en bekijk de resultaten. Zie Een index bouwen en er query's op uitvoeren in Azure Portal voor instructies.
Probeer andere querysyntaxis uit de voorbeeldsectie Documenten zoeken of uit eenvoudige querysyntaxis in Search Explorer in Azure Portal.
Controleer scoreprofielen als u de classificatie in uw zoektoepassing wilt afstemmen.
Meer informatie over het toepassen van taalspecifieke lexicale analyses.
Configureer aangepaste analyses voor minimale verwerking of gespecialiseerde verwerking op specifieke velden.
Zie ook
REST API voor documenten zoeken