Semantische rangschikking in Azure AI Search
In Azure AI Search is semantische rangschikking een functie die de relevantie van de zoekfunctie aanzienlijk verbetert door de taalbegripmodellen van Microsoft te gebruiken om zoekresultaten opnieuw te rangschikken. Dit artikel is een inleiding op hoog niveau om inzicht te krijgen in het gedrag en de voordelen van semantische rangschikking.
Semantische ranker is een Premium-functie, gefactureerd op basis van gebruik. We raden dit artikel aan voor achtergrond, maar als u liever aan de slag wilt gaan, volgt u deze stappen.
Notitie
Semantische ranker maakt geen gebruik van generatieve AI of vectoren. Als u zoekt naar vectorondersteuning en overeenkomsten zoeken, raadpleegt u Vector search in Azure AI Search voor meer informatie.
Wat is semantische rangschikking?
Semantische ranker is een verzameling mogelijkheden aan de queryzijde die de kwaliteit verbeteren van een eerste BM25-gerangschikt of RRF-gerangschikt zoekresultaat voor op tekst gebaseerde query's, vectorquery's en hybride query's. Wanneer u deze inschakelt voor uw zoekservice, breidt semantische classificatie de pijplijn voor het uitvoeren van query's op twee manieren uit:
Ten eerste voegt het secundaire classificatie toe boven een eerste resultatenset die werd gescoord met BEHULP van BM25 of Recimaal Rank Fusion (RRF). Deze secundaire classificatie maakt gebruik van meertalige deep learning-modellen die zijn aangepast van Microsoft Bing om de meest semantisch relevante resultaten te promoten.
Ten tweede worden bijschriften en antwoorden geëxtraheerd en geretourneerd in het antwoord, die u op een zoekpagina kunt weergeven om de zoekervaring van de gebruiker te verbeteren.
Hier volgen de mogelijkheden van de semantische reranker.
| Mogelijkheid | Beschrijving |
|---|---|
| L2-classificatie | Gebruikt de context of semantische betekenis van een query om een nieuwe relevantiescore te berekenen ten opzichte van vooraf gedefinieerde resultaten. |
| Semantische bijschriften en markeringen | Extraheert exacte zinnen en woordgroepen uit velden die de inhoud het beste samenvatten, met markeringen over belangrijke passages voor eenvoudig scannen. Bijschriften die een resultaat samenvatten, zijn handig wanneer afzonderlijke inhoudsvelden te dicht zijn voor de pagina met zoekresultaten. Gemarkeerde tekst verhoogt de meest relevante termen en woordgroepen, zodat gebruikers snel kunnen bepalen waarom een overeenkomst als relevant werd beschouwd. |
| Semantische antwoorden | Een optionele en extra substructuur die wordt geretourneerd door een semantische query. Het biedt een direct antwoord op een query die lijkt op een vraag. Het vereist dat een document tekst bevat met de kenmerken van een antwoord. |
Hoe semantische ranker werkt
Semantische ranker voert een query en resultaten uit voor taalkennis van modellen die door Microsoft worden gehost en scant op betere overeenkomsten.
In de volgende afbeelding wordt het concept uitgelegd. Houd rekening met de term 'kapitaal'. Het heeft verschillende betekenissen, afhankelijk van of de context financieel, recht, geografie of grammatica is. Via taalkennis kan de semantische ranker context detecteren en resultaten promoten die passen bij de queryintentie.
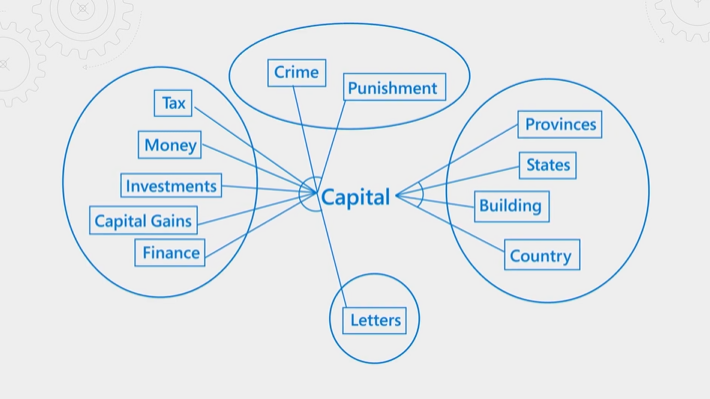
Semantische rangschikking is zowel resource- als tijdsintensief. Om de verwerking binnen de verwachte latentie van een querybewerking te voltooien, worden de invoer in de semantische rangschikking geconsolideerd en verkleind, zodat de herrankeringsstap zo snel mogelijk kan worden voltooid.
Er zijn drie stappen voor semantische rangschikking:
- Invoer verzamelen en samenvatten
- Scoreresultaten met behulp van de semantische ranker
- Resultaten, bijschriften en antwoorden met opnieuw scoren
Hoe invoer wordt verzameld en samengevat
In semantische classificatie geeft het querysubsysteem zoekresultaten door als invoer voor samenvattings- en classificatiemodellen. Omdat de classificatiemodellen beperkingen voor invoergrootte hebben en intensief worden verwerkt, moeten zoekresultaten worden aangepast en gestructureerd (samengevat) voor een efficiënte verwerking.
Semantische ranker begint met een BM25-gerangschikt resultaat van een tekstquery of een RRF-gerangschikt resultaat van een vector- of hybride query. Alleen tekstvelden worden gebruikt in de herrankeringsoefening en alleen de top 50 resultaten worden naar semantische rangschikking uitgevoerd, zelfs als de resultaten meer dan 50 bevatten. Velden die in semantische rangschikking worden gebruikt, zijn doorgaans informatief en beschrijvend.
Voor elk document in het zoekresultaat accepteert het samenvattingsmodel maximaal 2000 tokens, waarbij een token ongeveer 10 tekens is. Invoer wordt samengesteld uit de velden 'title', 'keyword' en 'content' die worden vermeld in de semantische configuratie.
Overmatige lange tekenreeksen worden bijgesneden om ervoor te zorgen dat de totale lengte voldoet aan de invoervereisten van de samenvattingsstap. Deze bijsnijdoefening is waarom het belangrijk is om velden toe te voegen aan uw semantische configuratie in volgorde van prioriteit. Als u zeer grote documenten met tekstzware velden hebt, wordt alles na de maximumlimiet genegeerd.
Semantisch veld Tokenlimiet "titel" 128 tokens "trefwoorden 128 tokens "inhoud" resterende tokens Samenvattingsuitvoer is een samenvattingstekenreeks voor elk document, samengesteld uit de meest relevante informatie uit elk veld. Samenvattingstekenreeksen worden verzonden naar de classificatie voor scoren en naar leesbegripmodellen van computers voor bijschriften en antwoorden.
De maximale lengte van elke gegenereerde samenvattingstekenreeks die wordt doorgegeven aan de semantische ranker, is 256 tokens.
Hoe rangschikking wordt beoordeeld
Scoren wordt uitgevoerd via het bijschrift en andere inhoud uit de samenvattingstekenreeks waarmee de lengte van het 256-token wordt ingevuld.
Bijschriften worden geëvalueerd voor conceptuele en semantische relevantie ten opzichte van de opgegeven query.
Een @search.rerankerScore wordt aan elk document toegewezen op basis van de semantische relevantie van het document voor de opgegeven query. Scores variëren van 4 tot 0 (hoog tot laag), waarbij een hogere score een hogere relevantie aangeeft.
Score Betekenis 4.0 Het document is zeer relevant en beantwoordt de vraag volledig, hoewel de passage mogelijk extra tekst bevat die niet aan de vraag is gerelateerd. 3,0 Het document is relevant, maar ontbreekt aan details waarmee het document kan worden voltooid. 2.0 Het document is enigszins relevant; het beantwoordt de vraag gedeeltelijk of alleen een aantal aspecten van de vraag. 1.0 Het document is gerelateerd aan de vraag en beantwoordt een klein deel ervan. 0,0 Het document is niet relevant. Overeenkomsten worden in aflopende volgorde weergegeven op score en opgenomen in de nettolading van het queryantwoord. De nettolading bevat antwoorden, tekst zonder opmaak en gemarkeerde bijschriften en velden die u hebt gemarkeerd als ophaalbaar of opgegeven in een select-component.
Notitie
Voor een bepaalde query kunnen de distributies van @search.rerankerScore kleine variaties vertonen vanwege omstandigheden op infrastructuurniveau. Updates van classificatiemodellen zijn ook bekend om de distributie te beïnvloeden. Als u om deze redenen aangepaste code schrijft voor minimale drempelwaarden of als u de drempelwaarde-eigenschap instelt voor vector- en hybride query's, moet u de limieten niet te gedetailleerd maken.
Uitvoer van semantische rangschikking
Uit elke samenvattingstekenreeks vinden de machinebegripmodellen passages die het meest representatief zijn.
Uitvoer is:
Een semantisch bijschrift voor het document. Elk bijschrift is beschikbaar in een tekst zonder opmaak en een markeringsversie en is vaak minder dan 200 woorden per document.
Een optioneel semantisch antwoord, ervan uitgaande dat u de
answersparameter hebt opgegeven, is de query ingesteld als een vraag en wordt een passage gevonden in de lange tekenreeks die waarschijnlijk antwoord geeft op de vraag.
Bijschriften en antwoorden zijn altijd exacte tekst uit uw index. Er is geen generatief AI-model in deze werkstroom waarmee nieuwe inhoud wordt gemaakt of samengesteld.
Semantische mogelijkheden en beperkingen
Semantische ranker is een nieuwere technologie, dus het is belangrijk om verwachtingen te stellen over wat het wel en niet kan. Wat het kan doen:
Promoot overeenkomsten die semantisch dichter bij de intentie van de oorspronkelijke query liggen.
Zoek tekenreeksen die moeten worden gebruikt als bijschriften en antwoorden. Bijschriften en antwoorden worden geretourneerd in het antwoord en kunnen worden weergegeven op een pagina met zoekresultaten.
Wat semantische ranker niet kan doen, is de query opnieuw uitvoeren op het hele corpus om semantisch relevante resultaten te vinden. De Semantische classificatie herschikt de bestaande resultatenset, bestaande uit de top 50 resultaten, zoals beoordeeld door het standaardclassificatie-algoritme. Bovendien kan semantische ranker geen nieuwe informatie of tekenreeksen maken. Bijschriften en antwoorden worden letterlijk uit uw inhoud geëxtraheerd, dus als de resultaten geen antwoordachtige tekst bevatten, produceren de taalmodellen er geen.
Hoewel semantische rangschikking in elk scenario niet nuttig is, kan bepaalde inhoud aanzienlijk profiteren van de mogelijkheden ervan. De taalmodellen in semantische rangschikking werken het beste voor doorzoekbare inhoud die informatierijk en gestructureerd is als proza. Een knowledge base, onlinedocumentatie of documenten die beschrijvende inhoud bevatten, zien de meeste voordelen van semantische classificatiemogelijkheden.
De onderliggende technologie is afkomstig van Bing en Microsoft Research en is geïntegreerd in de Azure AI Search-infrastructuur als een invoegtoepassingsfunctie. Zie Hoe AI van Bing Azure AI Search aanstuurt (Microsoft Research Blog) voor meer informatie over de onderzoeks- en AI-investeringen die semantische rangschikking bieden.
De volgende video biedt een overzicht van de mogelijkheden.
Beschikbaarheid en prijzen
Semantische ranker is beschikbaar voor zoekservices in de Basic- en hogere lagen, afhankelijk van regionale beschikbaarheid.
Wanneer u semantische rangschikking inschakelt, kiest u een prijsplan voor de functie:
- Bij lagere queryvolumes (minder dan 1000 maandelijks) is semantische classificatie gratis.
- Kies bij hogere queryvolumes het standaardprijsplan.
Op de pagina met prijzen voor Azure AI Search ziet u het factureringstarief voor verschillende valuta's en intervallen.
Kosten voor semantische rangschikking worden in rekening gebracht wanneer queryaanvragen zijn opgenomen queryType=semantic en de zoekreeks niet leeg is (bijvoorbeeld search=pet friendly hotels in New York). Als uw zoekreeks leeg is (search=*), worden er geen kosten in rekening gebracht, zelfs niet als het queryType is ingesteld op semantisch.
Aan de slag met semantische ranker
Meld u aan bij Azure Portal om te controleren of uw zoekservice Basic of hoger is.
Stel query's in om semantische bijschriften en markeringen te retourneren.