Een vectorquery maken in Azure AI Search
Als u in Azure AI Search een vectorindex hebt, wordt in dit artikel uitgelegd hoe u:
In dit artikel wordt REST gebruikt voor illustratie. Zie de GitHub-opslagplaats azure-search-vector-samples voor end-to-end-oplossingen met vectorquery's voor codevoorbeelden in andere talen.
U kunt Search Explorer ook gebruiken in Azure Portal.
Vereisten
Azure AI Search, in elke regio en op elke laag.
Een vectorindex in Azure AI Search. Controleer op een
vectorSearchsectie in uw index om een vectorindex te bevestigen.Voeg eventueel een vectorizer toe aan uw index voor ingebouwde tekst-naar-vector- of image-to-vector-conversie tijdens query's.
Visual Studio Code met een REST-client en voorbeeldgegevens als u deze voorbeelden zelf wilt uitvoeren. Zie quickstart: Azure AI Search met REST om aan de slag te gaan met de REST-client.
Een queryreeksinvoer converteren naar een vector
Als u een query wilt uitvoeren op een vectorveld, moet de query zelf een vector zijn.
Een benadering voor het converteren van de tekenreeks voor tekstquery's van een gebruiker naar de vectorweergave is het aanroepen van een insluitbibliotheek of API in uw toepassingscode. Als best practice kunt u altijd dezelfde insluitingsmodellen gebruiken die worden gebruikt voor het genereren van insluitingen in de brondocumenten. U vindt codevoorbeelden die laten zien hoe u insluitingen genereert in de opslagplaats azure-search-vector-samples .
Een tweede benadering is het gebruik van geïntegreerde vectorisatie, nu algemeen beschikbaar, om Azure AI Search te laten omgaan met de invoer en uitvoer van uw queryvectorisatie.
Hier volgt een REST API-voorbeeld van een querytekenreeks die is verzonden naar een implementatie van een Azure OpenAI-insluitmodel:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
Het verwachte antwoord is 202 voor een geslaagde aanroep naar het geïmplementeerde model.
Het veld 'insluiten' in de hoofdtekst van het antwoord is de vectorweergave van de querytekenreeks 'invoer'. Voor testdoeleinden kopieert u de waarde van de matrix 'embedding' naar vectorQueries.vector in een queryaanvraag, met behulp van de syntaxis die wordt weergegeven in de volgende secties.
Het werkelijke antwoord voor deze POST-aanroep naar het geïmplementeerde model bevat 1536 insluitingen, die hier zijn ingekort tot slechts de eerste paar vectoren voor leesbaarheid.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
In deze benadering is uw toepassingscode verantwoordelijk voor het maken van verbinding met een model, het genereren van insluitingen en het verwerken van het antwoord.
Vectorqueryaanvraag
In deze sectie ziet u de basisstructuur van een vectorquery. U kunt Azure Portal, REST API's of de Azure SDK's gebruiken om een vectorquery te formuleren. Als u migreert van 2023-07-01-Preview, zijn er belangrijke wijzigingen. Zie Upgraden naar de nieuwste REST API voor meer informatie.
2024-07-01 is de stabiele REST API-versie voor Search POST. Deze versie ondersteunt:
vectorQueriesis de constructie voor vectorzoekopdrachten.vectorQueries.kindingesteld opvectorvoor een vectormatrix of ingesteld optextals de invoer een tekenreeks is en u een vectorizer hebt.vectorQueries.vectoris een query (een vectorweergave van tekst of een afbeelding).vectorQueries.weight(optioneel) geeft het relatieve gewicht aan van elke vectorquery die is opgenomen in zoekbewerkingen (zie vectorgewicht).exhaustive(optioneel) roept uitgebreide KNN aan tijdens het uitvoeren van query's, zelfs als het veld is geïndexeerd voor HNSW.
In het volgende voorbeeld is de vector een weergave van deze tekenreeks: 'wat Azure-services ondersteuning bieden voor zoeken in volledige tekst'. De query is gericht op het contentVector veld. De query retourneert k resultaten. De werkelijke vector heeft 1536 insluitingen, dus deze wordt in dit voorbeeld ingekort voor leesbaarheid.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
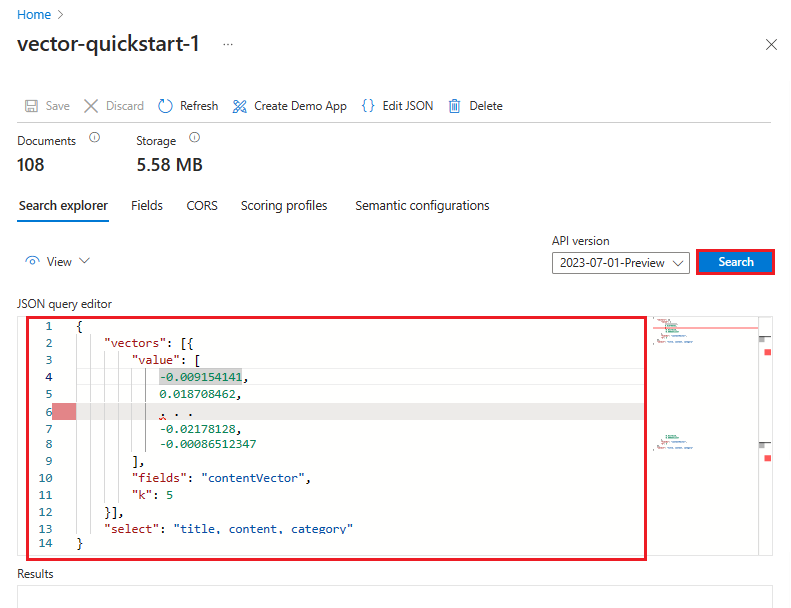
Vectorqueryantwoord
In Azure AI Search bestaan queryantwoorden standaard uit alle retrievable velden. Het is echter gebruikelijk om zoekresultaten te beperken tot een subset retrievable van velden door ze in een select instructie weer te geven.
In een vectorquery moet u zorgvuldig overwegen of u vectorvelden in een antwoord moet gebruiken. Vectorvelden zijn niet door mensen leesbaar, dus als u een reactie naar een webpagina pusht, moet u niet-vectorvelden kiezen die representatief zijn voor het resultaat. Als de query bijvoorbeeld wordt uitgevoerd contentVector, kunt u in plaats daarvan retourneren content .
Als u vectorvelden in het resultaat wilt, ziet u hier een voorbeeld van de antwoordstructuur. contentVector is een tekenreeksmatrix met insluitingen, die hier zijn ingekort om kortheid te beperken. De zoekscore geeft relevantie aan. Andere niet-ctorvelden zijn opgenomen voor context.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Belangrijkste punten:
kbepaalt hoeveel dichtstbijzijnde buurresultaten worden geretourneerd, in dit geval drie. Vectorquery's retournerenkaltijd resultaten, ervan uitgaande dat er ten minstekdocumenten bestaan, zelfs als er documenten met een slechte overeenkomst zijn, omdat het algoritme alle dichtstbijzijnde buren aan de queryvector vindtk.De
@search.scorewordt bepaald door het algoritme voor vectorzoekopdrachten.Velden in zoekresultaten zijn alle
retrievablevelden of velden in eenselectcomponent. Tijdens de uitvoering van vectorquery's wordt de overeenkomst alleen gemaakt op vectorgegevens. Een antwoord kan echter elkretrievableveld in een index bevatten. Omdat er geen mogelijkheid is voor het decoderen van een vectorveldresultaat, is het opnemen van niet-vectortekstvelden handig voor hun leesbare waarden.
Meerdere vectorvelden
U kunt de eigenschap vectorQueries.fields instellen op meerdere vectorvelden. De vectorquery wordt uitgevoerd op elk vectorveld dat u in de fields lijst opgeeft. Wanneer u query's uitvoert op meerdere vectorvelden, moet u ervoor zorgen dat elk veld insluitingen bevat uit hetzelfde insluitingsmodel en dat de query ook wordt gegenereerd op basis van hetzelfde insluitingsmodel.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Query's met meerdere vectoren
Meerdere queryvectorzoekopdrachten verzenden meerdere query's over meerdere vectorvelden in uw zoekindex. Een veelvoorkomend voorbeeld van deze queryaanvraag is bij het gebruik van modellen zoals CLIP voor een multimodale vectorzoekopdracht waarbij hetzelfde model afbeeldings- en tekstinhoud kan vectoriseren.
In het volgende queryvoorbeeld wordt gezocht naar overeenkomsten in beide myImageVector en myTextVector, maar worden er twee verschillende insluitingen voor query's verzonden, die beide parallel worden uitgevoerd. Deze query produceert een resultaat dat wordt gescoord met behulp van Recimaal Rank Fusion (RRF).
vectorQueriesbiedt een matrix van vectorquery's.vectorbevat de afbeeldingsvectoren en tekstvectoren in de zoekindex. Elk exemplaar is een afzonderlijke query.fieldsgeeft aan welk vectorveld moet worden gericht.kis het aantal dichtstbijzijnde burenovereenkomsten dat moet worden opgenomen in de resultaten.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Zoekresultaten bevatten een combinatie van tekst en afbeeldingen, ervan uitgaande dat uw zoekindex een veld voor het afbeeldingsbestand bevat (een zoekindex slaat geen afbeeldingen op).
Query uitvoeren met geïntegreerde vectorisatie
In deze sectie ziet u een vectorquery die de geïntegreerde vectorisatie aanroept waarmee een tekst- of afbeeldingsquery wordt geconverteerd naar een vector. We raden de stabiele 2024-07-01 REST API, Search Explorer of nieuwere Azure SDK-pakketten voor deze functie aan.
Een vereiste is een zoekindex waarbij een vectorizer is geconfigureerd en toegewezen aan een vectorveld. De vectorizer biedt verbindingsgegevens met een insluitmodel dat wordt gebruikt tijdens het uitvoeren van query's.
Search Explorer biedt ondersteuning voor geïntegreerde vectorisatie tijdens het uitvoeren van query's. Als uw index vectorvelden bevat en een vectorizer heeft, kunt u de ingebouwde conversie van tekst-naar-vector gebruiken.
Meld u aan bij Azure Portal met uw Azure-account en ga naar uw Azure AI-Search-service.
Vouw in het linkermenu zoekbeheerindexen> uit en selecteer uw index. Search Explorer is het eerste tabblad op de indexpagina.
Controleer vectorprofielen om te bevestigen dat u een vectorizer hebt.
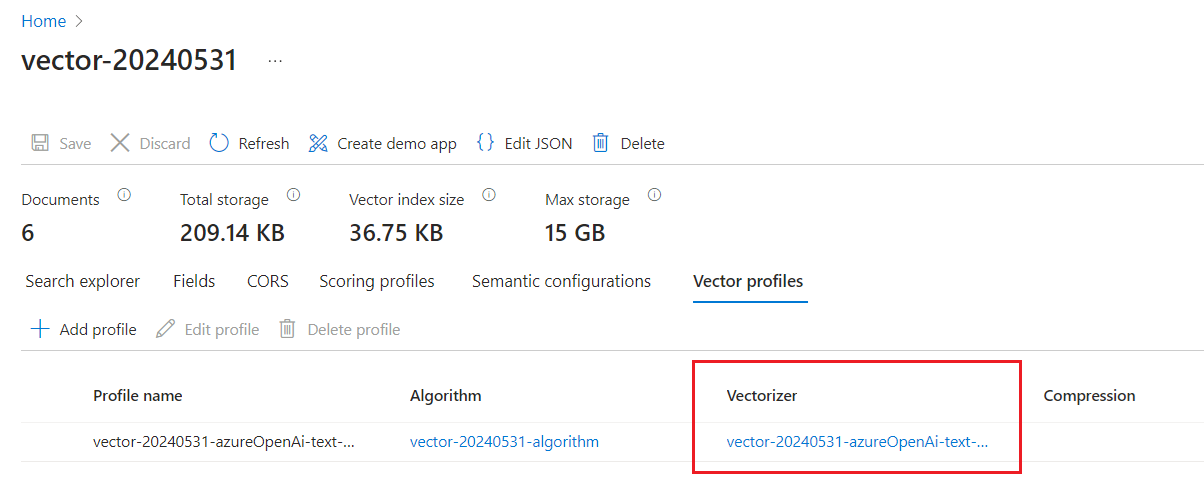
In Search Explorer kunt u een tekenreeks invoeren in de standaardzoekbalk in de queryweergave. De ingebouwde vectorizer converteert uw tekenreeks naar een vector, voert de zoekopdracht uit en retourneert resultaten.
U kunt ook de JSON-weergave Weergeven> selecteren om de query weer te geven of te wijzigen. Als vectoren aanwezig zijn, stelt Search Explorer automatisch een vectorquery in. U kunt de JSON-weergave gebruiken om velden te selecteren die worden gebruikt in zoekopdrachten en in het antwoord, filters toe te voegen of meer geavanceerde query's zoals hybride te maken. Er wordt een JSON-voorbeeld gegeven op het tabblad REST API van deze sectie.
Aantal gerangschikte resultaten in een vectorqueryantwoord
Een vectorquery geeft de k parameter op, waarmee wordt bepaald hoeveel overeenkomsten worden geretourneerd in de resultaten. De zoekmachine retourneert k altijd het aantal overeenkomsten. Als k het aantal documenten in de index groter is dan het aantal documenten, bepaalt het aantal documenten de bovengrens van wat kan worden geretourneerd.
Als u bekend bent met zoeken in volledige tekst, weet u dat u nul resultaten verwacht als de index geen term of woordgroep bevat. Bij vectorzoekopdrachten identificeert de zoekbewerking echter de dichtstbijzijnde buren en retourneert k deze altijd resultaten, zelfs als de dichtstbijzijnde buren niet zo vergelijkbaar zijn. Het is dus mogelijk om resultaten te krijgen voor niet-gevoelige of off-topic-query's, met name als u geen prompts gebruikt om grenzen in te stellen. Minder relevante resultaten hebben een slechtere gelijkenisscore, maar ze zijn nog steeds de dichtstbijzijnde vectoren als er niets dichterbij is. Als zodanig kan een antwoord zonder zinvolle resultaten nog steeds resultaten retourneren k , maar de gelijkenisscore van elk resultaat zou laag zijn.
Een hybride benadering met zoeken in volledige tekst kan dit probleem verhelpen. Een andere beperking is het instellen van een minimumdrempel voor de zoekscore, maar alleen als de query een pure enkelvoudige vectorquery is. Hybride query's zijn niet leidend tot minimale drempelwaarden, omdat de RRF-bereiken zoveel kleiner en vluchtig zijn.
Queryparameters die van invloed zijn op het aantal resultaten zijn onder andere:
"k": nresultaten voor query's met alleen vectoren"top": nresultaten voor hybride query's die een zoekparameter bevatten
Zowel k als top zijn optioneel. Niet opgegeven, het standaardaantal resultaten in een antwoord is 50. U kunt 'top' en 'overslaan' instellen op pagina's door meer resultaten of de standaardwaarde wijzigen.
Classificatiealgoritmen die worden gebruikt in een vectorquery
De rangschikking van resultaten wordt berekend door:
- Metrische gegevens over overeenkomsten
- Wederzijdse Rank Fusion (RRF) als er meerdere sets zoekresultaten zijn.
Metrische gegevens over overeenkomsten
De metrische overeenkomst die is opgegeven in de indexsectie vectorSearch voor een vectorquery. Geldige waarden zijn cosine, euclidean en dotProduct.
Azure OpenAI-insluitmodellen maken gebruik van cosinus-overeenkomsten, dus als u Azure OpenAI-insluitingsmodellen gebruikt, cosine is dit de aanbevolen metrische waarde. Andere ondersteunde metrische classificatiegegevens zijn onder andere euclidean en dotProduct.
RRF gebruiken
Er worden meerdere sets gemaakt als de query is gericht op meerdere vectorvelden, meerdere vectorquery's parallel uitvoert of als de query een hybride van vector en zoeken in volledige tekst is, met of zonder semantische rangschikking.
Tijdens het uitvoeren van query's kan een vectorquery slechts één interne vectorindex bereiken. Voor meerdere vectorvelden en meerdere vectorquery's genereert de zoekmachine dus meerdere query's die gericht zijn op de respectieve vectorindexen van elk veld. De uitvoer is een set gerangschikte resultaten voor elke query, die worden gefuseerd met behulp van RRF. Zie Relevantiescores met behulp van Recimaal Rank Fusion (RRF) voor meer informatie.
Vectorgewicht
Voeg een weight queryparameter toe om het relatieve gewicht op te geven van elke vectorquery die is opgenomen in zoekbewerkingen. Deze waarde wordt gebruikt bij het combineren van de resultaten van meerdere classificatielijsten die zijn geproduceerd door twee of meer vectorquery's in dezelfde aanvraag, of van het vectorgedeelte van een hybride query.
De standaardwaarde is 1,0 en de waarde moet een positief getal groter dan nul zijn.
Gewichten worden gebruikt bij het berekenen van de wederzijdse rangschikkingsscores van elk document. De berekening is vermenigvuldiger van de weight waarde ten opzichte van de rangschikkingsscore van het document in de respectieve resultatenset.
Het volgende voorbeeld is een hybride query met twee vectorqueryreeksen en één tekenreeks. Gewichten worden toegewezen aan de vectorquery's. De eerste query is 0,5 of de helft van het gewicht, waardoor het belang ervan in de aanvraag wordt verminderd. De tweede vectorquery is twee keer zo belangrijk.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
Vectorgewicht is alleen van toepassing op vectoren. De tekstquery in dit voorbeeld ("hallo wereld") heeft een impliciet gewicht van 1,0 of neutraal gewicht. In een hybride query kunt u echter het belang van tekstvelden vergroten of verkleinen door maxTextRecallSize in te stellen.
Drempelwaarden instellen om resultaten met een lage score uit te sluiten (preview)
Omdat het zoeken van dichtstbijzijnde buren altijd de aangevraagde k buren retourneert, is het mogelijk om meerdere overeenkomsten met lage scores te verkrijgen als onderdeel van het voldoen aan de vereiste voor het k aantal in zoekresultaten. Als u een zoekresultaat met een lage score wilt uitsluiten, kunt u een threshold queryparameter toevoegen waarmee resultaten worden gefilterd op basis van een minimale score. Filteren vindt plaats voordat resultaten van verschillende relevante overeenkomstensets worden samengesmelt.
Deze parameter is nog in preview. U wordt aangeraden de preview-versie van REST API 2024-05-01-preview te bekijken.
In dit voorbeeld worden alle overeenkomsten die lager dan 0,8 scoren uitgesloten van vectorzoekresultaten, zelfs als het aantal resultaten lager kis dan .
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
MaxTextSizeRecall voor hybride zoekopdrachten (preview)
Vectorquery's worden vaak gebruikt in hybride constructies die niet-vectorvelden bevatten. Als u ontdekt dat bm25-gerangschikte resultaten over of ondervertegenwoordigd zijn in een hybride queryresultaten, kunt u instellen maxTextRecallSize dat de resultaten met BM25-classificatie voor hybride classificatie worden verhoogd of verlaagd.
U kunt deze eigenschap alleen instellen in hybride aanvragen die zowel de onderdelen 'search' als 'vectorQueries' bevatten.
Deze parameter is nog in preview. U wordt aangeraden de preview-versie van REST API 2024-05-01-preview te bekijken.
Zie Set maxTextRecallSize - Een hybride query maken voor meer informatie.
Volgende stappen
Bekijk als volgende stap voorbeelden van vectorquerycode in Python, C# of JavaScript.