Azure Service Fabric bewaken
In dit artikel wordt het volgende beschreven:
- De typen bewakingsgegevens die u voor deze service kunt verzamelen.
- Manieren om die gegevens te analyseren.
Notitie
Als u al bekend bent met deze service en/of Azure Monitor en alleen wilt weten hoe u bewakingsgegevens analyseert, raadpleegt u de sectie Analyseren aan het einde van dit artikel.
Wanneer u kritieke toepassingen en bedrijfsprocessen hebt die afhankelijk zijn van Azure-resources, moet u waarschuwingen voor uw systeem bewaken en ontvangen. De Azure Monitor-service verzamelt en aggregeert metrische gegevens en logboeken van elk onderdeel van uw systeem. Azure Monitor biedt een overzicht van beschikbaarheid, prestaties en tolerantie, en geeft u een overzicht van problemen. U kunt de Azure-portal, PowerShell, Azure CLI, REST API of clientbibliotheken gebruiken om bewakingsgegevens in te stellen en weer te geven.
- Zie het overzicht van Azure Monitor voor meer informatie over Azure Monitor.
- Zie Azure-resources bewaken met Azure Monitor voor meer informatie over het bewaken van Azure-resources in het algemeen.
Azure Service Fabric-bewaking
Azure Service Fabric heeft de volgende lagen die u kunt bewaken:
- Toepassingsbewaking: de toepassingen die worden uitgevoerd op de knooppunten. U kunt toepassingen bewaken met Application Insights-sleutel of SDK, EventStore of ASP.NET Core-logboekregistratie.
- Bewaking van platformen (cluster): metrische clientgegevens, logboeken en gebeurtenissen voor het platform of clusterknooppunt , inclusief metrische containergegevens. De metrische gegevens en logboeken verschillen voor Linux- of Windows-knooppunten.
- Bewaking van infrastructuur (prestaties): Servicestatus en prestatiemeteritems voor de service-infrastructuur.
U kunt controleren hoe uw toepassingen worden gebruikt, de acties die worden uitgevoerd door het Service Fabric-platform, uw resourcegebruik met prestatiemeteritems en de algehele status van uw cluster. Azure Monitor-logboeken en Application Insights bieden ingebouwde integratie met Service Fabric.
- Zie Best practices voor bewaking en diagnostische procedures voor Azure Service Fabric voor meer informatie over aanbevolen procedures.
- Zie Zelfstudie: Een Service Fabric-cluster bewaken in Azure voor een zelfstudie over het weergeven van service fabric-gebeurtenissen en statusrapporten, het uitvoeren van query's op de EventStore-API's en het bewaken van prestatiemeteritems.
- Zie zelfstudie: Windows-containers bewaken in Service Fabric met behulp van Azure Monitor-logboeken voor meer informatie over het configureren van Azure Monitor-logboeken voor het bewaken van uw Windows-containers die zijn ingedeeld in Service Fabric.
Service Fabric Explorer
Service Fabric Explorer, een bureaubladtoepassing voor Windows, macOS en Linux, is een opensource-hulpprogramma voor het inspecteren en beheren van Azure Service Fabric-clusters. Om automatisering mogelijk te maken, kan elke actie die kan worden uitgevoerd via Service Fabric Explorer ook worden uitgevoerd via PowerShell of een REST API.
Toepassingsbewaking
Toepassingsbewaking houdt bij hoe functies en onderdelen van uw toepassing worden gebruikt. U wilt uw toepassingen controleren om ervoor te zorgen dat er problemen zijn die van invloed zijn op gebruikers. De verantwoordelijkheid van toepassingsbewaking is voor de gebruikers die een toepassing en de bijbehorende services ontwikkelen, omdat deze uniek is voor de bedrijfslogica van uw toepassing. Het bewaken van uw toepassingen kan handig zijn in de volgende scenario's:
- Hoeveel verkeer ondervindt mijn toepassing? - Moet u uw services schalen om te voldoen aan de eisen van gebruikers of om een potentieel knelpunt in uw toepassing aan te pakken?
- Zijn mijn service-naar-service-aanroepen geslaagd en bijgehouden?
- Welke acties worden uitgevoerd door de gebruikers van mijn toepassing? - Het verzamelen van telemetrie kan leiden tot toekomstige functieontwikkeling en betere diagnostische gegevens voor toepassingsfouten
- Werpt mijn toepassing onverwerkte uitzonderingen op?
- Wat gebeurt er in de services die in mijn containers worden uitgevoerd?
Het mooie van toepassingsbewaking is dat ontwikkelaars alle hulpprogramma's en frameworks kunnen gebruiken die ze willen, omdat ze zich in de context van uw toepassing bevinden. Meer informatie over de Azure-oplossing voor toepassingsbewaking met Azure Monitor Application Insights in Gebeurtenisanalyse met Application Insights.
We hebben ook een zelfstudie over het instellen hiervan voor .NET-toepassingen. In deze zelfstudie wordt uitgelegd hoe u de juiste hulpprogramma's installeert, een voorbeeld voor het schrijven van aangepaste telemetrie in uw toepassing en het weergeven van de diagnostische gegevens en telemetrie van toepassingen in Azure Portal.
Toepassingslogboeken
Het instrumenteren van uw code is niet alleen een manier om inzicht te krijgen in uw gebruikers, maar ook de enige manier waarop u kunt weten of er iets mis is in uw toepassing en om vast te stellen wat er moet worden opgelost. Hoewel het technisch gezien mogelijk is om een foutopsporingsprogramma te verbinden met een productieservice, is het niet gebruikelijk. Het is dus belangrijk om gedetailleerde instrumentatiegegevens te hebben.
Sommige producten instrumenteer automatisch uw code. Hoewel deze oplossingen goed kunnen werken, is handmatige instrumentatie vrijwel altijd vereist om specifiek te zijn voor uw bedrijfslogica. Uiteindelijk moet u voldoende informatie hebben om forensisch fouten in de toepassing op te sporen. Service Fabric-toepassingen kunnen worden geïnstrueerd met elk logboekregistratieframework. In deze sectie worden een aantal verschillende benaderingen beschreven voor het instrumenteren van uw code en wanneer u een methode kiest voor een andere.
Application Insights SDK: Application Insights heeft een uitgebreide integratie met Service Fabric. Gebruikers kunnen de NUGet-pakketten van AI Service Fabric toevoegen en gegevens en logboeken ontvangen die zijn gemaakt en verzameld die kunnen worden weergegeven in Azure Portal. Daarnaast worden gebruikers aangemoedigd om hun eigen telemetrie toe te voegen om hun toepassingen te diagnosticeren en fouten op te sporen en bij te houden welke services en onderdelen van hun toepassing het meest worden gebruikt. De TelemetryClient-klasse in de SDK biedt veel manieren om telemetrie in uw toepassingen bij te houden. Zie Gebeurtenisanalyse en visualisatie met Application Insights voor meer informatie.
Bekijk een voorbeeld van het instrumenteren en toevoegen van application insights aan uw toepassing in onze zelfstudie voor het bewaken en diagnosticeren van een .NET-toepassing.
EventSource: Wanneer u een Service Fabric-oplossing maakt op basis van een sjabloon in Visual Studio, wordt er een EventSource-klasse (ServiceEventSource of ActorEventSource) gegenereerd. Er wordt een sjabloon gemaakt waarin u gebeurtenissen voor uw toepassing of service kunt toevoegen. De EventSource-naam moet uniek zijn en moet worden gewijzigd in de standaardsjabloontekenreeks MyCompany-solution-project><><. Als u meerdere EventSource-definities hebt die dezelfde naam gebruiken, treedt er tijdens de runtime een probleem op. Elke gedefinieerde gebeurtenis moet een unieke id hebben. Als een id niet uniek is, treedt er een runtimefout op. Sommige organisaties geven waardenbereiken voor id's vooraf om conflicten tussen afzonderlijke ontwikkelteams te voorkomen. Zie de blog van Vance of de MSDN-documentatie voor meer informatie.
ASP.NET Core-logboekregistratie: het is belangrijk dat u zorgvuldig plant hoe u uw code gaat instrumenteren. Met het juiste instrumentatieplan kunt u voorkomen dat uw codebasis wordt gedestabiliseerd en moet de code vervolgens opnieuw worden geïnstrualiseerd. Als u het risico wilt verminderen, kunt u een instrumentatiebibliotheek kiezen zoals Microsoft.Extensions.Logging, die deel uitmaakt van Microsoft ASP.NET Core. ASP.NET Core heeft een ILogger-interface die u kunt gebruiken met de provider van uw keuze, terwijl het effect op bestaande code wordt geminimaliseerd. U kunt de code gebruiken in ASP.NET Core in Windows en Linux en in het volledige .NET Framework, zodat uw instrumentatiecode is gestandaardiseerd.
Zie Logboekregistratie toevoegen aan uw Service Fabric-toepassing voor voorbeelden van het gebruik van deze suggesties.
Platformbewaking (cluster)
Een gebruiker heeft controle over welke telemetrie afkomstig is van de toepassing, omdat een gebruiker de code zelf schrijft, maar hoe zit het met de diagnostische gegevens van het Service Fabric-platform? Een van de doelstellingen van Service Fabric is om toepassingen bestand te houden tegen hardwarefouten. Dit doel wordt bereikt door de mogelijkheid van systeemservices van het platform om infrastructuurproblemen en snel failoverworkloads naar andere knooppunten in het cluster te detecteren. Maar in dit specifieke geval, wat als de systeemservices zelf problemen hebben? Of als bij het implementeren of verplaatsen van een workload regels voor de plaatsing van services worden geschonden? Service Fabric biedt diagnostische gegevens voor deze en meer om ervoor te zorgen dat u op de hoogte bent van activiteiten die plaatsvinden in uw cluster. Enkele voorbeeldscenario's voor clusterbewaking zijn:
Zie Het cluster bewaken voor meer informatie over platformbewaking (cluster).
Service Fabric-gebeurtenissen
Service Fabric biedt een uitgebreide set diagnostische gebeurtenissen, die u kunt openen via de EventStore of het operationele gebeurteniskanaal dat het platform beschikbaar maakt. Deze Service Fabric-gebeurtenissen illustreren acties die door het platform worden uitgevoerd op verschillende entiteiten, zoals knooppunten, toepassingen, services en partities. Dezelfde gebeurtenissen zijn beschikbaar op zowel Windows- als Linux-clusters.
Service Fabric-gebeurteniskanalen: In Windows zijn Service Fabric-gebeurtenissen beschikbaar van één ETW-provider met een set relevante gegevens
logLevelKeywordFiltersdie wordt gebruikt om te kiezen tussen operationele en data & messaging-kanalen. Dit is de manier waarop we uitgaande Service Fabric-gebeurtenissen scheiden waarop ze naar behoefte moeten worden gefilterd. In Linux worden Service Fabric-gebeurtenissen via LTTng geleverd en in één Storage-tabel geplaatst, van waaruit ze naar behoefte kunnen worden gefilterd. Deze kanalen bevatten gecureerde, gestructureerde gebeurtenissen die kunnen worden gebruikt om de status van uw cluster beter te begrijpen. Diagnostische gegevens worden standaard ingeschakeld tijdens het maken van het cluster, waarmee een Azure Storage-tabel wordt gemaakt waarin de gebeurtenissen van deze kanalen in de toekomst naar u worden verzonden om een query uit te voeren.EventStore is een functie die Service Fabric-platformevenementen weergeeft in Service Fabric Explorer en programmatisch via de REST API van de Service Fabric-clientbibliotheek . U ziet een momentopnameweergave van wat er in uw cluster gebeurt voor elk knooppunt, elke service en elke toepassing en query op basis van het tijdstip van de gebeurtenis. De EventStore-API's zijn alleen beschikbaar voor Windows-clusters die worden uitgevoerd in Azure. Op Windows-computers worden deze gebeurtenissen ingevoerd in het gebeurtenislogboek, zodat u Service Fabric-gebeurtenissen in Logboeken kunt zien.
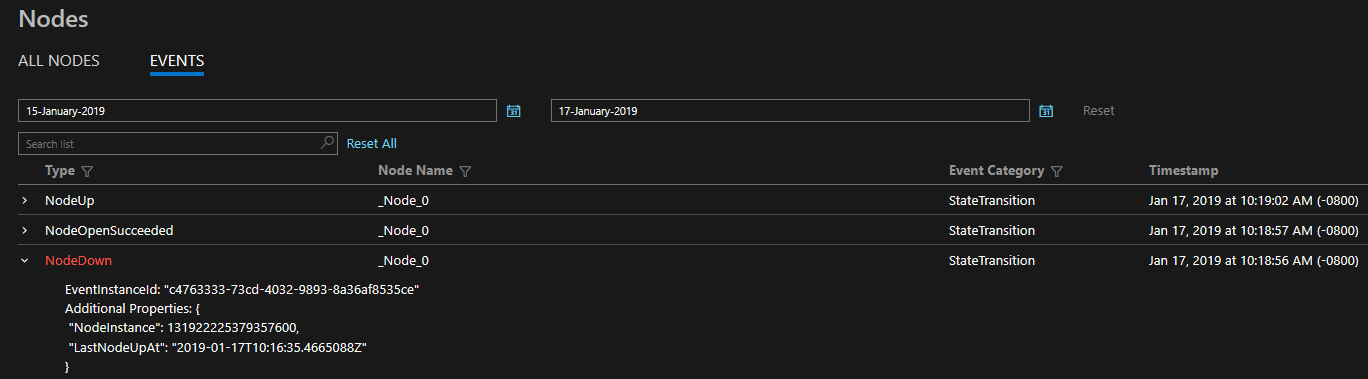
De opgegeven diagnostische gegevens zijn in de vorm van een uitgebreide reeks gebeurtenissen in het vak. Deze Service Fabric-gebeurtenissen illustreren acties die door het platform op verschillende entiteiten worden uitgevoerd, zoals knooppunten, toepassingen, services, partities, enzovoort. In het laatste scenario hierboven, als een knooppunt uitvalt, zou het platform een NodeDown gebeurtenis verzenden en zou u onmiddellijk op de hoogte kunnen worden gesteld door uw controleprogramma van keuze. Andere veelvoorkomende voorbeelden zijn ApplicationUpgradeRollbackStarted of PartitionReconfigured tijdens een failover. Dezelfde gebeurtenissen zijn beschikbaar op zowel Windows- als Linux-clusters.
De gebeurtenissen worden verzonden via standaardkanalen in zowel Windows als Linux en kunnen worden gelezen door elk bewakingsprogramma dat deze ondersteunt. De Azure Monitor-oplossing is Azure Monitor-logboeken. Lees gerust meer over de integratie van Azure Monitor-logboeken, waaronder een aangepast operationeel dashboard voor uw cluster en enkele voorbeeldquery's waaruit u waarschuwingen kunt maken. Er zijn meer concepten voor clusterbewaking beschikbaar op platformniveau voor het genereren van gebeurtenissen en logboeken.
Statuscontrole
Het Service Fabric-platform bevat een statusmodel dat uitbreidbare statusrapportage biedt voor de status van entiteiten in een cluster. Elk knooppunt, elke toepassing, service, partitie, replica of exemplaar heeft een status die continu kan worden bijgewerkt. De status kan 'OK', 'Waarschuwing' of 'Fout' zijn. U kunt Service Fabric-gebeurtenissen beschouwen als werkwoorden die door het cluster worden uitgevoerd naar verschillende entiteiten en status als een bijvoeglijk naamwoord voor elke entiteit. Telkens wanneer de status van een bepaalde entiteit overgaat, wordt er ook een gebeurtenis verzonden. Op deze manier kunt u query's en waarschuwingen instellen voor statusevenementen in uw controleprogramma van uw keuze, net als elke andere gebeurtenis.
Daarnaast laten we gebruikers zelfs de status van entiteiten overschrijven. Als uw toepassing een upgrade uitvoert en er validatietests mislukken, kunt u schrijven naar Service Fabric Health met behulp van de Health-API om aan te geven dat uw toepassing niet meer in orde is en Service Fabric de upgrade automatisch terugdraait. Bekijk de inleiding tot Service Fabric-statuscontrole voor meer informatie over het statusmodel
Waakhonden
Over het algemeen is een watchdog een afzonderlijke service die de status en belasting van services bewaakt, eindpunten pingt en onverwachte status gebeurtenissen in het cluster rapporteert. Dit kan helpen bij het voorkomen van fouten die mogelijk niet alleen worden gedetecteerd op basis van de prestaties van één service. Watchdogs zijn ook een goede plek om code te hosten die herstelacties uitvoert waarvoor geen gebruikersinteractie is vereist, zoals het opschonen van logboekbestanden in de opslag met bepaalde tijdsintervallen. Zie het FabricObserver-project als u een volledig geïmplementeerde open source SF-watchdog-service wilt die een gebruiksvriendelijk uitbreidbaarheidsmodel voor watchdogs bevat en dat wordt uitgevoerd in zowel Windows- als Linux-clusters. FabricObserver is software die gereed is voor productie. We raden u aan FabricObserver te implementeren in uw test- en productieclusters en deze uit te breiden om te voldoen aan uw behoeften via het invoegtoepassingsmodel of door het te forken en uw eigen ingebouwde waarnemers te schrijven. De voormalige (plug-ins) is de aanbevolen aanpak.
Bewaking van infrastructuur (prestaties)
Nu we de diagnostische gegevens in uw toepassing en het platform hebben behandeld, hoe weten we dat de hardware werkt zoals verwacht? Het bewaken van uw onderliggende infrastructuur is een belangrijk onderdeel van het begrijpen van de status van uw cluster en het resourcegebruik. Het meten van systeemprestaties is afhankelijk van veel factoren die subjectief kunnen zijn, afhankelijk van uw workloads. Deze factoren worden doorgaans gemeten via prestatiemeteritems. Deze prestatiemeteritems kunnen afkomstig zijn van verschillende bronnen, waaronder het besturingssysteem, het .NET Framework of het Service Fabric-platform zelf. Sommige scenario's waarin ze nuttig zouden zijn, zijn
- Gebruik ik mijn hardware efficiënt? Wilt u uw hardware gebruiken op 90% CPU of 10% CPU. Dit is handig bij het schalen van uw cluster of het optimaliseren van de processen van uw toepassing.
- Kan ik proactief infrastructuurproblemen voorspellen? - veel problemen worden voorafgegaan door plotselinge wijzigingen (dalingen) in de prestaties, zodat u prestatiemeteritems zoals netwerk-I/O en CPU-gebruik kunt gebruiken om de problemen proactief te voorspellen en diagnosticeren.
Een lijst met prestatiemeteritems die moeten worden verzameld op het niveau van de infrastructuur, vindt u in metrische prestatiegegevens.
Azure Monitor-logboeken worden aanbevolen voor het bewaken van gebeurtenissen op clusterniveau. Nadat u de Log Analytics-agent hebt geconfigureerd met uw werkruimte, kunt u het volgende verzamelen:
- Metrische gegevens over prestaties, zoals CPU-gebruik.
- .NET-prestatiemeteritems, zoals cpu-gebruik op procesniveau.
- Service Fabric-prestatiemeteritems, zoals het aantal uitzonderingen van een betrouwbare service.
- Metrische gegevens van containers, zoals CPU-gebruik.
Resourcetypen
Azure maakt gebruik van het concept van resourcetypen en id's om alles in een abonnement te identificeren. Resourcetypen maken ook deel uit van de resource-id's voor elke resource die wordt uitgevoerd in Azure. Eén resourcetype voor een virtuele machine is Microsoft.Compute/virtualMachinesbijvoorbeeld . Zie Resourceproviders voor een lijst met services en de bijbehorende resourcetypen.
Azure Monitor organiseert op dezelfde manier kernbewakingsgegevens in metrische gegevens en logboeken op basis van resourcetypen, ook wel naamruimten genoemd. Er zijn verschillende metrische gegevens en logboeken beschikbaar voor verschillende resourcetypen. Uw service is mogelijk gekoppeld aan meer dan één resourcetype.
Zie de naslaginformatie over service fabric-bewakingsgegevens voor meer informatie over de resourcetypen voor Azure Service Fabric.
Gegevensopslag
Voor Azure Monitor:
- Metrische gegevens worden opgeslagen in de metrische gegevensdatabase van Azure Monitor.
- Logboekgegevens worden opgeslagen in het logboekarchief van Azure Monitor. Log Analytics is een hulpprogramma in Azure Portal waarmee een query kan worden uitgevoerd op dit archief.
- Het Azure-activiteitenlogboek is een afzonderlijk archief met een eigen interface in Azure Portal.
U kunt eventueel metrische gegevens en activiteitenlogboekgegevens routeren naar het logboekarchief van Azure Monitor. Vervolgens kunt u Log Analytics gebruiken om een query uit te voeren op de gegevens en deze te correleren met andere logboekgegevens.
Veel services kunnen diagnostische instellingen gebruiken om metrische gegevens en logboekgegevens te verzenden naar andere opslaglocaties buiten Azure Monitor. Voorbeelden hiervan zijn Azure Storage, gehoste partnersystemen en niet-Azure-partnersystemen, met behulp van Event Hubs.
Zie het Azure Monitor-gegevensplatform voor gedetailleerde informatie over hoe Azure Monitor gegevens opslaat.
Metrische gegevens van het Azure Monitor-platform
Azure Monitor biedt metrische platformgegevens voor veel services. Zie Ondersteunde metrische gegevens in Azure Monitor voor een lijst met alle metrische gegevens die kunnen worden verzameld voor alle resources in Azure Monitor.
Deze service verzamelt geen metrische platformgegevens.
Metrische gegevens op basis van niet-Azure Monitor
Deze service biedt andere metrische gegevens die niet zijn opgenomen in de metrische Gegevensdatabase van Azure Monitor.
Metrische gegevens van gastbesturingssystemen
Metrische gegevens voor het gastbesturingssysteem (OS) die worden uitgevoerd op Service Fabric-clusterknooppunten, moeten worden verzameld via een of meer agents die worden uitgevoerd op het gastbesturingssysteem. Metrische gegevens van gastbesturingssystemen zijn prestatiemeteritems die het CPU-percentage of geheugengebruik van gasten bijhouden, die beide vaak worden gebruikt voor automatisch schalen of waarschuwingen.
Een best practice is om de Azure Monitor-agent te gebruiken en te configureren voor het verzenden van metrische gegevens van gastbesturingssystemen via de aangepaste api voor metrische gegevens naar de metrische Azure Monitor-database. U kunt de metrische gegevens van het gastbesturingssystemen verzenden naar Azure Monitor-logboeken met behulp van dezelfde agent. Vervolgens kunt u query's uitvoeren op deze metrische gegevens en logboeken met behulp van Log Analytics.
Notitie
De Azure Monitor-agent vervangt de Azure Diagnostics-extensie en de Log Analytics-agent voor routering van gastbesturingssystemen. Zie Overzicht van Azure Monitor-agents voor meer informatie.
Azure Monitor-resourcelogboeken
Resourcelogboeken bieden inzicht in bewerkingen die zijn uitgevoerd door een Azure-resource. Logboeken worden automatisch gegenereerd, maar u moet ze routeren naar Azure Monitor-logboeken om ze op te slaan of er query's op uit te voeren. Logboeken zijn ingedeeld in categorieën. Een bepaalde naamruimte kan meerdere resourcelogboekcategorieën bevatten die u kunt verzamelen.
Deze service verzamelt geen resourcelogboeken, maar u kunt er informatie over vinden in Bewakingsgegevens van Azure-resources.
Service Fabric-logboeken en -gebeurtenissen
Service Fabric kan de volgende logboeken verzamelen:
- Voor Windows-clusters kunt u clusterbewaking instellen met diagnostische agent - en Azure Monitor-logboeken.
- Voor Linux-clusters is Azure Monitor-logboeken ook het aanbevolen hulpprogramma voor azure-platform- en infrastructuurbewaking. Diagnostische gegevens voor Linux-platform vereisen een andere configuratie. Zie Service Fabric Linux-cluster gebeurtenissen in Syslog voor meer informatie.
- U kunt de Azure Monitor-agent configureren voor het verzenden van logboeken van gastbesturingssystemen naar Azure Monitor-logboeken, waar u query's kunt uitvoeren met behulp van Log Analytics.
- U kunt Service Fabric-containerlogboeken schrijven naar stdout of stderr , zodat ze beschikbaar zijn in Azure Monitor-logboeken.
- U kunt de containerbewakingsoplossing voor Azure Monitor-logboeken instellen om container gebeurtenissen weer te geven.
Andere oplossingen voor logboekregistratie
Hoewel de twee oplossingen die we hebben aanbevolen, Azure Monitor-logboeken en Application Insights hebben ingebouwd in integratie met Service Fabric, worden veel gebeurtenissen geschreven via ETW-providers en kunnen ze worden uitgebreid met andere logboekoplossingen. U moet ook kijken naar de Elastic Stack (met name als u een cluster in een offlineomgeving wilt uitvoeren), Dynatrace of een ander platform van uw voorkeur. Zie Azure Service Fabric Monitoring Partners voor een lijst met geïntegreerde partners.
De belangrijkste punten voor elk platform dat u kiest, moeten omvatten hoe comfortabel u bent met de gebruikersinterface, de querymogelijkheden, de beschikbare aangepaste visualisaties en dashboards en de extra hulpprogramma's die ze bieden om uw bewakingservaring te verbeteren.
Azure-activiteitenlogboek
Het activiteitenlogboek bevat gebeurtenissen op abonnementsniveau waarmee bewerkingen voor elke Azure-resource worden bijgehouden, zoals van buiten die resource wordt gezien; Bijvoorbeeld het maken van een nieuwe resource of het starten van een virtuele machine.
Verzameling: gebeurtenissen in activiteitenlogboeken worden automatisch gegenereerd en verzameld in een afzonderlijk archief voor weergave in Azure Portal.
Routering: U kunt activiteitenlogboekgegevens verzenden naar Azure Monitor-logboeken, zodat u deze naast andere logboekgegevens kunt analyseren. Andere locaties, zoals Azure Storage, Azure Event Hubs en bepaalde Microsoft-bewakingspartners, zijn ook beschikbaar. Zie Overzicht van het Azure-activiteitenlogboek voor meer informatie over het routeren van het activiteitenlogboek.
Bewakingsgegevens analyseren
Er zijn veel hulpprogramma's voor het analyseren van bewakingsgegevens.
Azure Monitor-hulpprogramma's
Azure Monitor ondersteunt de volgende basishulpprogramma's:
Metrics Explorer, een hulpprogramma in Azure Portal waarmee u metrische gegevens voor Azure-resources kunt weergeven en analyseren. Zie Metrische gegevens analyseren met Azure Monitor Metrics Explorer voor meer informatie.
Log Analytics, een hulpprogramma in Azure Portal waarmee u logboekgegevens kunt opvragen en analyseren met behulp van de Kusto-querytaal (KQL). Zie Aan de slag met logboekquery's in Azure Monitor voor meer informatie.
Het activiteitenlogboek, dat een gebruikersinterface in Azure Portal heeft voor het weergeven en uitvoeren van basiszoekopdrachten. Als u uitgebreidere analyses wilt uitvoeren, moet u de gegevens routeren naar Azure Monitor-logboeken en complexere query's uitvoeren in Log Analytics.
Hulpprogramma's waarmee complexere visualisaties mogelijk zijn, zijn onder andere:
- Dashboards waarmee u verschillende soorten gegevens kunt combineren in één deelvenster in Azure Portal.
- Werkmappen, aanpasbare rapporten die u kunt maken in Azure Portal. Werkmappen kunnen tekst, metrische gegevens en logboekquery's bevatten.
- Grafana, een open platformhulpprogramma dat excelleert in operationele dashboards. U kunt Grafana gebruiken om dashboards te maken die gegevens uit meerdere andere bronnen dan Azure Monitor bevatten.
- Power BI, een business analytics-service die interactieve visualisaties biedt in verschillende gegevensbronnen. U kunt Power BI zo configureren dat logboekgegevens automatisch vanuit Azure Monitor worden geïmporteerd om te profiteren van deze visualisaties.
Azure Monitor-exporthulpprogramma's
U kunt gegevens uit Azure Monitor ophalen in andere hulpprogramma's met behulp van de volgende methoden:
Metrische gegevens: gebruik de REST API voor metrische gegevens om metrische gegevens te extraheren uit de metrische Azure Monitor-database. De API ondersteunt filterexpressies om de opgehaalde gegevens te verfijnen. Zie azure Monitor REST API-naslaginformatie voor meer informatie.
Logboeken: Gebruik de REST API of de bijbehorende clientbibliotheken.
Een andere optie is het exporteren van werkruimtegegevens.
Als u aan de slag wilt gaan met de REST API voor Azure Monitor, raadpleegt u de stapsgewijze instructies voor Azure Monitoring REST API.
Kusto-query's
U kunt bewakingsgegevens analyseren in de Azure Monitor-logboeken/Log Analytics-opslag met behulp van de Kusto-querytaal (KQL).
Belangrijk
Wanneer u Logboeken selecteert in het menu van de service in de portal, wordt Log Analytics geopend met het querybereik ingesteld op de huidige service. Dit bereik betekent dat logboekquery's alleen gegevens uit dat type resource bevatten. Als u een query wilt uitvoeren die gegevens uit andere Azure-services bevat, selecteert u Logboeken in het menu Azure Monitor . Zie Log-querybereik en tijdsbereik in Azure Monitor Log Analytics voor meer informatie.
Zie de interface voor Log Analytics-query's voor een lijst met algemene query's voor elke service.
Voorbeeldquery's
De volgende query's retourneren Service Fabric-gebeurtenissen, inclusief acties op knooppunten. Zie Service Fabric-gebeurtenissen voor andere nuttige query's.
Operationele gebeurtenissen retourneren die zijn vastgelegd in het afgelopen uur:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Retourstatusrapporten met HealthState == 3 (Fout) en extraheer meer eigenschappen uit het EventMessage veld:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Operationele Service Fabric-gebeurtenissen ophalen die zijn geaggregeerd met de specifieke service en het specifieke knooppunt:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Waarschuwingen
Azure Monitor-waarschuwingen melden u proactief wanneer er specifieke voorwaarden worden gevonden in uw bewakingsgegevens. Met waarschuwingen kunt u problemen in uw systeem identificeren en oplossen voordat uw klanten ze opmerken. Zie Azure Monitor-waarschuwingen voor meer informatie.
Er zijn veel bronnen van algemene waarschuwingen voor Azure-resources. Zie Voorbeeldquery's voor logboekwaarschuwingen voor voorbeelden van veelvoorkomende waarschuwingen voor Azure-resources. De site Azure Monitor Baseline Alerts (AMBA) biedt een semi-geautomatiseerde methode voor het implementeren van belangrijke metrische platformwaarschuwingen, dashboards en richtlijnen. De site is van toepassing op een voortdurend uitbreidende subset van Azure-services, inclusief alle services die deel uitmaken van de Azure Landing Zone (ALZ).
Het algemene waarschuwingsschema standaardiseert het verbruik van Azure Monitor-waarschuwingsmeldingen. Zie Algemeen waarschuwingsschema voor meer informatie.
Typen waarschuwingen
U kunt een waarschuwing ontvangen voor elke metrische gegevensbron of logboekgegevensbron in het Azure Monitor-gegevensplatform. Er zijn veel verschillende typen waarschuwingen, afhankelijk van de services die u bewaakt en de bewakingsgegevens die u verzamelt. Verschillende typen waarschuwingen hebben verschillende voordelen en nadelen. Zie Het juiste waarschuwingstype voor bewaking kiezen voor meer informatie.
In de volgende lijst worden de typen Azure Monitor-waarschuwingen beschreven die u kunt maken:
- Metrische waarschuwingen evalueren met regelmatige tussenpozen resourcegegevens. Metrische gegevens kunnen metrische platformgegevens, aangepaste metrische gegevens, logboeken van Azure Monitor zijn geconverteerd naar metrische gegevens of metrische Gegevens van Application Insights. Metrische waarschuwingen kunnen ook meerdere voorwaarden en dynamische drempelwaarden toepassen.
- Met logboekwaarschuwingen kunnen gebruikers een Log Analytics-query gebruiken om resourcelogboeken met een vooraf gedefinieerde frequentie te evalueren.
- Waarschuwingen voor activiteitenlogboeken worden geactiveerd wanneer een nieuwe gebeurtenis van het activiteitenlogboek plaatsvindt die overeenkomt met gedefinieerde voorwaarden. Resource Health-waarschuwingen en Service Health-waarschuwingen zijn waarschuwingen voor activiteitenlogboeken die rapporteren over uw service en resourcestatus.
Sommige Azure-services ondersteunen ook waarschuwingen voor slimme detectie, Prometheus-waarschuwingen of aanbevolen waarschuwingsregels.
Voor sommige services kunt u op schaal bewaken door dezelfde waarschuwingsregel voor metrische gegevens toe te passen op meerdere resources van hetzelfde type dat in dezelfde Azure-regio aanwezig is. Afzonderlijke meldingen worden verzonden voor elke bewaakte resource. Zie Meerdere resources bewaken met één waarschuwingsregel voor ondersteunde Azure-services en -clouds.
Service Fabric-waarschuwingsregels
De volgende tabel bevat enkele waarschuwingsregels voor Service Fabric. Deze waarschuwingen zijn slechts voorbeelden. U kunt waarschuwingen instellen voor elke vermelding van metrische gegevens, logboekvermeldingen of activiteitenlogboeken die worden vermeld in de service Fabric-controlegegevensverwijzing of de lijst met Service Fabric-gebeurtenissen.
| Waarschuwingstype | Voorwaarde | Beschrijving |
|---|---|---|
| Knooppunt gebeurtenis | Knooppunt gaat omlaag | ServiceFabricOperationalEvent waarbij EventID >= 25622 en EventID <= 25626. Deze gebeurtenis-id's vindt u in de verwijzing naar knooppuntgebeurtenissen. |
| Toepassingsevenement | Terugdraaien van toepassingsupgrade | ServiceFabricOperationalEvent waarbij EventID == 29623 of EventID == 29624. Deze gebeurtenis-id's vindt u in de naslaginformatie over toepassingsgebeurtenissen. |
| Status van resources | Upgradeservice onbereikbaar/niet beschikbaar | Het cluster gaat naar de status UpgradeServiceUnreachable. |
Advisor-aanbevelingen
Voor sommige services, als er kritieke omstandigheden of aanstaande wijzigingen optreden tijdens resourcebewerkingen, wordt een waarschuwing weergegeven op de pagina Serviceoverzicht in de portal. Meer informatie en aanbevolen oplossingen voor de waarschuwing vindt u in Advisor-aanbevelingen onder Bewaking in het linkermenu. Tijdens normale bewerkingen worden er geen aanbevelingen van advisor weergegeven.
Zie het overzicht van Azure Advisor voor meer informatie over Azure Advisor.
Aanbevolen installatie
Nu we elk gebied van bewaking en voorbeeldscenario's hebben doorlopen, vindt u hier een overzicht van de Azure-bewakingshulpprogramma's en hebt u deze nodig om alle bovenstaande gebieden te bewaken.
- Toepassingsbewaking met Application Insights
- Clusterbewaking met diagnostische agent en Azure Monitor-logboeken
- Infrastructuurbewaking met Azure Monitor-logboeken
U kunt ook de ARM-voorbeeldsjabloon gebruiken en wijzigen om de implementatie van alle benodigde resources en agents te automatiseren.
Gerelateerde inhoud
- Raadpleeg de naslaginformatie over bewakingsgegevens van Service Fabric voor een verwijzing naar de metrische gegevens, logboeken en andere belangrijke waarden die zijn gemaakt voor Service Fabric.
- Zie Azure-resources bewaken met Azure Monitor voor algemene informatie over het bewaken van Azure-resources.
- Zie de lijst met Service Fabric-gebeurtenissen.