Defragmentatie van metrische gegevens en belasting in Service Fabric
Het Service Fabric-cluster Resource Manager standaardstrategie voor het beheren van metrische belastinggegevens in het cluster is het verdelen van de belasting. Door ervoor te zorgen dat knooppunten gelijkmatig worden gebruikt, voorkomt u warme en koude plekken die leiden tot conflicten en verspilde resources. Het distribueren van workloads in het cluster is ook het veiligst als het gaat om het overleven van fouten, omdat het ervoor zorgt dat een storing geen groot percentage van een bepaalde workload overneemt.
Het Service Fabric-cluster Resource Manager ondersteunt een andere strategie voor het beheren van de belasting, namelijk defragmentatie. Defragmentatie betekent dat in plaats van te proberen het gebruik van een metrische waarde over het cluster te verdelen, het wordt geconsolideerd. Consolidatie is slechts een omkering van de standaardverdelingsstrategie. In plaats van de gemiddelde standaarddeviatie van de metrische belasting te minimaliseren, probeert de Cluster-Resource Manager deze te verhogen.
Wanneer gebruikt u defragmentatie?
Het distribueren van belasting in het cluster verbruikt een aantal resources op elk knooppunt. Sommige workloads maken services die uitzonderlijk groot zijn en de meeste of alle knooppunten verbruiken. In dergelijke gevallen is het mogelijk dat wanneer er grote workloads worden gemaakt, er onvoldoende ruimte is op een knooppunt om ze uit te voeren. Grote workloads zijn geen probleem in Service Fabric; in deze gevallen bepaalt de cluster-Resource Manager dat het cluster opnieuw moet worden indelen om ruimte te maken voor deze grote werkbelasting. In de tussentijd moet die workload echter wachten om te worden gepland in het cluster.
Als er veel services en statussen zijn om te verplaatsen, kan het lang duren voordat de grote workload in het cluster wordt geplaatst. Dit is waarschijnlijker als andere workloads in het cluster ook groot zijn en het dus langer duurt om opnieuw in te delen. Het Service Fabric-team heeft de aanmaaktijden gemeten in simulaties van dit scenario. We hebben vastgesteld dat het maken van grote services veel langer duurde zodra het clustergebruik tussen 30% en 50% hoger kwam. Om dit scenario af te handelen, hebben we defragmentatie geïntroduceerd als een balanceringsstrategie. We hebben vastgesteld dat voor grote workloads, met name wanneer de aanmaaktijd belangrijk was, defragmentatie er echt toe heeft bijgedragen dat deze nieuwe workloads in het cluster worden gepland.
U kunt metrische gegevens over defragmentatie configureren om de Cluster-Resource Manager proactief te proberen de belasting van de services te reduceren tot minder knooppunten. Dit zorgt ervoor dat er bijna altijd ruimte is voor grote services zonder het cluster te reorganiseren. Als u het cluster niet opnieuw hoeft te organiseren, kunt u snel grote workloads maken.
De meeste mensen hebben geen defragmentatie nodig. Services zijn meestal klein, dus het is niet moeilijk om er ruimte voor te vinden in het cluster. Wanneer reorganisatie mogelijk is, gaat dit snel, ook omdat de meeste services klein zijn en snel en parallel kunnen worden verplaatst. Als u echter grote services hebt en deze snel wilt maken, is de defragmentatiestrategie iets voor u. Hierna bespreken we de compromissen van het gebruik van defragmentatie.
Compromissen voor defragmentatie
Defragmentatie kan de impact van fouten vergroten, omdat er meer services worden uitgevoerd op knooppunten die mislukken. Defragmentatie kan ook de kosten verhogen, omdat resources in het cluster in reserve moeten worden bewaard in afwachting van het maken van grote workloads.
Het volgende diagram geeft een visuele weergave van twee clusters, één die is gedefragmenteerd en één die niet.
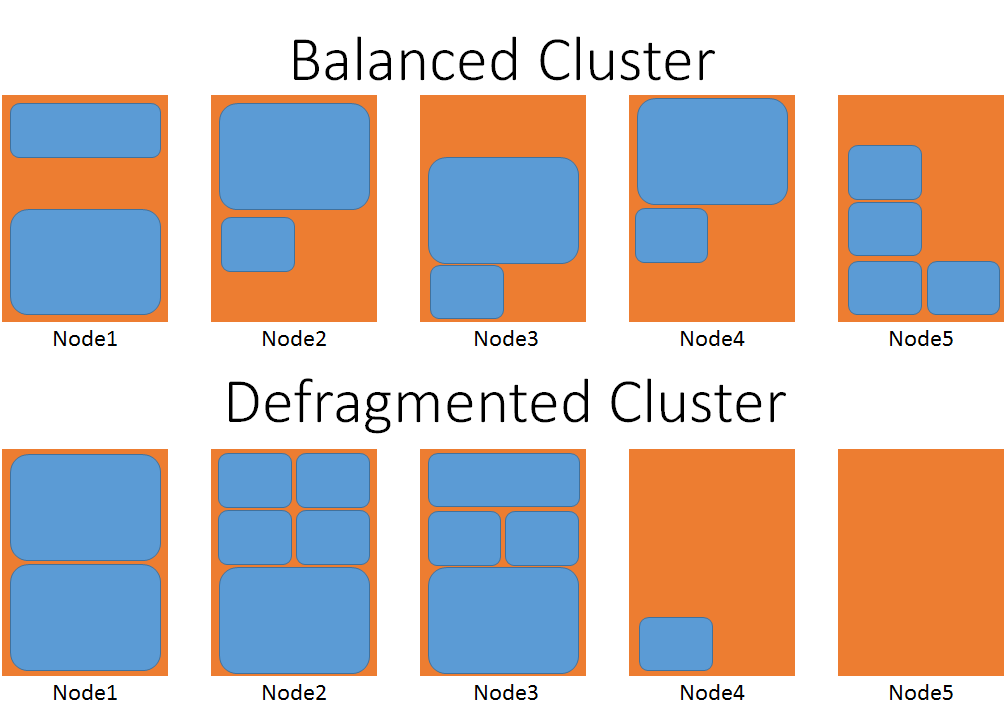
Houd in het evenwichtige geval rekening met het aantal verplaatsingen dat nodig is om een van de grootste serviceobjecten te plaatsen. In het gedefragmenteerde cluster kan de grote workload worden geplaatst op knooppunten vier of vijf zonder te hoeven wachten tot andere services worden verplaatst.
Voor- en nadelen van defragmentatie
Wat zijn die andere conceptuele compromissen? Hier volgt een korte tabel met aandachtspunten:
| Defragmentatie pros | Defragmentatie cons |
|---|---|
| Maakt het sneller maken van grote services mogelijk | De belasting wordt geconcentreerd op minder knooppunten, waardoor de conflicten toenemen |
| Maakt een lagere gegevensverplaatsing mogelijk tijdens het maken | Fouten kunnen van invloed zijn op meer services en meer verloop veroorzaken |
| Maakt een uitgebreide beschrijving van vereisten en het vrijmaken van ruimte mogelijk | Complexere algemene resourcebeheerconfiguratie |
U kunt gedefragmenteerde en normale metrische gegevens combineren in hetzelfde cluster. De Cluster-Resource Manager probeert de metrische gegevens voor defragmentatie zoveel mogelijk te consolideren terwijl de andere gegevens worden uitgespreid. De resultaten van het combineren van defragmentatie- en balanceringsstrategieën zijn afhankelijk van verschillende factoren, waaronder:
- het aantal metrische balansgegevens versus het aantal metrische defragmentatiegegevens
- Of een service beide typen metrische gegevens gebruikt
- de metrische gewichten
- huidige metrische belasting
Experimenten zijn vereist om de exacte configuratie te bepalen die nodig is. We raden u aan uw workloads grondig te meten voordat u metrische defragmentatiegegevens inschakelt in productie. Dit geldt met name voor het combineren van defragmentatie en evenwichtige metrische gegevens binnen dezelfde service.
Metrische defragmentatiegegevens configureren
Het configureren van metrische defragmentatiegegevens is een globale beslissing in het cluster en afzonderlijke metrische gegevens kunnen worden geselecteerd voor defragmentatie. De volgende configuratiefragmenten laten zien hoe u metrische gegevens voor defragmentatie configureert. In dit geval wordt 'Metric1' geconfigureerd als een metrische waarde voor defragmentatie, terwijl 'Metric2' normaal wordt verdeeld.
ClusterManifest.xml:
<Section Name="DefragmentationMetrics">
<Parameter Name="Metric1" Value="true" />
<Parameter Name="Metric2" Value="false" />
</Section>
via ClusterConfig.json voor zelfstandige implementaties of Template.json voor door Azure gehoste clusters:
"fabricSettings": [
{
"name": "DefragmentationMetrics",
"parameters": [
{
"name": "Metric1",
"value": "true"
},
{
"name": "Metric2",
"value": "false"
}
]
}
]
Volgende stappen
- De cluster Resource Manager heeft veel opties voor het beschrijven van het cluster. Raadpleeg dit artikel over het beschrijven van een Service Fabric-cluster voor meer informatie hierover
- Metrische gegevens zijn de wijze waarop het Service Fabric-clusterresourcebeheer het verbruik en de capaciteit in het cluster beheert. Raadpleeg dit artikel voor meer informatie over metrische gegevens en hoe u deze configureert