Resourceverbruik beheren en laden in Service Fabric met metrische gegevens
Metrische gegevens zijn de resources die uw services belangrijk maken en die worden geleverd door de knooppunten in het cluster. Een metrische waarde is alles wat u wilt beheren om de prestaties van uw services te verbeteren of te bewaken. U kunt bijvoorbeeld het geheugenverbruik bekijken om te weten of uw service overbelast is. Een ander gebruik is om erachter te komen of de service elders kan worden verplaatst waar het geheugen minder beperkt is om betere prestaties te krijgen.
Dingen zoals geheugen, schijf en CPU-gebruik zijn voorbeelden van metrische gegevens. Deze metrische gegevens zijn fysieke metrische gegevens, resources die overeenkomen met fysieke resources op het knooppunt dat moet worden beheerd. Metrische gegevens kunnen ook logische metrische gegevens (en meestal) zijn. Logische metrische gegevens zijn bijvoorbeeld 'MyWorkQueueDepth' of 'MessagesToProcess' of 'TotalRecords'. Logische metrische gegevens zijn door de toepassing gedefinieerd en komen indirect overeen met een bepaald gebruik van fysieke resources. Logische metrische gegevens zijn gebruikelijk omdat het lastig kan zijn om het verbruik van fysieke resources per service te meten en te rapporteren. De complexiteit van het meten en rapporteren van uw eigen fysieke metrische gegevens is ook waarom Service Fabric enkele standaard metrische gegevens biedt.
Standaardmetrieken
Stel dat u aan de slag wilt met het schrijven en implementeren van uw service. Op dit moment weet u niet welke fysieke of logische resources worden gebruikt. Dat is prima. Service Fabric Cluster Resource Manager maakt gebruik van enkele standaard metrische gegevens wanneer er geen andere metrische gegevens worden opgegeven. Dit zijn:
- PrimaryCount - aantal primaire replica's op het knooppunt
- ReplicaCount : het aantal totale stateful replica's op het knooppunt
- Count - telling van alle serviceobjecten (staatloos en stateful) op het knooppunt
| Metrische gegevens | Stateless Instance Load | Stateful secundaire belasting | Stateful primaire belasting | Gewicht |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | Hoog |
| ReplicaCount | 0 | 1 | 1 | Gemiddeld |
| Tellen | 1 | 1 | 1 | Beperkt |
Voor basisworkloads bieden de standaardgegevens een fatsoenlijke verdeling van werk in het cluster. In het volgende voorbeeld kijken we wat er gebeurt wanneer we twee services maken en afhankelijk zijn van de standaard metrische gegevens voor taakverdeling. De eerste service is een stateful service met drie partities en een doelreplicasetgrootte van drie. De tweede service is een stateless service met één partitie en een aantal exemplaren van drie.
Dit zijn de onderdelen:
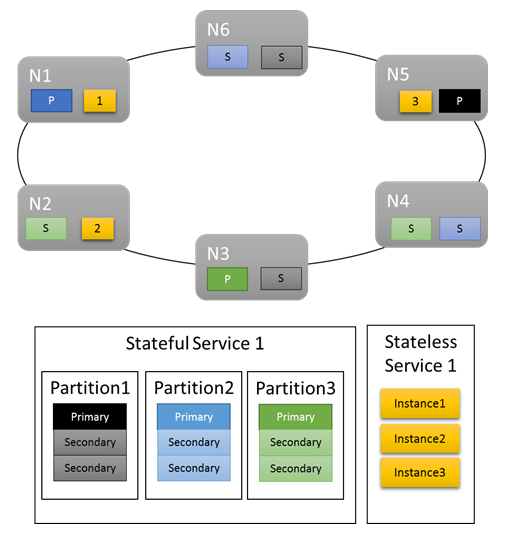
Enkele dingen die u moet noteren:
- Primaire replica's voor de stateful service worden verdeeld over verschillende knooppunten
- Replica's voor dezelfde partitie bevinden zich op verschillende knooppunten
- Het totale aantal primaries en secundaire bestanden wordt gedistribueerd in het cluster
- Het totale aantal serviceobjecten wordt gelijkmatig toegewezen op elk knooppunt
Goed!
De standaard metrische gegevens werken prima als begin. De standaardgegevens bevatten echter alleen u tot nu toe. Bijvoorbeeld: Wat is de kans dat het partitioneringsschema dat u hebt gekozen, resulteert in perfect gelijkmatig gebruik door alle partities? Wat is de kans dat de belasting voor een bepaalde service in de loop van de tijd constant is, of zelfs precies hetzelfde over meerdere partities op dit moment?
U kunt uitvoeren met alleen de standaard metrische gegevens. Dit betekent echter meestal dat het clustergebruik lager en ongelijk is dan u wilt. Dit komt doordat de standaard metrische gegevens niet adaptief zijn en ervan uitgaan dat alles gelijk is. Een primaire die bezet is en een primaire die niet beide '1' bijdraagt aan de metrische waarde PrimaryCount. In het ergste geval kan het gebruik van alleen de standaard metrische gegevens ook leiden tot te veel geplande knooppunten, wat resulteert in prestatieproblemen. Als u geïnteresseerd bent in het optimaal benutten van uw cluster en prestatieproblemen wilt voorkomen, moet u aangepaste metrische gegevens en dynamische belastingrapportage gebruiken.
Aangepaste meetwaarden
Metrische gegevens worden geconfigureerd per service-exemplaar wanneer u de service maakt.
Een metrische waarde heeft enkele eigenschappen die deze beschrijven: een naam, een gewicht en een standaardbelasting.
- Metrische naam: de naam van de metrische waarde. De naam van de metrische waarde is een unieke id voor de metrische gegevens in het cluster vanuit het perspectief van Resource Manager.
Notitie
Naam van aangepaste metrische gegevens mag geen van de namen van de systeemgegevens zijn, zoals servicefabric:/_CpuCores of servicefabric:/_MemoryInMB omdat dit kan leiden tot niet-gedefinieerd gedrag. Vanaf Service Fabric versie 9.1 wordt voor bestaande services met deze aangepaste metrische namen een statuswaarschuwing afgegeven om aan te geven dat de metrische naam onjuist is.
- Gewicht: Metrische gewicht bepaalt hoe belangrijk deze metrische waarde is ten opzichte van de andere metrische gegevens voor deze service.
- Standaardbelasting: de standaardbelasting wordt anders weergegeven, afhankelijk van of de service staatloos of stateful is.
- Voor stateless services heeft elke metriek één eigenschap met de naam DefaultLoad
- Voor stateful services die u definieert:
- PrimaryDefaultLoad: de standaardhoeveelheid van deze metrische waarde die door deze service wordt gebruikt wanneer het een primaire waarde is
- SecondaryDefaultLoad: de standaardhoeveelheid van deze metrische waarde die door deze service wordt gebruikt wanneer het een secundaire waarde is
Notitie
Als u aangepaste metrische gegevens definieert en u ook de standaard metrische gegevens wilt gebruiken, moet u expliciet de standaard metrische gegevens toevoegen en gewichten en waarden voor deze metrische gegevens definiëren. Dit komt doordat u de relatie tussen de standaard metrische gegevens en uw aangepaste metrische gegevens moet definiëren. Misschien geeft u bijvoorbeeld om ConnectionCount of WorkQueueDepth meer dan primaire distributie. Standaard is het gewicht van de metric PrimaryCount Hoog, dus u wilt deze verlagen tot Gemiddeld wanneer u uw andere metrische gegevens toevoegt om ervoor te zorgen dat deze prioriteit krijgen.
Metrische gegevens voor uw service definiëren - een voorbeeld
Stel dat u de volgende configuratie wilt:
- Uw service rapporteert een metrische waarde met de naam ConnectionCount
- U wilt ook de standaard metrische gegevens gebruiken
- U hebt enkele metingen uitgevoerd en weet dat normaal gesproken een primaire replica van die service 20 eenheden van 'ConnectionCount' in beslag neemt
- Secondaries gebruiken 5 eenheden van 'ConnectionCount'
- U weet dat ConnectionCount de belangrijkste metrische waarde is voor het beheren van de prestaties van deze specifieke service
- U wilt nog steeds dat primaire replica's evenwichtig zijn. Het verdelen van primaire replica's is over het algemeen een goed idee, ongeacht wat. Dit helpt voorkomen dat het verlies van een knooppunt of foutdomein invloed heeft op een meerderheid van de primaire replica's, samen met het domein.
- Anders zijn de standaardgegevens prima
Hier volgt de code die u schrijft om een service te maken met die metrische configuratie:
Code:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Notitie
De bovenstaande voorbeelden en de rest van dit document beschrijven het beheren van metrische gegevens per benoemde service. Het is ook mogelijk om metrische gegevens voor uw services op servicetypeniveau te definiëren. Dit wordt bereikt door ze op te geven in uw servicemanifesten. Het definiëren van metrische gegevens op typeniveau wordt om verschillende redenen niet aanbevolen. De eerste reden is dat namen van metrische gegevens vaak omgevingsspecifiek zijn. Tenzij er een vast contract is, kunt u er niet zeker van zijn dat de metrische waarde Cores in één omgeving niet 'MiliCores' of 'CoReS' in andere omgevingen is. Als uw metrische gegevens zijn gedefinieerd in uw manifest, moet u nieuwe manifesten per omgeving maken. Dit leidt meestal tot een verspreiding van verschillende manifesten met slechts kleine verschillen, wat kan leiden tot beheerproblemen.
Metrische belastingen worden doorgaans per service-exemplaar toegewezen. Stel dat u één exemplaar van de service maakt voor CustomerA die deze slechts licht wil gebruiken. Stel ook dat u een andere maakt voor CustomerB die een grotere workload heeft. In dit geval wilt u waarschijnlijk de standaardbelastingen voor deze services aanpassen. Als u metrische gegevens en belastingen hebt gedefinieerd via manifesten en u dit scenario wilt ondersteunen, zijn voor elke klant verschillende toepassings- en servicetypen vereist. De waarden die tijdens het maken van de service zijn gedefinieerd, overschrijven de waarden die in het manifest zijn gedefinieerd, zodat u deze kunt gebruiken om de specifieke standaardwaarden in te stellen. Dit zorgt er echter voor dat de waarden die in de manifesten zijn gedeclareerd, niet overeenkomen met de waarden waarmee de service daadwerkelijk wordt uitgevoerd. Dit kan tot verwarring leiden.
Ter herinnering: als u alleen de standaardgegevens wilt gebruiken, hoeft u de verzameling met metrische gegevens helemaal niet aan te raken of iets speciaals te doen bij het maken van uw service. De standaard metrische gegevens worden automatisch gebruikt wanneer er geen andere gegevens worden gedefinieerd.
Laten we nu elk van deze instellingen in meer detail doorlopen en praten over het gedrag dat het beïnvloedt.
Laden
Het hele punt van het definiëren van metrische gegevens is het weergeven van een bepaalde belasting. Laden is hoeveel van een bepaalde metrische waarde wordt verbruikt door een service-exemplaar of replica op een bepaald knooppunt. De belasting kan op vrijwel elk moment worden geconfigureerd. Voorbeeld:
- Laden kan worden gedefinieerd wanneer een service wordt gemaakt. Dit type belastingconfiguratie wordt standaardbelasting genoemd.
- De metrische gegevens, inclusief standaardbelastingen, voor een service kunnen worden bijgewerkt nadat de service is gemaakt. Deze metrische update wordt uitgevoerd door een service bij te werken.
- De belastingen voor een bepaalde partitie kunnen opnieuw worden ingesteld op de standaardwaarden voor die service. Deze metrische update wordt het opnieuw instellen van de partitiebelasting genoemd.
- De belasting kan dynamisch tijdens runtime worden gerapporteerd per serviceobject. Deze metrische update wordt rapportagebelasting genoemd.
- Laden voor replica's of exemplaren van partities kan ook worden bijgewerkt door belastingswaarden te rapporteren via een Fabric-API-aanroep. Deze metrische update wordt de rapportagebelasting voor een partitie genoemd.
Al deze strategieën kunnen gedurende de levensduur van dezelfde service worden gebruikt.
Standaardbelasting
Standaardbelasting is hoeveel van de metrische gegevens elk serviceobject (staatloze instantie of stateful replica) van deze service verbruikt. Het clusterbronbeheer gebruikt dit nummer voor de belasting van het serviceobject totdat er andere informatie wordt ontvangen, zoals een rapport voor dynamische belasting. Voor eenvoudigere services is de standaardbelasting een statische definitie. De standaardbelasting wordt nooit bijgewerkt en wordt gebruikt voor de levensduur van de service. Standaardbelastingen werken uitstekend voor eenvoudige scenario's voor capaciteitsplanning waarbij bepaalde hoeveelheden resources zijn toegewezen aan verschillende workloads en niet veranderen.
Notitie
Zie dit artikel voor meer informatie over capaciteitsbeheer en het definiëren van capaciteiten voor de knooppunten in uw cluster.
Met Cluster Resource Manager kunnen stateful services een andere standaardbelasting opgeven voor hun Primaries en Secondaries. Stateless services kunnen slechts één waarde opgeven die van toepassing is op alle exemplaren. Voor stateful services is de standaardbelasting voor primaire en secundaire replica's doorgaans anders, omdat replica's verschillende soorten werk doen in elke rol. Primaries dienen bijvoorbeeld meestal zowel lees- als schrijfbewerkingen en verwerken de meeste rekenkundige lasten, terwijl secundaire bestanden dat niet doen. Meestal is de standaardbelasting voor een primaire replica hoger dan de standaardbelasting voor secundaire replica's. De reële getallen moeten afhankelijk zijn van uw eigen metingen.
Dynamische belasting
Stel dat u uw service al een tijdje uitvoert. Met enige controle hebt u gemerkt dat:
- Sommige partities of exemplaren van een bepaalde service verbruiken meer resources dan andere
- Sommige services hebben belasting die in de loop van de tijd varieert.
Er zijn veel dingen die dit soort belastingschommelingen kunnen veroorzaken. Verschillende services of partities zijn bijvoorbeeld gekoppeld aan verschillende klanten met verschillende vereisten. De belasting kan ook veranderen omdat de hoeveelheid werk die de service gedurende de dag uitvoert, varieert. Ongeacht de reden is er meestal geen enkel getal dat u standaard kunt gebruiken. Dit geldt vooral als u het meeste gebruik van het cluster wilt krijgen. Elke waarde die u kiest voor standaardbelasting, is een deel van de tijd onjuist. Onjuiste standaardbelastingen resulteren in clusterbronbeheer via of onder het toewijzen van resources. Als gevolg hiervan hebt u knooppunten die te veel of minder worden gebruikt, ook al denkt clusterbronbeheer dat het cluster evenwichtig is. Standaardbelastingen zijn nog steeds goed omdat ze wat informatie bieden voor de eerste plaatsing, maar ze zijn geen volledig verhaal voor echte workloads. Om de veranderende resourcevereisten nauwkeurig vast te leggen, staat Cluster Resource Manager elk serviceobject toe om tijdens runtime een eigen belasting bij te werken. Dit wordt dynamische belastingrapportage genoemd.
Met dynamische belastingrapporten kunnen replica's of exemplaren hun toewijzing/gerapporteerde belasting van metrische gegevens gedurende hun levensduur aanpassen. Een servicereplica of een exemplaar dat koud was en geen werk zou doen, rapporteert meestal dat er lage hoeveelheden van een bepaalde metrische waarde worden gebruikt. Een bezet replica of exemplaar rapporteert dat ze meer gebruiken.
Met rapportagebelasting per replica of exemplaar kan Cluster Resource Manager de afzonderlijke serviceobjecten in het cluster opnieuw organiseren. Het opnieuw ordenen van de services zorgt ervoor dat ze de resources krijgen die ze nodig hebben. Bezet-services krijgen effectief toegang tot resources van andere replica's of exemplaren die momenteel koud zijn of minder werk doen.
Binnen Reliable Services ziet de code voor het dynamisch laden van rapporten er als volgt uit:
Code:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Een service kan tijdens het maken rapporteren over alle metrische gegevens die hiervoor zijn gedefinieerd. Als een service een belasting rapporteert voor een metrische waarde die niet is geconfigureerd voor gebruik, negeert Service Fabric dat rapport. Als er andere metrische gegevens op hetzelfde moment zijn gerapporteerd die geldig zijn, worden deze rapporten geaccepteerd. Servicecode kan alle metrische gegevens meten en rapporteren, en operators kunnen de configuratie van de metrische gegevens opgeven die moeten worden gebruikt zonder dat de servicecode hoeft te worden gewijzigd.
Rapportagebelasting voor een partitie
In de vorige sectie wordt beschreven hoe servicereplica's of exemplaren zichzelf laden. Er is een extra optie voor het dynamisch rapporteren van belasting voor de replica's of exemplaren van een partitie via de Service Fabric-API. Wanneer de belasting voor een partitie wordt gerapporteerd, kunt u rapporteren voor meerdere partities tegelijk.
Deze rapporten worden op exact dezelfde manier gebruikt als het laden van rapporten die afkomstig zijn van de replica's of exemplaren zelf. Gerapporteerde waarden zijn geldig totdat nieuwe laadwaarden worden gerapporteerd door de replica of het exemplaar of door een nieuwe belastingswaarde voor een partitie te rapporteren.
Met deze API zijn er meerdere manieren om de belasting in het cluster bij te werken:
- Een stateful servicepartitie kan de primaire replicabelasting bijwerken.
- Zowel stateless als stateful services kunnen de belasting van alle secundaire replica's of exemplaren bijwerken.
- Zowel stateless als stateful services kunnen de belasting van een specifieke replica of instantie op een knooppunt bijwerken.
Het is ook mogelijk om deze updates per partitie tegelijkertijd te combineren. Combinatie van belastingsupdates voor een bepaalde partitie moet worden opgegeven via het object PartitionMetricLoadDescription, dat de bijbehorende lijst met laadupdates kan bevatten, zoals wordt weergegeven in het onderstaande voorbeeld. Laadupdates worden weergegeven via de object MetricLoadDescription, die de huidige of voorspelde belastingswaarde voor een metrische waarde kan bevatten, die is opgegeven met een metrische naam.
Notitie
Voorspelde waarden voor metrische belasting is momenteel een preview-functie. Hiermee kunnen voorspelde laadwaarden worden gerapporteerd en gebruikt aan de kant van Service Fabric, maar die functie is momenteel niet ingeschakeld.
Het bijwerken van de belasting voor meerdere partities is mogelijk met één API-aanroep. In dat geval bevat de uitvoer een antwoord per partitie. Als de partitie-update om welke reden dan ook niet is toegepast, worden updates voor die partitie overgeslagen en worden de bijbehorende foutcode voor een doelpartitie verstrekt:
- PartitionNotFound - opgegeven partitie-id bestaat niet.
- ReconfigurationPending - Partition wordt momenteel opnieuw geconfigureerd.
- InvalidForStatelessServices: er is geprobeerd de belasting van een primaire replica te wijzigen voor een partitie die deel uitmaakt van een stateless service.
- ReplicaDoesNotExist - Secundaire replica of instantie bestaat niet op een opgegeven knooppunt.
- InvalidOperation: kan in twee gevallen optreden: het bijwerken van de belasting voor een partitie die deel uitmaakt van de systeemtoepassing of het bijwerken van voorspelde belasting is niet ingeschakeld.
Als sommige van deze fouten worden geretourneerd, kunt u de invoer voor een specifieke partitie bijwerken en de update opnieuw proberen.
Code:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
In dit voorbeeld voert u een update uit van de laatst gerapporteerde belasting voor een partitie 53df3d7f-5471-403b-b736-bde6ad584f42. De primaire replicabelasting voor een metrische CustomMetricName0 wordt bijgewerkt met de waarde 100. Tegelijkertijd wordt de belasting voor dezelfde metrische waarde voor een specifieke secundaire replica op het knooppunt NodeName0 bijgewerkt met de waarde 200.
De metrische configuratie van een service bijwerken
De lijst met metrische gegevens die zijn gekoppeld aan de service en de eigenschappen van deze metrische gegevens kunnen dynamisch worden bijgewerkt terwijl de service live is. Dit maakt experimenten en flexibiliteit mogelijk. Enkele voorbeelden van wanneer dit nuttig is, zijn:
- het uitschakelen van een metrische waarde met een buggy-rapport voor een bepaalde service
- het gewicht van metrische gegevens opnieuw configureren op basis van gewenst gedrag
- een nieuwe metriek alleen inschakelen nadat de code al is geïmplementeerd en gevalideerd via andere mechanismen
- de standaardbelasting voor een service wijzigen op basis van waargenomen gedrag en verbruik
De belangrijkste API's voor het wijzigen van de metrische configuratie bevinden zich FabricClient.ServiceManagementClient.UpdateServiceAsync in C# en Update-ServiceFabricService in PowerShell. Alle gegevens die u met deze API's opgeeft, vervangen de bestaande metrische gegevens voor de service onmiddellijk.
Standaardbelastingswaarden en dynamische belastingsrapporten combineren
Standaardbelasting en dynamische belastingen kunnen worden gebruikt voor dezelfde service. Wanneer een service zowel rapporten voor standaardbelasting als dynamische belasting gebruikt, fungeert de standaardbelasting als een schatting totdat dynamische rapporten worden weergegeven. De standaardbelasting is goed omdat het Cluster Resource Manager iets geeft om mee te werken. Met de standaardbelasting kan Cluster Resource Manager de serviceobjecten op goede locaties plaatsen wanneer ze worden gemaakt. Als er geen standaardinformatie over belasting wordt verstrekt, is de plaatsing van services in feite willekeurig. Wanneer het laden van rapporten later aankomt, is de eerste willekeurige plaatsing vaak onjuist en moet de Cluster Resource Manager services verplaatsen.
Laten we eens kijken wat er gebeurt wanneer we aangepaste metrische gegevens en dynamische belastingrapportage toevoegen. In dit voorbeeld gebruiken we MemoryInMb als voorbeeldmetriek.
Notitie
Geheugen is een van de metrische systeemgegevens die Service Fabric kan beheren en rapportage zelf is doorgaans moeilijk. We verwachten niet dat u rapporteert over geheugenverbruik; Geheugen wordt hier gebruikt als hulpmiddel bij het leren over de mogelijkheden van Cluster Resource Manager.
Stel dat we de stateful service in eerste instantie hebben gemaakt met de volgende opdracht:
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Ter herinnering: deze syntaxis is ('MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad').
Laten we eens kijken hoe een mogelijke clusterindeling eruit kan zien:
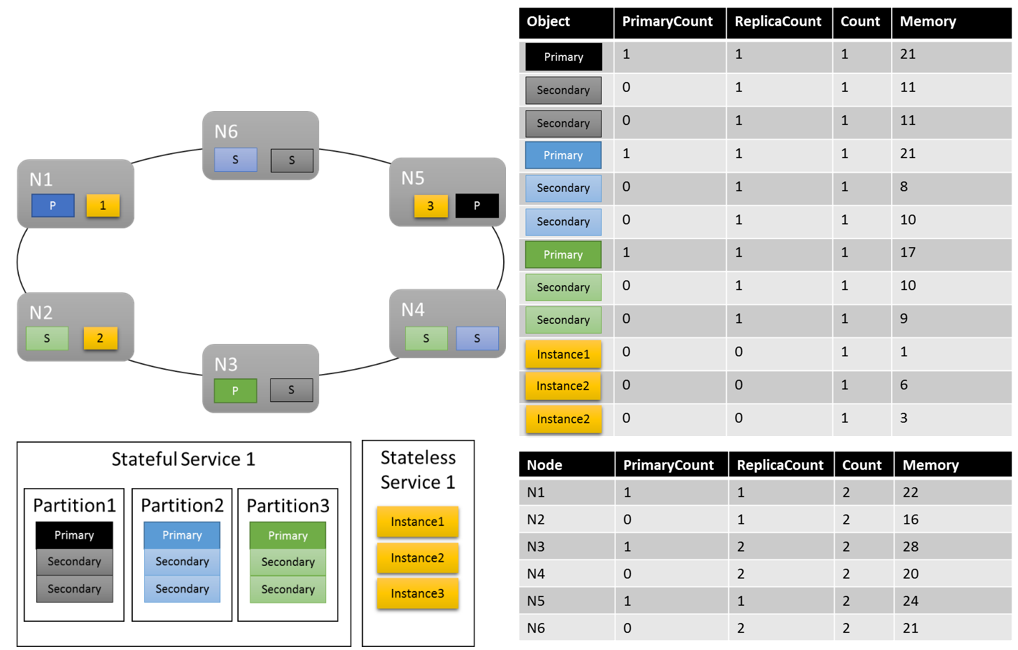
Enkele dingen die de moeite waard zijn om te noteren:
- Secundaire replica's binnen een partitie kunnen elk hun eigen belasting hebben
- Over het algemeen zien de metrische gegevens er evenwichtig uit. Voor geheugen is de verhouding tussen de maximale en minimale belasting 1,75 (het knooppunt met de meeste belasting is N3, het minste N2 en 28/16 = 1,75).
Er zijn nog enkele dingen die we nog moeten uitleggen:
- Wat is bepaald of een verhouding van 1,75 redelijk was of niet? Hoe weet clusterbronbeheer of dat goed genoeg is of als er meer werk te doen is?
- Wanneer treedt er een taakverdeling op?
- Wat betekent het dat geheugen 'Hoog' is gewogen?
Metrische gewichten
Het bijhouden van dezelfde metrische gegevens in verschillende services is belangrijk. In deze globale weergave kan Cluster Resource Manager het verbruik in het cluster bijhouden, het verbruik verdelen over knooppunten en ervoor zorgen dat knooppunten geen capaciteit overslaan. Services kunnen echter verschillende weergaven hebben met betrekking tot het belang van dezelfde metrische gegevens. In een cluster met veel metrische gegevens en veel services bestaan mogelijk niet alle metrische gegevens. Hoe moet Cluster Resource Manager deze situaties afhandelen?
Metrische gewichten kunnen clusterresourcebeheer bepalen hoe het cluster moet worden afgestemd wanneer er geen perfect antwoord is. Metrische gewichten kunnen clusterresourcebeheer ook specifieke services op een andere manier verdelen. Metrische gegevens kunnen vier verschillende gewichtsniveaus hebben: Nul, Laag, Gemiddeld en Hoog. Een metrische waarde met een gewicht van Nul draagt niets bij wanneer u bedenkt of dingen in balans zijn of niet. De belasting draagt echter nog steeds bij aan capaciteitsbeheer. Metrische gegevens met nulgewicht zijn nog steeds nuttig en worden vaak gebruikt als onderdeel van servicegedrag en prestatiebewaking. Dit artikel bevat meer informatie over het gebruik van metrische gegevens voor het bewaken en diagnosticen van uw services.
De werkelijke impact van verschillende metrische gewichten in het cluster is dat de Cluster Resource Manager verschillende oplossingen genereert. Metrische gewichten vertellen de Cluster Resource Manager dat bepaalde metrische gegevens belangrijker zijn dan andere. Als er geen perfecte oplossing is, kan Cluster Resource Manager de voorkeur geven aan oplossingen die de hogere gewogen metrische gegevens beter verdelen. Als een service denkt dat een bepaalde metrische waarde onbelangrijk is, kan het gebruik van die metrische waarde ongelijk zijn. Hierdoor kan een andere service een gelijkmatige verdeling krijgen van bepaalde metrische gegevens die belangrijk voor deze service zijn.
Laten we eens kijken naar een voorbeeld van een aantal belastingrapporten en hoe verschillende metrische gewichten tot verschillende toewijzingen in het cluster leidt. In dit voorbeeld zien we dat het schakelen tussen het relatieve gewicht van de metrische gegevens ervoor zorgt dat Cluster Resource Manager verschillende rangschikkingen van services maakt.
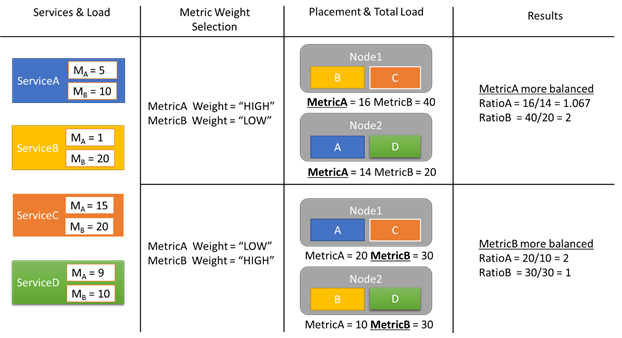
In dit voorbeeld zijn er vier verschillende services, die allemaal verschillende waarden rapporteren voor twee verschillende metrische gegevens, MetricA en MetricB. In één geval definiëren alle services MetricA het belangrijkste (Gewicht = Hoog) en MetricB als onbelangrijk (Gewicht = Laag). Als gevolg hiervan zien we dat Cluster Resource Manager de services plaatst, zodat MetricA beter in balans is dan MetricB. 'Beter evenwichtig' betekent dat MetricA een lagere standaarddeviatie heeft dan MetricB. In het tweede geval keren we de metrische gewichten om. Als gevolg hiervan wisselt De Cluster Resource Manager services A en B om een toewijzing te krijgen waarbij MetricB beter in balans is dan MetricA.
Notitie
Metrische gewichten bepalen hoe de Cluster Resource Manager moet worden afgewogen, maar niet wanneer er een taakverdeling moet plaatsvinden. Raadpleeg dit artikel voor meer informatie over het verdelen
Globale gewichten voor metrische gegevens
Stel dat ServiceA MetricA definieert als gewicht hoog en ServiceB stelt het gewicht voor MetricA in op Laag of Nul. Wat is het werkelijke gewicht dat uiteindelijk wordt gebruikt?
Er zijn meerdere gewichten die worden bijgehouden voor elke metrische waarde. Het eerste gewicht is het gewicht dat is gedefinieerd voor de metrische waarde wanneer de service wordt gemaakt. Het andere gewicht is een globaal gewicht, dat automatisch wordt berekend. Cluster Resource Manager gebruikt beide gewichten bij het scoren van oplossingen. Rekening houdend met beide gewichten is belangrijk. Hierdoor kan Cluster Resource Manager elke service op basis van zijn eigen prioriteiten verdelen en ervoor zorgen dat het cluster als geheel correct wordt toegewezen.
Wat zou er gebeuren als de Cluster Resource Manager niet om zowel globaal als lokaal evenwicht gaf? Het is eenvoudig om oplossingen te maken die wereldwijd evenwichtig zijn, maar die resulteren in een slechte resourcebalans voor afzonderlijke services. In het volgende voorbeeld kijken we naar een service die is geconfigureerd met alleen de standaard metrische gegevens en kijken wat er gebeurt wanneer er alleen een globaal saldo wordt overwogen:
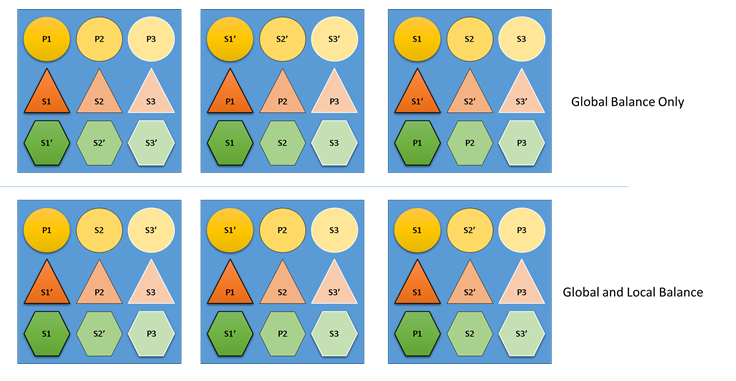
In het bovenste voorbeeld op basis van globaal evenwicht is het cluster als geheel inderdaad evenwichtig. Alle knooppunten hebben hetzelfde aantal primaries en hetzelfde aantal totale replica's. Als u echter de werkelijke impact van deze toewijzing bekijkt, is dit niet zo goed: het verlies van een knooppunt heeft een onevenredige invloed op een bepaalde workload, omdat alle primaries worden verwijderd. Als het eerste knooppunt bijvoorbeeld mislukt, gaan de drie primaries voor de drie verschillende partities van de Circle-service allemaal verloren. Omgekeerd verliezen de services Driehoek en Zeshoek hun partities een replica. Dit veroorzaakt geen onderbreking, behalve het herstellen van de offlinereplica.
In het onderste voorbeeld heeft Cluster Resource Manager de replica's gedistribueerd op basis van zowel het globale als het saldo per service. Bij het berekenen van de score van de oplossing geeft het grootste deel van het gewicht aan de globale oplossing en een (configureerbaar) gedeelte aan afzonderlijke services. Het globale saldo voor een metrische waarde wordt berekend op basis van het gemiddelde van de metrische gewichten van elke service. Elke service wordt verdeeld volgens zijn eigen gedefinieerde metrische gewichten. Dit zorgt ervoor dat de diensten op zichzelf in balans zijn op basis van hun eigen behoeften. Als hetzelfde eerste knooppunt mislukt, wordt de fout verdeeld over alle partities van alle services. De impact op elk is hetzelfde.
Volgende stappen
- Meer informatie over het configureren van services vindt u in meer informatie over het configureren van services (service-fabric-cluster-resource-manager-configure-services.md)
- Het definiëren van metrische gegevens over de fragmentatie is een manier om de belasting van knooppunten samen te voegen in plaats van deze uit te spreiden. Raadpleeg dit artikel voor meer informatie over het configureren van de fragmentatie
- Raadpleeg het artikel over taakverdeling
- Begin vanaf het begin en krijg een inleiding tot het Service Fabric-cluster Resource Manager
- Verplaatsingskosten zijn een manier om aan te geven aan clusterbronbeheer dat bepaalde services duurder zijn om te verplaatsen dan andere. Raadpleeg dit artikel voor meer informatie over verplaatsingskosten