Schalen in Service Fabric
Met Azure Service Fabric kunt u eenvoudig schaalbare toepassingen bouwen door de services, partities en replica's op de knooppunten van een cluster te beheren. Door veel workloads op dezelfde hardware uit te voeren, kunt u maximaal resourcegebruik gebruiken, maar biedt u ook flexibiliteit in termen van hoe u ervoor kiest om uw workloads te schalen. In deze Channel 9-video wordt beschreven hoe u schaalbare microservicestoepassingen kunt bouwen:
Schalen in Service Fabric wordt op verschillende manieren uitgevoerd:
- Schalen door stateless service-exemplaren te maken of te verwijderen
- Schalen door nieuwe benoemde services te maken of te verwijderen
- Schalen door nieuwe benoemde toepassingsexemplaren te maken of te verwijderen
- Schalen met behulp van gepartitioneerde services
- Schalen door knooppunten toe te voegen aan en te verwijderen uit het cluster
- Schalen met behulp van metrische gegevens van Cluster Resource Manager
Schalen door stateless service-exemplaren te maken of te verwijderen
Een van de eenvoudigste manieren om binnen Service Fabric te schalen, werkt met stateless services. Wanneer u een staatloze service maakt, krijgt u de kans om een InstanceCount. InstanceCount definieert hoeveel actieve kopieën van de code van die service worden gemaakt wanneer de service wordt gestart. Stel dat er 100 knooppunten in het cluster zijn. Stel ook dat er een service wordt gemaakt met een InstanceCount van de 10. Tijdens runtime kunnen die 10 actieve kopieën van de code allemaal te druk worden (of zijn ze niet bezet genoeg). Een manier om die workload te schalen, is door het aantal exemplaren te wijzigen. Een deel van de bewakings- of beheercode kan bijvoorbeeld het bestaande aantal exemplaren wijzigen in 50 of 5, afhankelijk van of de workload moet worden ingeschaald of uitgeschaald op basis van de belasting.
C#:
StatelessServiceUpdateDescription updateDescription = new StatelessServiceUpdateDescription();
updateDescription.InstanceCount = 50;
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
PowerShell:
Update-ServiceFabricService -Stateless -ServiceName $serviceName -InstanceCount 50
Dynamisch aantal exemplaren gebruiken
Met name voor stateless services biedt Service Fabric een automatische manier om het aantal exemplaren te wijzigen. Hierdoor kan de service dynamisch worden geschaald met het aantal beschikbare knooppunten. De manier om dit gedrag in te stellen, is door het aantal exemplaren = -1 in te stellen. InstanceCount = -1 is een instructie voor Service Fabric met de tekst 'Deze stateless service uitvoeren op elk knooppunt'. Als het aantal knooppunten verandert, wordt in Service Fabric automatisch het aantal exemplaren aangepast, zodat de service wordt uitgevoerd op alle geldige knooppunten.
C#:
StatelessServiceDescription serviceDescription = new StatelessServiceDescription();
//Set other service properties necessary for creation....
serviceDescription.InstanceCount = -1;
await fc.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless -PartitionSchemeSingleton -InstanceCount "-1"
Schalen door nieuwe benoemde services te maken of te verwijderen
Een benoemd service-exemplaar is een specifiek exemplaar van een servicetype (zie de levenscyclus van de Service Fabric-toepassing) binnen een benoemd toepassingsexemplaren in het cluster.
Nieuwe benoemde service-exemplaren kunnen worden gemaakt (of verwijderd) naarmate services meer of minder druk worden. Hierdoor kunnen aanvragen worden verspreid over meer service-exemplaren, waardoor de belasting van bestaande services meestal kan afnemen. Bij het maken van services plaatst Service Fabric-cluster Resource Manager de services in het cluster op gedistribueerde wijze. De exacte beslissingen worden bepaald door de metrische gegevens in het cluster en andere plaatsingsregels. Services kunnen op verschillende manieren worden gemaakt, maar de meest voorkomende zijn via beheeracties zoals iemand die belt New-ServiceFabricServiceof door code aan te roepen CreateServiceAsync. CreateServiceAsync kan zelfs worden aangeroepen vanuit andere services die in het cluster worden uitgevoerd.
Het dynamisch maken van services kan worden gebruikt in allerlei scenario's en is een gemeenschappelijk patroon. Denk bijvoorbeeld aan een stateful service die een bepaalde werkstroom vertegenwoordigt. Aanroepen die werk vertegenwoordigen, worden weergegeven voor deze service en deze service gaat de stappen naar die werkstroom uitvoeren en de voortgang vastleggen.
Hoe maakt u deze specifieke serviceschaal? De service kan in een bepaalde vorm meerdere tenants hebben en aanroepen accepteren en stappen starten voor veel verschillende exemplaren van dezelfde werkstroom, allemaal tegelijk. Hierdoor kan de code echter complexer worden, omdat het zich nu zorgen moet maken over veel verschillende exemplaren van dezelfde werkstroom, allemaal in verschillende fasen en van verschillende klanten. Het afhandelen van meerdere werkstromen tegelijkertijd lost het schaalprobleem niet op. Dit komt doordat deze service op een bepaald moment te veel resources verbruikt om op een bepaalde computer te passen. Veel services die niet voor dit patroon zijn gebouwd, ondervinden ook problemen vanwege een inherent knelpunt of vertraging in hun code. Deze typen problemen zorgen ervoor dat de service niet goed werkt wanneer het aantal gelijktijdige werkstromen dat wordt bijgehouden, groter wordt.
Een oplossing is het maken van een exemplaar van deze service voor elk ander exemplaar van de werkstroom die u wilt bijhouden. Dit is een geweldig patroon en werkt of de service staatloos of stateful is. Om dit patroon te laten werken, is er meestal een andere service die fungeert als een Workload Manager-service. De taak van deze service is het ontvangen van aanvragen en het routeren van deze aanvragen naar andere services. De manager kan dynamisch een exemplaar van de workloadservice maken wanneer het bericht wordt ontvangen en vervolgens aanvragen aan deze services doorgeven. De managerservice kan ook callbacks ontvangen wanneer een bepaalde werkstroomservice de taak heeft voltooid. Wanneer de manager deze callbacks ontvangt, kan het dat exemplaar van de werkstroomservice worden verwijderd of verlaten als er meer aanroepen worden verwacht.
Geavanceerde versies van dit type manager kunnen zelfs pools maken van de services die worden beheerd. De pool helpt ervoor te zorgen dat wanneer er een nieuwe aanvraag binnenkomt, de service niet hoeft te wachten totdat de service is opgeslagen. In plaats daarvan kan de manager gewoon een werkstroomservice kiezen die momenteel niet bezet is vanuit de pool of willekeurig routeren. Door een groep services beschikbaar te houden, worden nieuwe aanvragen sneller verwerkt, omdat het minder waarschijnlijk is dat de aanvraag moet wachten totdat een nieuwe service wordt uitgedeeld. Het maken van nieuwe services is snel, maar niet gratis of onmiddellijk. De pool helpt de hoeveelheid tijd te minimaliseren die de aanvraag moet wachten voordat de service wordt uitgevoerd. Dit manager- en poolpatroon wordt vaak weergegeven wanneer de reactietijden het belangrijkst zijn. Het in de wachtrij plaatsen van de aanvraag en het maken van de service op de achtergrond en deze vervolgens doorgeven, is ook een populair managerpatroon, zoals het maken en verwijderen van services op basis van een aantal tracering van de hoeveelheid werk die momenteel in behandeling is voor de service.
Schalen door nieuwe benoemde toepassingsexemplaren te maken of te verwijderen
Het maken en verwijderen van hele toepassingsexemplaren is vergelijkbaar met het patroon van het maken en verwijderen van services. Voor dit patroon is er een managerservice die de beslissing neemt op basis van de aanvragen die worden weergegeven en de informatie die het ontvangt van de andere services in het cluster.
Wanneer moet het maken van een nieuw benoemd toepassingsexemplaren worden gebruikt in plaats van een nieuwe benoemde service-exemplaren te maken in sommige al bestaande toepassingen? Er zijn enkele gevallen:
- Het nieuwe toepassingsexemplaren is voor een klant waarvan de code moet worden uitgevoerd onder een bepaalde identiteit of beveiligingsinstellingen.
- Met Service Fabric kunnen verschillende codepakketten worden uitgevoerd onder bepaalde identiteiten. Als u hetzelfde codepakket onder verschillende identiteiten wilt starten, moeten de activeringen plaatsvinden in verschillende toepassingsexemplaren. Overweeg een geval waarin u de workloads van een bestaande klant hebt geïmplementeerd. Deze kunnen worden uitgevoerd onder een bepaalde identiteit, zodat u de toegang tot andere resources, zoals externe databases of andere systemen, kunt bewaken en beheren. In dit geval wilt u, wanneer een nieuwe klant zich aanmeldt, de code waarschijnlijk niet activeren in dezelfde context (procesruimte). Hoewel u dat kunt, is het voor uw servicecode moeilijker om te handelen binnen de context van een bepaalde identiteit. Doorgaans moet u meer code voor beveiliging, isolatie en identiteitsbeheer hebben. In plaats van verschillende benoemde service-exemplaren binnen hetzelfde toepassingsexemplaren te gebruiken en daarom dezelfde procesruimte, kunt u verschillende benoemde Service Fabric-toepassingsexemplaren gebruiken. Dit maakt het eenvoudiger om verschillende identiteitscontexten te definiëren.
- Het nieuwe toepassingsexemplaren fungeert ook als een configuratiemiddel
- Standaard worden alle benoemde service-exemplaren van een bepaald servicetype binnen een toepassingsexemplaren uitgevoerd in hetzelfde proces op een bepaald knooppunt. Wat dit betekent, is dat hoewel u elk service-exemplaar anders kunt configureren, dit ingewikkeld is. Services moeten een token hebben dat ze gebruiken om hun configuratie in een configuratiepakket op te zoeken. Meestal is dit alleen de naam van de service. Dit werkt prima, maar de configuratie wordt gekoppeld aan de namen van de afzonderlijke benoemde service-exemplaren binnen dat toepassingsexemplaren. Dit kan verwarrend en moeilijk te beheren zijn, omdat configuratie normaal gesproken een ontwerptijdartefact is met specifieke waarden voor het toepassingsexemplaren. Het maken van meer services betekent altijd dat er meer toepassingsupgrades nodig zijn om de informatie in de configuratiepakketten te wijzigen of om nieuwe services te implementeren, zodat de nieuwe services hun specifieke informatie kunnen opzoeken. Het is vaak eenvoudiger om een geheel nieuw benoemd toepassingsexemplaren te maken. Vervolgens kunt u de toepassingsparameters gebruiken om de configuratie in te stellen die nodig is voor de services. Op deze manier kunnen alle services die worden gemaakt binnen dat benoemde toepassingsexemplaren bepaalde configuratie-instellingen overnemen. In plaats van één configuratiebestand te hebben met de instellingen en aanpassingen voor elke klant, zoals geheimen of resourcelimieten per klant, hebt u in plaats daarvan een ander toepassingsexemplaren voor elke klant met deze instellingen overschreven.
- De nieuwe toepassing fungeert als een upgradegrens
- Binnen Service Fabric fungeren verschillende benoemde toepassingsexemplaren als grenzen voor de upgrade. Een upgrade van een benoemd toepassingsexemplaren heeft geen invloed op de code die door een ander benoemd toepassingsexemplaren wordt uitgevoerd. De verschillende toepassingen zullen uiteindelijk verschillende versies van dezelfde code op dezelfde knooppunten uitvoeren. Dit kan een factor zijn wanneer u een schaalbeslissing moet nemen, omdat u kunt kiezen of de nieuwe code dezelfde upgrades moet volgen als een andere service of niet. Stel bijvoorbeeld dat een oproep binnenkomt bij de managerservice die verantwoordelijk is voor het schalen van de workloads van een bepaalde klant door dynamisch services te maken en te verwijderen. In dit geval is de aanroep echter voor een workload die is gekoppeld aan een nieuwe klant. De meeste klanten houden ervan niet alleen om de eerder vermelde beveiligings- en configuratieredenen te isoleren, maar omdat het meer flexibiliteit biedt in termen van het uitvoeren van specifieke versies van de software en het kiezen wanneer ze worden geüpgraded. U kunt ook een nieuw toepassingsexemplaren maken en de service daar maken om de hoeveelheid services die een upgrade aanraakt, verder te partitioneren. Afzonderlijke toepassingsexemplaren bieden meer granulariteit bij het uitvoeren van toepassingsupgrades en het inschakelen van A/B-tests en Blue/Green-implementaties.
- Het bestaande toepassingsexemplaren is vol
- In Service Fabric is toepassingscapaciteit een concept dat u kunt gebruiken om de hoeveelheid resources te beheren die beschikbaar zijn voor bepaalde toepassingsexemplaren. U kunt bijvoorbeeld besluiten dat een bepaalde service een ander exemplaar moet hebben gemaakt om te kunnen schalen. Dit toepassingsexemplaren hebben echter geen capaciteit meer voor een bepaald metrische waarde. Als deze specifieke klant of workload nog steeds meer resources moet krijgen, kunt u de bestaande capaciteit voor die toepassing verhogen of een nieuwe toepassing maken.
Schalen op partitieniveau
Service Fabric ondersteunt partitionering. Partitionering splitst een service in verschillende logische en fysieke secties, die elk onafhankelijk van elkaar werken. Dit is handig bij stateful services, omdat geen enkele set replica's alle aanroepen moet verwerken en alle status tegelijk moet bewerken. Het overzicht van partitionering biedt informatie over de typen partitioneringsschema's die worden ondersteund. De replica's van elke partitie worden verdeeld over de knooppunten in een cluster, waarbij de belasting van die service wordt gedistribueerd en ervoor zorgt dat de service als geheel of een partitie geen single point of failure heeft.
Overweeg een service die gebruikmaakt van een bereikpartitioneringsschema met een lage sleutel van 0, een hoge sleutel van 99 en een partitieaantal van 4. In een cluster met drie knooppunten kan de service worden ingedeeld met vier replica's die de resources op elk knooppunt delen, zoals hier wordt weergegeven:
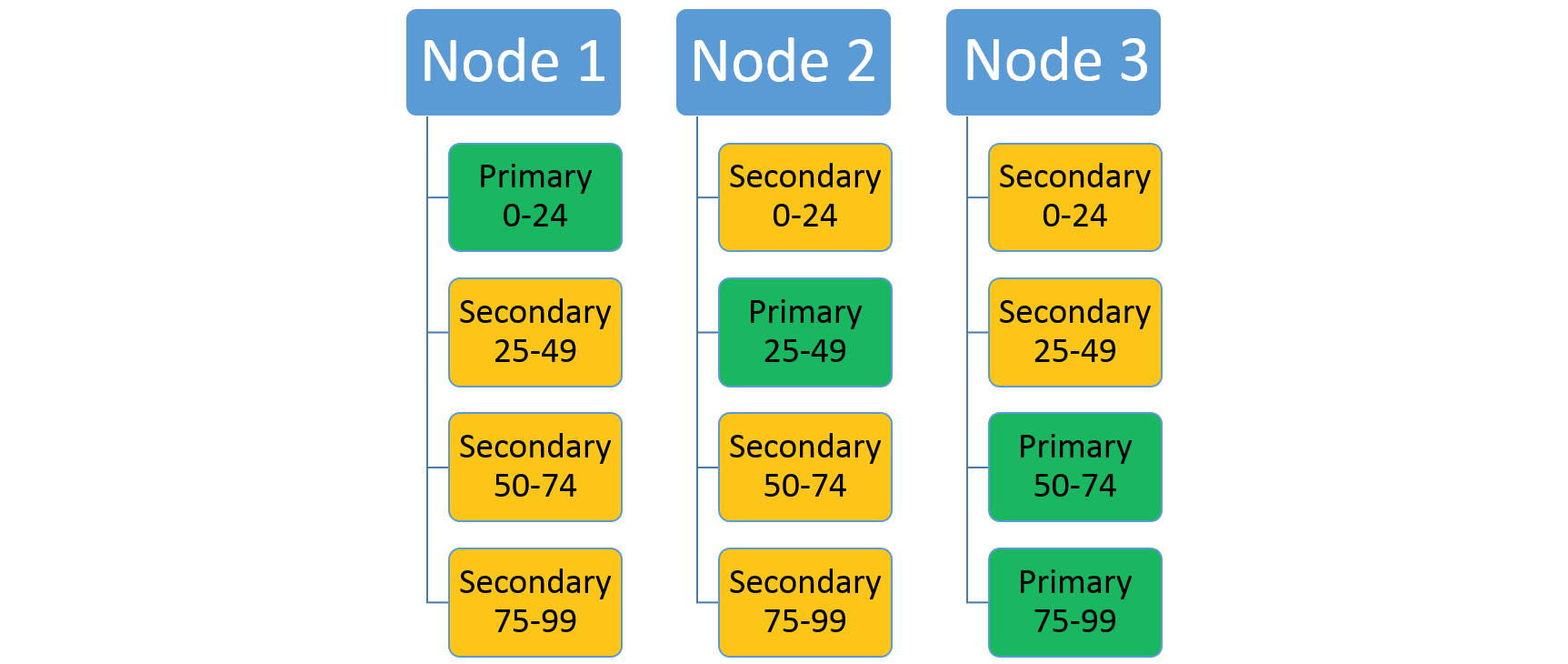
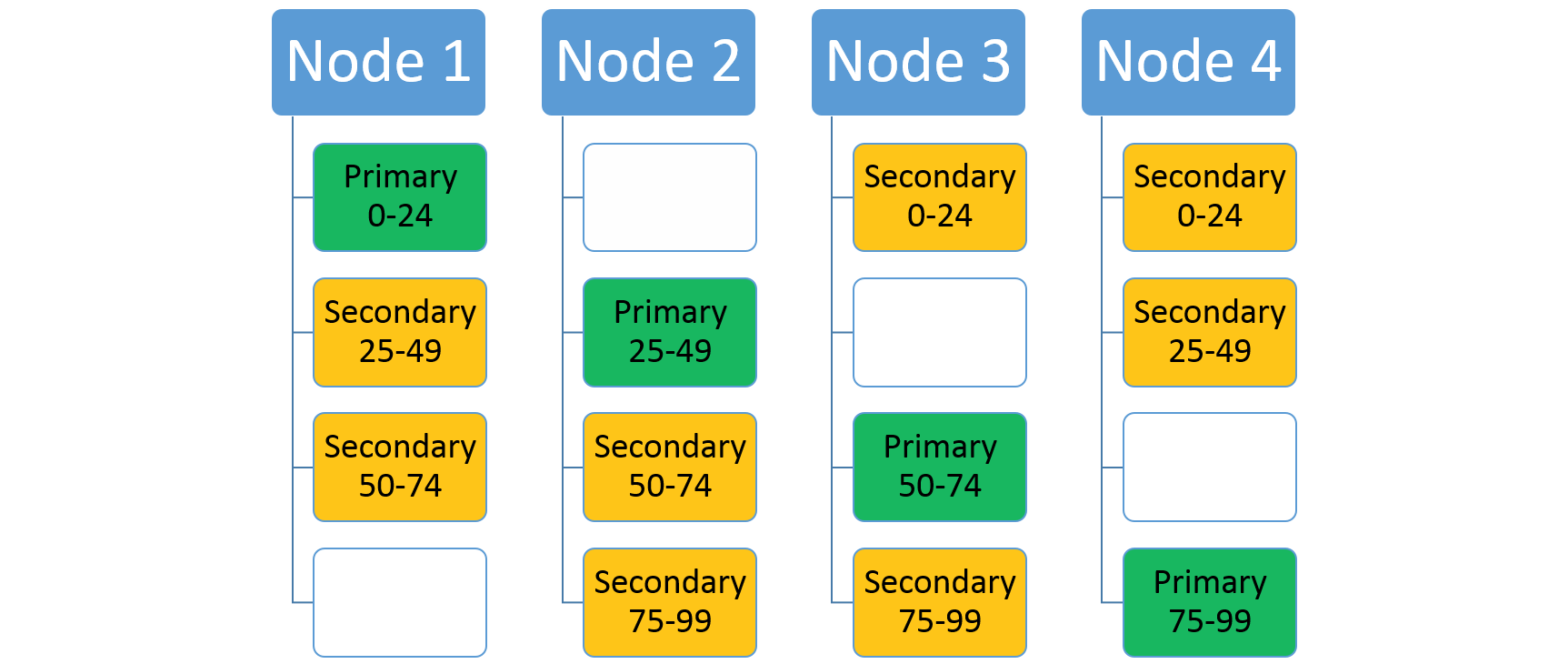
Als u het aantal knooppunten verhoogt, verplaatst Service Fabric enkele van de bestaande replica's daar. Stel dat het aantal knooppunten toeneemt tot vier en dat de replica's opnieuw worden gedistribueerd. De service heeft nu drie replica's die op elk knooppunt worden uitgevoerd, die elk behoren tot verschillende partities. Dit maakt een beter resourcegebruik mogelijk omdat het nieuwe knooppunt niet koud is. Het verbetert doorgaans ook de prestaties omdat elke service meer resources beschikbaar heeft.
Schalen met behulp van Service Fabric Cluster Resource Manager en metrische gegevens
Metrische gegevens zijn de wijze waarop services hun resourceverbruik uitdrukken naar Service Fabric. Het gebruik van metrische gegevens biedt Cluster Resource Manager de mogelijkheid om de indeling van het cluster opnieuw te ordenen en te optimaliseren. Er kunnen bijvoorbeeld veel resources in het cluster zijn, maar ze worden mogelijk niet toegewezen aan de services die momenteel werken. Met behulp van metrische gegevens kan Cluster Resource Manager het cluster opnieuw ordenen om ervoor te zorgen dat services toegang hebben tot de beschikbare resources.
Schalen door knooppunten toe te voegen aan en te verwijderen uit het cluster
Een andere optie voor schalen met Service Fabric is het wijzigen van de grootte van het cluster. Als u de grootte van het cluster wijzigt, betekent dit dat u knooppunten toevoegt of verwijdert voor een of meer van de knooppunttypen in het cluster. Denk bijvoorbeeld aan een geval waarin alle knooppunten in het cluster hot zijn. Dit betekent dat de resources van het cluster bijna allemaal worden verbruikt. In dit geval is het toevoegen van meer knooppunten aan het cluster de beste manier om te schalen. Zodra de nieuwe knooppunten lid zijn van het cluster, verplaatst De Resource Manager van het Service Fabric-cluster er services naartoe, wat resulteert in minder totale belasting op de bestaande knooppunten. Voor stateless services met het aantal exemplaren = -1 worden automatisch meer service-exemplaren gemaakt. Hierdoor kunnen sommige aanroepen van de bestaande knooppunten naar de nieuwe knooppunten worden verplaatst.
Zie clusterschalen voor meer informatie.
Een platform kiezen
Als gevolg van implementatieverschillen tussen besturingssystemen kan het kiezen voor het gebruik van Service Fabric met Windows of Linux een essentieel onderdeel zijn van het schalen van uw toepassing. Een mogelijke barrière is hoe gefaseerde logboekregistratie wordt uitgevoerd. Service Fabric in Windows maakt gebruik van een kernelstuurprogramma voor een logboek met één per machine, gedeeld tussen stateful servicereplica's. Dit logboek weegt ongeveer 8 GB. Linux gebruikt daarentegen een faseringslogboek van 256 MB voor elke replica, waardoor het minder ideaal is voor toepassingen die het aantal lichtgewicht servicereplica's op een bepaald knooppunt willen maximaliseren. Deze verschillen in tijdelijke opslagvereisten kunnen mogelijk het gewenste platform voor de implementatie van een Service Fabric-cluster informeren.
Alles samenvoegen
Laten we alle ideeën nemen die we hier hebben besproken en een voorbeeld bespreken. Houd rekening met de volgende service: u probeert een service te bouwen die fungeert als een adresboek, waarbij u de namen en contactgegevens vasthoudt.
U hebt meteen een aantal vragen met betrekking tot schalen: Hoeveel gebruikers gaat u hebben? Hoeveel contactpersonen worden door elke gebruiker opgeslagen? Het is moeilijk om dit allemaal te achterhalen wanneer u uw service voor de eerste keer opstaat. Stel dat u met één statische service met een specifiek aantal partities zou gaan. De gevolgen van het kiezen van het verkeerde aantal partities kunnen ervoor zorgen dat u later problemen ondervindt met de schaal. Ook als u het juiste aantal kiest, hebt u mogelijk niet alle informatie die u nodig hebt. U moet bijvoorbeeld ook de grootte van het cluster vooraf bepalen, zowel wat betreft het aantal knooppunten als de grootte ervan. Het is meestal moeilijk te voorspellen hoeveel resources een service gedurende de levensduur gaat verbruiken. Het kan ook moeilijk zijn om van tevoren te weten wat het verkeerspatroon is dat de service daadwerkelijk ziet. Misschien voegen mensen bijvoorbeeld hun contactpersonen alleen 's ochtends toe en verwijderen, of misschien worden ze gelijkmatig verdeeld over de loop van de dag. Op basis hiervan moet u mogelijk dynamisch uitschalen en inschalen. Misschien kunt u voorspellen wanneer u moet uitschalen en inschalen, maar op beide manieren moet u waarschijnlijk reageren op het veranderen van resourceverbruik door uw service. Dit kan betrekking hebben op het wijzigen van de grootte van het cluster om meer resources te bieden bij het opnieuw ordenen van het gebruik van bestaande resources is niet voldoende.
Maar waarom probeert u zelfs een enkel partitieschema voor alle gebruikers te kiezen? Waarom uzelf beperken tot één service en één statisch cluster? De werkelijke situatie is meestal dynamischer.
Houd bij het bouwen van schaal rekening met het volgende dynamische patroon. Mogelijk moet u deze aanpassen aan uw situatie:
- In plaats van eerst een partitioneringsschema te kiezen voor iedereen, bouwt u een 'managerservice'.
- De taak van de managerservice is om klantgegevens te bekijken wanneer ze zich registreren voor uw service. Afhankelijk van die informatie maakt de managerservice vervolgens een exemplaar van uw werkelijke contactopslagservice voor die klant. Als ze specifieke configuratie, isolatie of upgrades vereisen, kunt u ook besluiten om een toepassingsexemplementatie voor deze klant in te stellen.
Dit dynamische creatiepatroon biedt veel voordelen:
- U probeert niet het juiste aantal partities voor alle gebruikers vooraf te raden of een enkele service te bouwen die oneindig schaalbaar is.
- Verschillende gebruikers hoeven niet hetzelfde aantal partities, replicaaantallen, plaatsingsbeperkingen, metrische gegevens, standaardbelastingen, servicenamen, DNS-instellingen of een van de andere eigenschappen te hebben die zijn opgegeven op service- of toepassingsniveau.
- U krijgt extra gegevenssegmentatie. Elke klant heeft een eigen kopie van de service
- Elke klantenservice kan op een andere manier worden geconfigureerd en meer of minder resources worden verleend, met meer of minder partities of replica's op basis van de verwachte schaal.
- Stel bijvoorbeeld dat de klant heeft betaald voor de 'Gold'-laag: ze kunnen meer replica's of een groter aantal partities krijgen, en mogelijk resources die zijn toegewezen aan hun services via metrische gegevens en toepassingscapaciteiten.
- Of stel dat ze informatie hebben verstrekt die aangeeft hoeveel contactpersonen ze nodig hadden, 'Klein'. Ze krijgen slechts een paar partities of kunnen zelfs worden geplaatst in een gedeelde servicegroep met andere klanten.
- Elke klantenservice kan op een andere manier worden geconfigureerd en meer of minder resources worden verleend, met meer of minder partities of replica's op basis van de verwachte schaal.
- U voert geen aantal service-exemplaren of replica's uit terwijl u wacht tot klanten worden weergegeven
- Als een klant ooit vertrekt, is het verwijderen van de gegevens uit uw service net zo eenvoudig als het verwijderen van die service of toepassing die door de manager is gemaakt.
Volgende stappen
Zie de volgende artikelen voor meer informatie over Service Fabric-concepten: