Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In deze zelfstudie leert u hoe u gebeurtenissen in een opslagaccount met een hiërarchische naamruimte verwerkt.
U maakt een kleine oplossing waarmee een gebruiker een Databricks Delta-tabel kan invullen door een bestand met door komma's gescheiden waarden (CSV) te uploaden waarin een verkooporder wordt beschreven. U maakt deze oplossing door een Event Grid-abonnement, een Azure-functie en een taak in Azure Databricks aan elkaar te koppelen.
In deze zelfstudie leert u het volgende:
- Maak een Event Grid-abonnement die een Azure-functie aanroept.
- Maak een Azure-functie die een melding ontvangt van een gebeurtenis en vervolgens de taak uitvoert in Azure Databricks.
- Maak een Databricks-taak waarmee een klantorder wordt ingevoegd in een Databricks Delta-tabel in het opslagaccount.
U maakt deze oplossing in omgekeerde volgorde, te beginnen met de Azure Databricks-werkruimte.
Vereisten
Maak een opslagaccount met een hiërarchische naamruimte (Azure Data Lake Storage). In deze zelfstudie wordt een opslagaccount met de naam
contosoordersgebruikt.Zie Een opslagaccount maken voor gebruik met Azure Data Lake Storage.
Zorg ervoor dat aan uw gebruikersaccount de rol van Gegevensbijdrager voor opslagblob is toegewezen.
Maak een service-principal, maak een clientgeheim en verdeel vervolgens de service-principal toegang tot het opslagaccount.
Zie zelfstudie: Verbinding maken met Azure Data Lake Storage (stap 1 tot en met 3). Nadat u deze stappen hebt voltooid, moet u de waarden voor tenant-id, app-id en clientgeheim in een tekstbestand plakken. U hebt deze binnenkort nodig.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Een verkooporder maken
Maak eerst een CSV-bestand waarin een verkooporder wordt beschreven en upload dat bestand vervolgens naar het opslagaccount. Later gebruikt u de gegevens uit dit bestand om de eerste rij in de Databricks Delta-tabel in te vullen.
Navigeer naar het nieuwe opslagaccount in Azure Portal.
Selecteer Opslagbrowser-Blob-containers>-> Container toevoegen en maak een nieuwe container met de naam gegevens.
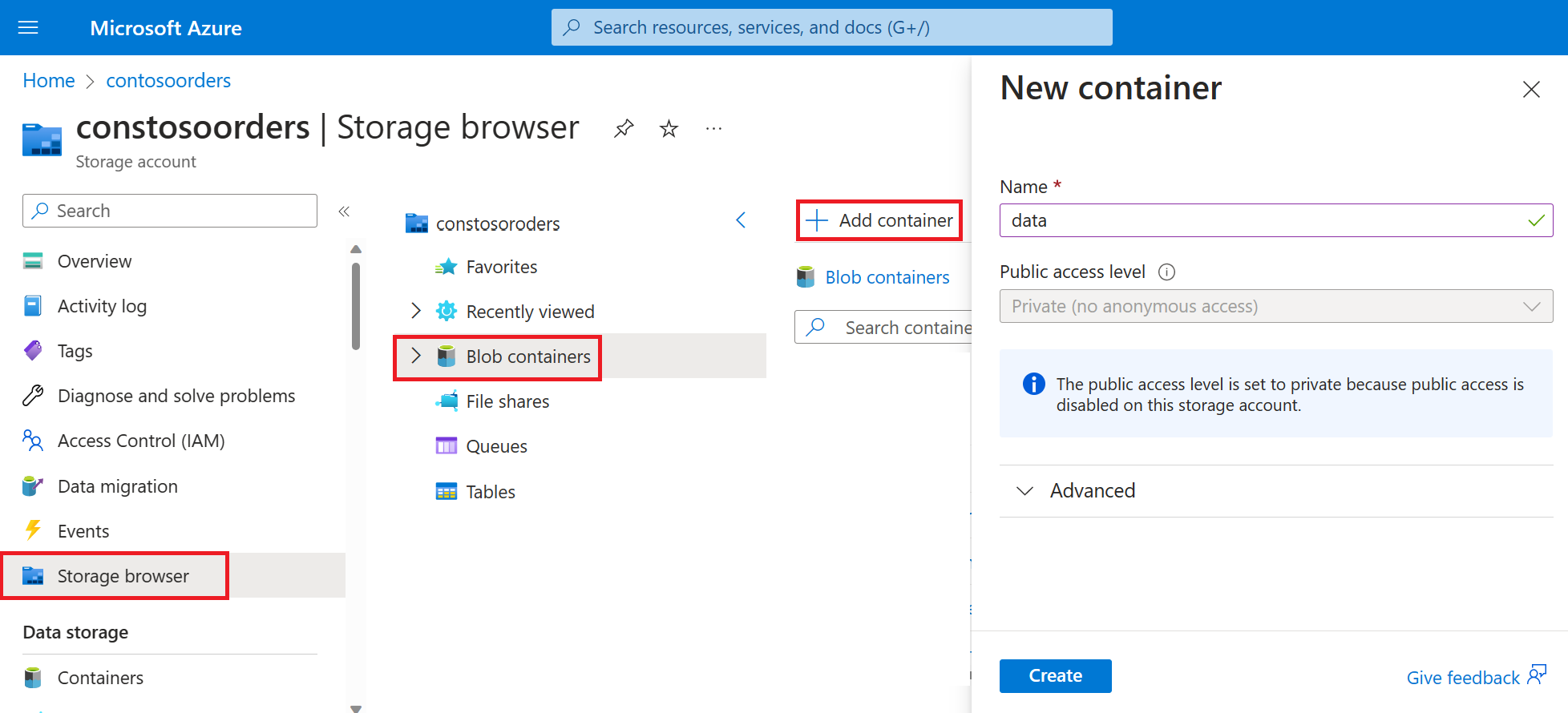
Maak in de gegevenscontainer een map met de naam Invoer.
Plak de volgende tekst in een teksteditor.
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomSla dit bestand op uw lokale computer op en geef het de naam data.csv.
Upload dit bestand in de opslagbrowser naar de invoermap .
Een taak maken in Azure Databricks
In deze sectie voert u de volgende taken uit:
- Een Azure Databricks-werkruimte maken.
- Maak een notebook.
- Een Databricks Delta-tabel maken en invullen.
- Code toevoegen waarmee rijen in de Databricks Delta-tabel worden ingevoegd.
- Een taak maken.
Een Azure Databricks-werkruimte maken
In deze sectie gaat u een Azure Databricks-werkruimte maken met behulp van Azure Portal.
Een Azure Databricks-werkruimte maken. Geef die werkruimte
contoso-orderseen naam. Zie Een Azure Databricks-werkruimte maken.Een cluster maken. Geef het cluster
customer-order-clustereen naam. Zie Een cluster maken.Maak een notebook. Geef het notebook
configure-customer-tableeen naam en kies Python als de standaardtaal van het notebook. Zie Een notitieblok maken.
Een Databricks Delta-tabel maken en invullen
Kopieer en plak het volgende codeblok in de eerste cel van de notebook die u hebt gemaakt, maar voer deze code nog niet uit.
Vervang de plaatsaanduidingen
appId,passwordentenantin het codeblok door de waarden die u hebt verzameld bij het uitvoeren van de vereiste stappen voor deze zelfstudie.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Met deze code wordt een widget met de naam source_file gemaakt. Later gaat u een Azure-functie maken die deze code aanroept en een bestandspad aan die widget doorgeeft. Deze code verifieert ook uw service-principal met het opslagaccount en maakt enkele variabelen die u in andere cellen gebruikt.
Notitie
In een productieomgeving kunt u de verificatiesleutel eventueel in Azure Databricks opslaan. Vervolgens voegt u een opzoeksleutel toe aan uw codeblok in plaats van de verificatiesleutel.
In plaats van deze regel met code te gebruiken (spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>")) gebruikt u bijvoorbeeld de regel met codespark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
Nadat u deze zelfstudie hebt voltooid, raadpleegt u het Artikel over Azure Data Lake Storage op de Azure Databricks-website om voorbeelden van deze benadering te bekijken.Druk op de toetsen Shift + Enter om de code in dit blok uit te voeren.
Kopieer en plak het volgende codeblok in een andere cel en druk op de toetsen SHIFT + ENTER om de code in dit blok uit te voeren.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Deze code maakt de Databricks Delta-tabel in uw opslagaccount en laadt vervolgens enkele initiële gegevens uit het CSV-bestand dat u eerder hebt geüpload.
Nadat het codeblok is uitgevoerd, verwijdert u het uit de notebook.
Code toevoegen waarmee rijen worden ingevoegd in de Databricks Delta-tabel
Kopieer en plak het volgende codeblok in een andere cel, maar voer deze cel nog niet uit.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Met deze code worden gegevens in een tijdelijke tabelweergave ingevoegd met behulp van gegevens uit een CSV-bestand. Het pad naar dat CSV-bestand is afkomstig van de invoerwidget die u in een eerdere stap hebt gemaakt.
Kopieer en plak het volgende codeblok in een andere cel. Met deze code wordt de inhoud van de tijdelijke tabelweergave samengevoegd met de Databricks Delta-tabel.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Een taak maken
Maak een taak die de notebook uitvoert die u eerder hebt gemaakt. Later maakt u een Azure-functie waarmee deze taak wordt uitgevoerd wanneer een gebeurtenis wordt gegenereerd.
Selecteer Nieuwe> taak.
Geef de taak een naam, kies het notitieblok dat u hebt gemaakt en het cluster. Selecteer vervolgens Maken om de taak te maken.
Een Azure-functie maken
Maak een Azure-functie waarmee de taak wordt uitgevoerd.
Klik in uw Azure Databricks-werkruimte op uw Azure Databricks-gebruikersnaam in de bovenste balk en selecteer vervolgens in de vervolgkeuzelijst Gebruikersinstellingen.
Selecteer op het tabblad Toegangstokens de optie Nieuw token genereren.
Kopieer het token dat wordt weergegeven en klik vervolgens op Gereed.
Kies in de linkerbovenhoek van de Databricks-werkruimte het pictogram Personen en kies vervolgens Gebruikersinstellingen.

Selecteer de knop Nieuw token genereren en selecteer vervolgens de knop Genereren .
Zorg ervoor dat u het token naar een veilige locatie kopieert. Uw Azure-functie heeft dit token nodig om te verifiëren met Databricks, zodat de taak kan worden uitgevoerd.
Selecteer vanuit het menu van Azure Portal of op de startpagina de optie Een resource maken.
Selecteer op de pagina NieuwReken>functie-app.
Kies op het tabblad Basisbeginselen van de pagina Functie-app maken een resourcegroep en wijzig of controleer de volgende instellingen:
Instelling Weergegeven als Functions App-naam contosoorder Runtimestack .NET Publiceren Code Besturingssysteem Windows Abonnementtype Verbruik (serverloos) Selecteer Controleren en maken en selecteer vervolgens Maken.
Wanneer de implementatie is voltooid, selecteert u Ga naar de resource om de overzichtspagina van de functie-app te openen.
Selecteer Configuratie in de groep Instellingen.
Kies op de pagina Toepassingsinstellingen de knop Nieuwe toepassingsinstelling om elke instelling toe te voegen.

Voeg de volgende instellingen toe:
Naam instelling Weergegeven als DBX_INSTANCE De regio van uw Databricks-werkruimte. Bijvoorbeeld: westus2.azuredatabricks.netDBX_PAT Het persoonlijke toegangstoken dat u eerder hebt gegenereerd. DBX_JOB_ID De id van de taak die wordt uitgevoerd. Selecteer Opslaan om deze instellingen door te voeren.
Selecteer Functies in de groep Functions en selecteer vervolgens Maken.
Kies Azure Event Grid-trigger.
Installeer de extensie Microsoft.Azure.WebJobs.Extensions.EventGrid als u dit wordt gevraagd. Als u deze moet installeren, kiest u opnieuw Azure Event Grid-trigger om de functie te maken.
Het deelvenster Nieuwe functie wordt weergegeven.
Geef in het deelvenster Nieuwe functie de naam van de functie UpsertOrder en selecteer vervolgens de knop Maken .
Vervang de inhoud van het codebestand door deze code en selecteer vervolgens de knop Opslaan :
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Deze code parseert informatie over de opslaggebeurtenis die is gegenereerd en maakt vervolgens een aanvraagbericht met een URL van het bestand dat de gebeurtenis heeft geactiveerd. Als onderdeel van het bericht geeft de functie een waarde door aan de widget source_file die u eerder hebt gemaakt. De functiecode verzendt het bericht naar de Databricks-taak en gebruikt het token dat u eerder hebt verkregen als verificatie.
Een Event Grid-abonnement maken
In deze sectie maakt u een Event Grid-abonnement dat de Azure-functie aanroept wanneer bestanden naar het opslagaccount worden geüpload.
Selecteer Integratie en selecteer vervolgens op de integratiepagina Event Grid-trigger.
Geef in het deelvenster Trigger bewerken de gebeurtenis
eventGridEventeen naam en selecteer vervolgens Een gebeurtenisabonnement maken.Notitie
De naam
eventGridEventkomt overeen met de parameter die wordt doorgegeven aan de Azure-functie.Wijzig of controleer de volgende instellingen op het tabblad Basis van de pagina Gebeurtenisabonnement maken:
Instelling Weergegeven als Naam contoso-order-event-subscription Onderwerptype Opslagaccount Bronresource contosoorders Naam van systeemonderwerp <create any name>Filteren op gebeurtenistypen Blob gemaakt en blob verwijderd Selecteer de knop Maken.
Het Event Grid-abonnement testen
Maak een bestand met de naam
customer-order.csv, plak de volgende gegevens in dat bestand en sla het op uw lokale computer op.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneUpload dit bestand in Storage Explorer naar de map input van uw opslagaccount.
Als u een bestand uploadt, wordt de gebeurtenis Microsoft.Storage.BlobCreated gegenereerd. Event Grid waarschuwt alle abonnees voor die gebeurtenis. In ons geval is de Azure-functie de enige abonnee. De Azure-functie parseert de gebeurtenisparameters om te bepalen welke gebeurtenis heeft plaatsgevonden. Vervolgens wordt de URL van het bestand doorgegeven aan de Databricks-taak. De Databricks-taak leest het bestand en voegt een rij toe aan de Databricks Delta-tabel in uw opslagaccount.
Als u wilt controleren of de taak is voltooid, bekijkt u de uitvoeringen voor uw taak. U ziet een voltooiingsstatus. Zie Uitvoeringen voor een taak weergeven voor een taak voor meer informatie over het weergeven van uitvoeringen voor een taak
Voer in een nieuwe werkbladcel deze query uit om de bijgewerkte Delta-tabel weer te geven.
%sql select * from customer_dataDe geretourneerde tabel bevat de meest recente record.

Als u deze record wilt bijwerken, maakt u een bestand met de naam
customer-order-update.csv, plakt u de volgende gegevens in dat bestand en slaat u het op uw lokale computer op.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneDit CSV-bestand is bijna identiek aan het vorige, maar de hoeveelheid van de order is gewijzigd van
228in22.Upload dit bestand in Storage Explorer naar de map input van uw opslagaccount.
Voer de query
selectopnieuw uit om de bijgewerkte Delta-tabel weer te geven.%sql select * from customer_dataDe geretourneerde tabel toont de bijgewerkte record.

Resources opschonen
Verwijder de resourcegroep en alle gerelateerde resources, wanneer u deze niet meer nodig hebt. Hiervoor selecteert u de resourcegroep voor het opslagaccount en selecteert u Verwijderen.