Prestaties verbeteren voor NFS Azure-bestandsshares
In dit artikel wordt uitgelegd hoe u de prestaties voor Azure-bestandsshares (Network File System) (NFS) kunt verbeteren.
Van toepassing op
| Bestands sharetype | SMB | NFS |
|---|---|---|
| Standaardbestandsshares (GPv2), LRS/ZRS | ||
| Standaardbestandsshares (GPv2), GRS/GZRS | ||
| Premium bestandsshares (FileStorage), LRS/ZRS |
De leesdoorvoer vergroten om de leesdoorvoer te verbeteren
De read_ahead_kb kernelparameter in Linux vertegenwoordigt de hoeveelheid gegevens die 'vooruit lezen' moet zijn of die vooraf moeten worden opgehaald tijdens een sequentiële leesbewerking. Linux-kernelversies vóór 5.4 stellen de waarde voor lezen in op het equivalent van 15 keer de gekoppelde bestandssysteem rsize, die de koppelingsoptie aan de clientzijde vertegenwoordigt voor de leesbuffergrootte. Hiermee stelt u in de meeste gevallen de waarde voor lezen hoog genoeg in om de sequentiële leesdoorvoer van de client te verbeteren.
Vanaf Linux-kernelversie 5.4 gebruikt de Linux NFS-client echter een standaardwaarde read_ahead_kb van 128 KiB. Deze kleine waarde kan de hoeveelheid leesdoorvoer voor grote bestanden verminderen. Klanten die upgraden van Linux-releases met de grotere leeswaarde naar releases met de standaardwaarde 128 KiB, kunnen een afname van de sequentiële leesprestaties ervaren.
Voor Linux-kernels 5.4 of hoger raden we u aan de read_ahead_kb 15 MiB permanent in te stellen voor verbeterde prestaties.
Als u deze waarde wilt wijzigen, stelt u de leesgrootte in door een regel toe te voegen in udev, een Linux-kernelapparaatbeheer. Volg vervolgens deze stappen:
Maak in een teksteditor het bestand /etc/udev/rules.d/99-nfs.rules door de volgende tekst in te voeren en op te slaan:
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"Pas in een console de udev-regel toe door de opdracht udevadm uit te voeren als supergebruiker en de regelbestanden en andere databases opnieuw te laden. U hoeft deze opdracht slechts eenmaal uit te voeren om udev op de hoogte te stellen van het nieuwe bestand.
sudo udevadm control --reload
Nconnect
Nconnect is een Linux-koppelingsoptie aan de clientzijde die de prestaties op schaal verhoogt door meer TCP-verbindingen (Transmission Control Protocol) te gebruiken tussen de client en de Azure Premium Files-service voor NFSv4.1.
Voordelen van nconnect
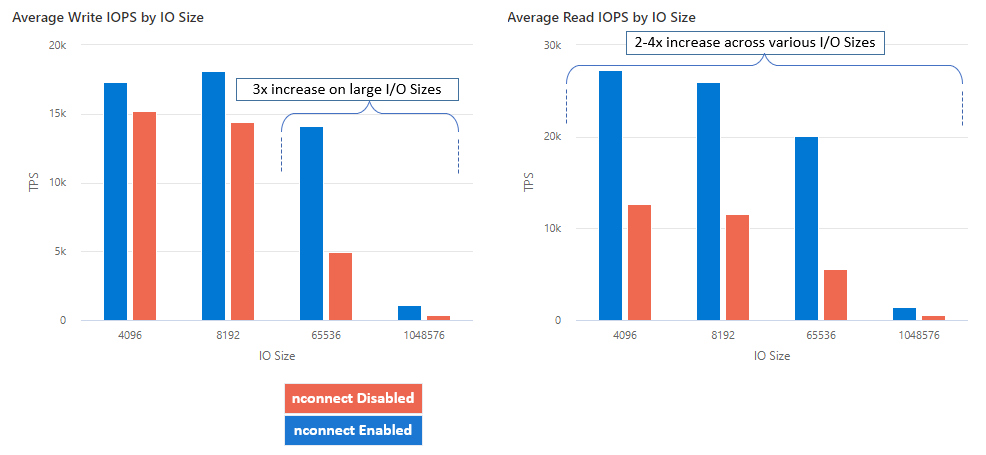
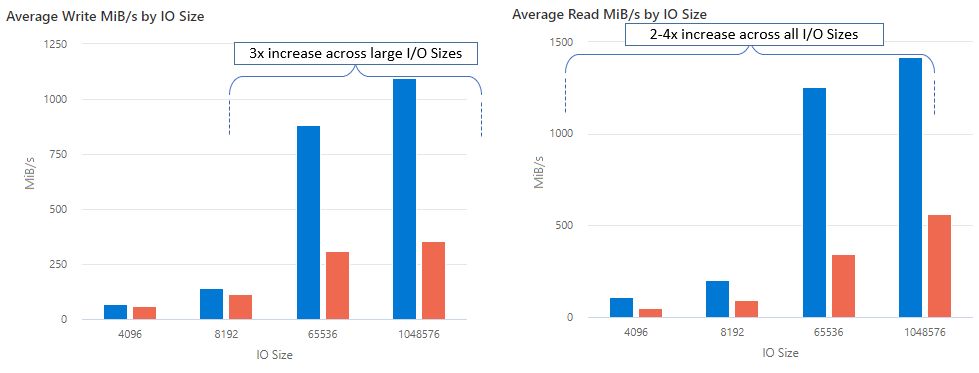
Met nconnect, kunt u de prestaties op schaal verbeteren met minder clientcomputers om de totale eigendomskosten (TCO) te verlagen. Nconnect verhoogt de prestaties door gebruik te maken van meerdere TCP-kanalen op een of meer NIC's, met behulp van één of meerdere clients. Zonder nconnecthebt u ongeveer 20 clientcomputers nodig om de bandbreedteschaallimieten (10 GiB/s) te bereiken die worden aangeboden door de grootste premium azure-bestandsshareinrichtingsgrootte. Met nconnect, kunt u deze limieten bereiken met slechts 6-7 clients, waardoor de rekenkosten met bijna 70% worden verlaagd en tegelijkertijd aanzienlijke verbeteringen in I/O-bewerkingen per seconde (IOPS) en doorvoer op schaal worden geboden. Zie de onderstaande tabel.
| Metrische waarde (bewerking) | I/O-grootte | Prestatieverbetering |
|---|---|---|
| IOPS (schrijven) | 64K, 1024K | 3x |
| IOPS (lezen) | Alle I/O-grootten | 2-4x |
| Doorvoer (schrijven) | 64K, 1024K | 3x |
| Doorvoer (lezen) | Alle I/O-grootten | 2-4x |
Vereisten
- De nieuwste Linux-distributies worden volledig ondersteund
nconnect. Voor oudere Linux-distributies moet u ervoor zorgen dat de Linux-kernelversie 5.3 of hoger is. - Configuratie per koppeling wordt alleen ondersteund wanneer één bestandsshare per opslagaccount wordt gebruikt via een privé-eindpunt.
Invloed op de prestaties van nconnect
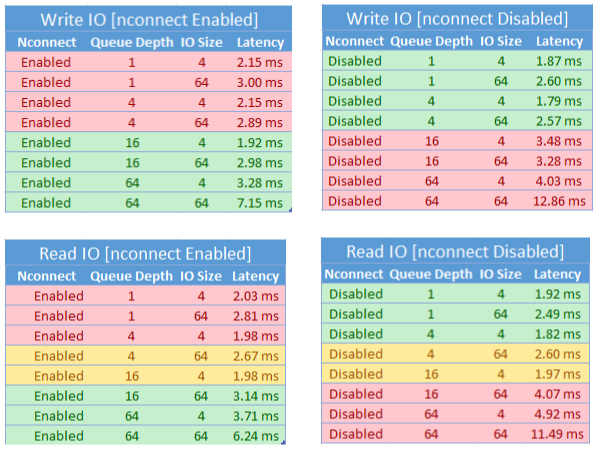
We hebben de volgende prestatieresultaten bereikt bij het gebruik van de nconnect koppelingsoptie met NFS Azure-bestandsshares op Linux-clients op schaal. Zie de configuratie van de prestatietest voor meer informatie over hoe we deze resultaten hebben bereikt.
Aanbevelingen voor nconnect
Volg deze aanbevelingen om de beste resultaten te krijgen van nconnect.
Set nconnect=4
Hoewel Azure Files ondersteuning biedt voor het instellen nconnect van maximaal 16, raden we u aan om de koppelopties te configureren met de optimale instelling.nconnect=4 Momenteel zijn er geen voordelen meer dan vier kanalen voor de Azure Files-implementatie van nconnect. In feite kan het overschrijden van vier kanalen tot één Azure-bestandsshare van één client de prestaties nadelig beïnvloeden vanwege de verzadiging van het TCP-netwerk.
Grootte van virtuele machines zorgvuldig aanpassen
Afhankelijk van uw workloadvereisten is het belangrijk om de grootte van de virtuele machines van de client (VM's) correct te bepalen om te voorkomen dat deze worden beperkt door de verwachte netwerkbandbreedte. U hebt geen meerdere netwerkinterfacecontrollers (NIC's) nodig om de verwachte netwerkdoorvoer te bereiken. Hoewel het gebruikelijk is om vm's voor algemeen gebruik te gebruiken met Azure Files, zijn er verschillende VM-typen beschikbaar, afhankelijk van uw workloadbehoeften en beschikbaarheid van regio's. Zie Azure VM Selector voor meer informatie.
Wachtrijdiepte kleiner dan of gelijk aan 64 houden
De wachtrijdiepte is het aantal in behandeling zijnde I/O-aanvragen dat een opslagresource kan verwerken. We raden u niet aan om de optimale wachtrijdiepte van 64 te overschrijden, omdat u geen prestatieverbeteringen meer ziet. Zie Wachtrijdiepte voor meer informatie.
Nconnect Configuratie per koppeling
Als voor een workload meerdere shares met een of meer opslagaccounts met verschillende nconnect instellingen van één client moeten worden gekoppeld, kunnen we niet garanderen dat deze instellingen behouden blijven bij het koppelen via het openbare eindpunt. Configuratie per koppeling wordt alleen ondersteund wanneer één Azure-bestandsshare wordt gebruikt per opslagaccount via het privé-eindpunt, zoals beschreven in Scenario 1.
Scenario 1: nconnect configuratie per koppeling via privé-eindpunt met meerdere opslagaccounts (ondersteund)
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Scenario 2: nconnect configuratie per koppeling via openbaar eindpunt (niet ondersteund)
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Notitie
Zelfs als het opslagaccount wordt omgezet in een ander IP-adres, kunnen we niet garanderen dat dat adres blijft bestaan omdat openbare eindpunten geen statische adressen zijn.
Scenario 3: nconnect configuratie per koppeling via privé-eindpunt met meerdere shares in één opslagaccount (niet ondersteund)
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
Configuratie van prestatietest
We hebben de volgende resources en benchmarkinghulpprogramma's gebruikt om de resultaten te bereiken en te meten die in dit artikel worden beschreven.
- Eén client: Azure VM (DSv4-serie) met één NIC
- Besturingssysteem: Linux (Ubuntu 20.40)
- NFS-opslag: Azure Files Premium-bestandsshare (ingericht 30 TiB, set
nconnect=4)
| Grootte | vCPU | Geheugen | Tijdelijke opslag (SSD) | Maximum aantal gegevensschijven | Maximum aantal NIC's | Verwachte netwerkbandbreedte |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64 GiB | Alleen externe opslag | 32 | 8 | 12.500 Mbps |
Benchmarkinghulpprogramma's en tests
We gebruikten Flexibele I/O-tester (FIO), een gratis opensource-schijf-I/O-hulpprogramma dat zowel wordt gebruikt voor benchmark- als stress-/hardwareverificatie. Als u FIO wilt installeren, volgt u de sectie Binaire pakketten in het FIO README-bestand dat u wilt installeren voor het platform van uw keuze.
Hoewel deze tests zich richten op willekeurige I/O-toegangspatronen, krijgt u vergelijkbare resultaten wanneer u sequentiële I/O gebruikt.
Hoge IOPS: 100% leesbewerkingen
4k I/O-grootte - willekeurig lezen - 64 wachtrijdiepte
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
8k I/O-grootte - willekeurige leesbewerking - 64 wachtrijdiepte
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Hoge doorvoer: 100% leesbewerkingen
I/O-grootte van 64k - willekeurig lezen - 64 wachtrijdiepte
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
I/O-grootte van 1024k - 100% willekeurig lezen - 64 wachtrijdiepte
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Hoge IOPS: 100% schrijfbewerkingen
4k I/O-grootte - 100% willekeurige schrijfbewerking - 64 wachtrijdiepte
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
8k I/O-grootte - 100% willekeurige schrijfbewerking - 64 wachtrijdiepte
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Hoge doorvoer: 100% schrijfbewerkingen
64k I/O-grootte - 100% willekeurige schrijfbewerking - 64 wachtrijdiepte
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
I/O-grootte van 1024k - 100% willekeurige schrijfbewerkingen - 64 wachtrijdiepte
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Prestatieoverwegingen voor nconnect
Wanneer u de nconnect koppelingsoptie gebruikt, moet u workloads met de volgende kenmerken nauwkeurig evalueren:
- Latentiegevoelige schrijfworkloads met één thread en/of gebruik een lage wachtrijdiepte (minder dan 16)
- Latentiegevoelige leesworkloads die uit één thread bestaan en/of een lage wachtrijdiepte gebruiken in combinatie met kleinere I/O-grootten
Niet alle workloads vereisen IOPS op grote schaal of tijdens de prestaties. Voor kleinere workloads nconnect is dit mogelijk niet logisch. Gebruik de volgende tabel om te bepalen of nconnect het voordelig is voor uw workload. Scenario's die groen zijn gemarkeerd, worden aanbevolen, terwijl scenario's in rood niet zijn gemarkeerd. Scenario's die geel zijn gemarkeerd, zijn neutraal.