Zelfstudie: Event Hubs-gegevens vastleggen in Parquet-indeling en analyseren met Azure Synapse Analytics
In deze zelfstudie ziet u hoe u de Stream Analytics-editor zonder code kunt gebruiken om een taak te maken waarmee Event Hubs-gegevens worden vastgelegd in Azure Data Lake Storage Gen2 in de Parquet-indeling.
In deze zelfstudie leert u het volgende:
- Een gebeurtenisgenerator implementeren die voorbeeld gebeurtenissen naar een Event Hub verzendt
- Een Stream Analytics-taak maken met de editor zonder code
- Invoergegevens en schema controleren
- Configureren Azure Data Lake Storage Gen2 naar welke Event Hub-gegevens worden vastgelegd
- De Stream Analytics-taak uitvoeren
- Gebruik Azure Synapse Analytics om query's uit te voeren op de Parquet-bestanden
Vereisten
Voordat u begint, moet u de volgende stappen hebben voltooid:
- Als u nog geen abonnement op Azure hebt, maakt u een gratis account aan.
- Implementeer de TollApp-gebeurtenisgenerator-app in Azure. Stel de parameter interval in op 1 en gebruik een nieuwe resourcegroep voor deze stap.
- Maak een Azure Synapse Analytics-werkruimte met een Data Lake Storage Gen2-account.
Geen code-editor gebruiken om een Stream Analytics-taak te maken
Zoek de resourcegroep waarin de TollApp-gebeurtenisgenerator is geïmplementeerd.
Selecteer de Azure Event Hubs naamruimte.
Selecteer op de pagina Event Hubs-naamruimtede optie Event Hubs onder Entiteiten in het menu links.
Selecteer
entrystreamexemplaar.
Selecteer op de pagina Event Hubs-exemplaarde optie Gegevens verwerken in de sectie Functies in het menu aan de linkerkant.
Selecteer Start op de tegel Gegevens vastleggen in ADLS Gen2 in Parquet-indeling .
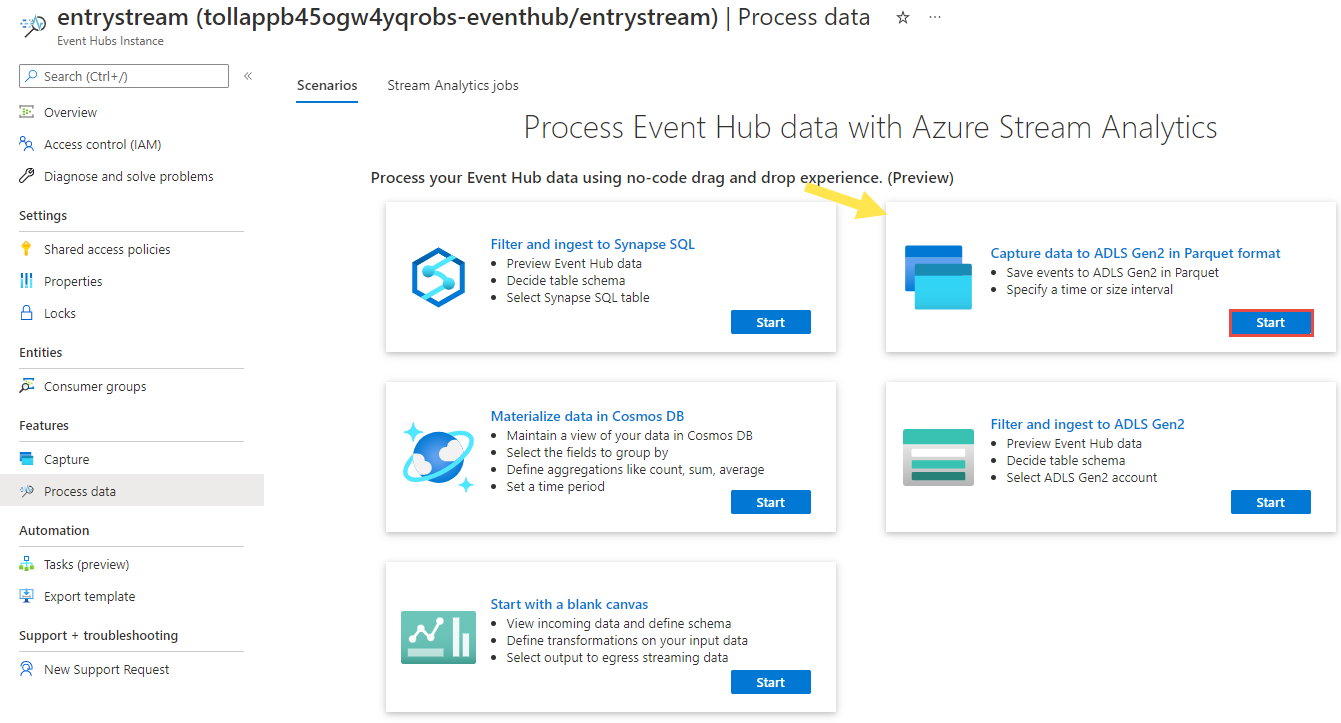
Geef uw taak
parquetcaptureeen naam en selecteer Maken.
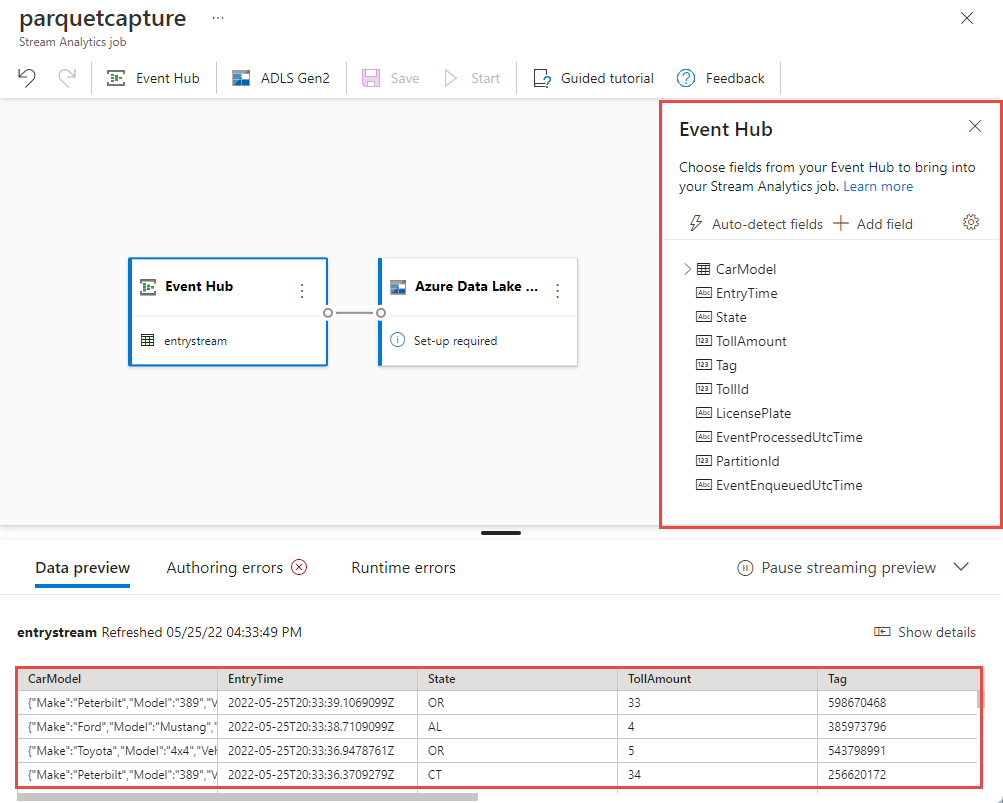
Bevestig op de configuratiepagina van de Event Hub de volgende instellingen en selecteer vervolgens Verbinding maken.
Consumentengroep: standaard
Serialisatietype van uw invoergegevens: JSON
Verificatiemodus die de taak gebruikt om verbinding te maken met uw Event Hub: Verbindingsreeks.

Binnen enkele seconden ziet u voorbeeldinvoergegevens en het schema. U kunt ervoor kiezen om velden te verwijderen, de naam van velden te wijzigen of het gegevenstype te wijzigen.
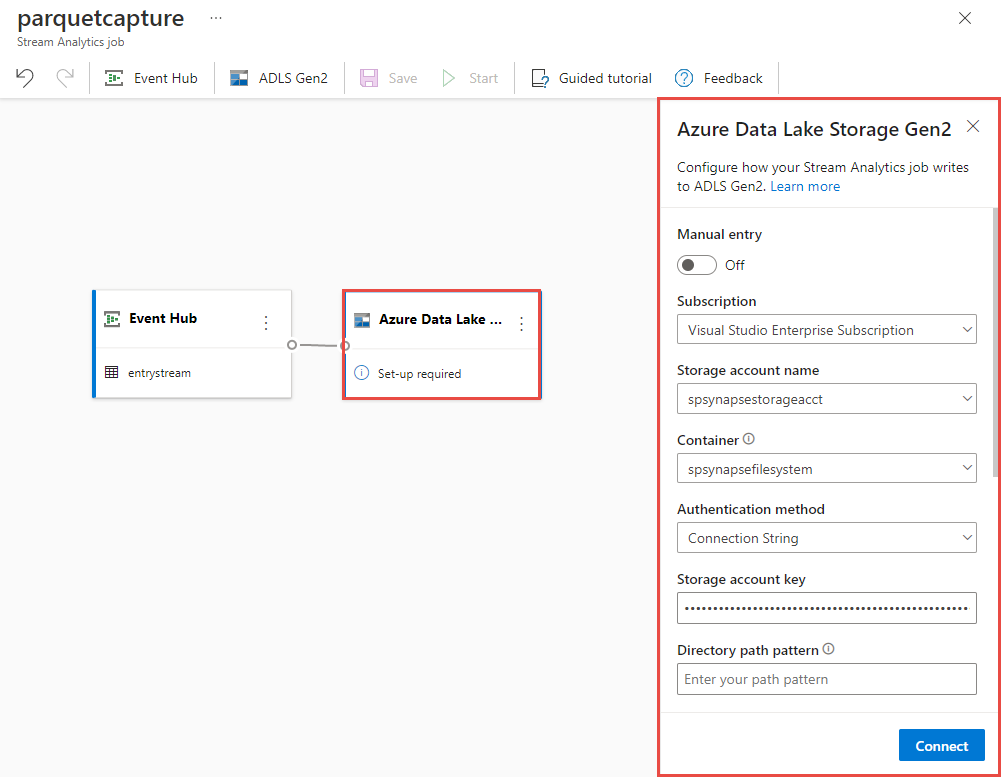
Selecteer de tegel Azure Data Lake Storage Gen2 op het canvas en configureer deze door op te geven
- Abonnement waarin uw Azure Data Lake Gen2-account zich bevindt
- De naam van het opslagaccount moet hetzelfde ZIJN als het ADLS Gen2-account dat wordt gebruikt voor uw Azure Synapse Analytics-werkruimte in de sectie Vereisten.
- Container waarin de Parquet-bestanden worden gemaakt.
- Padpatroon ingesteld op {date}/{time}
- Datum- en tijdpatroon als standaard jjjj-mm-dd en UU.
- Selecteer Verbinding maken
Selecteer Opslaan in het bovenste lint om uw taak op te slaan en selecteer vervolgens Start om de taak uit te voeren. Zodra de taak is gestart, selecteert u X in de rechterhoek om de stream analytics-taakpagina te sluiten.

Vervolgens ziet u een lijst met alle Stream Analytics-taken die zijn gemaakt met de editor zonder code. En binnen twee minuten krijgt uw taak de status Wordt uitgevoerd . Selecteer de knop Vernieuwen op de pagina om de status te wijzigen van Gemaakt -> Beginnend -> Actief.
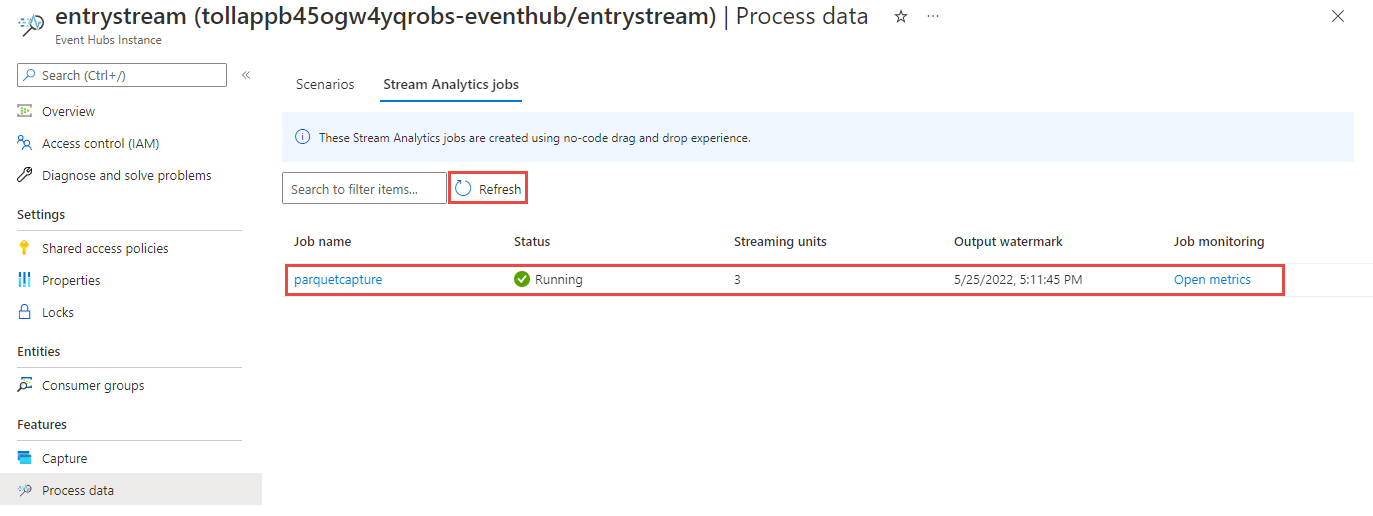








Uitvoer weergeven in uw Azure Data Lake Storage Gen 2-account
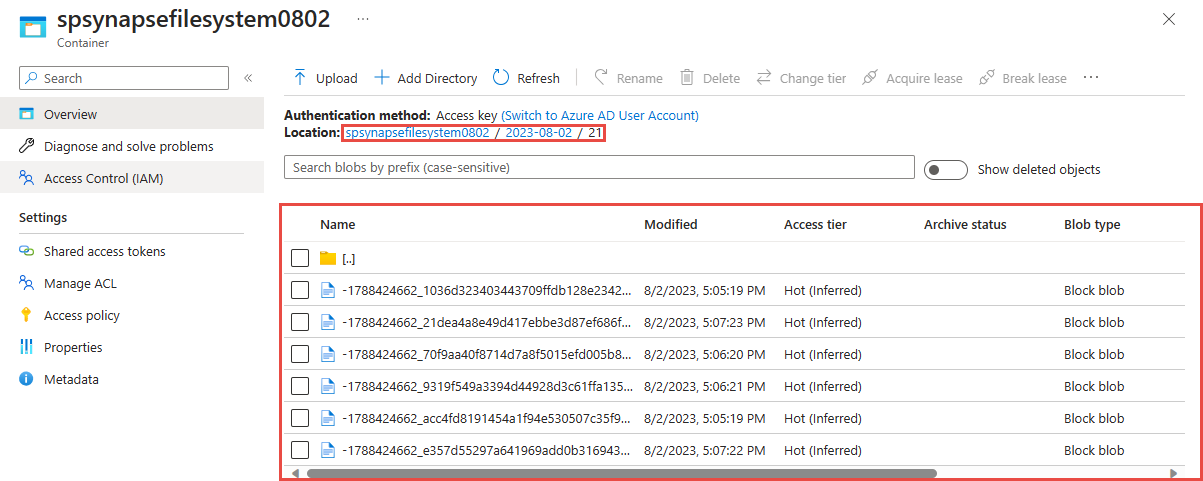
Zoek het Azure Data Lake Storage Gen2-account dat u in de vorige stap hebt gebruikt.
Selecteer de container die u in de vorige stap hebt gebruikt. U ziet dat parquet-bestanden zijn gemaakt op basis van het padpatroon {date}/{time} dat in de vorige stap is gebruikt.
Query's uitvoeren op vastgelegde gegevens in Parquet-indeling met Azure Synapse Analytics
Query uitvoeren met Azure Synapse Spark
Zoek uw Azure Synapse Analytics-werkruimte en open Synapse Studio.
Maak een serverloze Apache Spark-pool in uw werkruimte als deze nog niet bestaat.
Ga in de Synapse Studio naar de hub Ontwikkelen en maak een nieuw notebook.
Maak een nieuwe codecel en plak de volgende code in die cel. Vervang container en adlsname door de naam van de container en het ADLS Gen2-account dat in de vorige stap is gebruikt.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Selecteer voor Koppelen aan op de werkbalk uw Spark-pool in de vervolgkeuzelijst.
Selecteer Alles uitvoeren om de resultaten te bekijken


Query's uitvoeren met Azure Synapse serverloze SQL
Maak in de hub Ontwikkelen een nieuw SQL-script.
Plak het volgende script en voer het uit met behulp van het ingebouwde serverloze SQL-eindpunt . Vervang container en adlsname door de naam van de container en het ADLS Gen2-account dat in de vorige stap is gebruikt.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]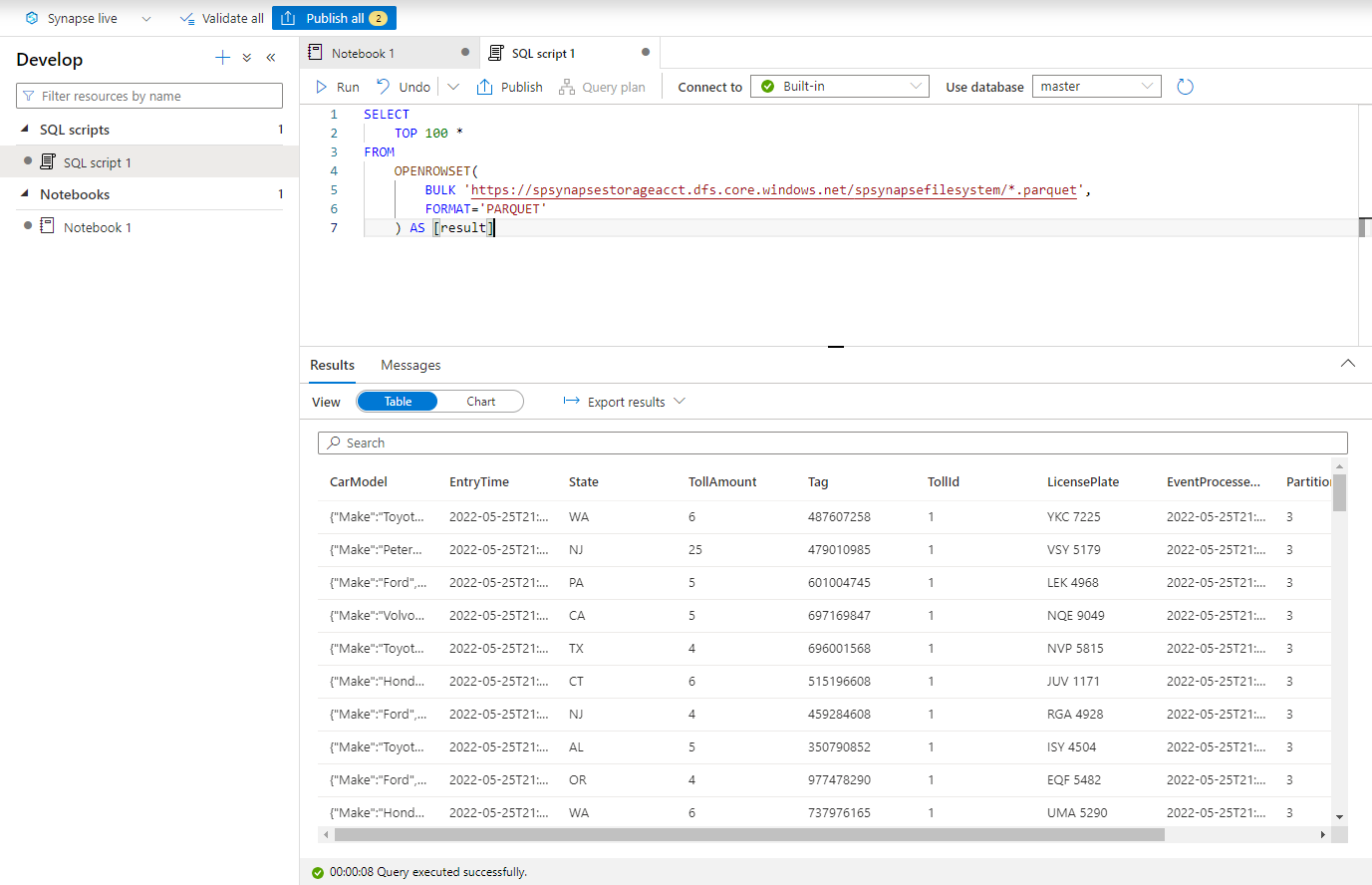

Resources opschonen
- Zoek uw Event Hubs-exemplaar en bekijk de lijst met Stream Analytics-taken onder de sectie Gegevens verwerken . Stop alle taken die worden uitgevoerd.
- Ga naar de resourcegroep die u hebt gebruikt tijdens het implementeren van de TollApp-gebeurtenisgenerator.
- Selecteer Resourcegroep verwijderen. Typ de naam van de resourcegroep om het verwijderen te bevestigen.
Volgende stappen
In deze zelfstudie hebt u geleerd hoe u een Stream Analytics-taak maakt met behulp van de editor zonder code om Event Hubs-gegevensstromen in Parquet-indeling vast te leggen. Vervolgens hebt u Azure Synapse Analytics gebruikt om een query uit te voeren op de Parquet-bestanden met zowel Synapse Spark als Synapse SQL.